






之前几篇文章我介绍了三种O(n²)的排序算法《O(n²)的三个排序算法》(选择排序、插入排序和冒泡排序)以及它们的优化,然后顺便还写了一篇希尔排序的文章《插入排序的优化之希尔排序》,但是其实用的比较多的还是直接插入排序,它们比较适合于小规模数据的排序 。下面我将记录时间复杂度为nlog(n)的几种排序算法之一 —— 归并排序算法,这种排序算法适合大规模的数据排序,比之前的O(n²)的三种排序算法更为常用,在学习之前我们可以先对比一下nlog(n)和n²是什么概念。
nlog(n)比n²快多少
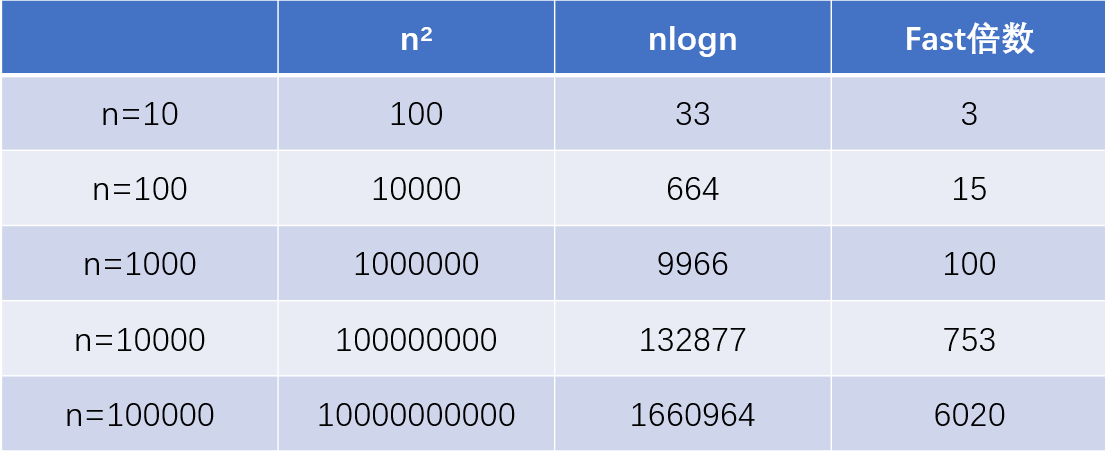
我们可以看出,在n越来越大的时候,nlogn比n²快上千倍甚至上万倍,所以nlogn的排序算法相对于n²的排序算法在大规模的数据的情况下更常用,也更实用。
归并排序 MergeSort
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
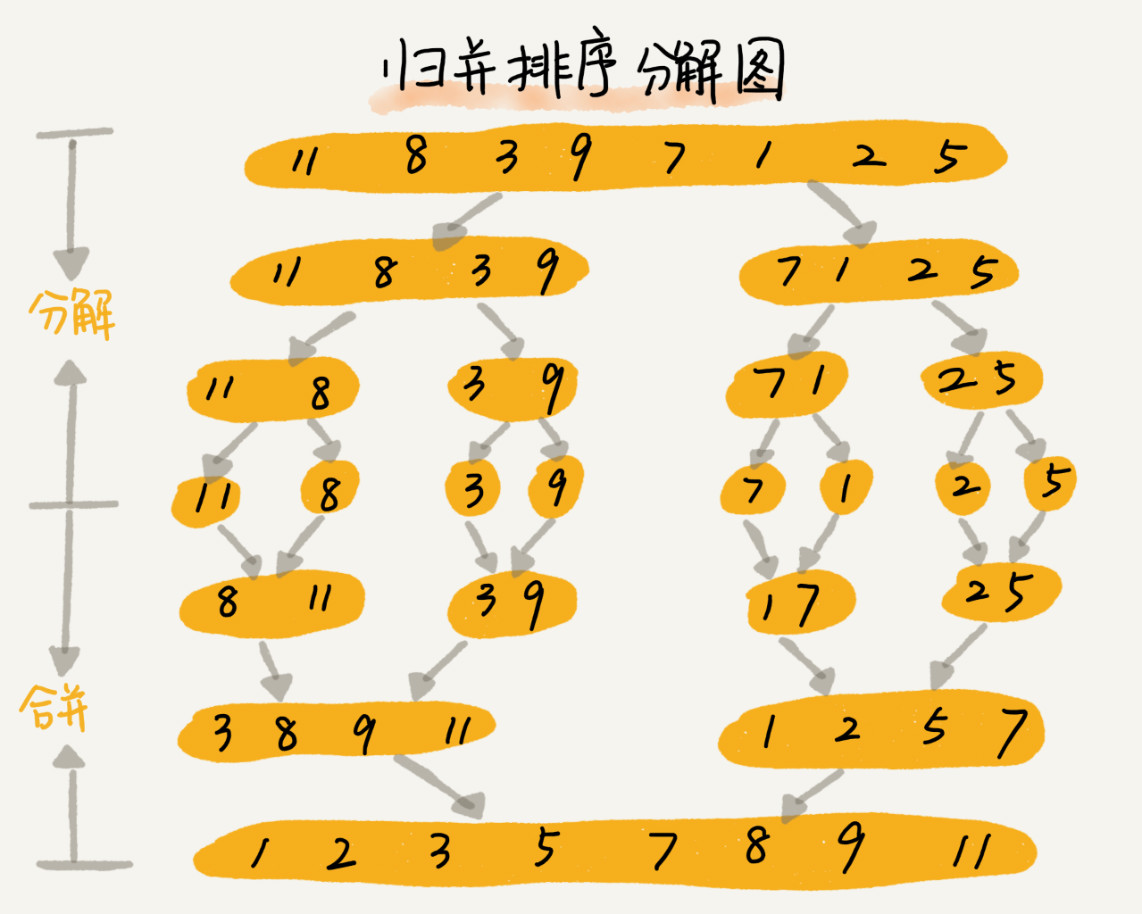
归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。 分治思想跟递归思想很像,分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
通过上面的示意图,很容易可以写出对应的伪代码:
// 归并排序算法, A 是数组,n 表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用函数
merge_sort_c(A, p, r) {
// 递归终止条件
if p >= r then return
// 取 p 到 r 之间的中间位置 q
q = (p+r) / 2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将 A[p...q] 和 A[q+1...r] 合并为 A[p...r]
merge(A[p...r], A[p...q], A[q+1...r])
}
