







前言
感觉自己学习东西比较慢,需要多次接触才能记住,caffe官方教程阅读起来发现真的是详细,不光介绍了caffe框架的主要构成以及作用,还介绍了使用方法,当然还有深度学习、机器学习的只是铺陈其中,很用心,很详细,很容易懂,之前看博客也好,看中文版教程也好,只能是东西快西边一块,而且第一次接触的东西忘得也快,理解也不深,阅读了一半发现,很有必要把这个官方教程看完。
一、blobs, layers, nets
1.关于层layers
每层有三个关键部分:setup, forward, and backward
2.网络
一个典型的网络从数据层开始,以loss层结束
二.Forward and Backward传播计算
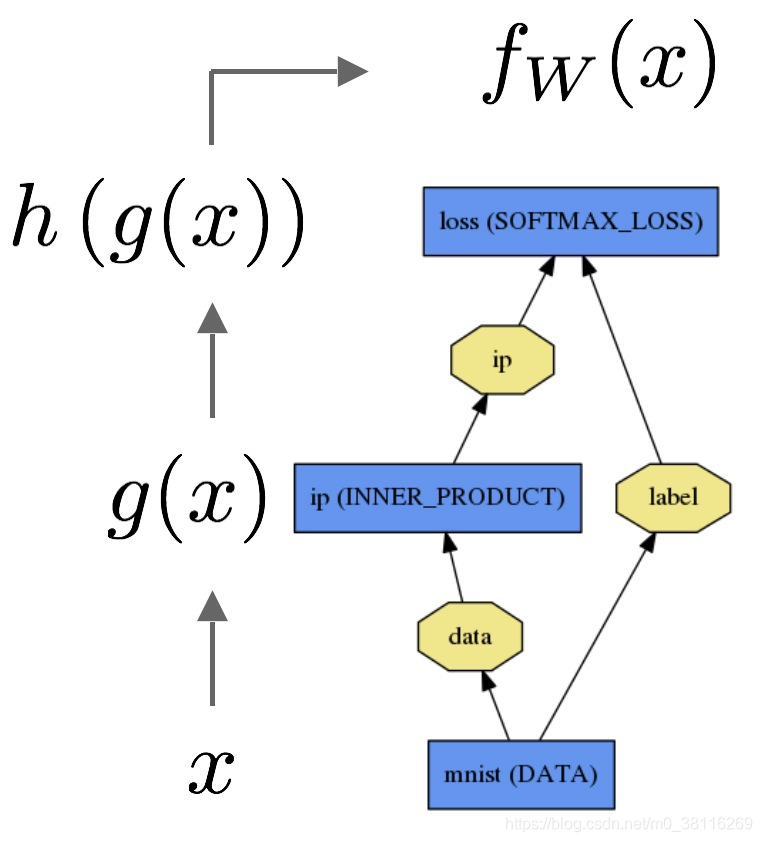 这个是前向传播的过程,非常浅显,从数据层一直向上传到损失层
这个是前向传播的过程,非常浅显,从数据层一直向上传到损失层
对于都想传播,就是求偏导数的过程,将蕴含loss的偏导往回传播,要用得到链式法则。caffe中提供了cpu和gpu两种模式的前向传播和后向传播方式。
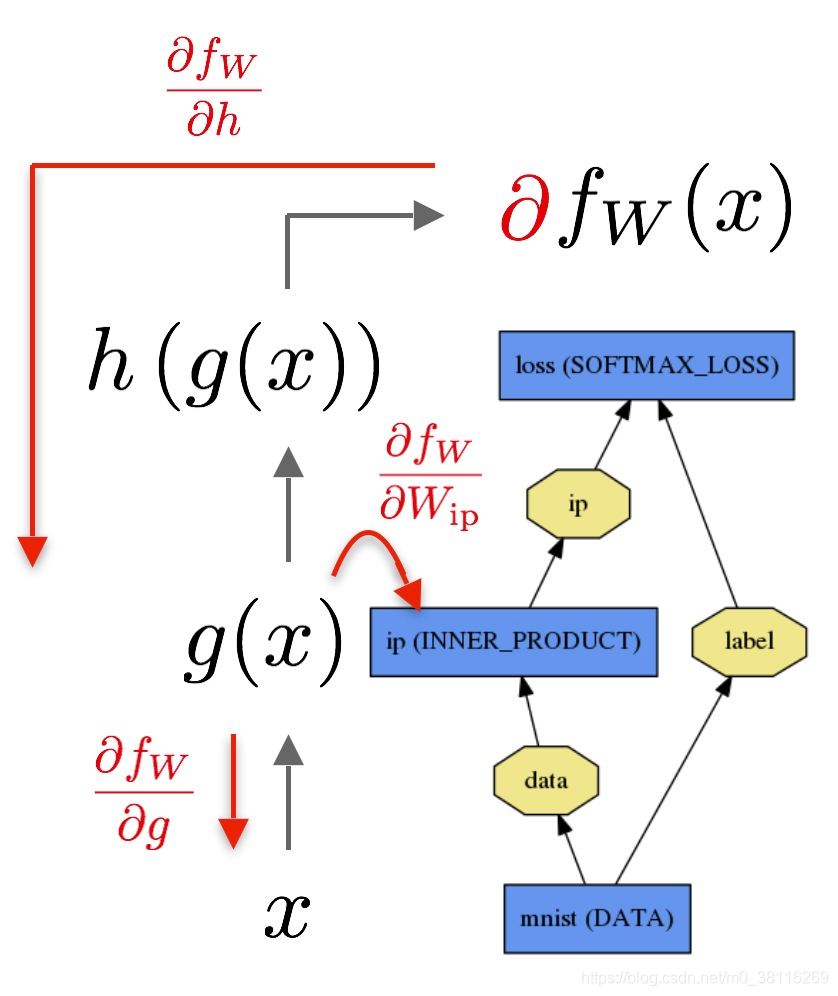
solver求解器优化模型的方法是:首先调用forward来生成输出和损失,然后调用backward来生成模型的梯度,然后将梯度合并到权重更新中,以尽量减少loss。
三、loss
学习的过程就是靠减小loss来驱动的,又叫做,error, cost, or objective function,目标就是找到能够使loss最小的一组权重。
通常就一个loss层,其他的都是些中间层,但是其实其它层也可以计算loss, 通过加上:loss_weight: 。也就是说,隐含的,loss层的loss_weight=1,而其它层的loss_weight=0。 这里想问一下,所有的loss_weight加起来和是1吗?我猜测是。如果需要,让有些中间层的loss_weight非零,对网络的某些中间层所产生的激活进行正则化。
caffe中loss的计算方式,现在也明白过来了
loss := 0
for layer in layers: #遍历所有层
for top, loss_weight in layer.tops, layer.loss_weights:
loss += loss_weight * sum(top) #就是各个层的top权重乘损失再加和
四、solver
学习任务划分为两个部分:负责监督优化,更新参数和更新产生损失和梯度的网络。
求解器的作用:
1.记录优化过程,创建用于学习的训练网络和用于评估的测试网络。
2.调用 forward / backward迭代优化,并更新网络参数
3.周期性的测试网络
4.在整个优化过程中将模型和求解器状态记录下来(snapshot)
对于SGD solver, 要设置超参数,为了让训练又稳又快进行,通常设置,a =0.01左右,and u=0.9左右,
这里再回顾一下里面各个参数的意义。
base_lr: 0.01 # 开始的学习率 0.01 = 1e-2
