







对于很多人来说,python的中字符转码是一件很头疼的事情,本来期望结果输出的是中文,结果来一段像这样\xe4\xbd\xa0\xe5\xa5\xbd像是乱码的字符串。
由于学python没多久,昨天使用python的时候,就遇到这种问题,现在来深入研究下与之相关的encode()和decode()函数,和如何把如乱码般的字符串转成中文。
encode()和decode()都是字符串的函数,可直接查看关于python字符串章节的官方文档:
https://docs.python.org/3/library/stdtypes.html?highlight=encode#string-methods
从英文意思上看,encode和decode分别指编码和解码。在python中,Unicode类型是作为编码的基础类型,即:
decode encode
str ---------> str(Unicode) ---------> str>>> u = '中文' # 指定字符串类型对象u
>>> str1 = u.encode('gb2312') # 以gb2312编码对u进行编码,获得bytes类型对象
>>> print(str1)
b'\xd6\xd0\xce\xc4'
>>> str2 = u.encode('gbk') # 以gbk编码对u进行编码,获得bytes类型对象
>>> print(str2)
b'\xd6\xd0\xce\xc4'
>>> str3 = u.encode('utf-8') # 以utf-8编码对u进行编码,获得bytes类型对象
>>> print(str3)
b'\xe4\xb8\xad\xe6\x96\x87'
>>> u1 = str1.decode('gb2312') # 以gb2312编码对字符串str进行解码,获得字符串类型对象
>>> print('u1')
'中文'
>>> u2 = str1.decode('utf-8') # 报错,因为str1是gb2312编码的
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd6 in position 0: invalid continuation byte简要说下一般有哪些编码格式。
ASCII码
ASCII码是美国早期制定的编码规范,只能表示128个字符,包括英文字符、阿拉伯数字、西文字符以及32个控制字符。简单来说,就是下面这个表:
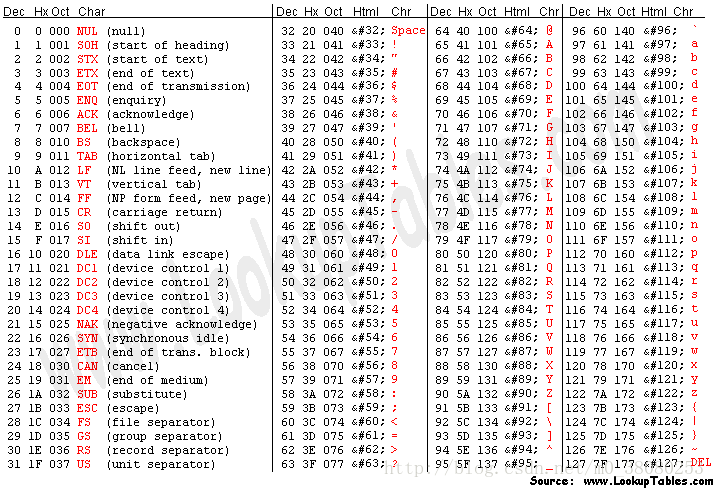
扩展ASCII码(Extended ASCII)
简单而言,扩展ASCII码的出现是因为ASCII不够用,所以向ASCII表继续扩充到256个符号。
但是因为对于扩展ASCII,不同的国家有不同的标准,于是促使了Unicode编码的诞生。
扩展ASCII码表如下:
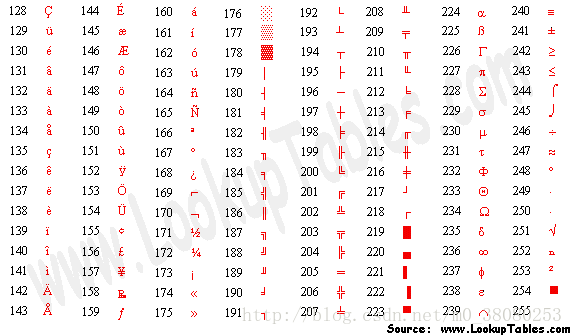
Unicode
准确来说,Unicode不是编码格式,而是字符集。这个字符集包含了世界上目前所有的符号。
另外,在原来有些字符可以用一个字节即8位来表示的,在Unicode将所有字符的长度全部统一为16位,因此字符是定长的。
Unicode是长这样的:
\u4f60\u597d\u4e2d\u56fd\uff01\u0068\u0065\u006c\u006c\u006f\uff0c\u0031\u0032\u0033上面这段Unicode的意思是“你好中国!hello,123”。