可以发现,其实最重要的两个步骤就是分支递归的过程和合并的过程,那么是如何合并的呢?
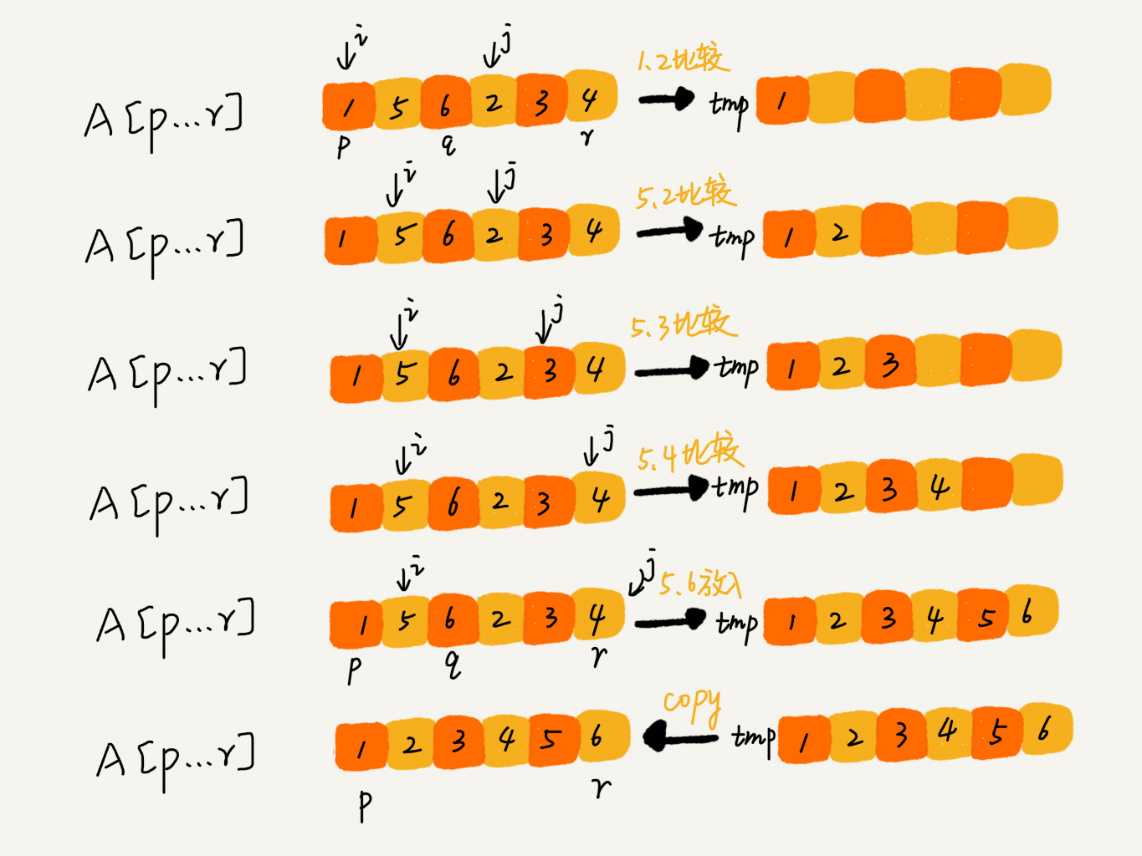
下面是Java版本的伪码
public static void mergeSort(int[] arr){
mergeChild(arr, 0, arr.length-1);
}
//使用递归进行归并排序,对arr[start, end]的范围进行排序
private static void mergeChild(int[] arr, int start, int end){
//代表处理的数据集为空
if(start >= end) return;
int mid = (end - start) / 2 + start;
mergeChild(arr, start, mid);
mergeChild(arr, mid + 1, end);
merge(arr, start, mid, end);
}
//将arr[start ... mid]和arr[mid+1 ... end] 两部分进行归并
private static void merge(int[] arr, int start, int mid, int end) {
//创建临时数组
int[] aux = new int[end - start + 1];
System.arraycopy(arr, start, aux, 0, end - start + 1);
int i = start;
int j = mid + 1;
for (int k = start; k <= end ; k++) {
//左部分的已经归并完毕
if(i > mid){
arr[k] = aux[j - start];
j++;
//右部分的已经归并完毕
}else if(j > end){
arr[k] = aux[i - start];
i++;
}else if(aux[i - start] < aux[j - start]){
arr[k] = aux[i - start];
i++;
}else{
arr[k] = aux[j - start];
j++;
