






参考资料:
对于初学者来说,编程遇到的头一个问题可能就是不知道怎么编写数据读取的代码以输入网络。本文主要讲解的就是编写该部分代码的常见方法和编程思路。内容基本是官方文档的翻译与总结。
数据
下载之后保存在data/faces路径下。
里面一共有69张脸部图片,有一个csv文档作为金标准用于保存所有的关键点,每一张脸部图像有68个关键点。
打开csv文件可以看到该文档以表格的形式保存着所有图片的文件名和对应关键点的坐标。

单张图片和标签的读取
在进入正式主题之前,为了理解之后的代码,我们先来看下单张图片和对应标签的读取和可视化。
#--coding:utf-8--
import os
import pandas as pd
from skimage import io
import matplotlib.pyplot as plt
#用pandas库读取csv文件
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 65#行号
img_name = landmarks_frame.iloc[n, 0]
landmarks = landmarks_frame.iloc[n, 1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
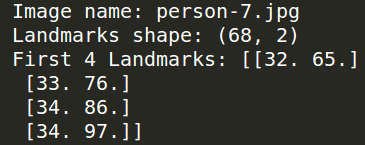
print('Image name: {}'.format(img_name))
print('Landmarks shape: {}'.format(landmarks.shape))
print('First 4 Landmarks: {}'.format(landmarks[:4]))
def show_landmarks(image, landmarks):
"""Show image with landmarks"""
plt.imshow(image)
plt.scatter(landmarks[:, 0], landmarks[:, 1], s=10, marker='.', c='r')
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/', img_name)),
landmarks)
plt.show()运行结果:

数据集的读取和处理
Pytorch数据读取的思路大致分为两步。
1、读取并处理数据集获得Dataset的子类。方法可以是自定义子类,也可以直接调用现有的类方法如ImageFolder。
2、调用Dataloader方法分批迭代读取数据
一、Dataset类
torch.utils.data.Dataset是一个抽象类,代表着一个数据集。在读取一个数据集时,我们应该定义一个该类的子类,并重写下列方法:
__len__:返回数据集的大小,有多少张图片
__getitem__:返回索引值对应的样本。从而dataset[i]就能得到对应的样本。
我们将在__init__函数中读取csv文件,而在__getitem__函数中读取图片。这样就不需要读取所有图片占用内存了,而是只在需要的时候读取对应索引的图片即可。
我们数据集的样本将以字典的形式保存{'image':image,'landmarks':landmarks}
数据处理的部分将会封装在transform类中,这个之后讲。
我们来看具体的代码:定义一个数据集并将其实例化,可视化前四个样本。
#--coding:utf-8--
'''
一个数据读取的实例。特征点坐标检测
'''
import os
import torch
import pandas as pd
from skimage import io, transform
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
def show_landmarks(image, l 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9873
9873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









