






 文章讲述了在面对传统网页请求失败时如何进行网页逆向分析来获取数据。作者通过检查网络数据包,发现数据请求的加密表头和表单,并模拟浏览器行为尝试用Python进行POST请求。然而,简单的POST请求导致系统错误,提示存在反爬措施。通过设置XHR断点,作者揭示了正确的请求头(包括Content-Type为application/json)和数据格式(JSON字符串),并提供了修正后的Python代码以成功发送请求。
文章讲述了在面对传统网页请求失败时如何进行网页逆向分析来获取数据。作者通过检查网络数据包,发现数据请求的加密表头和表单,并模拟浏览器行为尝试用Python进行POST请求。然而,简单的POST请求导致系统错误,提示存在反爬措施。通过设置XHR断点,作者揭示了正确的请求头(包括Content-Type为application/json)和数据格式(JSON字符串),并提供了修正后的Python代码以成功发送请求。
目标网站:
http://www.whggzy.com/PoliciesAndRegulations/index.html?utm=sites_group_front.2ef5001f.0.0.3178acd0d74911ed95c2c52125a73da9
抓取目标:
- 标题
- 时间
- 网页链接
难点:
- 数据请求表头和表单加密。
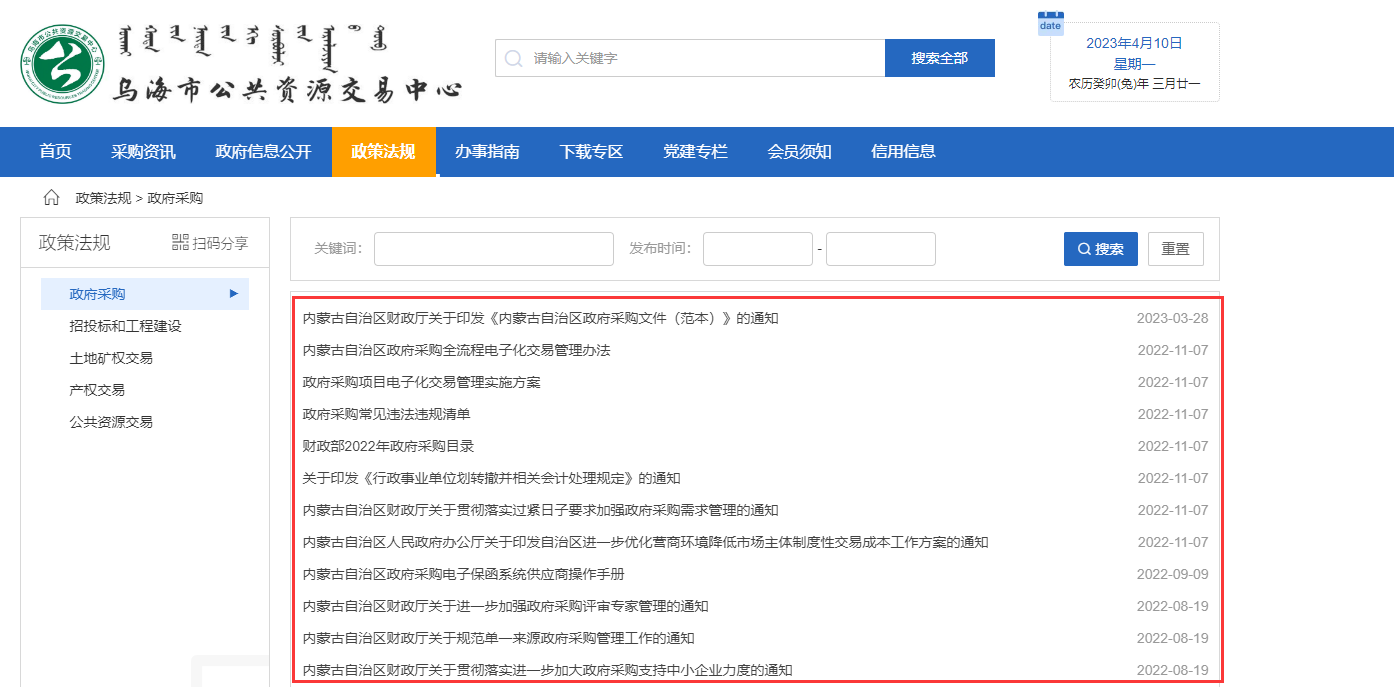
传统网页请求失败
