






通过一个实验来看Spark 中 map 与 flatMap 的区别。
步骤一:将测试数据放到hdfs上面
hadoopdfs -put data1/test1.txt /tmp/test1.txt
该测试数据有两行文本:

步骤二:在Spark中创建一个RDD来读取hdfs文件/tmp/test1.txt

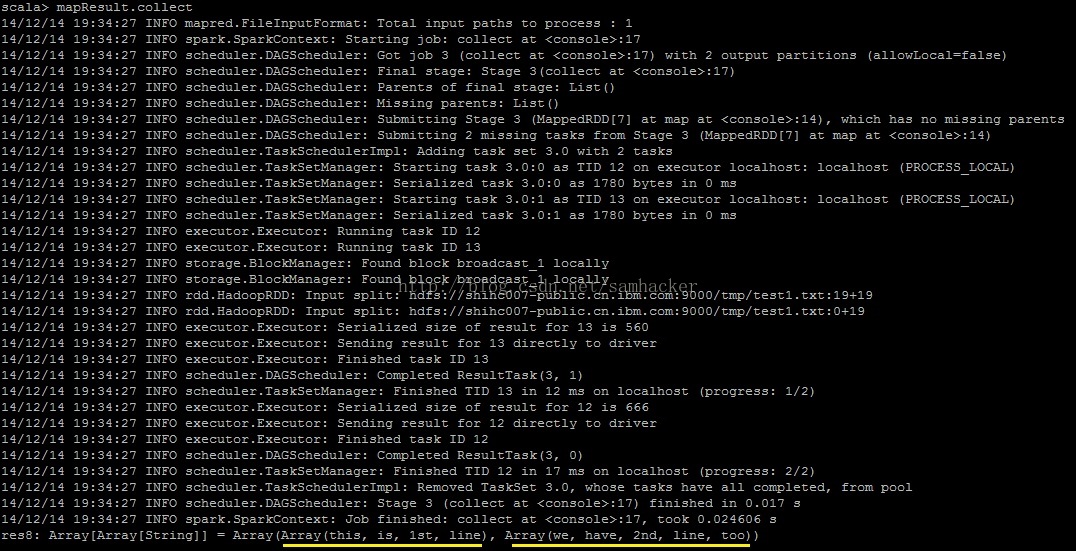
步骤三:查看map函数的返回值
得到map函数返回的RDD:

查看map函数的返回值——文件中的每一行数据返回了一个数组对象
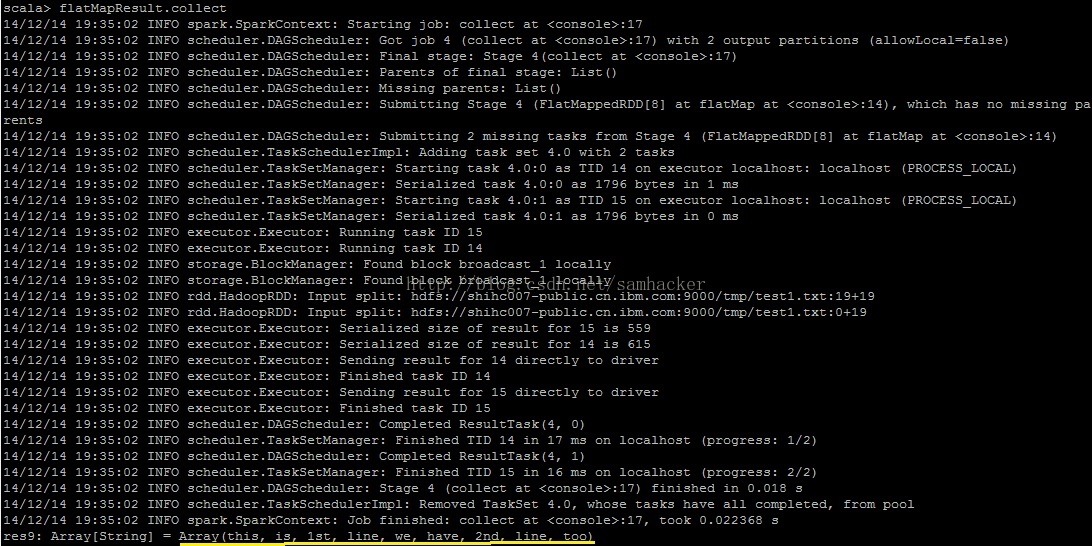
步骤四:查看flatMap函数的返回值
得到flatMap函数返回的RDD:

查看flatMap函数的返回值——文件中的所有行数据仅返回了一个数组对象
总结:
- Spark 中 map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象;
- 而flatMap函数则是两个操作的集合——正是“先映射后扁平化”:
操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象
操作2:最后将所有对象合并为一个对象
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-bash-4.1# sh /opt/hadoop-2.7.2/sbin/start-all.sh
-bash-4.1# sh /opt/spark-2.1.1-hadoop2.7/sbin/start-all.sh
-bash-4.1# spark-shell
scala> sc
res1: org.apache.spark.SparkContext = org.apache.spark.SparkContext@23d07ad3scala> rdd=sc.parallelize([1,2,3])
<console>:1: error: illegal start of simple expression
rdd=sc.parallelize([1,2,3])
^
scala> import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.{SparkConf, SparkContext}
scala> val textFile = sc.textFile("/root/spark_function_test")
textFile: org.apache.spark.rdd.RDD[String] = /root/spark_function_test MapPartitionsRDD[1] at textFile at <console>:25
scala> var mapResult = textFile.map(line => line.splt("\\s+"))
<console>:27: error: value splt is not a member of String
var mapResult = textFile.map(line => line.splt("\\s+"))
^
scala> var mapResult = textFile.map(line => line.split("\\s+"))
mapResult: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:27
scala> mapResult.collect
res2: Array[Array[String]] = Array(Array(This, is, 1st, line), Array(We, have, 2nd, line, too))
scala> var flatMapResult = textFile.flatmap(line => line.split("\\s+"))
<console>:27: error: value flatmap is not a member of org.apache.spark.rdd.RDD[String]
var flatMapResult = textFile.flatmap(line => line.split("\\s+"))
^
scala> var flatMapResult = textFile.flatMap(line => line.split("\\s+"))
flatMapResult: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at flatMap at <console>:27
scala> flatMapResult.colect
<console>:30: error: value colect is not a member of org.apache.spark.rdd.RDD[String]
flatMapResult.colect
^
scala> flatMapResult.collect
res4: Array[String] = Array(This, is, 1st, line, We, have, 2nd, line, too)















 5645
5645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









