







HashMap是工作中经常使用到的集合类,当然面试中也会经常被问到。下面我们就来看下面试中常见的HashMap问题吧。
HashMap如何解决Hash碰撞的?
HashMap底层是有数组+链表+红黑树(jdk1.8)的数据结构来实现的。
当发生hash碰撞后,hashMap会把当前node(key-val)加到发生碰撞的hash位置的链表中。1.8后如果到达转化为红黑树的阀那么就会发生重新把链表转化为红黑树。如果添加的node对应hash位置发生碰撞的是TreeNode(红黑树节点),那么直接对添加到该红黑树(涉及到左旋右旋等)。
刚刚提到了红黑树,那么为什么jdk1.8要使用红黑树而不用val树或者B树而是要用红黑树呢?
此问题同时考验了你对val,b树和红黑树的理解。
1,首先val树,这个是一个比较严格的平衡二叉树,而红黑树相对没有那么严格,val在查找方面大多数情况快于红黑树但是在插入删除性能低于红黑树,而红黑树在查找、插入、删除几个方面都比较不错。因为HashMap增删查都使用的比较多,所以选择性能均衡的红黑树。
2,B树(这个一般数据库索引使用的比较多),B树不是二叉树,是一个平衡多路查找树,相同数据B树的整体高度一般会低于红黑树,因为每个节点可以存放多个数据。B树在数据库中索引使用的较多,他的层级低可以最大限度的较少磁盘IO。但是在每个节点中又需要遍历每个节点才能找到对应的数据。这样效率肯定没有红黑树效率高。
如果我用一个User作为Key,User的Id相同的Key不能重复该怎么做?
需要重写Key对象的hashCode方法和equals方法,因为HashMap在判断相同key的时候使用的下面这样的代码:
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
判断hash时候相等(hash就是key的hashCode然后进行位运算后的数字)并且equals为true,这个时候就会为相同key。
所以我们在hashCode和equals中判断id就可以实现了。
HashMap如何遍历以及原理?
HashMap本身不能被遍历。
这里首先说下java几种遍历的(不包括stream等)
1、遍历数组,使用下标获取,比如ArrayList
2、foreach,这个遍历我们需要实现Iterable接口
3、直接遍历相关迭代器。使用while进行hasNext判断。
HashMap提供了三种迭代器,分别是:KeyIterator(KeySet),,ValueIterator(Values),EntryIterator(EntrySet)。
其实三种遍历方式都是一样,只是返回的数据不同而已,第一种只返回key第二种只返回value,第三种返回Node。遍历代码主要逻辑代码:
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.value);
}
首先遍历数组然后next查找链表。由于hash里面的数组是一个hash散列,因此这样的遍历是没有先后顺序的,但是对于一个节点的链表中的数据有时候是有先后顺序(仅仅是没有resize和没有转化为红黑树的情况)。
遍历中使用next,那么说下红黑树节点是如何遍历的?
其实红黑树节点是集成了Node的,虽然是红黑树,但是同时也有一个链表在维护其中的前后数据关系,关于红黑树的前后关系维护,参考如下代码:
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}
代码分析可以知道红黑树的添加的时候首先判断父节点hash和当前节点hash的大小,如果小在左边,大在右边,这个就是红黑树,比较好理解。接下来看next逻辑:
1、如果当前父节点左右都没有数据,那么父node的next直接为当前node。
2、如果右边有数据,但是右边的子节点没数据,那么把父节点的next指向本节点的next,同时把父节点的next指向当前节点。(左边有数据右边没数据一样)。
3、如果右边有数据,但是右边的子节点有数据,这时和第2种情况一样,那么把父节点的next指向本节点的next,同时把父节点的next指向当前节点。
这样红黑树结构的链表就形成了。
链表和红黑树相互转化的时机?
HashMap内部有一个参数(TREEIFY_THRESHOLD=8),当hash桶位碰撞的数据的超过这个参数时会进行重构为红黑树(调用treeifyBin进行),
当红黑树中数据少于(UNTREEIFY_THRESHOLD = 6)这个参数时就会转化为链表。
描述下put的整个流程
- 首先对key进行hash算法算出hash。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 判断hash桶(table)是否为空,为空或者长度为0,那么进行resize初始化hash桶的数组。hash散列算法代码:
(n - 1) & hash
- 取key对应的hash数组位置时候不存在,不存在那么创建一个node把当前key-val放进去。
- 如果存在,那么取出来,判断hash是否和equals返回为ture,如果是就直接覆盖当前value。
- 如果是红黑树节点,那么直接添加到红黑树。
- 如果是链表形式的那么添加到链表
- 最后如果hash桶数据 达到阀值(负载因子*数组容量),那么进行resize。
HashMap扩容?为什么容量总是2的n次幂?为什么初始容量是16?
