






题目: Rendezvous: A Search Engine for Binary Code
作者: Wei Ming Khoo, Alan Mycroft, Ross Anderson
单位: University of Cambridge
出版: MSR, 2013
简介
代码重用是软件工程中的常见做法。搜索Github [1]上的短语“基于”,截至2013年2月,共有269,789次匹配。Mockus [2]发现,开源项目创建的所有文件的50%至少在另一个开源项目;这些项目中最多使用的文件来自GNU C库和Linux内核。有时代码在不适当考虑其许可条款的情况下重复使用。截至2012年,Welte在gpl-violations.org [3]成功执行或解决的软件产品中报告了200例GNU公共许可证违规。代码重用也带来了导入代码中披露的漏洞成为主要产品中未公开漏洞的风险。
目前,寻求在软件产品中识别重复使用的组件(如GPL合规性)的审计师有两种主要方法:源代码审查和软件逆向工程。然而,源代码可用性并不总是得到保证,特别是如果代码是由第三方开发的,并且理解机器代码目前相当具有挑战性。
我们提出的方法是通过提供二进制代码的搜索引擎来引导这个过程。通过利用诸如GNU,Apache基础,Linux和BSD发行版以及公共代码存储库(如Github和Google代码[4])等开源项目,我们可以重新标识代码重用作为索引和搜索问题,并提供了一个很好的解决方案对于这个问题将需要二进制代码的来源服务。
截至2013年2月,GNU C图书馆估计有118万行代码,GNU核心实用工具套件估计有57,000行C,根据开源项目追踪者Ohloh [5],Linux内核有1530万行]。有了我们今天所使用的许多代码行,我们很清楚,我们需要一种有效的索引和搜索方法。理想情况下,我们希望速度和精确度都是一样的,所以合理的方法是使用几种现有的方法进行近似,这些方法是快速的,然后进行优化和评估。另一种可行的方法是以准确性为目标,然后优化速度。我们在这里采用了前者的做法。
因此,我们的主要目标是提高效率:我们希望有一个可执行代码的快速信息检索方案。像文本搜索引擎一样,快速的响应时间是可用性的关键。
我们的次要目标是精确度(低假阳性)和召回(低假阴性)。由于我们无法控制编译器或使用的选项,因此在编译及其各种优化方面必须保持良好的性能。
本文作出以下贡献:
1)我们解决了识别不同编译器生成的大型代码库及其各种优化的问题,据我们所知,这些优化尚未完成。
2)我们已经实现了一个称为Rendezvous的二进制代码的原型搜索引擎,它利用指令助记符,控制流子图和数据常量的组合(第三部分)。 实验表明,Rendezvous能够实现GNU C库2.16编译的gcc- O1和-O2优化级别的86.7%F2度量,对于coreutils 6.10套件程序,集合度为83.0% 用gcc -O2和clang -O2编译。
3)作为一个早期的原型,在最坏的情况下,Rendezvous的效率约为0.407秒。
设计
