







1
作为spark初学者对,一直对map与flatMap两个函数比较难以理解,这几天看了和写了不少例子,终于把它们搞清楚了
两者的区别主要在于action后得到的值
例子:
import org.apache.spark.{SparkConf, SparkContext}
object MapAndFlatMap {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setAppName("map_flatMap_demo").setMaster("local"))
val arrayRDD =sc.parallelize(Array("a_b","c_d","e_f"))
arrayRDD.foreach(println) //打印结果1
arrayRDD.map(string=>{
string.split("_")
}).foreach(x=>{
println(x.mkString(",")) //打印结果2
})
arrayRDD.flatMap(string=>{
string.split("_")
}).foreach(x=>{
println(x.mkString(","))//打印结果3
})
}
}
上述代码中,打印结果1、2、3分别如下面三图
打印结果1
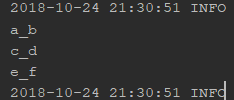
打印结果2

打印结果3

对比结果2与结果3,很容易得出结论:
map函数后,RDD的值为 Array(Array("a","b"),Array("c","d"),Array("e","f"))
flatMap函数处理后,RDD的值为 Array("a","b","c","d","e","f")
即最终可以认为,flatMap会将其返回的数组全部拆散,然后合成到一个数组中
spark中map和flatmap的区别
- map会将每一条输入映射为一个新对象。{苹果,梨子}.map(去皮) = {去皮苹果,去皮梨子} 其中: “去皮”函数的类型为:A ⇒ B
2.flatMap包含两个操作:会将每一个输入对象输入映射为一个新集合,然后把这些新集合连成一个大集合。 {苹果,梨子}.flatMap(切碎) = {苹果碎片1,苹果碎片2,梨子碎片1,梨子碎片2} 其中: “切碎”函数的类型为: A ⇒ List<B>
2
在使用时map会将一个长度为N的RDD转换为另一个长度为N的RDD;而flatMap会将一个长度为N的RDD转换成一个N个元素的集合,然后再把这N个元素合成到一个单个RDD的结果集。
比如一个包含三行内容的数据文件“README.md”。
a b c
d经过以下转换过程
val textFile = sc.textFile("README.md")
textFile.flatMap(_.split(" ")) 其实就是经历了以下转换
["a b c", "", "d"] => [["a","b","c"],[],["d"]] => ["a","b","c","d"]在这个示例中,flatMap就把包含多行数据的RDD,即[“a b c”, “”, “d”] ,转换为了一个包含多个单词的集合。实际上,flatMap相对于map多了的是[[“a”,”b”,”c”],[],[“d”]] => [“a”,”b”,”c”,”d”]这一步。
区别对比
map(func)函数会对每一条输入进行指定的func操作,然后为每一条输入返回一个对象;而flatMap(func)也会对每一条输入进行执行的func操作,然后每一条输入返回一个相对,但是最后会将所有的对象再合成为一个对象;从返回的结果的数量上来讲,map返回的数据对象的个数和原来的输入数据是相同的,而flatMap返回的个数则是不同的。请参考下图进行理解:

通过上图可以看出,flatMap其实比map多的就是flatten操作。
















 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









