






一、基础sql
1、增
(1)直接插入全部字段
insert into table_name values(value1,value2,value3)
(2)插入部分字段
insert into table_name (column_name1,column_name2) values(value1,value2)
2、删
delete from table_name where colunm_name =''
3、改
update table_name set column1='' where column2=''
4、查
select * from table_name where column=''
二、常用函数
1、nuion和union all
#union语法
select name from table1
union
select name from table2
#union all语法
select name from table1
union all
select name from table2
相同点:union和union all内部的select语句必须拥有相同数量的列,列也必须拥有相似的数据类型,同时,每条select语句中的列的顺序必须相同
不同点:1、union默认操作取不同的值
2、若允许重复的值,请使用union all
注意点:union和union all 结果集钟的列名总是等于第一个select语句中的列名
2、case–when–then–else–end
case when 相当于if else语句
有两种用法
1、简单的用法
case sex
when '1' then '男'
when '2' then '女'
else '其他'
end
2、搜索用法
case
when sex='1' then '男'
when sex='2' then '女'
else '其他' end
3、join
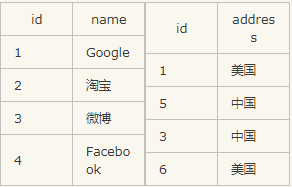
1、inner join--内连接
inner join和join是一样的,只连接匹配的就行
示例:
select * from A inner join B on A.id=B.id
结果如下:
id name address
1 Google 美国
3 微博 中国
2、left join
left join返回左表的全部行和右表满足on条件的行,如果左表的行在右表中没有匹配,那么这一行的右表中对应的数据用NULL代替。
示例:
select * from A left join B on A.id=B.id
结果如下:
id name address
1 Google 美国
2 淘宝 NULL
3 微博 中国
4 Facebook NULL
3、right join
right join返回右表的全部行和左表满足on条件的行,如果右表的行在左表中没有匹配,那么这一行的左表中对应的数据用NULL代替。
示例:
select * from A left join B on A.id=B.id
结果如下:
id name address
1 Google 美国
5 NULL 中国
3 微博 中国
6 NULL 美国
4、full outer join
full join会从左表和右表那里返回所有的行。如果其中一个表的数据行在另一个表中没有匹配的行,那么对面的数据用NULL代替
示例:
select * from A full outer join B on A.id=B.id
结果如下:
id name address
1 Google 美国
2 淘宝 NULL
3 微博 中国
4 Facebook NULL
5 NULL 中国
6 NULL 美国
4、between and
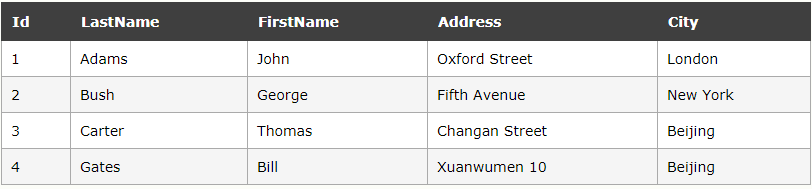
between ... and 会选取结余两个之间的数据范围,这些只可以是数值、文本或者日期,该操作语句是使用在where字句中的
示例:
select * from A where LasrName between 'Adams' and 'Carter'
执行结果:
Id LastName FirstName Address City
1 Adams
2 Bush
注:不同的数据库对 BETWEEN...AND 操作符的处理方式是有差异的。某些数据库会列出介于 "Adams" 和 "Carter" 之间的人,但不包括 "Adams" 和 "Carter" ;某些数据库会列出介于 "Adams" 和 "Carter" 之间并包括 "Adams" 和 "Carter" 的人;而另一些数据库会列出介于 "Adams" 和 "Carter" 之间的人,包括 "Adams" ,但不包括 "Carter" 。
如需使用上面的例子显示范围之外的人,请使用 NOT 操作符
select * from A where LasrName NOT between 'Adams' and 'Carter'
执行结果:
Id LastName FirstName Address City
1 Carter
2 Gates
5、contact
1、conact()
连接的字符串中有一个为null,则结果值为null,默认连接符号是,
示例:
select concat(id,username) from user_info
2、contact_ws()
连接的第一个参数是分隔符号,分隔符可以是一个字符串,也可以是其他参数,注意:分隔符为NULL,则结果为NULL,函数会忽略任何分隔符参数后的NULL值
示例:
select concat_ws('|',id,username) from user_info
3、group_contact()
语法:
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
示例:
select id,GROUP_CONCAT(`password` ORDER BY error_count desc SEPARATOR '|') from user_info group by username
6、空值替代函数
1、COALESCE
COALESCE(name,'a'),如果name是空值时,用a替代
2、ifnull
ifnull(coluname,value),如果coluname是NUll,则用value来替代,如果不是null,还是coluname
3、nvl
NVL(表达式1,表达式2) 如果表达式1的值为空值,返回表达式2的值
4、nvl2
NVL2(表达式1,表达式2,表达式3) 如果表达1的值为空,就返回表达式3的值,如果不为空,就返回表达式2的值
7、四舍五入、向上取整、向下取整
1、round
四舍五入保留指定小数位数的数据
select round(column_name,decimals) from table_name
2、floor
向下取整:返回小于或等于指定value的最大整数
select floor(column_name) from table_name
3、ceiling
向上取整:返回大于或等于指定value的最小整数
select ceiling(column_name) from table_name
8、data_format(date,format)
将时间字段按照指定的格式进行输出