}
}
}
算法稳定性
归并排序是稳定的排序算法吗?归并排序稳不稳定关键要看 merge() 函数,也就是两个有序子数组合并成一个有序数组的那部分代码。 由于是直接拷贝进了临时数组,这样就保证了值相同的元素,在合并前后的先后顺序不变。所以,归并排序是一个稳定的排序算法。
最好和最坏情况
从我们的原理分析和伪代码可以看出,归并排序的执行效率与要排序的原始数组的有序程度无关,所以其时间复杂度是非常稳定的,不管是最好情况、最坏情况,还是平均情况,时间复杂度都是 O(nlogn)。
归并排序的优化
通过测试我们发现如果是对大批的随机数进行排序的话,相对于插入排序性能有百倍或者千倍的优势,如如我现在对50万个随机数用归并和插入进行排序:
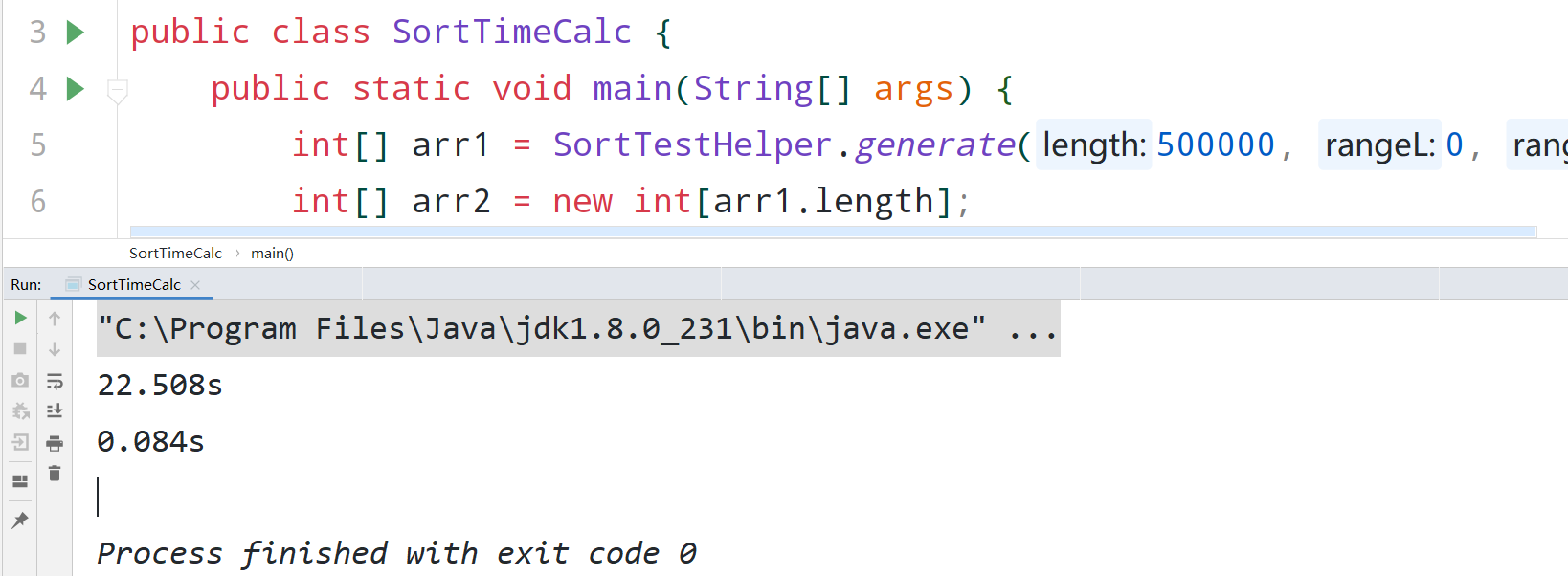
可以看出,归并排序的速度快280倍。可是如果是排接近有序的数组呢?我们知道,在插入排序最优的情况下就是已经有序,此时时间复杂度为O(n),那么归并排序并不能达到O(n)的时间复杂度。现在对1000万个接近有序的数进行排序,只交换十次:
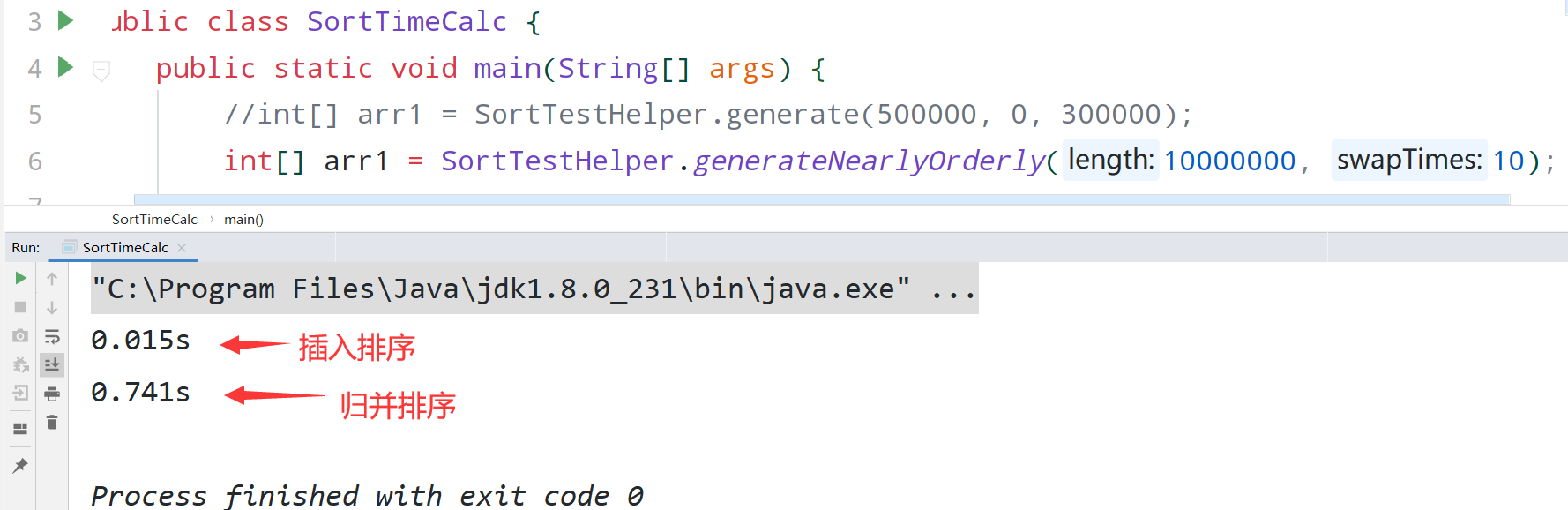
所以我们需要对归并排序进行优化:
我们可以回顾一下归并排序的过程,假设在merge之前,如果arr[mid] <= arr[mid+1],那么是不是说明已经有序了呢?因为我们保证了arr[start, mid]是有序的,arr[mid+1, end]也是有序的。例如:[1,2 , 3 , 4, 5]、[6, 7, 8, 9, 10],如果arr[mid] <= arr[mid+1],那么此时数组已经有序,无需执行merge操作。
优化后的代码如下:
public static void mergeSort(int[] arr){
mergeChild(arr, 0, arr.length-1);
}
//使用递归进行归并排序,对arr[start, end]的范围进行排序
private static void mergeChild(int[] arr, int start, int end){
//代表我们处理的数据集为空
