







1.什么是Hash表?
其实Hash表存储的位置,是连续的存储空间,和数组一样。
链表不是连续的存储空间。
以链地址法为例:
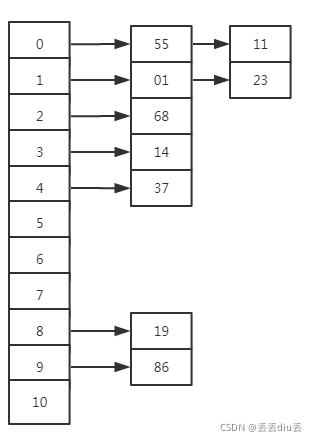
它是通过Hash函数,直接根据Key计算出数据存储的地址,一个数组下标index。
- 1.根据key,计算index = Hash(key);
- 2.如果数组[index]不为空,则查找成功(当然链地址法还要比较equal)
- 为空,则查找失败
2.Hash冲突怎么办?
链地址法
- 拉链法
公共溢出区法
- 找一个公共的地方存放冲突的key-value。(如果冲突的数量很多,查找效率就不行了)
线性探测法
- f(key)冲突时,则计算(f(key)+1)/mod是否冲突?
3.如果用Hash进行分布式存储会有什么弊端?
如果出现某台机器宕机,或增加1台新机器时。
- 1.不做任何改变,宕机的数据就无法恢复了,新增的机器也没法进行应用了;
- 2.重哈希,因为桶的数量会改变,所有的值都将重新映射。这会带来问题:
- 问题1:rehash时,所有key重新映射,对于大并发时,是灾难性的事,缓存中的数据都将失效,请求全部涌向数据库,可能会数据库崩溃;
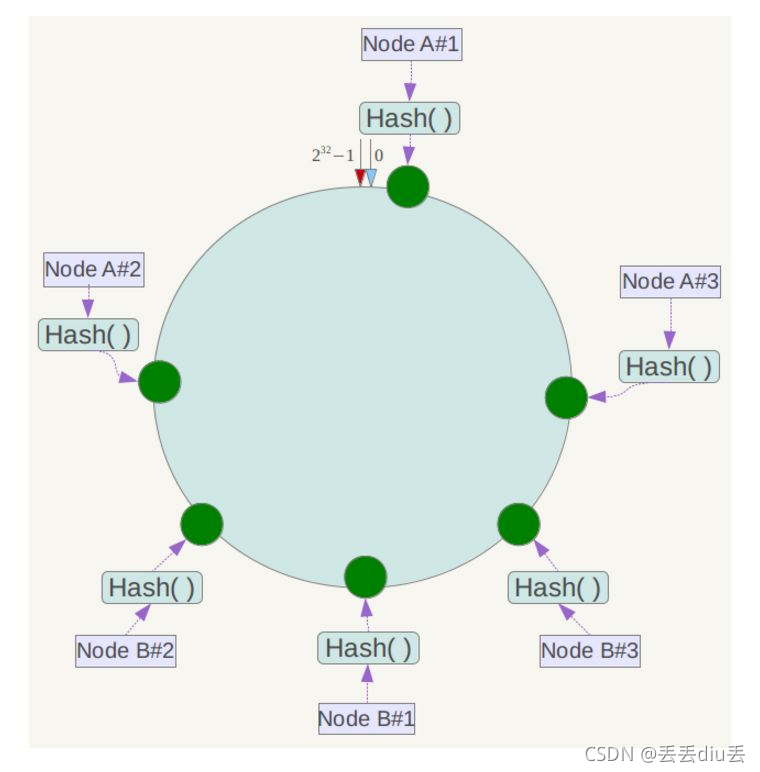
