







语言模型是很多自然语言处理应用的基石,非常多自然语言处理应用的技术都是基于语言模型。
语言模型的任务就是预测每个句子在语言中出现的概率。
一、 评价方法
语言模型效果好坏的常用评价指标时复杂度(perplexity)。在一个测试集上得到的perplexity越低,说明建模的效果越好。计算perplexity值的公式如下:
p
e
r
p
l
e
c
i
t
y
(
S
)
=
p
(
w
1
,
w
2
,
w
3
,
.
.
.
w
m
)
=
1
p
(
w
1
,
w
2
,
w
3
,
.
.
.
w
m
)
m
=
∏
1
p
(
w
i
∣
w
1
,
w
3
,
.
.
.
w
i
−
1
)
m
perplecity(S) = p(w_1, w_2, w_3, ... w_m) =\sqrt[m]{\frac{1}{p(w_1, w_2, w_3, ... w_m)}} =\sqrt[m]{\prod \frac{1}{p(w_i|w_1, w_3, ... w_{i-1})}}
perplecity(S)=p(w1,w2,w3,...wm)=mp(w1,w2,w3,...wm)1=m∏p(wi∣w1,w3,...wi−1)1
在语言模型的训练中,通常采用 perplexity 的对数表达式:
l
o
g
(
p
e
r
p
l
e
x
i
t
y
(
S
)
)
=
−
1
m
∑
i
=
1
m
l
o
g
p
(
w
i
∣
w
1
,
w
3
,
.
.
.
w
i
−
1
)
log(perplexity(S)) = - \frac{1}{m} \sum_{i=1}^{m}logp(w_i|w_1, w_3, ... w_{i-1})
log(perplexity(S))=−m1i=1∑mlogp(wi∣w1,w3,...wi−1)
相比乘积求平方根的方式,使用加法的形式可以加速计算,同时避免概率乘积数值过小而导致浮点数向下溢出的问题。在数学上,log perplexity 可以看成真实分布与预测分部之间的交叉熵(Cross Entropy)。
在神经网络模型中,
p
(
w
i
∣
w
1
,
w
3
,
.
.
.
w
i
−
1
)
p(w_i|w_1, w_3, ... w_{i-1})
p(wi∣w1,w3,...wi−1) 分布通常是由一个 softmax 层产生的,TensorFlow 中提供了两个方便计算交叉熵的函数: tf.nn.softmax_cross_entropy_with_logits_v2 和 tf.nn.sparse_softmax_cross_entropy_with_logits。两个函数之间的区别可以看下面的例子:
import tensorflow as tf
# 假设词汇表的大小为3,语料包含两个单词 "2 0"
word_labels = tf.constant([2, 0])
# 假设模型对两个单词预测时,产生的logit 分别是[2.0, -1.0, 3.0] 和 [1.0, 0.0, -0.5]
# 注意这里的logit不是概率,因此他们不是0.0~1.0范围之间的数字。如果需要计算概率,
# 则需要调用 prob=tf.nn.softmax(logits)。但这里计算交叉熵的函数值直接输入logits即可。
predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]])
# 使用sparse_softmax_cross_entropy_with_logits计算交叉熵
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=word_labels, logits=predict_logits)
sess = tf.Session()
print(sess.run(loss))
# softmax_cross_entropy_with_logits与上面的函数相似,但是需要目标以概率分布的形式给出
word_prob_distribute = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]])
loss = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=word_prob_distribute, logits=predict_logits)
print(sess.run(loss))
# 由于 softmax_cross_entropy_with_logits 允许提供一个概率分布,因此在使用时有更大的
# 自由度。举个例子,一种叫label_smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,
# 将错误数据的概率设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果
word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]])
loss = tf.nn.softmax_cross_entropy_with_logits_v2(
labels=word_prob_smooth, logits=predict_logits)
print(sess.run(loss))
# 运行结果:
# [0.32656264 0.4643688 ]
# [0.32656264 0.4643688 ]
# [0.37656265 0.48936883]
二、神经语言模型