date_format(clue_time,'yyyyMMdd') as clue_time
9、regexp
正则匹配
where url 'www.baidu.com|jd.com' #只匹配出正则中的内容
等同于 url in('www.baidu.com','jd.com')
10、row_number() over()
一般用于分组排序,且标上排序的序号
业务场景:取每个学科排名前3的学生
ROW_NUMBER() over(PARTITION by subject order by score desc) as num
#partition by 根据字段进行分组
#order by 根据字段进行排序
11、数据类型转换
1、cast()
注意:(1)两个表达式的数据类型完全相同。
(2)两个表达式可隐性转换。
(3)必须显式转换数据类型。
SELECT CAST('12' AS int) #将12设置为整数
SELECT CAST('12.5' AS int) #报错,因为12.5不是一个整数
SELECT CAST('12.5' AS decimal(9,2)) #输出12.50
SELECT CAST('12.5' AS decimal) #输出12
12、replace()
#REPLACE(String,from_str,to_str) 即:将String中所有出现的from_str替换为to_str
select REPLACE('abcdefghabc','abc','xxx') #结果为:xxxdefghxxx
13、parse_url
hive库支持
语法:VARCHAR PARSE_URL(VARCHAR urlStr, VARCHAR partToExtract [, VARCHAR key])
返回urlStr中指定的部分解析后的值。如果urlStr参数值为null时,则返回值为null
partToExtract :QUERY--参数列表,?后面的内容
HOST--host
PATH--host至?前面的内容
REF
PROTOCOL--协议
FILE--host后面的全部内容
AUTHORITY--相当于host
USERINFO
14、截取字段值
1、substr()
作用:用来截取数据库某个字段中的一部分
语法:substr(string,start,length)
string参数:必选。数据库中需要截取的字段。
start参数:必选。正数,从字符串指定位子开始截取;
负数,从字符串结尾指定位子开始截取;
0,在字符串中第一个位子开始截取。
1,同理。(特殊)
length参数:可选。需要截取的长度。缺省,即截取到结束位置。
15、instr()
INSTR(C1,C2,I,J) 在一个字符串中搜索指定的字符,返回发现指定的字符的位置;相当于python中的index函数,返回某个字符的下标
C1 被搜索的字符串
C2 希望搜索的字符串
I 搜索的开始位置,默认为1
J 出现的位置,默认为1
示例:
SQL> select instr("abcde",'b');
结果是2,即在字符串“abcde”里面,字符串“b”出现在第2个位置。如果没有找到,则返回0;不可能返回负数
16、字符串反转
reverse
17、移除函数
1、trim
2、ltrim:将所有字串起头的空白移除
3、rtrim:将所有字串结尾的空白移除
18、字符串大小写转化
1、lower()
当前字符集映射所有字符改变为小写
2、lcase
字段的值转换为大写
19、字符分隔
split()
20、求字符长度
size()
21、group sets
1 SELECT
2 CustomerID,
3 SalesPersonID,
4 YEAR(OrderDate) AS 'OrderYear',
5 SUM(TotalDue) AS 'TotalDue'
6 FROM Sales.SalesOrderHeader
7 WHERE SalesPersonID IS NOT NULL
8 GROUP BY GROUPING SETS
9 (
10 -- Our 4 different grouping sets
11 (CustomerID, SalesPersonID, YEAR(OrderDate)), #相当于group by CustomerID, SalesPersonID, YEAR(OrderDate)
12 (CustomerID, YEAR(OrderDate)), #相当于group by CustomerID, YEAR(OrderDate)
13 (SalesPersonID, YEAR(OrderDate)), #相当于group by SalesPersonID, YEAR(OrderDate)
14 () #相当于将所有行的TotalDue加合在一起
15 )
16 GO
说明:该写法相当于四个group by 的结果最后union all
三、数据库命令集
四、数据库字段类型
1、mysql
(1)数值类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| tinyint | – | – | – | – |
| smallint | – | – | – | – |
| mediumint | – | – | – | – |
| int或integer | – | – | – | – |
| bigint | – | – | – | – |
| float | – | – | – | – |
| double | – | – | – | – |
| decimal | – | – | – | – |
(2)日期和时间类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| date | – | – | – | – |
| time | – | – | – | – |
| year | – | – | – | – |
| datetime | – | – | – | – |
| timestamp | – | – | – | – |
(3)字符串类型
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| char | – | – | – | – |
| varchar | – | – | – | – |
| tinyblob | – | – | – | – |
| tinytext | – | – | – | – |
| blob | – | – | – | – |
| text | – | – | – | – |
| mediumblob | – | – | – | – |
| mediumtext | – | – | – | – |
| longblob | – | – | – | – |
| longtext | – | – | – | – |
参考链接:
1、https://www.cnblogs.com/telescope11/p/9909757.html
2、https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
3、https://www.cnblogs.com/woodytu/p/4685959.html















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