由于提供给我们的检索系统的代码可能会从原来的修改,我们希望能够识别它的不变部分,如某些独特的功能。这可以通过统计模型近似可执行代码来实现。统计模型包括将代码分解成短块或令牌,并将参数分配给它们在参考语料库中的发生概率。令牌包括什么?对于自然语言,令牌的选择是一个单词或短语;机器代码比较复杂。程序抽象的决策空间不是未被探索的,而典型的选择是在静态和动态方法之间进行。主要是因为它的相对简单,我们选择静态分析。动态分析的缺点是需要一个虚拟执行环境,这在时间和资源方面是昂贵的[6]。静态拆卸在一般意义上决不是一个解决的问题[7],但是有一些众所周知的技术,如线性扫描和递归遍历[8],它们对于广泛的可执行文件都很有效。
三个候选抽象或表示被认为是指令助记符,控制流子图和数据常量。指令助记符是指指定要执行的操作的机器语言指令,例如32位x86架构上的mov,push和pop指令。控制流图(CFG)是一个有向图,表示程序中的控制流程。图的节点代表基本块;边缘表示节点之间的控制流。子图是包括CFG中节点子集的连接图。数据常数是指令使用的固定值,例如在计算中或作为存储器偏移量。常数的两种最常见的类型是整数和字符串。选择这些抽象是因为它们直接来自反汇编。指令助记符被选为代码语义的最简单的抽象;选择控制流图作为程序结构的最简单的抽象;选择数据常量作为数据值的最简单抽象。我们考虑的抽象类型的摘要见表一。

代码抽象
代码抽象过程涉及三个步骤。 可执行文件首先被拆分成其组成函数。 反汇编的功能然后被标记,也就是细分为指令助记符,控制流图和常数。 最后,进一步处理语句以形成查询词,然后用于构造搜索查询。
我们现在将使用运行示例详细描述三种不同抽象的抽象过程。 图2显示了用C语言编写的冒泡排序算法。

指令助记符
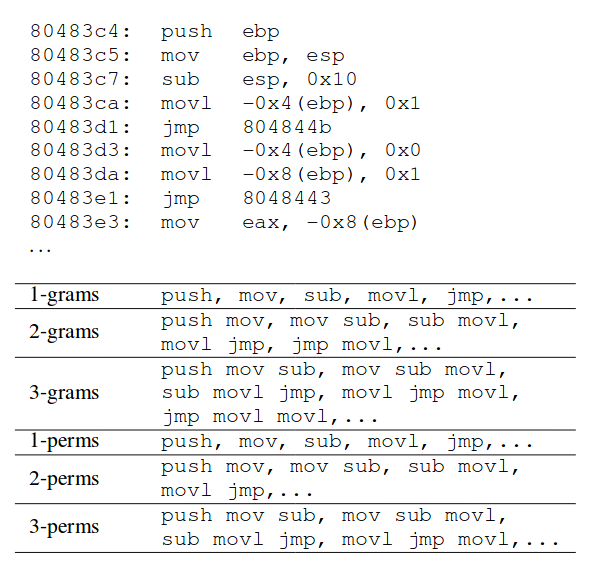
我们利用Dyninst二进制仪器工具[12]来提取指令助记符。指令助记符与操作码不同之处在于前者是文本描述,而后者是指令的十六进制编码,通常是第一个字节。多个操作码可以映射到相同的助记符,例如,操作码0x8b和0x89具有相同的助记符mov。 Dyninst识别470个助记符,包括64个浮点指令和42个SSE SIMD指令。我们使用8位来编码助记符,截断任何高阶位。可执行程序被拆卸,构成每条指令的字节一起合并为一个块。我们随后利用假设一个马尔科夫属性的n-gram模型,也就是说,令牌发生只受到它之前的n-1个令牌的影响。为了形成第一个n-gram,我们将助记符0连接到n-1;形成第二个n-gram,我们连接1到n等等。
使用助记标记的一个缺点是某些指令序列可能被重新排序而不影响程序语义。例如,以下两个指令序列在语义上是相同的,但它们将给出不同的3-gram。

n-gram模型的替代方案是使用n-perms [10]。 n-perm模型没有考虑到顺序,并且是基于集合的而不是基于序列的。 所以在上面的例子中,只有一个n-perm表示两个序列:mov,movl,sub。 然而,使用n-perms的折衷是,与同样n的n-gram相比,没有太多的n-perm,这可能会影响精度。 图3显示了指示助记符和1,2和3-grams以及对应的n-perms。
控制流子图