关于Unicode,可在这个网站查到所有字符:
https://unicode-table.com/en/
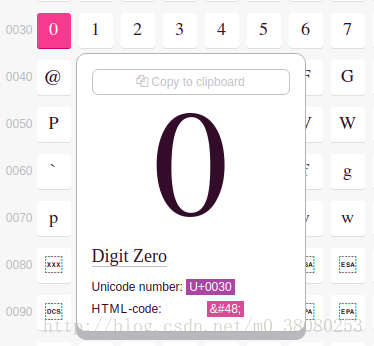
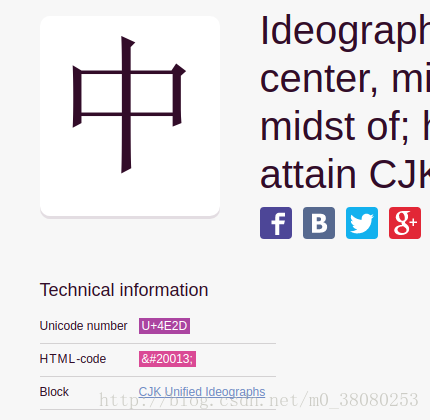
GB2312
当国人得到计算机后,那就要对汉字进行编码。在ASCII码表的基础上,小于127的字符意义与原来相同;而将两个大于127的字节连在一起,来表示汉字,前一个字节从0xA1(161)到0xF7(247)共87个字节,称为高字节,后一个字节从0xA1(161)到0xFE(254)共94个字节,称为低字节,两者可组合出约8000种组合,用来表示6763个简体汉字、数学符号、罗马字母、日文字等。
在重新编码的数字、标点、字母是两字节长的编码,这些称为“全角”字符;而原来在ASCII码表的127以下的称为“半角”字符。
简单而言,GB2312就是在ASCII基础上的简体汉字扩展。
gb2312码表:
http://www.fileformat.info/info/charset/GB2312/list.htm
GBK
简单而言,GBK是对GB2312的进一步扩展(K是汉语拼音kuo zhan(扩展)中“扩”字的声母),
收录了21886个汉字和符号,完全兼容GB2312。
GB18030
GB18030收录了70244个汉字和字符,更加全面,与 GB 2312-1980 和 GBK 兼容。
GB18030支持少数民族的汉字,也包含了繁体汉字和日韩汉字。
其编码是单、双、四字节变长编码的。
UTF(UCS Transfer Format)
UTF是在互联网上使用最广的一种Unicode的实现方式。我们最常用的是UTF-8,表示每次8个位传输数据,除此之外还有UTF-16。
UTF-8长这样,“你好中国!hello,123”:
你好中国!hello,123简单总结(来源于网络)
- 中国人民通过对 ASCII 编码的中文扩充改造,产生了 GB2312 编码,可以表示6000多个常用汉字。
- 汉字实在是太多了,包括繁体和各种字符,于是产生了 GBK 编码,它包括了 GB2312 中的编码,同时扩充了很多。
- 中国是个多民族国家,各个民族几乎都有自己独立的语言系统,为了表示那些字符,继续把 GBK 编码扩充为 GB18030 编码。
- 每个国家都像中国一样,把自己的语言编码,于是出现了各种各样的编码,如果你不安装相应的编码,就无法解释相应编码想表达的内容。
- 终于,有个叫 ISO 的组织看不下去了。他们一起创造了一种编码 UNICODE ,这种编码非常大,大到可以容纳世界上任何一个文字和标志。所以只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。
- UNICODE 在网络传输中,出现了两个标准 UTF-8 和 UTF-16,分别每次传输 8个位和 16个位。于是就会有人产生疑问,UTF-8 既然能保存那么多文字、符号,为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8 等编码体积比较大,占电脑空间比较多,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以。

















 3026
3026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









