






解决的问题
长尾item的用户反馈数据稀疏是推荐系统中长期存在的一个问题。近期受到CV和NLP领域在自监督学习任务上进展的启发,我们提出了一个针对大规模item推荐的自监督学习(SSL)框架。框架主要通过更好地学习item特征之间的潜在联系来解决label稀疏的问题。特别地,SSL既优化了item表征,又优化了线上服务,从而提升了模型的泛化能力。除此之外,我们还在框架中提出一种新颖的利用特征交互来进行数据增强的方法。我们通过两个真实的数据集和一个线上真实的app-to-app推荐场景来评估我们的模型,实验结果表明我们的框架确实对模型性能有所提升。
本文的方法
模型框架
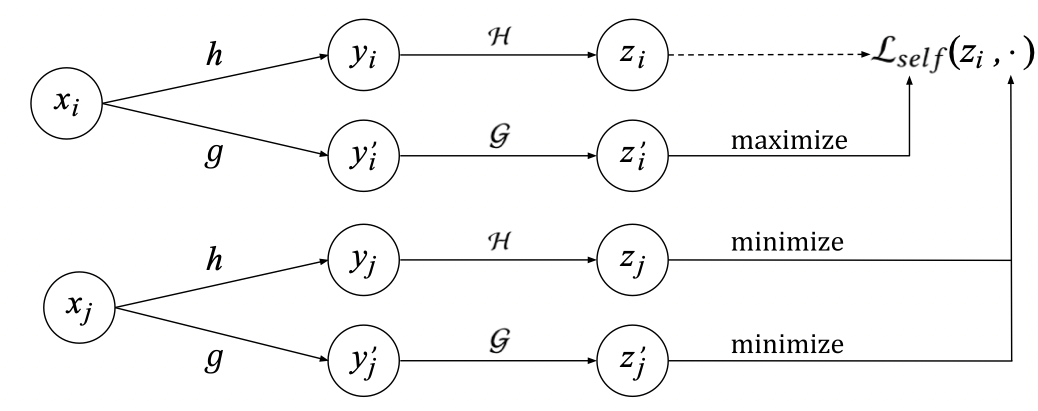
受到CV中SimCLR模型的启发,我们使用了相似的对比学习算法。基本思想分为两步:首先,我们对于相同的训练样本使用不同的数据增强方法来学习它们的表示。然后使用对比损失函数来使得相同训练样本的表示互相接近。对比损失也会用来双塔DNN的训练中,在双塔DNN中它的目的变成了让整样本的item与它相关的query接近。
Loss 我们考虑一个batch的样本
x
1
,
.
.
.
,
x
N
x_1, ..., x_N
x1,...,xN,其中
x
i
∈
X
x_i \in X
xi∈X表示第i个样本的特征集。在推荐系统中,一个样本可能是一个query,一个item或一个query-item对。假设我们有一对变换函数
h
,
g
:
X
→
X
h, g: X \rightarrow X
h,g:X→X,能够分别将
x
i
x_i
xi变换成
y
i
,
y
i
′
y_i, y_i'
yi,yi′,
y
i
←
h
(
x
i
)
,
y
i
′
←
g
(
x
i
)
y_i \leftarrow h(x_i), y_i'\leftarrow g(x_i)
yi←h(xi),yi′←g(xi)那么对比学习的loss就是要最小化
y
i
,
y
i
′
y_i, y_i'
yi,yi′之间的差别。而同时,对于不同的样本i和j,对比学习的loss就要最大化他们之间的差别。令
z
i
,
z
i
′
z_i, z_i'
zi,zi′表示
y
i
,
y
i
′
y_i, y_i'
yi,yi′经过网络
H
,
G
H, G
H,G变换后生成的embedding,我们将
(
z
i
,
z
i
′
)
(z_i, z_i')
(zi,zi′)视为正样本对,而
(
z
i
,
z
j
′
)
(z_i, z_j')
(zi,zj′)视为负样本对,令
s
(
z
i
,
z
j
′
)
s(z_i, z_j')
s(zi,zj′)为
z
i
,
z
j
′
z_i, z_j'
zi,zj′的cosine距离,我们定义一个有N个样本的batch的loss如下:
L
s
e
l
f
(
{
x
i
}
;
H
,
G
)
:
=
−
1
N
∑
i
∈
[
N
]
l
o
g
e
x
p
(
s
(
z
i
,
z
i
′
)
/
τ
)
∑
j
∈
[
N
]
e
x
p
(
s
(
z
i
,
z
j
′
)
/
τ
)
L_{self}(\{x_i\};H, G) := -\frac{1}{N}\sum_{i \in [N]}log\frac{exp(s(z_i, z_i')/\tau)}{\sum_{j\in [N]}exp(s(z_i, z_j')/\tau)}
