







 自我介绍 面试官好! 我叫xxx,2019年毕业于xxx。之前在上家公司主要负责离线数仓的部分,19年3月份进去实习,实习的时候,这家公司刚刚开始做大数据方面的业务。算是从零开始;大数据平台从搭建到稳定运行,我们花了半年左右的时间;后来领导看我表现不错,让我做离线数仓的项目。当时我们是结合阿里云整个数仓的建模模型建的这个数仓,同时增加了一个dwt这样一层,写需求的时候能更容易些。后来大半年都在做这个数仓项目,一直到现在这个项目还在,后来整体的架构搭建完成后,就交给了新来的实习生,让他们来接手。
自我介绍 面试官好! 我叫xxx,2019年毕业于xxx。之前在上家公司主要负责离线数仓的部分,19年3月份进去实习,实习的时候,这家公司刚刚开始做大数据方面的业务。算是从零开始;大数据平台从搭建到稳定运行,我们花了半年左右的时间;后来领导看我表现不错,让我做离线数仓的项目。当时我们是结合阿里云整个数仓的建模模型建的这个数仓,同时增加了一个dwt这样一层,写需求的时候能更容易些。后来大半年都在做这个数仓项目,一直到现在这个项目还在,后来整体的架构搭建完成后,就交给了新来的实习生,让他们来接手。
有关大数据学习资源,请关注微信公众号“码农书斋”。回复“大数据”,免费获取学习视频、源码及资料!
自我介绍
面试官好!
我叫xxx,xxx年毕业于xxx大学。之前做过
后来公司准备开始做实时的项目,就把我抽调出来做实时。项目是基于sparkStreaming实时计算框架。做之前也是对sparkStreaming这个技术也做了研究。实时项目也是做了大半年。
最近一段时间我发现flink非常火,我也喜欢研究新技术,然后就去研究了一下flink。利用业务时间把公司的一些实时指标,用flink重新实现了一遍,发现效果非常明显,非常好。它是实现了真正的实时。
项目介绍
1.1.1 数据量统计
1:用户行为数据
每日活跃用户:100万人
每人产生日志数量:100条
每天产生日志数量:100万*100条=1亿条日志
用户行为日志数据格式:
字段包括:
1,日期
2,用户id
3, session_id
4, 页面id
5, 动作时间点
6,搜索关键字
7,点击的年级id 和课程id
8, 下单的年级id 和课程id
9, 支付的年级id 和课程id
10, 城市id
每条日志数据大小:0.5-2k之间,平均每条1k左右
每天数据量大小:1亿*1k 大概100G左右
数据仓库:
ods层:100G采用lzo压缩之后大概10G左右
dwd层:采用lzo压缩+parquet列式存储后10G左右
dws/dwt层: dws+dwt(轻度聚合存储) 为了快速计算不采用压缩 50G左右
ods层: 数据量小,忽略不计
保存三个副本:70G*3=210G
半年不扩容:210G*180 约 37T
预留20%~30%: 37T/0.7=53T
2:Kafka中的数据
1、每天100G数据
2、2个副本 100G*2=200G
3、副本数据保存三天 200G*3=600G
4、预留30% 600G/0.7=约1T