if(start >= end) return;
int mid = (end - start) / 2 + start;
mergeChild(arr, start, mid);
mergeChild(arr, mid + 1, end);
//优化掉不必要的merge操作
if(arr[mid] > arr[mid] + 1)
merge(arr, start, mid, end);
}
//将arr[start ... mid]和arr[mid+1 ... end] 两部分进行归并
private static void merge(int[] arr, int start, int mid, int end) {
//创建临时数组
int[] aux = new int[end - start + 1];
System.arraycopy(arr, start, aux, 0, end - start + 1);
int i = start;
int j = mid + 1;
for (int k = start; k <= end ; k++) {
//左部分的已经归并完毕
if(i > mid){
arr[k] = aux[j - start];
j++;
//右部分的已经归并完毕
}else if(j > end){
arr[k] = aux[i - start];
i++;
}else if(aux[i - start] < aux[j - start]){
arr[k] = aux[i - start];
i++;
}else{
arr[k] = aux[j - start];
j++;
}
}
}
上面是第一个优化点,其实还能优化,就是我们在递归到最后数据量非常小的时候我们直接使用插入排序来解决排序问题。
public static void mergeSort(int[] arr){
mergeChild(arr, 0, arr.length-1);
}
//使用递归进行归并排序,对arr[start, end]的范围进行排序
private static void mergeChild(int[] arr, int start, int end){