Lself({xi};H,G):=−N1i∈[N]∑log∑j∈[N]exp(s(zi,zj′)/τ)exp(s(zi,zi′)/τ) 其中
τ
\tau
τ是softmax temperature,上面的loss函数能够习得稳定的embedding空间,在这个embedding空间中相似的item距离相近,而随机样本相距很远。上图就是整个的framework。
encoder框架 我们的
H
,
G
H, G
H,G由一个输入层和一个MLP组成,输入层由归一化后的稠密特征和稀疏特征embedding组成,embedding在H和G中是共享的,而基于不同的数据增强技术,MLP的参数在H和G中也是部分共享的。
与spread-out regularization的联系 在特殊情况下,h和g是相同的变换,而H和G是完全相同的MLP网络,上面的loss就会坍缩成
−
N
−
1
∑
i
l
o
g
e
x
p
(
1
/
τ
)
e
x
p
(
1
/
τ
)
+
∑
i
≠
j
e
x
p
(
s
(
z
i
,
z
j
′
)
/
τ
)
-N^{-1}\sum_ilog \frac{exp(1/\tau)}{exp(1/\tau) + \sum_{i \neq j}exp(s(z_i, z_j')/\tau)}
−N−1i∑logexp(1/τ)+∑i=jexp(s(zi,zj′)/τ)exp(1/τ) 这个公式的目的就是让不同样本的表达有较小的cosine相似度。这一loss很像spread-out regularization,除了softmax部分原本是平方损失。spread-out regularization已经被证明在大规模召回模型中能有效增强泛化能力。在后文中我们会提出一种基于SSL的正则,相比于spread-out regularization,基于SSL的正则能进一步提升模型性能。
两步数据增强
我们在上面的图中引入了数据增强,它的主要思想是给出一个item特征集,通过将特征中的部分信息mask掉来产生两个新样本。一个好的数据增强方法应该做出尽可能少的假设,从而能够被广泛利用在大部分数据集和模型上。我们的mask思想源自于BERT的mask方法,与序列token不同的是,我们的特征之间不存在顺序关系。我们提出了Correlated Feature Masking (CFM)方法,通过挖掘特征之间的关联来设计masking pattern。
如果不采用数据增强,那么我们的模型输入是将所有特征拼接起来。我们的两步骤数据增强包括:
- masking:我们使用一个默认embedding来替代在输入层被我们mask掉的特征
- dropout:对于多值特征,我们按概率来丢掉每个value,这一做法能够进一步减少输入信息,增加SSL任务的难度
接下来介绍masking阶段的策略。我们将Random Feature Masking (RFM)作为baseline,这种方法就是随机将一个样本的特征集分为两个不相交的特征子集,用两个特征子集生成两个样本。我们实际使用的方法是Correlated Feature Masking (CFM)。这种方法会根据两个特征的交互信息来度量特征的关联,在根据特征关联来进行特征的分割。