按F12打开开发者工具,然后新网页,然后复制一个标题的部分内容(例如:内蒙古自治区财政厅),在开发者工具中按住Ctrl + F进行搜索。
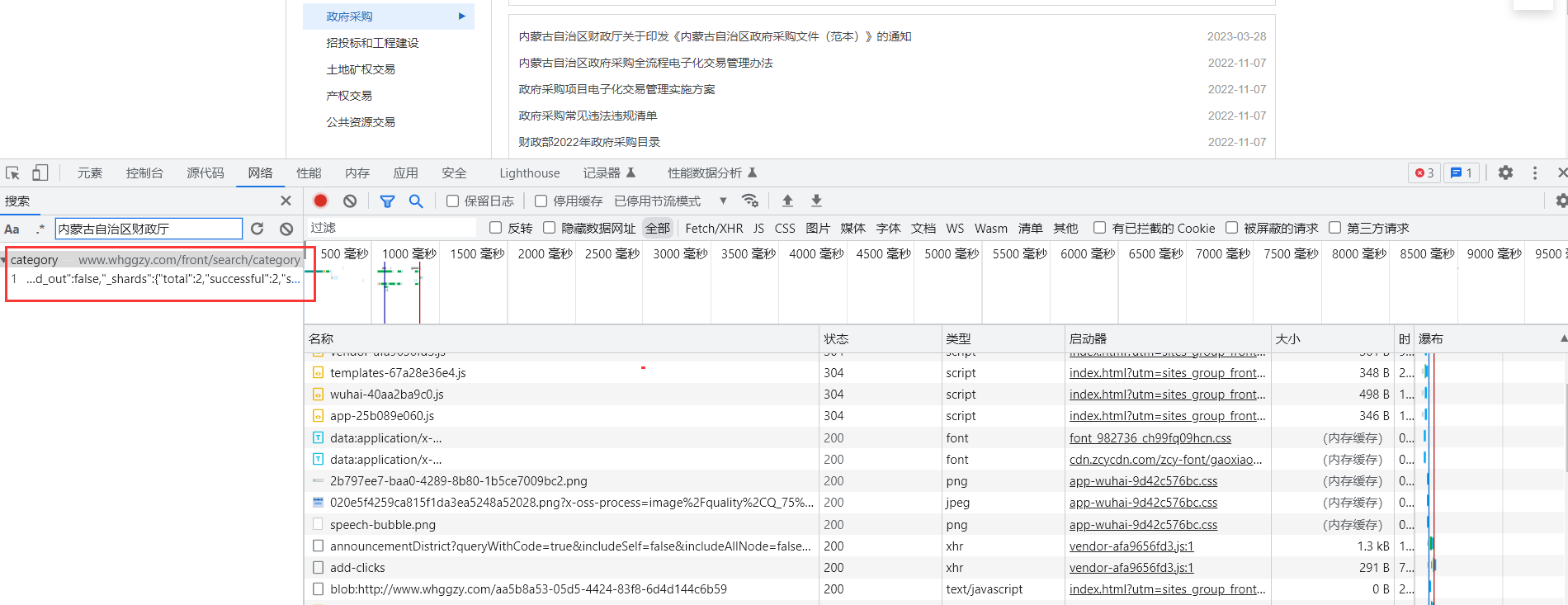
发现在搜索的结果中,可以展示对应的数据包。
双击该数据包定位到该数据包具体内容。

可以发现该数据包名称为category。
已经找到该数据包了,接下来只需要模拟浏览器访问行为,用代码对其进行访问即可。
首先,点击标头,查看数据包的访问地址及访问方式。
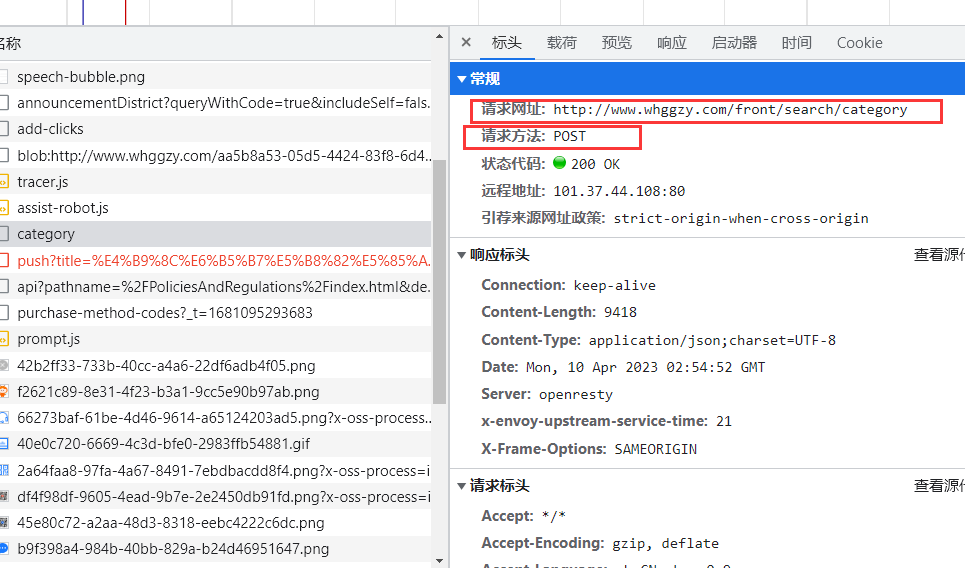
可以看到该数据包的
访问地址为:http://www.whggzy.com/front/search/category
访问方式为:POST请求
然后再点击载荷,查看POST请求的表单。