在PTB数据上使用循环神经网络建立语言模型。首先对文本数据进行预处理,从而使得它能作为神经网络的输入。然后对处理后的文本数据进行更加有效的batching来提升效率。最后实现通过循环神经网络对自然语言进行建模。
1. PTB数据集的预处理
数据的下载地址:http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
目前只需关心data文件夹下的三个文件:
ptb.test.txt # 测试集数据文件
ptb.train.txt # 训练集数据文件
ptb.valid.txt # 验证集数据文件
这三个数据文件中的数据已经过预处理,相邻单词之间用空格隔开。数据集共包含了9998个不同的单词词汇,加上稀有词语的特殊符号 和语句结束标记符在内,一共是10000个词汇。
为了将文本转化为模型可以读入的单词序列,需要将这10000个不同的词汇分别映射到0~9999之间的整数编号。下面的辅助程序首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
import codecs
import collections
from operator import itemgetter
RAW_DATA = '../data/simple-examples/data/ptb.train.txt' # 训练集数据文件
VACAB_OUTPUT = 'ptb.vocab' # 输出的词汇表文件
counter = collections.Counter() # 统计单词出现频率
with codecs.open(RAW_DATA, 'r', 'utf-8') as f:
for line in f:
for word in line.strip().split():
counter[word] += 1
# 按词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt]
# 需要在文本换行处加入句子结束符'<eos>'
sorted_words = ['<eos>'] + sorted_words
# 在PTB中,输入数据已经将低频词汇替换成了 '<unk>',因此不需要这一步骤
# sorted_words = ['<unk>', '<sos>', '<eos>'] + sorted_words
# if len(sorted_words) > 10000:
# sorted_words = sorted_words[:10000]
with codecs.open(VACAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + '\n')
在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
import codecs
RAW_DATA = '../data/simple-examples/data/ptb.test.txt' # 训练集数据文件
VOCAB = './data/ptb.vocab' # 之前生成的词汇表文件
OUTPUT_DATA = './data/ptb.train' # 将单词替换为单词比编号后的输出文件
# 读取词汇表,并简历词汇到单词编号的映射
with codecs.open(VOCAB, 'r', 'utf-8') as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))}
# 如果出现了被删除的低频词,则替换为'<unk>'
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id['<unk>']
fin = codecs.open(RAW_DATA, 'r', 'utf-8')
fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8')
for line in fin:
words = line.strip().split() + ['<eos>'] # 读取单词并添加<eos>结束符
# 将每个单词替换为词汇表中的编号
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
经过以上处理,得到三个文件 ptb.train、ptb.valid、ptb.test(一堆都是数字的文件,每个数字代表一个字符)
2. PTB数据的batching方法
在文本数据中,由于每个句子的长度不同,又无法像图像一样调整到固定维度,因此在对文本数据进行batching时需要采取一些特殊操作。最常见的办法时使用填充(padding)将同一bath内的句子长度补齐。在PTB数据集中,每个句子并非随机抽取的文本,而是在上下文之间有关联的内容。语言模型为了利用上下文信息,必须将前面句子的信息传递到后面的句子。为了实现这个目标,在PTB上下文有关联的数据集上,通常采用另一种batching方法。
将长序列切割为固定长度的子序列。循环神经网络在处理玩一个子序列后,它最终的隐藏状态将复制到下一个序列中作为初始值,这样在前向计算时,效果等同于一次性顺序地读取了整个文档;而在反向传播时,梯度则只在每个子序列内部传播。
为了利用计算时的并行能力,希望每一次计算可以对多个句子进行并行处理,同时又要尽量保证batch之间的上下文连续。解决方案是,先将整个文档分成若干连续段落,再让batch中的每一个位置负责其中一段。例如,如果batch大小时4,则先将这个文档平均分成4个子序列,让batch中的每一个位置负责其中一个子序列,这样每个子文档内部的所有数据仍可以被顺序处理。