3:Flume中的数据
数据量比较小,忽略不计
4:业务数据
1、每天活跃用户100万,平均每天下单用户10万,每人下单产生10条日志,每条日志平均1K左右,10万10条1k=1G左右
2、数仓4层存储(不压缩) 1G*3=3G
3、保存三个副本 3G*3=9G
4、半年不扩容 9G*180=约1.6T
5、预留20%~30% 1.6T/0.7=约2T
5:服务器台数
集群规模: 53T+1T+2T=56T
服务器台数 56T/8T=7台服务器
根据数据规模进行集群规划
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|
| nn | nn | dn | dn | dn | dn | dn |
| nm | nm | nm | nm | nm | ||
| rm | rm | |||||
| zk | zk | zk | ||||
| Kafka | Kafka | kafka | ||||
| Flume | Flume | flume | ||||
| Hbase | Hbase | Hbase | ||||
| Hive | hive | |||||
| Mysql | Mysql | |||||
| Spark | spark | |||||
| es | es | |||||
| Sqoop | Canal | |||||
| Azkaban | Azkaban | Azkaban |
1)消耗内存的rm和nn分开
2)kafka 、zk 、flume 传输数据比较紧密的放在一起
3)客户端尽量放在同一台服务器上,方便外部访问
另外还要准备3台专门用作测试环境的服务器。3 * 128 * 8TSSD
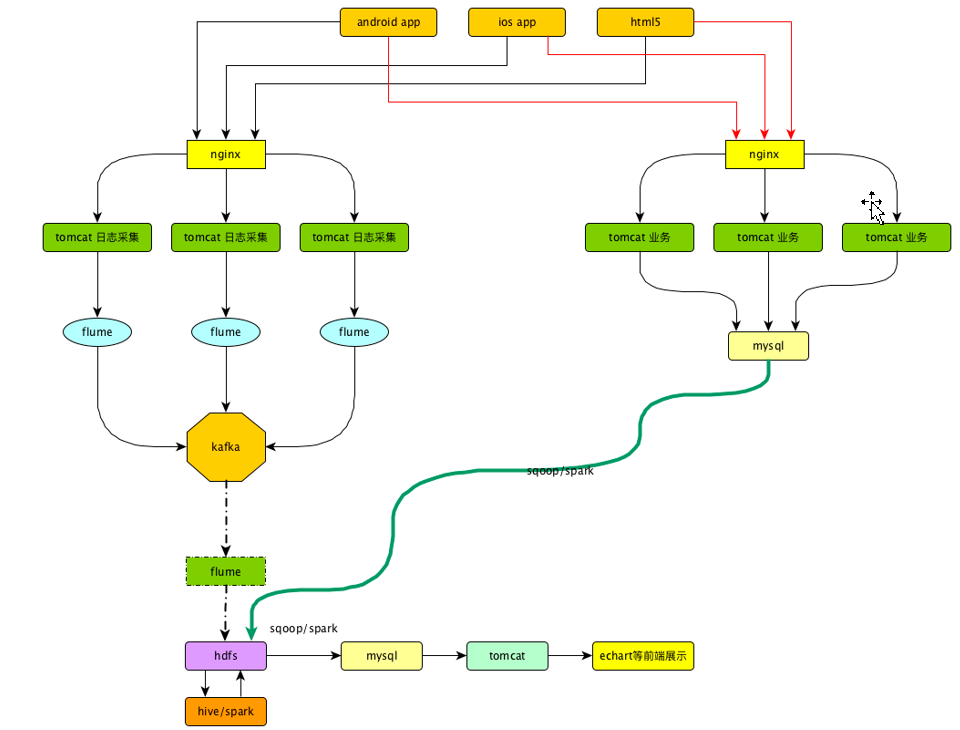
好,下面我介绍我们公司的这一套项目架构,我们公司有两套数据源,一套数据源是mysql里面的业务数据,另一套数据源是前端埋点的用户行为数据,用户行为数据是通过Nginx进行负载均衡,写到日志服务器,以文件的形式存在。日志文件需要保存30天,目的是为了防止后面任何一个组件挂了,依然能保证从日志服务器上取数据。然后用户行为数据导入到hive里面我们也做过很多尝试。刚开始我们想直接用Flume读日志文件直接怼到hadoop里面,理论上来说没有什么问题,而且调查了一下,有些企业也这么干。但是后来公司考虑到如果赶上双十一这样活动时,这就架构就不太好了。后来决定使用kafka在中间起到一个缓冲的作用。
我们刚开始使用的flume是1.6版本,在使用flume的过程中,我们深入研究了一下Flume,对于source我们用的是taildirSource 它可以实现断点续传和多
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1088
1088











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









