






题目: Online Defect Prediction for Imbalanced Data
作者: Ming Tan, Lin Tan, Sashank Dara, Caleb Mayeux
单位: University of Waterloo, Cisco Systems
出版: ICSE, 2015
解决的问题
change分类是软件缺陷分类中的一类问题。change分类面临着两个问题:
- 数据不平衡,有缺陷的change数远远少于无缺陷的change数。
- 通常所用的交叉验证方法不适用于评估change分类的性能。
本文重点解决这两个问题。
方法
标注changes
标注过程用到软件版本控制系统(VCS)和Bug Tracking系统(BTS)中的数据。从BTS系统中抽取修复bug的change,从VCS中抽取引入bug 的change。
抽取特征
我们的特征与以往工作类似,包括元数据,词袋和特性向量(characteristic vector)。元数据包括提交时间,完整路径,change添加的行数,删除的行数,更改的行数等。词袋特征是一个由文本中出现的词的计数组成的向量。特性向量是代码抽象语法树中每种结点的计数。
交叉验证问题
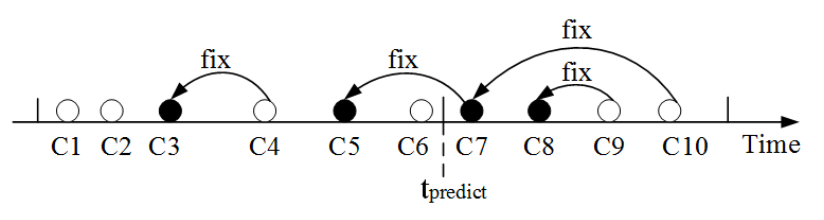
交叉验证存在两个问题:以十折交叉验证为例,首先十折交叉验证会在每次迭代中分别利用图中一个change作为测试集进行预测,也就是说可能会利用C2-C10构建模型,用来预测C1是否引入bug,这不符合实际场景。第二,交叉验证会导致change的误标。例如上图中C5会被标记为引入buggy,然而实际上,当我们预测C6时,我们应该处于时间 tpredict ,此时C5应该被标记为clean。我们的后续实验会验证交叉验证会得到大量误报。
时间敏感的change分类
change分类通常利用到时刻t所获得的信息来预测时刻t的commit。然而这种方法存在三个问题:
首先,实际应用中我们需要change一经提交就进行预测,这样我们就可以及早识别出bug,因此测试集的时间历程通常很短。然而bug通常都要经过数月甚至数年才能被发现,因此在
tpredict
时刻,训练集中的很多buggy changes特别是接近
tpredict
的很可能会被标记为clean,这会导致bug比率的降低。如果训练集和测试集的bug比率相差很大,分类算法可能就无法为测试集建立精确的模型。
第二,时间敏感的change分类性能取决于特定数据集。例如如果我们收集刚好在死线之前的一段时间的数据,那么它可能无法代表其他时期的数据,因此性能可能也与其他时期的数据不同。
第三,如果测试集中的change时间跨度很长,那么一些开发特性,例如开发任务,开发者经验,编程风格等都会与训练集不同,从而影响性能。
online change分类
为解决上面三个挑战,我们利用了balanced online time sensitive change classification方法,简称online change classification。为解决第一个问题,我们在训练集和测试集之前空出了一段时间。
为解决第二个和第三个问题,我们运行多次online change分类,每次的训练集都进行更新。最后的性能是这些次运行性能的加权平均。我们用图说明:
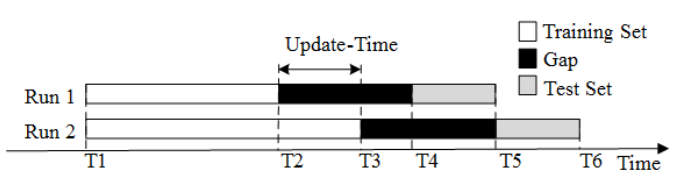
假设我们一共进行两次运行,第二次的训练集包含了第一次的数据,以及T2到T3时间的数据。第一次的测试集包含T4到T5时间段的数据,而第二次的测试集包含T5到T6时间段的数据。第二次的预测时刻是T6,因此,第二次的训练集中的数据按照T6时刻的情况进行标注。
重采样
为解决buggy change比clean change少得多的问题,我们应用了重采样技术和可更新分类技术。
待续















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









