







在找DBN的tensorflow实现的时候发现了这么一个工具,github主页指路。里面有RNN, CNN, 基于玻尔兹曼机的网络等等模型的实现。官方文档也有不过版本较旧,没太大参考价值了。
安装和使用
可以通过pip安装,但还是建议从github主页下载,毕竟后续无论什么工作都可能涉及到修改源码嘛。下载后进入Deep-Learning-TensorFlow目录,运行安装脚本。
sudo python setup.py install至此yadlt安装完毕。
yadlt对模型的调整和训练全部可以通过命令行选项完成。因为主要扒DBN部分,其他部分的使用与此类似就不赘述。
要正确使用yadlt的DBN模型首先要熟悉DBN,可以去看《深度学习》这本书或者其他人的博客。Hinton在2006年发表了一篇论文提到了DBN和它的训练方法,这里有我的一篇笔记,如果看了书还是一头雾水可以翻翻,说不定能够从一头雾水升级为一知半解。
构建和训练DBN的脚本为 /cmd_line/boltzmann/run_dbn.py,数据集,超参数,以及与tensorboard有关的一些设置都通过命令行选项来完成。
这份脚本支持的功能主要有:
- MNIST手写数据集的自动下载
- 手工指定用户训练集,验证集,测试集的路径
- 保存模型的预测结果
- 保存训练集和测试集每层的输出
- 选择是否进行pre-train
- 为随机数生成器设置种子
- 设定动量参数
- 设定RBM层数和每层单元数
- 设定RBM的迭代次数(epoch)
- 设定RBM训练过程中的batch大小
- 设定Gibbs采样步长
- 选择可视层为二值单元或高斯单元
- 设定模型调整的激活函数,学习率,迭代次数,优化方法,损失函数种类
- 设定模型调整时的dropout参数
想要立刻让这份代码跑起来可以进入/cmd_line/boltzmann/目录,敲以下代码:
python run_dbn.py --dataset mnist这行代码会让yadlt自己去下载mnist数据集,然后用它构建DBN模型并且测试模型的准确率,并且还会构建一个计算图,画出accuracy的曲线,可以利用tensorboard查看。至于调参,更改数据集等等内容请自行阅读run_dbn.py,这个文件其实就相当于一个文档。
代码笔记
与DBN有关的文件主要有:
- /cmd_line/boltzmann/run_dbn.py : 利用命令行构建DBN,对模型进行训练和测试,内容主要是参数的解析和main方法,调用以下文件中的类和方法。
- /yadlt/models/boltzmann/dbn.py : DBN的真正实现
- /yadlt/models/boltzmann/rbm.py : DBN的组成部分RBM的实现
- /yadlt/core/supervised_model.py : 此处DBN是作为监督学习模型实现的,继承了此类的一些方法
- /yadlt/core/unsupervised_model.py : 作为DBN组成部分的RBM是无监督模型,继承了此类的一些方法
- /yadlt/core/model.py : 上面两个类继承了此类的一些方法
从run_dbn.py入手可以看出,这份python程序一共可以分为下面几个流程。
数据的导入
在导入数据前是一个命令行参数解析的过程,利用了tensorflow的tf.app.flags模块来实现。
用来训练和测试的数据由命令行参数指定,有下面三个选项:
- mnist : MNIST手写数据集,无需手动下载或指明目录。
- cifar_dir : cifar数据集,需要自行下载,给命令行提供数据所在路径。
- custom : 用户自己的数据集,需要在命令行给出训练,验证,测试数据的特征向量和标签所在路径。
如果想用自己的数据集,需要把数据保存为.npy格式,并且把标签和样本特征保存为两个文件。
模型的构建
DBN模型的构建阶段初始化了一个DeepBeliefNetwork对象,从命令行传入了以下参数。
srbm = dbn.DeepBeliefNetwork(
name=FLAGS.name, do_pretrain=FLAGS.do_pretrain,
rbm_layers=rbm_layers,
finetune_act_func=finetune_act_func, rbm_learning_rate=rbm_learning_rate,
rbm_num_epochs=rbm_num_epochs, rbm_gibbs_k = rbm_gibbs_k,
rbm_gauss_visible=FLAGS.rbm_gauss_visible, rbm_stddev=FLAGS.rbm_stddev,
momentum=FLAGS.momentum, rbm_batch_size=rbm_batch_size, finetune_learning_rat
e=FLAGS.finetune_learning_rate,
finetune_num_epochs=FLAGS.finetune_num_epochs, finetune_batch_size=FLAGS.fine
tune_batch_size,
finetune_opt=FLAGS.finetune_opt, finetune_loss_func=FLAGS.finetune_loss_func,
finetune_dropout=FLAGS.finetune_dropout) 在DeepBeliefNetwork中又初始化了n个RBM对象,其中n是命令行参数rbm_layers数组的长度。
self.rbms.append(
rbm.RBM(
name=self.name + '-' + rbm_str,
num_hidden=layer,
learning_rate=rbm_params['learning_rate'][l],
num_epochs=rbm_params['num_epochs'][l],
batch_size=rbm_params['batch_size'][l],
gibbs_sampling_steps=rbm_params['gibbs_k'][l]))除此之外也指定了损失函数和后面调整模型时的训练函数。
pre-train
在初始化后,模型就对训练集和验证集的数据进行了预训练。
srbm.pretrain(trX, vlX)这一部分就是训练多层RBM的部分,是一个无监督的过程。假设DBN网络是长下图所示这样的:
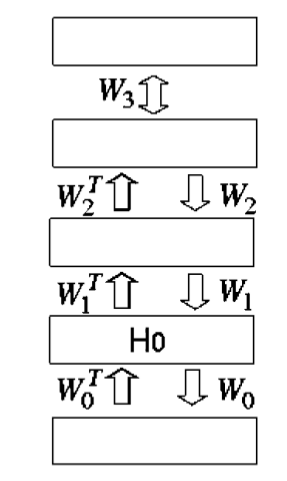
那么pretrain过程就是从
V−H0
V
−
H
0
层起,对
H0−H1,H1−H2,⋯