考虑的第二种抽象类型是控制流程。为了构建控制流程图(CFG),从反汇编中提取基本块(BB)及其流目标。 BB是连续的指令序列,其中没有进入或退出序列的中间跳转。调用指令是特例之一,因为它们不被视为外部跳转并被假设返回。条件指令,如cmov和loop是另一个特例,因为它们被视为不产生额外的控制流边。 BB形成图中的节点,流目标是节点之间的有向边。
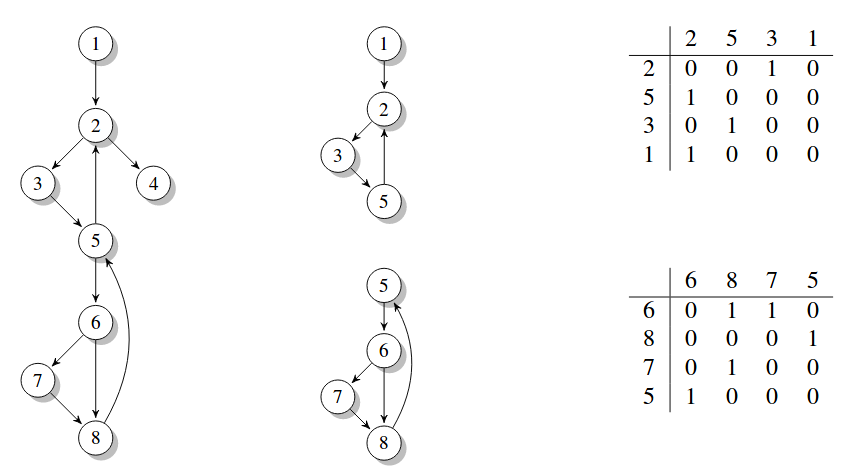
我们不对整个CFG进行索引。相反,我们提取大小为k的子图或k子图。我们的方法类似于Krugel等人采用的方法[11]。我们首先从CFG生成连接k图的列表。这通过选择每个块作为起始节点并遍历从该节点开始的所有可能的有效边,直到遇到k个节点来完成。
接下来,每个子图被转换为k大小的矩阵。然后通过预先计算的矩阵到矩阵映射将矩阵简化为其规范形式。该映射可以通过诸如Nauty [13]等标准工具离线计算,或者直接计算。
每个唯一子图对应于k平方位。对于k = 4,我们获得每个子图的16位值。图4显示了bubbleort的CFG,两个k-graph,1-2-3-5和5-6-7-8,它们的规范矩阵分别为0x1214和0x1286。该示例中的规范形式是导致最小可能数值的节点标签。
使用k-图的一个缺点是对于小的k值,图的唯一性是低的。例如,如果考虑到气泡的CFG中的3个图形,则图1-2-4,1-2-3,3-5-6都产生相同的k图。为了解决这个问题,我们提出了一个扩展k图,我们称之为扩展的k-图。除了内部节点之间的边缘之外,扩展k图包括在内部节点具有一个端点但在外部虚拟节点具有另一个端点的边,写为V*。这将添加一行和一列到我们的邻接矩阵。附加行包含从外部节点到达的边缘;额外列表示以外部节点为目标的边。这使我们现在可以区分我们之前提到的3个图。
数据常量
使用常量的动机是经验观察,常数不随编译器或编译器优化而改变。我们考虑了两种类型的常量–32位整数和字符串。我们包括用于计算的整数,以及用作指针偏移的整数;我们考虑的字符串是ANSI单字节空终止字符串。
我们的提取算法如下:首先从指令中提取所有常数。这些包括操作数和指针偏移量。我们明确排除与堆栈和帧指针相关联的偏移量,或者esp和ebp,因为这些取决于堆栈布局,因此随编译器而变化。
然后常数按类型分隔。由于我们正在考虑使用32位指令集,因此数据可能是32位整数或指针。进行地址查找以确定值v是否对应于数据或代码段中的有效地址,如果是,则检索数据dv。由于dv也可以是一个地址,这个过程可以通过dv上的另一个地址递归地继续。但是,我们不做第二次查询,而是停止在第一级间接。如果dv是一个有效的ANSI字符串,这是有效的ASCII字符,并以空字节终止,我们将其分配为字符串类型,否则我们不使用dv。在所有其他情况下,v被视为一个整数。图6显示了使用gcc默认选项编译的vdir程序的使用函数的常量。

模型评价指标
我们怎么知道什么时候我们有一个很好的统计模型? 给出一个可执行文件和一个查询语句,一个模型是高精度和回忆的模型。 真正的(tp)是指与查询相关的正确检索的文档; 真正的负面(tn)是一个正确省略的无关文件; 假阳性(fp)是不正确检索的无关文件; 而假阴性(fn)是缺失但相关的文件。
精确度和召回率定义如下。
换句话说,一个好的模型会检索很多相关文件,省略很多其他不相关的文件。 结合精度和召回的措施是F度量,其包括其谐波平均值。