下面的代码从文件中读取数据,并按上面介绍的方案将数据整理成batch。由于PTB数据集比较小,因此可以直接将这个数据集一次性读入内存。
import numpy as np
import tensorflow as tf
TRAIN_DATA = './data/ptb.train' # 训练数据路径
EVAL_DATA = './data/ptb.valid' # 验证数据路径
TEST_DATA = './data/ptb.test' # 测试数据路径
TRAIN_BATCH_SIZE = 20 # 训练数据batch的大小
TRAIN_NUM_STEP = 35 # 训练数据截断长度
# 从文件中读取数据,并返回包含单词编号的数组
def read_data(file_path):
with open(file_path, 'r') as fin:
# 将整个文档读进一个长字符串
id_string = ' '.join([line.strip() for line in fin.readlines()])
id_list = [int(w) for w in id_string.split()] # 将读取的单词编号转为整数
return id_list
def make_batch(id_list, batch_size, num_step):
# 计算总的batch数量,每个batch包含的单词数量是batch_size * num_step
num_batches = (len(id_list) - 1) // (batch_size * num_step)
# 将数据整理成一个维度为[batch_size, num_batches * num_step]的二维数组
data = np.array(id_list[: num_batches * batch_size * num_step])
data = np.reshape(data, [batch_size, num_batches * num_step])
# 沿着第二个维度将数据切分成num_batches个batch,存入一个数组
data_batches = np.split(data, num_batches, axis=1)
# 重复上述操作,但是每个位置向右移动一位,这里得到的时RNN每一步输出所需要预测的下一个单词
label = np.array(id_list[1: num_batches * batch_size * num_step + 1])
label = np.reshape(label, [batch_size, num_batches * num_step])
label_batches = np.split(label, num_batches, axis=1)
# 返回一个长度为num_batches的数组,其中每一项包含一个data矩阵和一个label矩阵
return list(zip(data_batches, label_batches))
3.基于循环神经网络的神经语言模型
词向量层
在输入层,每一个单词用一个实数向量表示,这个向量被称为“词向量”(word embedding)。词向量可以形象地理解为将词汇表嵌入到一个固定维度的实数空间里。将单词编号转化为词向量主要有两大作用。
- 降低输入的维度。如果不适用词向量层,而直接将单词以one-hot vector的形式输入循环神经网络,那么输入的维度大小将与词汇表大小相同,通常在10000以上。而词向量的维度通常在200~1000之间,这将大大减少循环神经网络的参数数量与计算量。
- 增加语义信息。简单的单词编号是不包含任何语义信息的。两个单词之间编号相近,并不意味着它们的含义有任何关联。而词向量将稀疏的编号转化为稠密的向量表示,这使得词向量有可能包含更为丰富的信息。
假设词向量的维度是EMB_SIZE,词汇表的大小为VOCAB_SIZE,那么所有单词的词向量可以放入一个大小为VOCAB_SIZExEMB_SIZE的矩阵内。在读取词向量时,可以使用 tf.nn.embedding_lookup方法:
embedding = tf.get_variable("embedding", [VOCAB_SIZE, EMB_SIZE])
# 输出的矩阵比输入数据多一个维度, 新增维度的大小是EMB_SIZE. 在语言模型中, 一般input_data的维度是
# batch_size x num_steps, 而输出的input_embedding的维度时batch_size x num_steps x EMB_SIZE
input_embedding = tf.nn.embedding_lookup(embedding, input_data)
Softmax层
Softmax层的作用是将循环神经网络的输出转化为一个单词表中每个单词的输出概率。模型训练通常并不关心概率的具体取值,而更关心最终的log perplexity,因此可以调用 tf.nn.sparse_softmax_cross_entropy_with_logits 方法直接从logits计算 log perplexity作为损失函数。
通过共享参数减少参数数量
以下是完整的训练程序:
import numpy as np
import tensorflow as tf
TRAIN_DATA = './data/ptb.train' # 训练数据路径
EVAL_DATA = './data/ptb.valid' # 验证数据路径
TEST_DATA = './data/ptb.test' # 测试数据路径
HIDDEN_SIZE = 300 # 隐藏层规模
