







目录
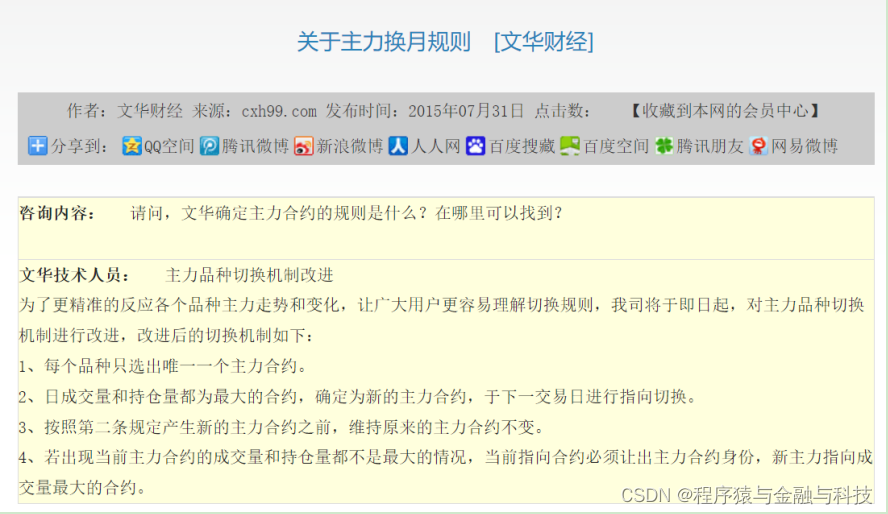
主力合约换月规则(文化财经)
主力合约计算逻辑

数据准备
本文以沪银为例,将沪银所有日数据文件放入一个文件夹中,文件名命名方式为 合约名_交割年份.csv
代码
def caculate_main_from_zero():
main_column_list = ['ticker','deliYear','tradeDate','openPrice','highestPrice','lowestPrice','closePrice','settlePrice','turnoverVol','turnoverValue','openInt']
# 放置品种所有日数据文件,文件名 合约名_交割年份.csv
pre_dir = r'E:/temp000/'
file_list = os.listdir(pre_dir)
# 将合约日文件合并到一个pd.DataFrame()中
df = pd.DataFrame()
for item in file_list:
file_path = pre_dir + item
item_str = item.split('.')[0]
ticker = item_str.split('_')[0]
deliYear = item_str.split('_')[1]
df_one = pd.read_csv(file_path,encoding='utf-8')
df_one['ticker'] = ticker
df_one['deliYear'] = deliYear
df = pd.concat([df,df_one])
pass
# 去除数据为空的数据
df.dropna(inplace=True)
if len(df)<=0:
print('所有合约数据为空')
return
# 按日期分组
df['o_date'] = pd.to_datetime(df['tradeDate'])
df.sort_values(by='o_date',ascending=True,inplace=True)
df['row_i'] = [i for i in range(len(df))]
df_group = df.groupby(by='o_date',as_index=False)
df_main = pd.DataFrame()
cur_main_ticker = None
cur_main_deliYear = None
pre_next_ticker = None
pre_next_deliYear = None
next_change_yeah = False
for name,group in df_group:
if len(group)<=1:
# 当日只有一条日数据,那该数据对应的合约即为主力合约
df_main = pd.concat([df_main,group.iloc[[0]]])
cur_main_ticker = group.iloc[0]['ticker']
cur_main_deliYear = group.iloc[0]['deliYear']
pass
else:
# 当日有多条日数据,分别计算成交量最大和持仓量最大的合约
# 成交量最大合约
df_vol = group.sort_values(by='turnoverVol',ascending=False)