这也被称为F1测量,精度和召回都是平等加权的。 为了我们的目的,我们对F2度量感兴趣,定义如下。
我们使用F2测量而不是F1测量的原因是我们想要检索尽可能多的相关文档,并且不太关心假阳性。 因此召回的优先级高于精度,F2权重的回收率是精度的两倍。
索引和查询
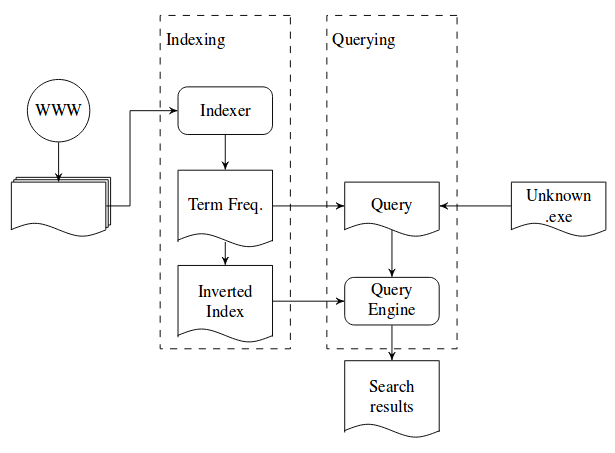
到目前为止,我们讨论过的涉及从可执行文件中提取术语。在本节中,我们将描述如何将令牌合并到标准的基于文本的索引中,以及如何对导致有意义的搜索结果的此索引进行查询。
图7显示了索引和查询过程的摘要。由于有52个不同的符号,我们可以将一个32位整数编码为一个6个字母的单词,用于一个字母索引器。索引过程是一个直接的一个 - 从网络检索的二进制文件的语料库首先被处理以给出全局的全局术语S全局。这些术语由产生两个数据映射的索引器处理。第一个是术语频率映射,将术语映射到其索引中的频率;第二个是将一个术语映射到包含该术语的文档列表的倒排索引。
我们考虑了两个查询模型 - 布尔模型(BM)和向量空间模型(VSM)。 BM是基于集合的模型,如果该术语出现在文档中,则文档权重被分配1,否则为0。布尔查询是通过将术语与布尔运算符(如AND,OR和NOT)结合形成的。 VSM是基于距离的,如果它们的权重向量的内积小,则两个文档是相似的。权重向量通过文档中所有项的归一化项频率来计算。我们的模型是基于两者的组合:首先通过BM过滤文档,然后通过VSM进行排名和评分。
给定一个感兴趣的可执行文件,我们首先将其分解成一组二进制形式的术语。二进制项被转换成字母符号字符串以给出一组术语S.例如,助记符序列push,mov,push,push,sub对应于4-gram 0x73f97373,0xf97373b3,其编码为查询词XvxFGF ,baNUAL。
然后从一组条款S构建一个布尔表达式Q.与典型的用户输入的文本查询不同,我们的问题是Q的长度可以是数千个项的长度,或者相反地,太短太常见了我们采用三种策略来处理这两个问题,即重复数据删除,填充和独特的术语选择。
重复数据删除是减少查询的术语计数的明显策略。对于所需的查询长度lQ,我们选择第一项t0,并删除t0的其他出现长度为2·lQ。重复此过程直到达到lQ条款。
可能出现的一个问题是如果Q太短,可能会导致太多的匹配。为了处理这个问题,我们添加不在S中的高频术语,用逻辑NOT来否定。例如,如果lQ是3,我们的查询有两个项A和B,我们添加第三个项NOT C,其中C是S全局中具有最高项目频率的项。这可以消除可能包含Q加其他常用术语的匹配。
在这些步骤结束时,我们为每个术语类别获取一系列术语。我们首先通过连接术语来构建最严格的查询
AND,例如XvxFGF和baNUAL,并将查询发送到查询引擎
反过来查询索引并以排名列表的形式返回结果。如果此查询不返回任何结果,我们继续构建具有唯一术语选择的第二个查询。
独特术语选择的目的是选择具有低文档频率或罕见术语的术语。如果S的大小大于最大查询长度lQ,则这样做。














 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