NUM_LAYERS = 2 # 深层循环神经网络中LSTM结构的层数
VOCAB_SIZE = 10000 # 词典规模
TRAIN_BATCH_SIZE = 20 # 训练数据batch的大小
TRAIN_NUM_STEP = 35 # 训练数据截断长度
EVAL_BATCH_SIZE = 1 # 测试数据batch的大小
EVAL_NUM_STEP = 1 # 测试数据截断长度
NUM_EPOCH = 5 # 使用训练数据的轮数
LSTM_KEEP_PROB = 0.9 # LSTM节点不被dropout的概率
EMBEDDING_KEEP_PROB = 0.9 # 词向量不被dropout的概率
MAX_GRAD_NORM = 5 # 用于控制梯度膨胀的梯度大小上限
SHARE_EMB_AND_SOFTMAX = True # 在softmax层和词向量层之间共享参数
# 通过一个PTBModel来描述模型,这样方便维护循环神经网络中的状态
class PTBModel(object):
def __init__(self, is_training, batch_size, num_steps):
# 记录使用的batch大小和截断长度
self.batch_size = batch_size
self.num_steps = num_steps
# 定义每一步的输出和预期输出,两个的维度都是[batch_size, num_steps]
self.input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
self.targets = tf.placeholder(tf.int32, [batch_size, num_steps])
# 定义使用LSTM结构为循环结构且使用dropout的深层循环神经网络
dropout_keep_prob = LSTM_KEEP_PROB if is_training else 1.0
lstm_cells = [
tf.nn.rnn_cell.DropoutWrapper(
tf.nn.rnn_cell.LSTMCell(HIDDEN_SIZE),
output_keep_prob=dropout_keep_prob
) for _ in range(NUM_LAYERS)
]
cell = tf.nn.rnn_cell.MultiRNNCell(lstm_cells)
# 通过zero_state函数获取初始状态
self.initial_state = cell.zero_state(batch_size, tf.float32)
# 初始化最初的状态,即全零的向量。这个量只在每个epoch初始化第一个batch时使用
embedding = tf.get_variable('embedding', [VOCAB_SIZE, HIDDEN_SIZE])
# 将输入单词转换为词向量
inputs = tf.nn.embedding_lookup(embedding, self.input_data)
# 只在训练时使用dropout
if is_training:
inputs = tf.nn.dropout(inputs, EMBEDDING_KEEP_PROB)
# 定义输出列表。在这里先将不同时刻LSTM结构的输出收集起来,再一起提供给softmax层
outputs = []
state = self.initial_state
with tf.variable_scope('RNN'):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
cell_output, state = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
# 把输出队列展开成[batch, hidden_size * num_steps]的形状,
# 然后再reshape成[batch*num_steps, hidden_size]的形状
output = tf.reshape(tf.concat(outputs, 1), [-1, HIDDEN_SIZE])
# softmax层:将RNN在每个位置上的输出转化为各个单词的logits
if SHARE_EMB_AND_SOFTMAX:
weight = tf.transpose(embedding)
else:
weight = tf.get_variable('weight', [HIDDEN_SIZE, VOCAB_SIZE])
bias = tf.get_variable('bias', [VOCAB_SIZE])
logits = tf.matmul(output, weight) + bias
# 定义交叉熵损失函数和平均损失
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.reshape(self.targets, [-1]),
logits=logits
)
self.cost = tf.reduce_sum(loss) / batch_size
self.final_state = state
# 只在训练模型时定义反向传播操作
if not is_training: return
trainable_variables = tf.trainable_variables()
# 控制梯度大小,定义优化方法和训练步骤
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, trainable_variables), MAX_GRAD_NORM)