lr_policy: "step" # 学习策略:每step次迭代之后就降低学习率
gamma: 0.1 # 学习率降低10倍,此处乘0.1.刚开始学习的快一些,最后学习的细致一些
stepsize: 100000 # 每100K次降低学习率
max_iter: 350000 #
momentum: 0.9
当然人家说了,还得根据实情来设置这些超参数,这些参数只能算用作参考。调参的时候,如果刚开始loss非常大,尝试降低base_lr重新训练,直到学习的合适的时候。
最后训练能生成.caffemodel和.solverstate,前者可以用于分类识别,后者可以干嘛?有什么作用呢?答案,原来可以用.soverstate继续之前的训练(后面在学习,先占个坑)这个很强啊,需要学习一下,那么以后训练就可以设置snapshot合理一些,万一突然中断,还能保存下来之前的状态,从而继续训练,不错不错。
五、Layers
学习一下常用的层即可,有许多冷门层用到再查文档了解即可。
5.1 数据层
这里想起来当时训练遇到的一个问题,solver求解器中其他参数不变的情况下,读取jpg格式的数据,训练起来不仅慢,而且不收敛,精度不高,然后lmdb格式的数据训练起来就非常正常了,不知道为啥。
数据预处理有很多方法,例如,减去平均值,缩放,随机裁剪,镜像,可以在TransformationParameters里面设置。
5.2 视觉层
通常以图像作为输入,以图像作为输出,考虑图像的空间信息。
5.3 激活层
在下面的层中,我们将忽略输入和输出的大小,因为它们是相同的
5.4 Loss层
损失层的学习目标是将输出与目标进行比较并将cost降至最低。损失本身由前向通道计算,梯度损失由后向通道计算。
六、接口(Interfaces)
训练模型需要: -solver solver.prototxt
恢复训练需要:-snapshot mode_iter_1000.solverstate
微调模型需要:-weights model.caffemodel
完整的微调得参考examples/finetuning_on_flickr_style
后两条得学习一下怎么用啊。
Python接口
卧槽,继续阅读,发现人家配套了ipython notebook的样例程序卧槽!!!真的是太贴心了,现在是个小白啥都不会,需要从头了解,真的是如获至宝啊!需要详细实现运行。
还有一些文档
caffe如何计算卷积:将卷积计算转化为矩阵乘法,这种线性代数计算方式使得GPU效率大大提高。
最后作者还给我们推荐了一本书Neural Networks and Deep Learning,对于理解神经网络和后向传播有帮助,英文原汁原味的论文,后面可以闲着再看。
对于API文档,目前看不同,目测好像是C++语言写的。
历史遗留,留待明天解决
1.今天在尝试用Python进行solver求解的时候,无法运行,模型一运行就崩溃,未找到原因,留待解决
2.刚才尝试使用记录的solverstate文件想继续训练,但是报错,留待解决。

















 4569
4569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