4.一致性哈希?
1.实现步骤
- 1.所有的存储节点,对2^32取模, 并将其配置到0-2^32-1的虚拟圆上。
- 2.对所有的Key,也是对对2^32取模, 并将其映射到相同的圆上。
- 3.从Key的数据映射位置开始顺时针查找,找到的第1个存储节点,把数据存在节点上。如果超过2^32仍然找不到,就会保存到第一台机器上。
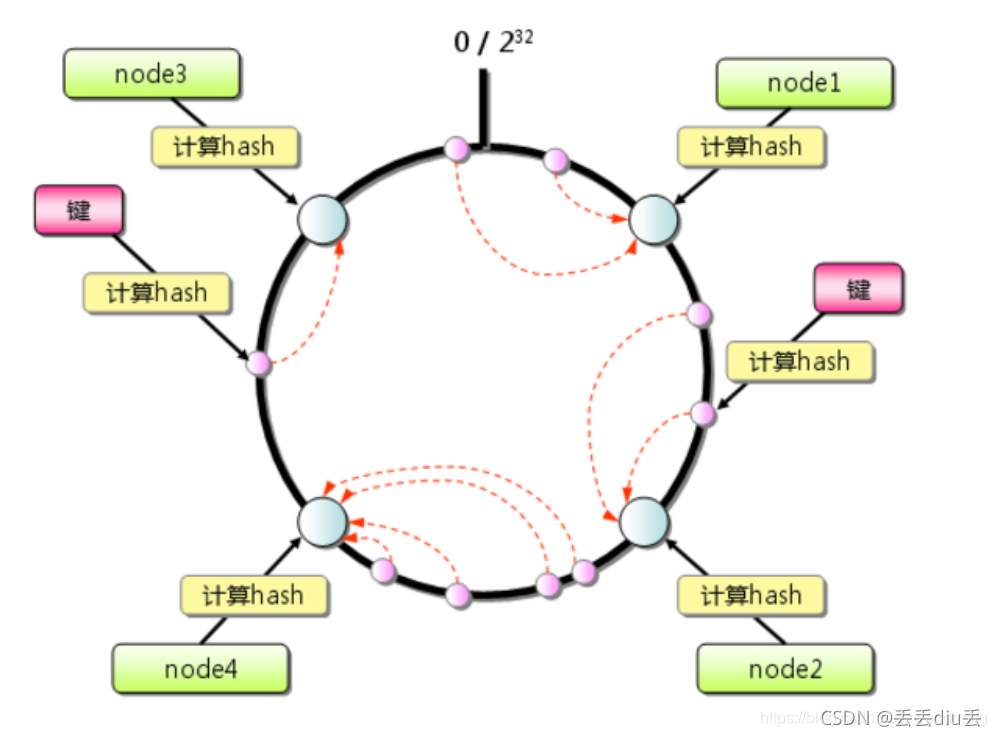
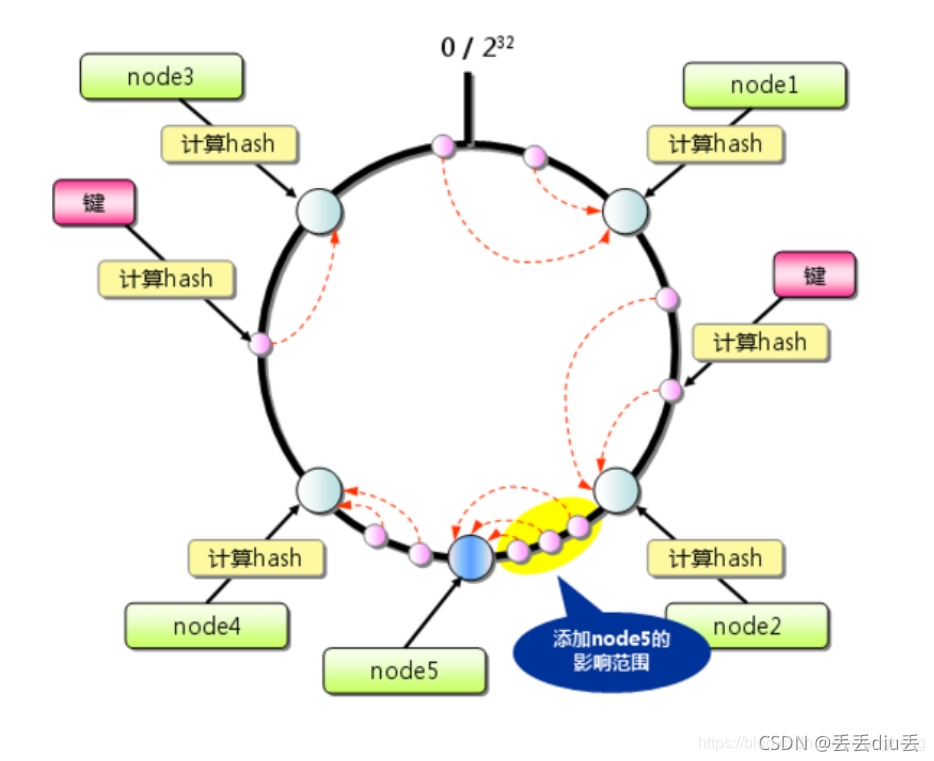
2.当增加存储节点时
如下图添加一台机器(node5)时,并没有影响到所有的数据,只有node4之前的节点node2到node5之间的数据受影响。
5.一致性Hash会有什么问题?——数据倾斜问题——用虚拟节点解决
1.什么是数据倾斜?
数据很不均匀的存在不同的存储节点上
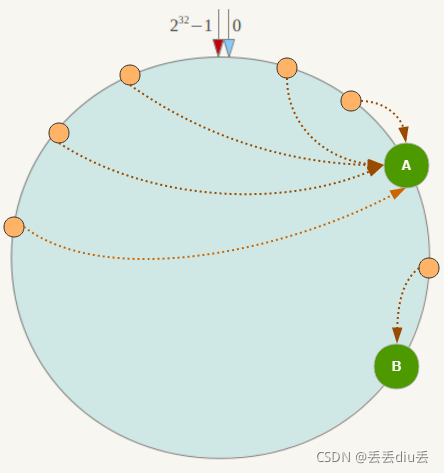
2.如何解决?——虚拟节点
对每一个节点,计算多次哈希,每个计算结果都放置1个此节点,成为虚拟节点。














 608
608











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