一共有4个字段,为了搞清楚这些字段是固定值还是经过了加密后的值,接下来对该网页进行刷新,再次查看该请求的载荷。
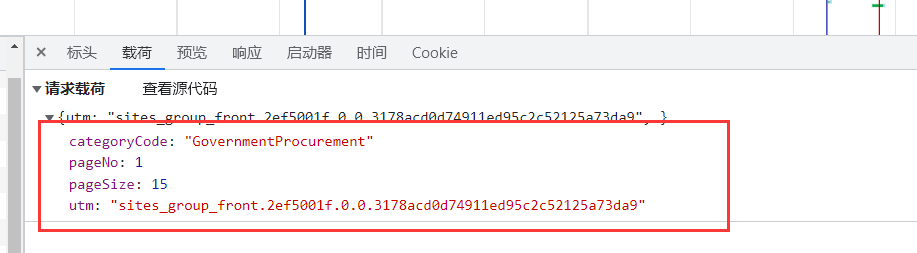
经过对比发现该请求的载荷内容没有发生变化,说明这里的4个参数均为固定值。
接下来开始编写Python代码
import requests
url = 'http://www.whggzy.com/front/search/category'
headers = {
"Referer": "http://www.whggzy.com/PoliciesAndRegulations/index.html?utm=sites_group_front.2ef5001