//代表我们处理的数据集为空
//if(start >= end) return;
if(end - start <= 15){
insertionSort(arr, start, end);
return;
}
int mid = (end - start) / 2 + start;
mergeChild(arr, start, mid);
mergeChild(arr, mid + 1, end);
//优化点:优化掉不必要的merge操作
if(arr[mid] > arr[mid] + 1)
merge(arr, start, mid, end);
}
//将arr[start ... mid]和arr[mid+1 ... end] 两部分进行归并
private static void merge(int[] arr, int start, int mid, int end) {
//创建临时数组
int[] aux = new int[end - start + 1];
System.arraycopy(arr, start, aux, 0, end - start + 1);
int i = start;
int j = mid + 1;
for (int k = start; k <= end ; k++) {
//左部分的已经归并完毕
if(i > mid){
arr[k] = aux[j - start];
j++;
//右部分的已经归并完毕
}else if(j > end){
arr[k] = aux[i - start];
i++;
}else if(aux[i - start] < aux[j - start]){
arr[k] = aux[i - start];
i++;
}else{
arr[k] = aux[j - start];
j++;
}
}
}
//优化点:在数据规模小的时候直接使用插入排序(对arr[start, end]范围的插入数据排序)
private static void insertionSort(int[] arr, int start, int end) {
