






天气数据与我们的生活息息相关,无论是出行规划,还是农业生产等,精准的天气信息都起着关键作用。本文旨在利用Python中的requests库爬取天气数据(以苏州为例),方便后续关注、分析。
天气后报网(www.tianqihoubao.com), 目前可以查询涵盖 34 个省、市所属的 2290 个城市、县、地区历史天气预报信息,主要指标包括每天最高气温、最低气温、天气状况、风向等。
网页分析
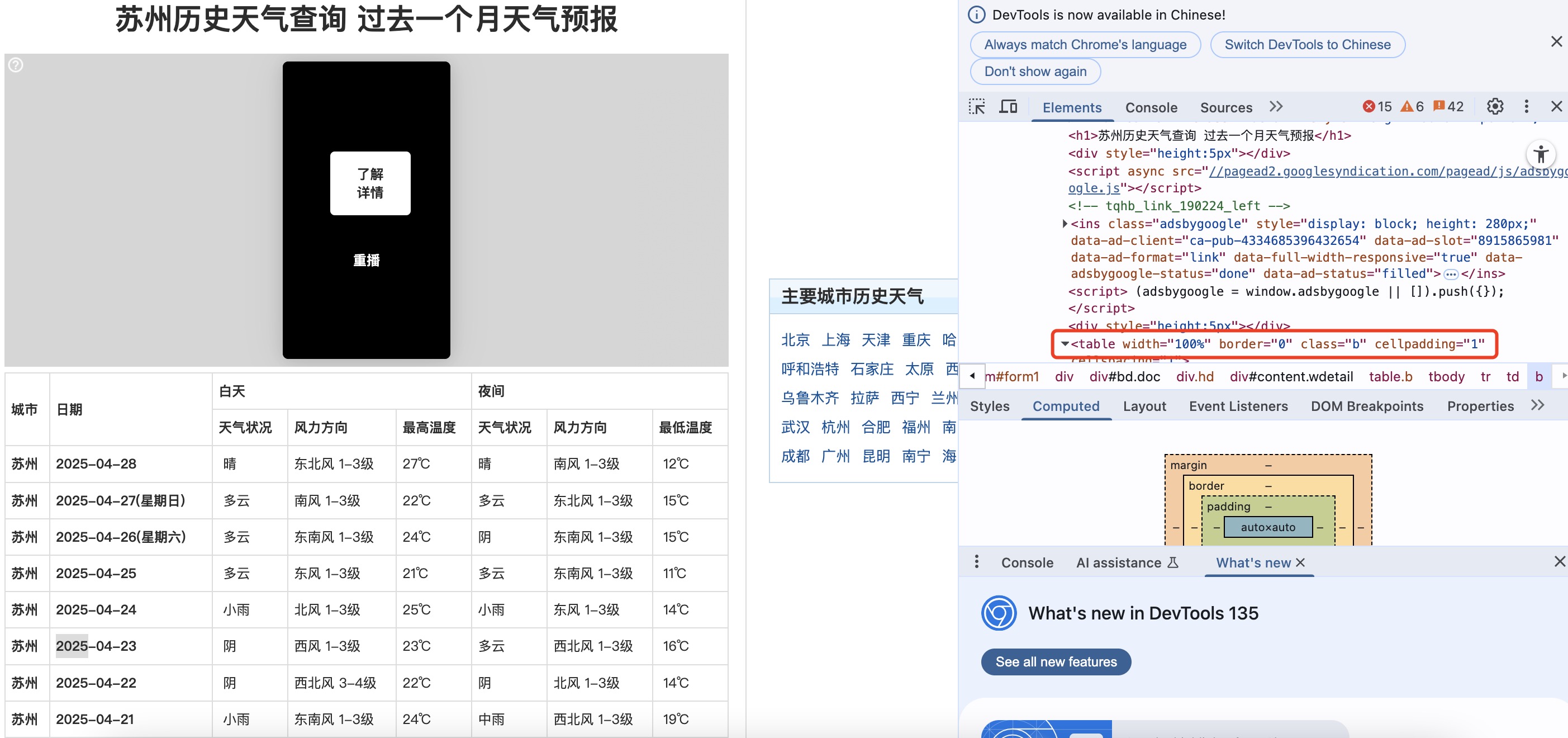
观察下网页的结构,发现该网站的数据为表格型数据,如上所示在检查元素里面有table的字样,这里可以使用read_html爬取网页数据,那么后面的操作就比较简单了。
代码实现
导入相关库
# -*- coding: UTF-8 -*-
# 导入相关库
import pandas as pd
import requests
from lxml import etree
提取苏州天气信息
# 获取网页内容
url = "http://www.tianqihoubao.com/weather/top/suzhou.html"
response = requests.get(url, headers=headers)
response.encoding = 'gbk' # 设置编码
# 使用 pandas 解析 HTML
df = pd.read_html(response.text, header=0)[0]