计算方法如下: M I ( V i , V j ) = ∑ v i ∈ V i , v j ∈ V j P ( v i , v j ) l o g P ( v i , v j ) P ( v i ) P ( v j ) MI(V_i, V_j) = \sum_{v_i \in V_i, v_j \in V_j} P(v_i, v_j)log \frac{P(v_i, v_j)}{P(v_i)P(v_j)} MI(Vi,Vj)=vi∈Vi,vj∈Vj∑P(vi,vj)logP(vi)P(vj)P(vi,vj) 其中 V i , V j V_i, V_j Vi,Vj表示词表,所有特征的交互信息都可以提前计算出来。
有了提前计算好的特征交互信息,对于被mask的特征 F m F_m Fm,我们会把关联度高的特征一起mask掉:首先从特征集中均匀采样一个种子特征 f s e e d f_{seed} fseed,然后选择与它最相关的top N个特征,最终的特征是由种子和与它关联的特征组成的,即 F m = { f s e e d , f c 1 , . . . , f c n } F_m = \{f_{seed}, f_{c1}, ..., f_{cn}\} Fm={fseed,fc1,...,fcn},我们选择 n = k / 2 n = k/2 n=k/2,使得mask掉的特征和保留的特征数量能近似相等。我们每个batch变换种子特征,以使SSL任务学习到多种mask pattern。
多任务学习
为将SSL学到的表达用到推荐的分类或回归任务中,我们利用一个多任务训练策略,对我们的主要任务和辅助的SSL任务一并进行训练。举例来说,令
{
(
q
i
,
x
i
)
}
\{(q_i, x_i)\}
{(qi,xi)}为一个从训练集分布
D
t
r
a
i
n
D_{train}
Dtrain中采样出来的query-item对的batch,令
{
x
i
}
\{x_i\}
{xi}为一个从item分布
D
i
t
e
m
D_{item}
Ditem中batch的item,那么联合loss如下所示:
L
=
L
m
a
i
n
(
{
(
q
i
,
x
i
)
}
)
+
α
⋅
L
s
e
l
f
(
{
x
i
}
)
L = L_{main}(\{(q_i, x_i)\}) + \alpha \cdot L_{self}(\{x_i\})
L=Lmain({(qi,xi)})+α⋅Lself({xi})
异构的样本分布从
D
t
r
a
i
n
D_{train}
Dtrain中采样出来的样本的边缘item分布基本服从幂律分布,如果用
D
t
r
a
i
n
D_{train}
Dtrain来采样计算
L
s
e
l
f
L_{self}
Lself会使得学到的特征关联与头部item有出入。于是我们从
D
i
t
e
m
D_{item}
Ditem中采样item来计算
L
s
e
l
f
L_{self}
Lself。我们在实践中发现两个任务分别采样对于SSL提升监督任务的性能是至关重要的。
主任务的loss我们利用batch softmax loss作为主任务的loss。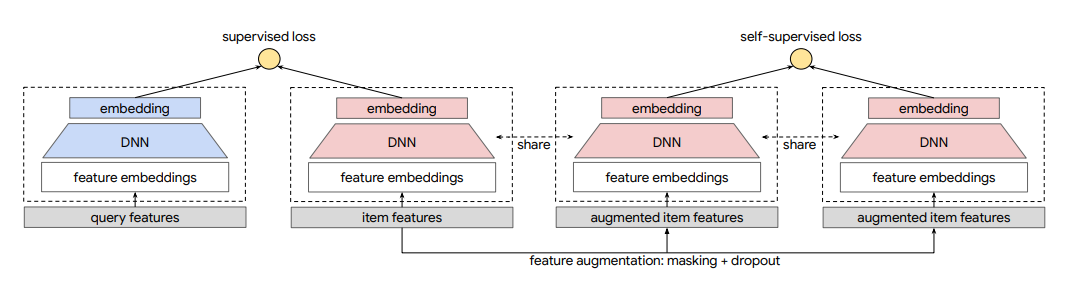
评估
评估结果显示,SSL方法对于baseline方法,对于长尾item的推荐效果有更大的提升。















 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