for (int i = start + 1; i <= end; i++) {
int e = arr[i];
int j;
for (j = i; j > start && arr[j - 1] < e; j--) {
arr[i] = arr[j - 1];
}
arr[j] = e;
}
}
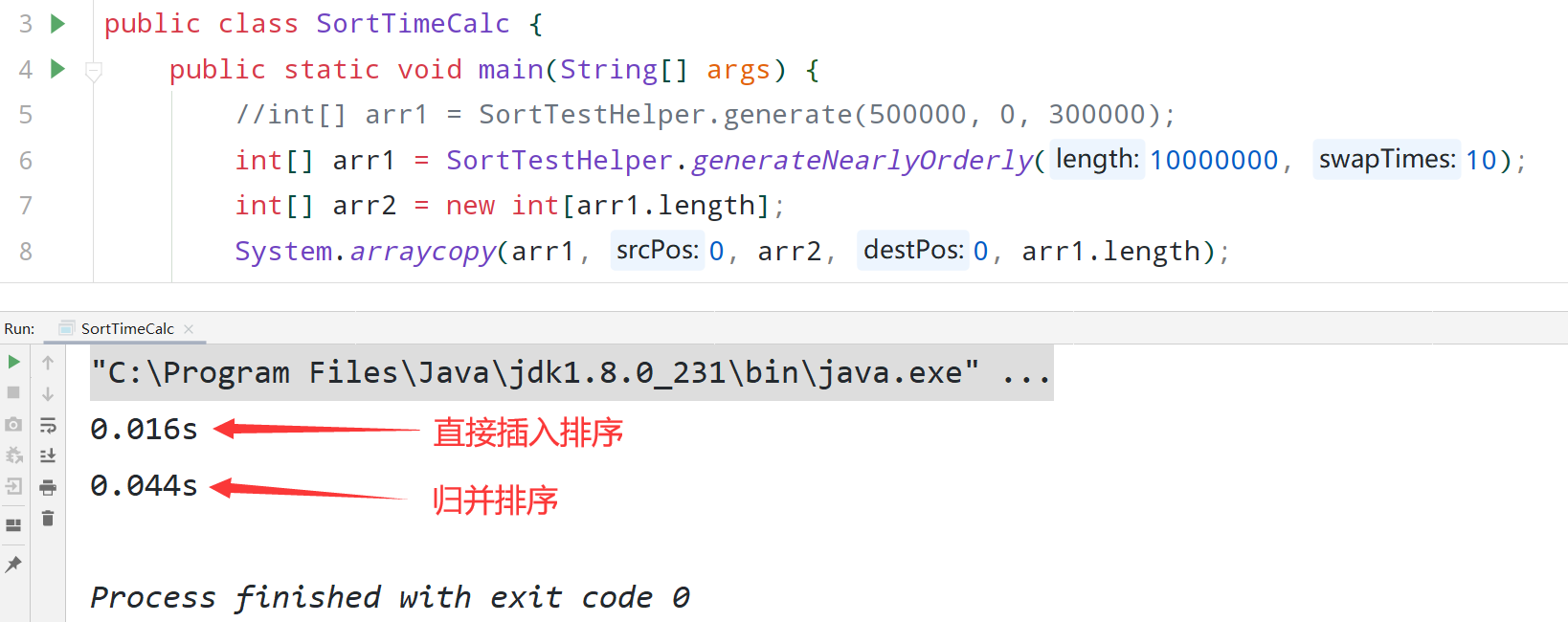
经过上面的两个优化步骤之后,直接插入排序和归并排序在排序大量几乎有序的数组的时候,效率并差不了多少
归并排序空间复杂度
归并排序的时间复杂度任何情况下都是 O(nlogn),看起来非常优秀。 即便是快速排序,最坏情况下,时间复杂度也是 O(n²),但是归并排序并没有像快排那样,应用广泛,这是为什么呢?因为它有一个致命的弱点,那就是归并排序不是原地排序算法。
实际上,递归代码的空间复杂度并不能像时间复杂度那样累加。尽管每次合并操作都需要申请额外的内存空间,但在合并完成之后,临时开辟的内存空间就被释放掉了。在任意时刻,CPU 只会有一个函数在执行,也就只会有一个临时的内存空间在使用。临时内存空间最大也不会超过 n 个数据的大小,所以空间复杂度是 O(n)。
但是在如今更多的场景是时间换空间,所以归并排序时间复杂度稳定为nlog(n),空间复杂度稳定为O(n),而且是稳定排序算法,用处还是挺多的。
自底向上的归并排序
如下图,我们先把数组划分为4部分,排序后划分为4部分进行归并为两部分,再把两部分归并为一部分:
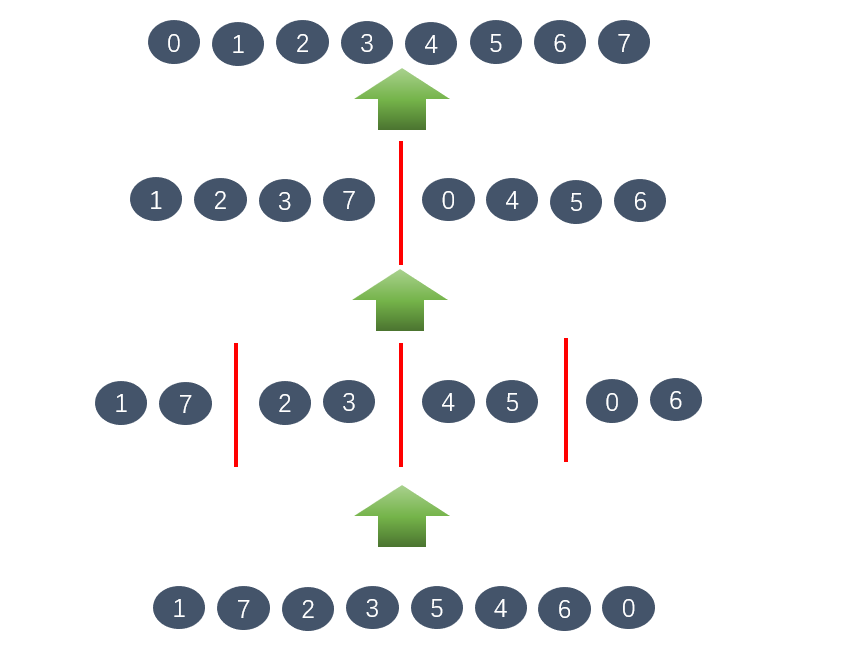
这样就免去了递归的过程,而是一个迭代的过程。
public static void bottomUpMergeSort(int[] arr){
for (int size = 1; size <= arr.length; size += size) {
//i + size < arr.length 防止越界
for (int i = 0; i + size < arr.length; i += size + size) {
int index = i + size + size - 1;