H
0
−
H
1
,
H
1
−
H
2
,
⋯
逐层对每个RBM的权重W和偏置b进行训练。
pretrain()经过一系列的辗转,调用到了Model类的pretrain_procedure()函数,又为每个RBM层分别调用了_pretrain_layer_and_gen_feed()函数。这一函数经过一系列的辗转后,调用了UnsupervisedModel类的fit()函数来对RBM进行训练,随后对训练集和验证集分别调用同为UnsupervisedModel类的transform()函数,用来生成“上层”的数据。
UnsupervisedModel.fit()
UnsupervisedModel类的fit()函数其实就是一个正常的tensorflow的训练流程:创建计算图,初始化op,打开一个Session,初始化变量,运行session,保存结果,并将这一过程丢进tensorboard。
def fit(self, train_X, train_Y=None, val_X=None, val_Y=None, graph=None):
g = graph if graph is not None else self.tf_graph
with g.as_default():
self.build_model(train_X.shape[1])
with tf.Session() as self.tf_session:
summary_objs = tf_utils.init_tf_ops(self.tf_session)
self.tf_merged_summaries = summary_objs[0]
self.tf_summary_writer = summary_objs[1]
self.tf_saver = summary_objs[2]
self._train_model(train_X, train_Y, val_X, val_Y)
self.tf_saver.save(self.tf_session, self.model_path) 代码中的self指的是RBM类的对象,因此在这一计算图中,模型构建调用的是RBM类的build_model(),传入了训练集特征向量的维度。
RBM.build_model()
RBM类的build_model()函数实现了在tensorflow中构建RBM的过程。首先是Gibbs采样:从可视层的二值得到隐藏层每个单元的激活概率,并且随机生成隐藏层的状态。然后又利用刚生成的隐藏层状态去重构可视层的状态。反复进行k次上述步骤。根据Gibbs采用的结果更新W和bh,bv,计算loss。
RBM._train_model()
这一函数的主要功能是把训练和验证数据喂给上面函数构建好的计算图。涉及到mini_batch的生成和Session的运行。
UnsupervisedModel.transform()
UnsupervisedModel类的trainsform()主要的功能就是载入训练好的模型,并在Session内将参数传入的data喂给模型(由最后一行的tensor.eval()完成)。对于RBM模型就是将输入的可视层的数据按照RBM._train_model()中训练好的W和bh,bv生成隐藏层数据。
def transform(self, data, graph=None):
g = graph if graph is not None else self.tf_graph
with g.as_default():
with tf.Session() as self.tf_session:
self.tf_saver.restore(self.tf_session, self.model_path)
feed = {self.input_data: data, self.keep_prob: 1}
return self.encode.eval(feed) finetuning(模型调整)
在pretrain部分,一个由多层RBM组成的无监督模型已经训练完成。finetuning部分将对模型进行调整。
这一部分调用了SupervisedModel类的fit()函数,与UnsupervisedModel类的fit()函数完全相同,创建计算图,初始化op,打开一个Session,初始化变量,运行session,保存结果,并将这一过程丢进tensorboard。
DeepBeliefNetwork.build_model()
DeepBeliefNetwork类的build_model()函数为DBN模型的调整过程生成了计算图:首先利用多层RBM的参数,用可视层的输入数据生成最顶部隐藏层的状态,然后利用线性模型,以最顶部隐藏层状态作为输入计算得到y值,与传入的标签进行比较,计算整个模型的cost,再利用选定的优化算法对模型参数进行优化调整。
test(模型测试)
在测试阶段,score()函数被调用来计算测试集的准确率(accuracy)。
score()函数继承自SupervisedModel类,具体过程为打开一个Session,载入训练好的模型,将测试集的特征向量和标签喂给计算图,利用tensor.eval()来计算测试集的准确率。
DBN.accuracy
accuracy()不是DBN类的函数,而是它的一个成员变量,在构建模型时被赋值为静态方法Evaluation.accuracy(),方法实现的就是普通的准确率计算。
一些细节问题
finetune阶段,计算验证集(validation set)的准确性与计算训练集准确性的方法并不相同,计算一个epoch的训练集准确性时,计算的是从原训练集中采样的样本预测结果的准确性,而验证集则是计算它整一个集合的准确性,不存在采样步骤。
使用过程中的记录
- dbn模型在构建过程中创建了rbm类的对象,并构成了一个list。
- 在训练时,rbm从可视层到隐藏层的转换固定使用sigmoid函数为激活函数,而在dbn的训练过程中,对其中的rbm层它只load了其参数W和b,而激活函数可以自选,如果此处不选择sigmoid函数,则dbn在fine_tune阶段得到的folded_rbm的输出将会与pretrain阶段得到的输出不同,大概也算这个库的一个坑。
- folded_rbm的输出由打印变量可以看出应为“encode-{l}/dropout/mul:0”,其中l为最后一层的层号。而通过get_tensor_by_name()得到的tensor在会话中运行结果与训练阶段得到的相差微小但并不相同,目前原因不明。















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