df = df.iloc[1:, :]
print(df)
处理数据,调整格式
# 修改列名
df_rename=df.rename(columns={"白天": "白天天气状况", "白天.1": "白天风力方向", "白天.2": "白天最高温度", "夜间": "夜间天气状况", "夜间.1": "夜间风力方向", "夜间.2": "夜间最低温度"})
# 规范日期列内容,提取日期的前10位
df_rename['日期']=df_rename['日期'].str[0:10]
df_rename
将提取的信息保存为CSV文件
# 保存为 CSV 文件
output_path = "天气信息.csv"
df.to_csv(output_path, index=False, encoding='utf-8-sig') # 保存为 UTF-8 编码的 CSV 文件
print(f"数据已保存为 {output_path}")
结果展示
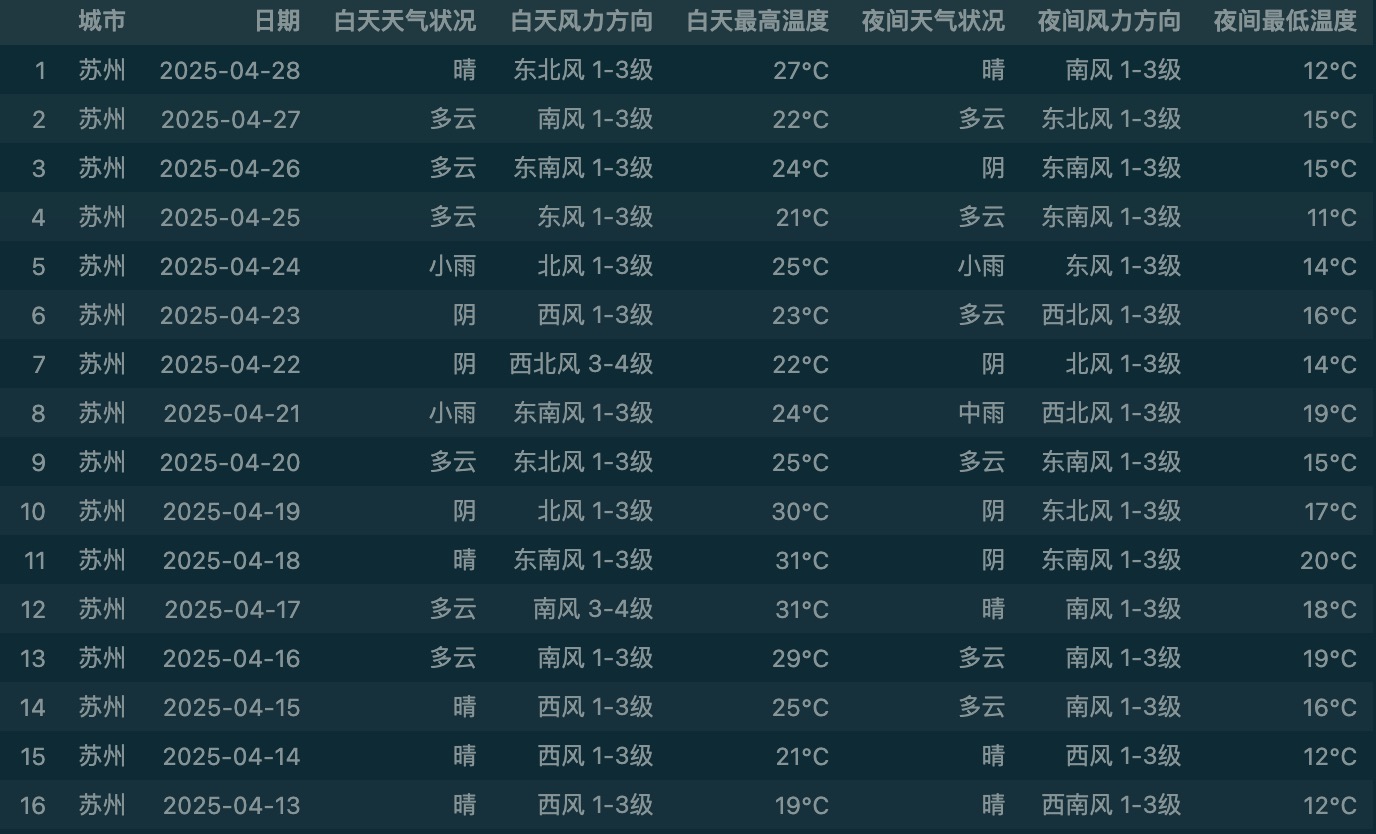
如下,苏州历史天气信息都提取保存为csv文件了。大家可以通过修改url,获取其他城市的天气信息。
推荐阅读
欢迎关注我的公众号“AI拾贝”,原创技术文章第一时间推送。后台发送天气,自动回复源码和数据。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









