







4. Implementation of Softmax Regression from Scratch
Just as we implemented linear regression from scratch, softmax regression is similarly fundamental.
We will work with the Fashion-MNIST dataset, which has 10 classes.
import torch
from torch import nn, optim
from torch.utils import data
from torchvision import transforms, datasets
def get_dataloader_workers():
"""Use 4 processes to read the data."""
return 4
def load_data_fashion_mnist(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
minst_train = datasets.FashionMNIST(root="./data", train=True, transform=trans, download=True)
minst_test = datasets.FashionMNIST(root="./data", train=False, transform=trans, download=True)
return (data.DataLoader(minst_train, batch_size, shuffle=True, num_workers=get_dataloader_workers()),
data.DataLoader(minst_test, batch_size, shuffle=False, num_workers=get_dataloader_workers()))
batch_size = 256
train_iter, test_iter = load_data_fashion_mnist(batch_size)
4.1 Initializing Model Parameters
Each example in the raw dataset is a 28×28 image.
In this section, we will flatten each image, treating them as vectors of length 784.
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
4.2 Defining the Softmax Operation
Equation:
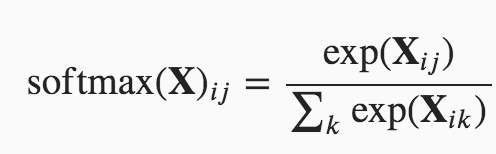
Implement:
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp/partition
4.3 Defining the Model
def net(X):
# (256, 1, 28, 28) t0 (256, 784)
return softmax(torch.matmul(X.reshape(-1, W.shape[0]), W)+b)
4.4 Defining the Loss Function
Implement the cross-entropy loss function:
def cross_entropy(y_hat, y):
return -torch.log(y_hat[range(len(y_hat)), y])
4.5 Classification Accuracy
def correct_num(y_hat, y):
# Compute the number of correct predictions.
if y_hat.shape[0] > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(dtype=y.dtype) == y
return float(sum(cmp))
class Accumulator:
# Accumulate sums over n variables.
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def accuracy(net, data_iter):
#Calculate accuracy of a dataset.
if isinstance(net, nn.Module):
net.eval()
metric = Accumulator(2)
for X, y in data_iter:
metric.add(correct_num(net(X), y), y.numel())
return metric[0] / metric[1]
4.6 Training
Define a function to train for one epoch:
def train_epoch(net, train_iter, loss, updater):
if isinstance(net, nn.Module):
net.train()
# Sum of loss, number of correct predictions, number of examples
metric = Accumulator(3)
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, optim.Optimizer):
updater.zero_grad()
l.backward()
updater.step()
metric.add(l * y.numel(), correct_num(y_hat, y), y.numel())
else:
l.sum().backward()
updater(X.shape[0])
metric.add(l.sum(), correct_num(y_hat, y), y.numel())
# Return loss and accuracy
return (metric[0] / metric[2]), (metric[1] / metric[2])
Define a function to train a model net on a training dataset accessed via train_iter for multiple epochs:
def train(num_epochs, net, train_iter, test_iter, loss, updater):
key_lst = ["train_los", "train_acc", "test_acc"]
history = dict().fromkeys(key_lst, [])
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch(net, train_iter, loss, updater)
test_acc = accuracy(net, test_iter)
history["train_los"].append(train_loss)
history["train_acc"].append(train_acc)
history["test_acc"].append(test_acc)
print("epoch: %d, train loss: %.4f, train_acc: %.4f, test_acc: %.4f" % (epoch + 1, train_loss, train_acc, test_acc))
return history
Use the minibatch stochastic gradient descent self-defined to optimize the loss function of the model with a learning rate 0.1:
def sgd(params, lr, batch_size):
# disabled gradient calculation
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
# clears old gradient from the last step
param.grad.zero_()
def updater(batch_size, lr=0.1):
return sgd([W, b], lr, batch_size)
Train the model with 2 epochs:
history = train(2, net, train_iter, test_iter, cross_entropy, updater)
epoch: 1, train loss: 0.7867, train_acc: 0.7484, test_acc: 0.7878
epoch: 2, train loss: 0.5705, train_acc: 0.8141, test_acc: 0.7675
history
{'train_los': [0.7866548803965251, 0.5704734970092773],
'train_acc': [0.7483833333333333, 0.8140666666666667],
'test_acc': [0.7878, 0.7675]}
References
Linear Neural Networks – Implementation of Softmax Regression from Scratch















 3901
3901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