# 持仓量最大合约
df_inte = group.sort_values(by='openInt',ascending=False)
# 如果成交量最大与持仓量最大为同一合约
if df_vol.iloc[0]['row_i'] == df_inte.iloc[0]['row_i']:
if not cur_main_ticker:
# 不存在前主力合约,那该合约即为主力合约
df_main = pd.concat([df_main,df_vol.iloc[[0]]])
cur_main_ticker = df_vol.iloc[0]['ticker']
cur_main_deliYear = df_vol.iloc[0]['deliYear']
pass
else:
if next_change_yeah:
# 有【预备主力合约】
if df_vol.iloc[0]['ticker'] == pre_next_ticker and df_vol.iloc[0]['deliYear']==pre_next_deliYear:
# 【预备主力合约】继昨日是成交量和持仓量同时最大后,今日还是成交量和持仓量最大,切换
df_main = pd.concat([df_main, df_vol.iloc[[0]]])
cur_main_ticker = pre_next_ticker
cur_main_deliYear = pre_next_deliYear
next_change_yeah = False
pass
else:
# 【预备主力合约】继昨日是成交量和持仓量同时最大后,今日不济,【预备主力合约】撤销
next_change_yeah = False
# ----------- 【当日成交量最大和持仓量最大 为同一个合约】 延续当前合约 start
# 存在前主力合约,判断该合约是否与前主力合约一致
if df_vol.iloc[0]['ticker'] == cur_main_ticker and df_vol.iloc[0][
'deliYear'] == cur_main_deliYear:
# 一致,主力合约延续,不切换
df_main = pd.concat([df_main, df_vol.iloc[[0]]])
pass
else:
# 不一致,主力合约延续,不切换;预备下一交易日切换
one_df = group.loc[(group['ticker'] == cur_main_ticker) & (
group['deliYear'] == cur_main_deliYear)].copy()
df_main = pd.concat([df_main, one_df.iloc[[0]]])
next_change_yeah = True
pre_next_ticker = df_vol.iloc[0]['ticker']
pre_next_deliYear = df_vol.iloc[0]['deliYear']
pass
# ----------- 【当日成交量最大和持仓量最大 为同一个合约】 延续当前合约 end
pass
pass
else:
# 无【预备主力合约】
# ----------- 【当日成交量最大和持仓量最大 为同一个合约】 延续当前合约 start
# 存在前主力合约,判断该合约是否与前主力合约一致
if df_vol.iloc[0]['ticker'] == cur_main_ticker and df_vol.iloc[0][