HashMap有默认的一个负载因子(0.75)。当size到达了capacity * load factor那么就会发生扩扩容,扩容的具体resize方法:
final Node<K,V>[] resize() {
...省略
//扩容机制,直接为原来的两倍。这个也是容量为什么是2的n次幂原因之一
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
...省略
//扩容后会对老的hash桶进行遍历把数据重新放入到新的hash桶。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
...省略
}
为什么是2的n次幂有两个原因:1,初始容量为2的n次幂。2,每次扩容为上次的两倍。
第二个原因我们已经知道了,现在主要分析为什么初始容量是2的n次幂。
先看下jdk的注释:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
初始容量必须是2的倍数。至于原因jdk其实也有。因为在计算hash数组的下标时候会进行这样的会运算(n-1)&hash。这个算法对于为什么容量是2^n非常重要。
下面我编写一个demo演示你就一目了然了。
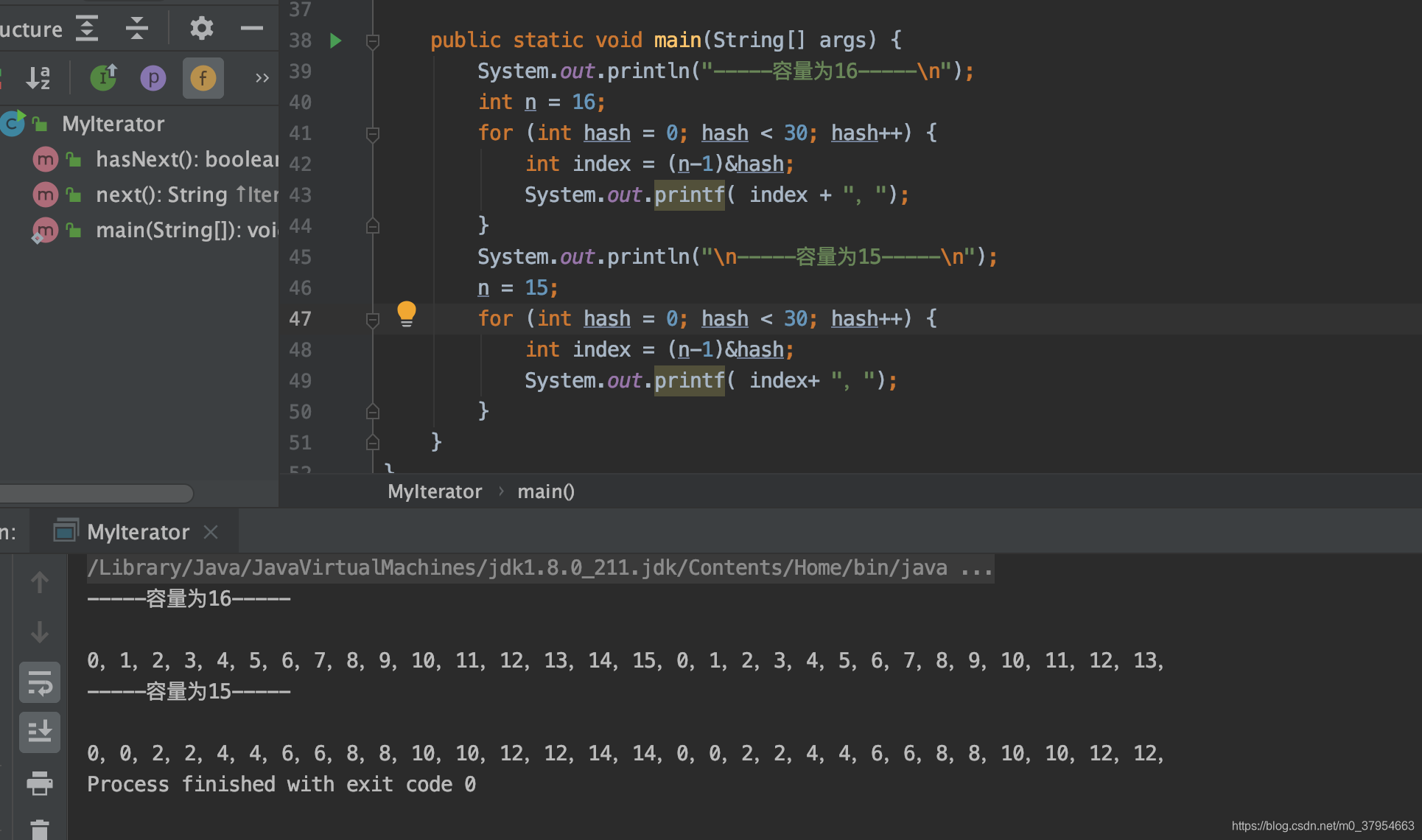
看见了吗?
如果容量为奇数那么(n-1)&hash公示计算出来的下标永远都是偶数,这个样就会有很多的hash桶位置不能得到利用。
问题又来了!那为什么不是其他偶数呢?比如12,14等。
这个就要分析计算机位运算的二进制了。2^n二进制表现形式位100000…00000这种形式,如果n-1那么就会位0111111…11111这种形式,这种形式的n-1与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
至于为什么初始容量是16,我理解这是一个统计学的问题,可能大多数情况16就够了,但是2,4,8又太少了。
加载因子为什么是0.75
先说说我的理解,当然不一定正确。
首先理解需要在不能是如果是0.5以及一下,那么就会浪费很多内存空间,比如16的时候容量到达8个就会扩容到32。这个过于浪费。
如果1的时候再扩容,那么势必会产生更多的hash碰撞。因此折中一个0.75.
下面是jdk对加载因子的解释和分析。
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
HashMap是有序的吗?为什么?说一说LinkedHashMap如何实现有序的?
HashMap不是有序的,因为HashMap遍历的时候是先对数组遍历,然后遍历链表的。hash本来就是无需的。遍历如下:
do {} while (index < t.length && (next = t[index++]) == null);
LinkedHashMap维护了一个链表来标示每个node的前后关系,不仅仅是hash冲入的时候才会有链表。
HashMap是线程安全的吗?ConcurrentHashMap底层实现原理?
HashMap不是线程安全的。
ConcurrentHashMap是线程安全的,他比HashTable更加高效,因为他的锁范围更加精细,锁粒度更加小。
那么ConcurrentHashMap是如何保证线程安全的呢?(1.8)
1,在设置值和判断空的时候使用CAS。比如在判断是否初始化数组的时候使用U.compareAndSwapObject。在获取hash散列的中的某个元素的时候使用U.getObjectVolatile,配合volatile。
2,在hash碰撞后的处理中使用synchronized锁住第一个节点。
1.8以前使用的是分段锁Segment分段锁(继承的ReentrantLock)。
















 8314
8314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