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0)
self.train_op = optimizer.apply_gradients(zip(grads, trainable_variables))
# 使用给定的模型model在数据data上运行train_op并返回再全部数据上的perplexity值
def run_epoch(session, model, batches, train_op, output_log, step):
# 计算平均perplexity的辅助变量
total_costs = 0.0
iters = 0
state = session.run(model.initial_state)
# 训练一个epoch
for x, y in batches:
# 在当前batch上运行train_op并计算损失值,交叉熵损失函数计算的就是下一个单词为给定单词的概率
cost, state, _ = session.run(
[model.cost, model.final_state, train_op],
{model.input_data: x, model.targets: y, model.initial_state: state}
)
total_costs += cost
iters += model.num_steps
# 只有在训练时输出日志
if output_log and step % 100 == 0:
print('After %d steps, perplexity is %.3f' % (step, np.exp(total_costs / iters)))
step += 1
# 返回给定模型在给定数据上的perplexity值
return step, np.exp(total_costs / iters)
# 从文件中读取数据,并返回包含单词编号的数组
def read_data(file_path):
... # 见预处理代码
def make_batch(id_list, batch_size, num_step):
... # 见预处理代码
def main():
# 定义初始化函数
initializer = tf.random_uniform_initializer(-0.05, 0.05)
# 定义训练用的循环神经网络模型
with tf.variable_scope('language_model', reuse=None, initializer=initializer):
train_model = PTBModel(True, TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
# 定义测试用的循环神经网络模型。它与train_model公用参数,但是没有dropout
with tf.variable_scope('language_model', reuse=True, initializer=initializer):
eval_model = PTBModel(False, EVAL_BATCH_SIZE, EVAL_NUM_STEP)
# 训练模型
with tf.Session() as sess:
tf.global_variables_initializer().run()
train_batches = make_batch(read_data(TRAIN_DATA), TRAIN_BATCH_SIZE, TRAIN_NUM_STEP)
eval_batches = make_batch(read_data(EVAL_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
test_batches = make_batch(read_data(TEST_DATA), EVAL_BATCH_SIZE, EVAL_NUM_STEP)
step = 0
for i in range(NUM_EPOCH):
print('In iteration: %d' % (i + 1))
step, train_pplx = run_epoch(sess, train_model, train_batches, train_model.train_op, True, step)
print('Epoch: %d Train Perplexity: %.3f' % (i + 1, train_pplx))
_, eval_pplx = run_epoch(sess, eval_model, eval_batches, tf.no_op(), False, 0)
print('Epoch: %d Eval Perplexity: %.3f' % (i + 1, eval_pplx))
_, test_pplx = run_epoch(sess, eval_model, test_batches, tf.no_op(), False, 0)
print('Test Perplexity: %.3f' % test_pplx)
if __name__ == '__main__':
main()
运行以上程序可以得到类似如下的输出结果:
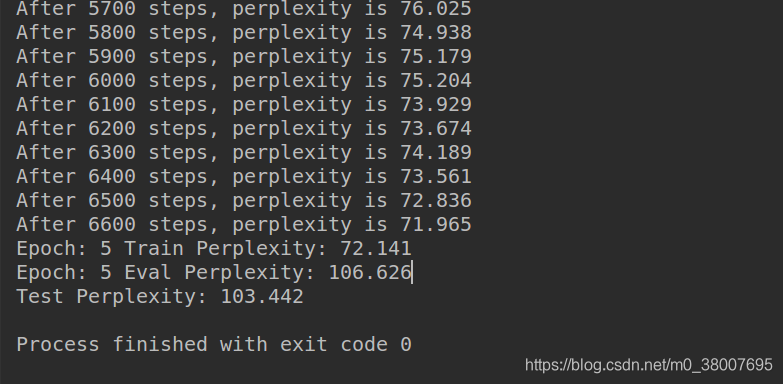
这段代码已经放到GitHub上,如需要可进行下载代码。


















 2814
2814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