'deliYear'] == cur_main_deliYear:
# 一致,主力合约延续,不切换
df_main = pd.concat([df_main, df_vol.iloc[[0]]])
pass
else:
# 不一致,主力合约延续,不切换;预备下一交易日切换
one_df = group.loc[
(group['ticker'] == cur_main_ticker) & (group['deliYear'] == cur_main_deliYear)].copy()
df_main = pd.concat([df_main, one_df.iloc[[0]]])
next_change_yeah = True
pre_next_ticker = df_vol.iloc[0]['ticker']
pre_next_deliYear = df_vol.iloc[0]['deliYear']
pass
# ----------- 【当日成交量最大和持仓量最大 为同一个合约】 延续当前合约 end
pass
pass
else:
# 成交量最大和持仓量最大不是同一合约
if not cur_main_ticker:
df_main = pd.concat([df_main,df_vol.iloc[[0]]])
cur_main_ticker = df_vol.iloc[0]['ticker']
cur_main_deliYear = df_vol.iloc[0]['deliYear']
pass
else:
if df_vol.iloc[0]['ticker']==cur_main_ticker and df_vol.iloc[0]['deliYear']==cur_main_deliYear:
df_main = pd.concat([df_main,df_vol.iloc[[0]]])
elif df_inte.iloc[0]['ticker'] == cur_main_ticker and df_inte.iloc[0]['deliYear']==cur_main_deliYear:
df_main = pd.concat([df_main,df_inte.iloc[[0]]])
else:
df_main = pd.concat([df_main,df_vol.iloc[[0]]])
cur_main_ticker = df_vol.iloc[0]['ticker']
cur_main_deliYear = df_vol.iloc[0]['deliYear']
pass
pass
pass
pass
pass
if len(df_main) <=0:
print('主力合约条数为0')
return
df_main = df_main.loc[:,main_column_list].copy()
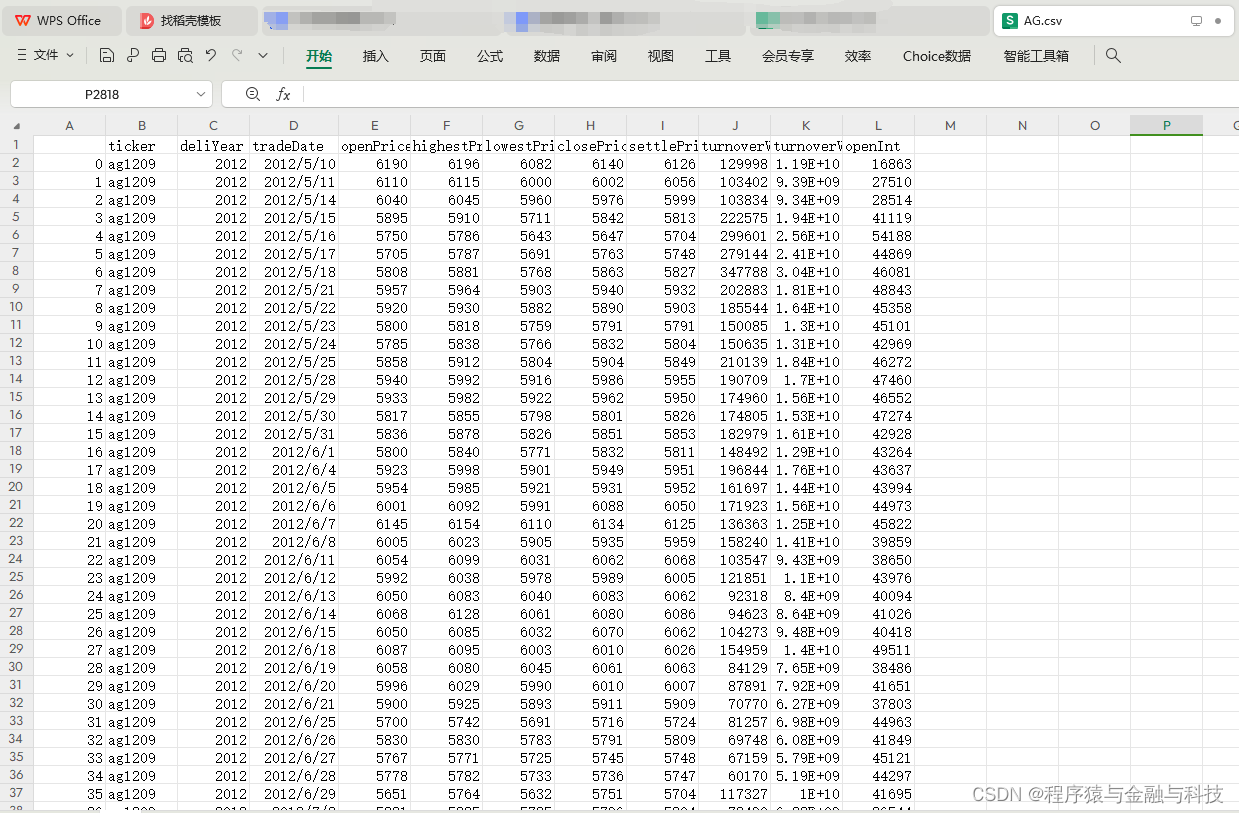
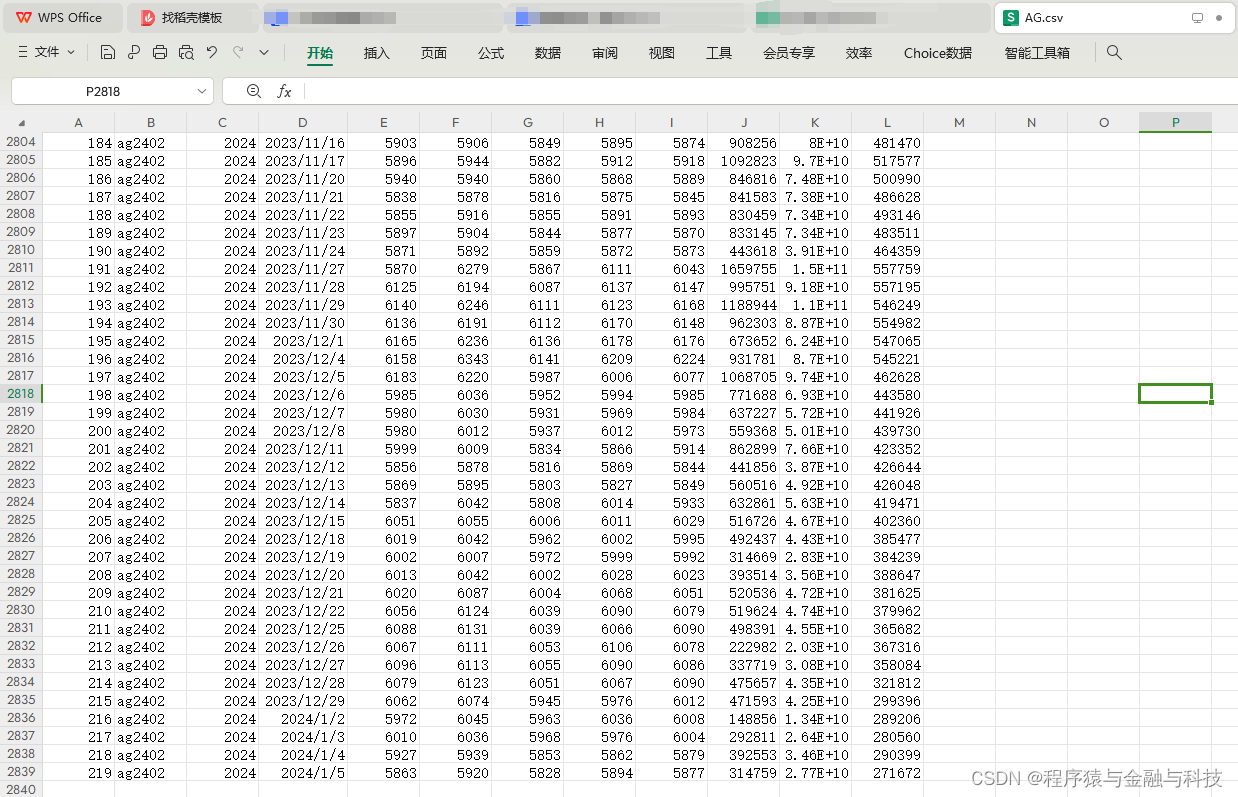
df_main.to_csv(pre_dir + 'AG.csv',encoding='utf-8')
pass结果存储为 AG.csv
 下载
下载
链接:https://pan.baidu.com/s/1X0O4ZtwX8_ZmdDJB4DJXTA
提取码:jjdz


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