//取i + size + size - 1 和 arr.length的最小值
merge(arr, i, i + size - 1, index > arr.length ? arr.length - 1: index);
}
}
}
//将arr[start ... mid]和arr[mid+1 ... end] 两部分进行归并
private static void merge(int[] arr, int start, int mid, int end) {
//创建临时数组
int[] aux = new int[end - start + 1];
System.arraycopy(arr, start, aux, 0, end - start + 1);
int i = start;
int j = mid + 1;
for (int k = start; k <= end ; k++) {
//左部分的已经归并完毕
if(i > mid){
arr[k] = aux[j - start];
j++;
//右部分的已经归并完毕
}else if(j > end){
arr[k] = aux[i - start];
i++;
}else if(aux[i - start] < aux[j - start]){
arr[k] = aux[i - start];
i++;
}else{
arr[k] = aux[j - start];
j++;
}
}
}
上面的代码其实还没有加入之前的两个优化点,加上之后效果更好。这种归并排序有一个很明显的特点就是没有使用数组的特性,即没有使用数组下标,正因为如此,这样的自底向上的归并排序可以对链表进行排序。


- 本文作者: Tim
- 本文链接: https://zouchanglin.cn/2020/04/09/507263713.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 许可协议。转载请注明出处!















 8672
8672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