f.0.0.ea6f6640d5cb11ed9547cf4018e15eea",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
}
data = {"utm":"sites_group_front.188479ff.0.0.48148460d60811ed992ee5ef25d2e7eb","categoryCode":"GovernmentProcurement","pageSize":15,"pageNo":1}
response = requests.post(url, headers=headers, data=data)
print(response.text)
运行代码后发现返回内容为系统出错,请稍后重试

说明使用简单的POST请求无法获取数据。
网站存在一定的反爬措施
网页逆向分析
在网络中找到该数据包,点击该数据包的启动器
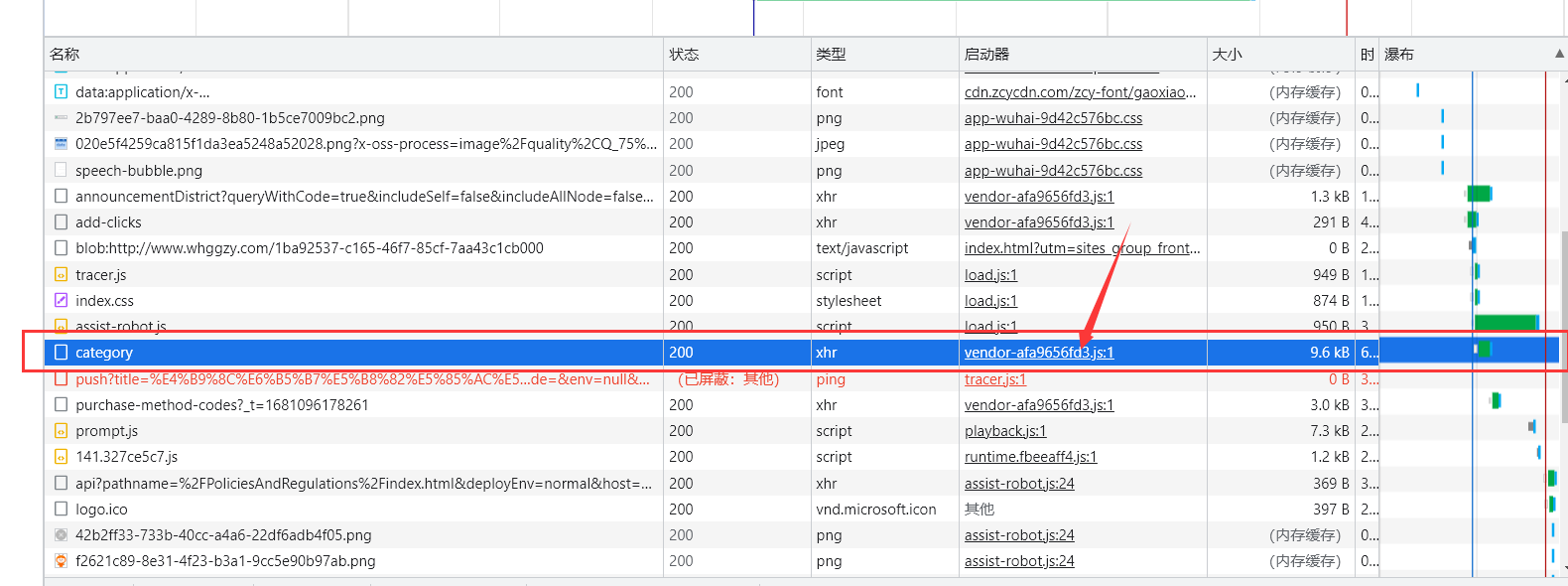
然后点击右侧添加XHR/提取断点
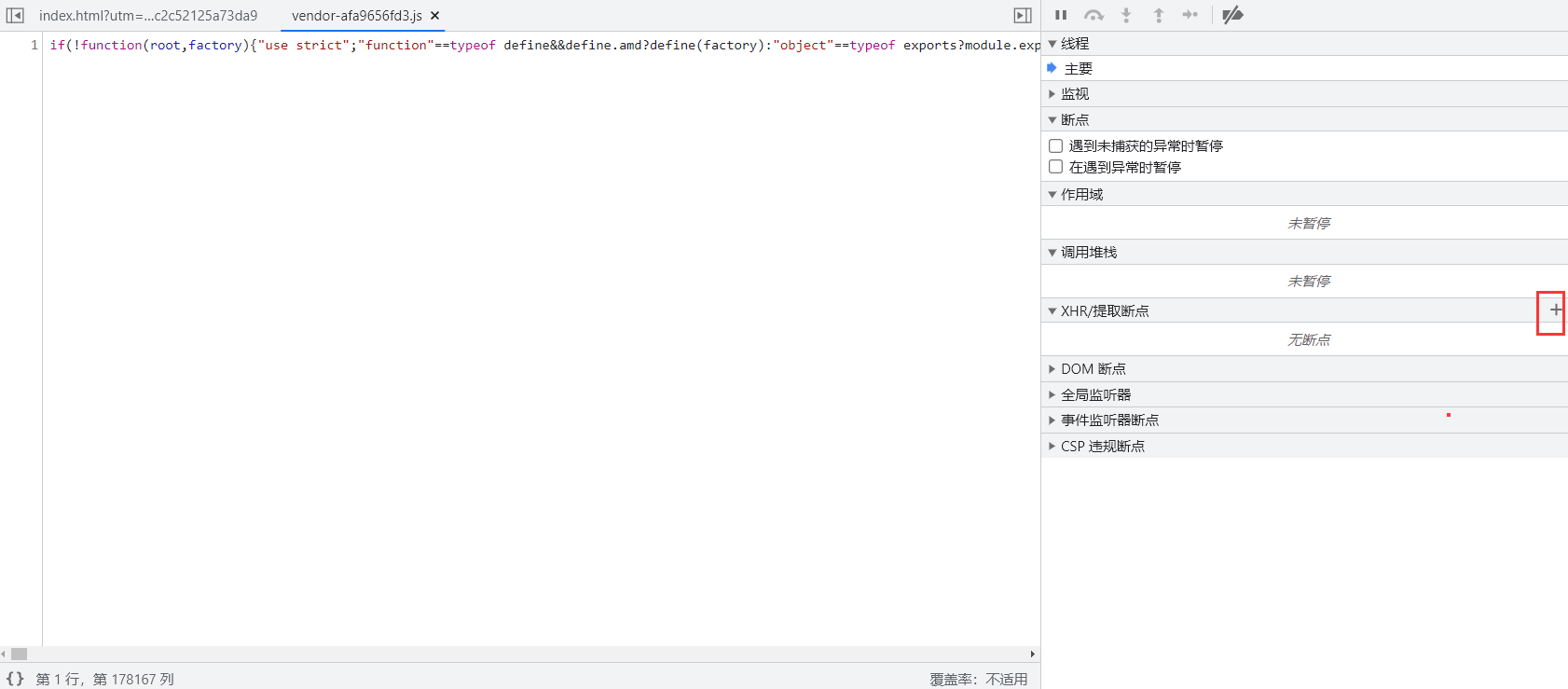
复制该数据包请求地址的路径/front/search/category添加到断点中。
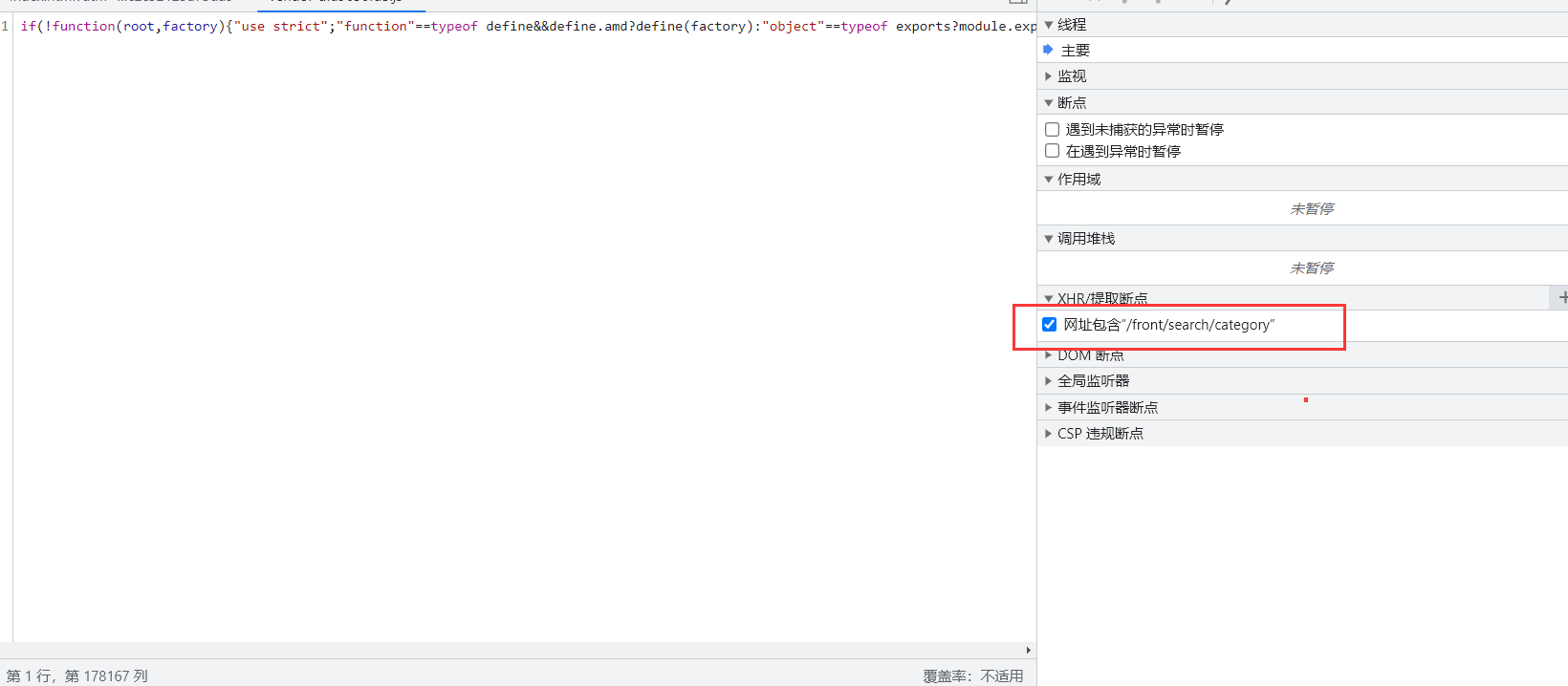
刷新网页。
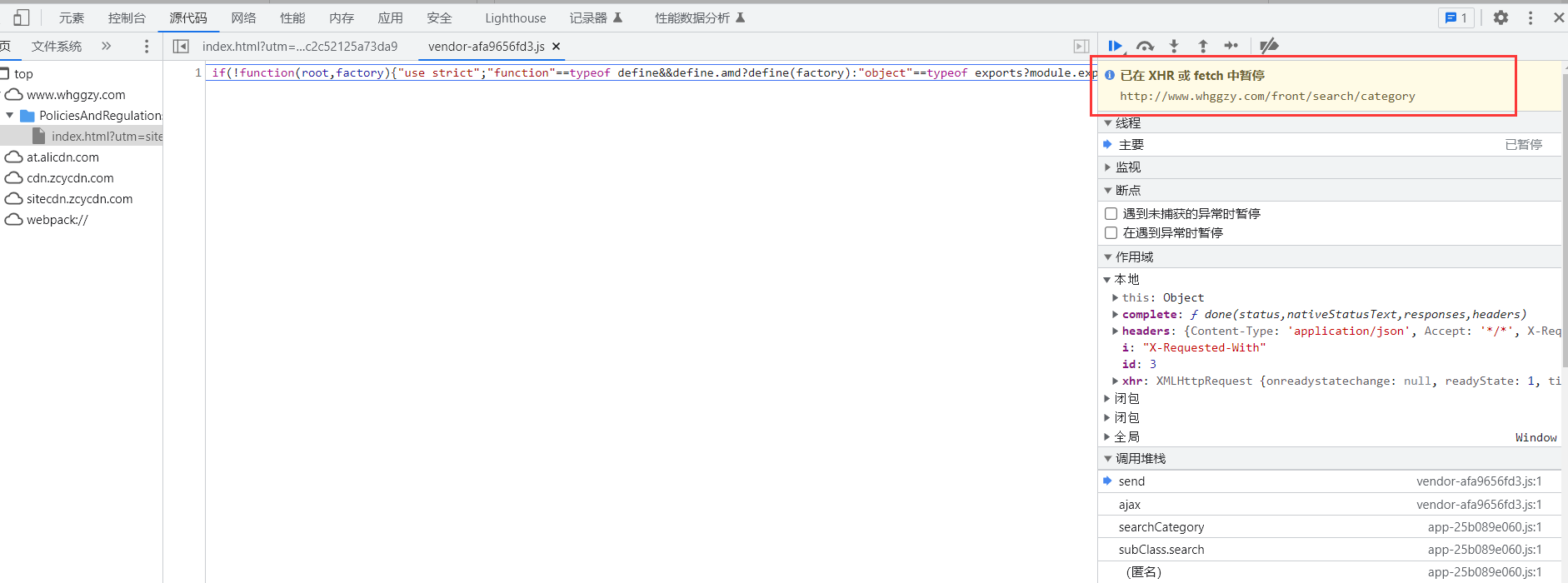
这个时候网页就会在断点处暂停,接下来点击右下角的{}让JS代码美观输出。
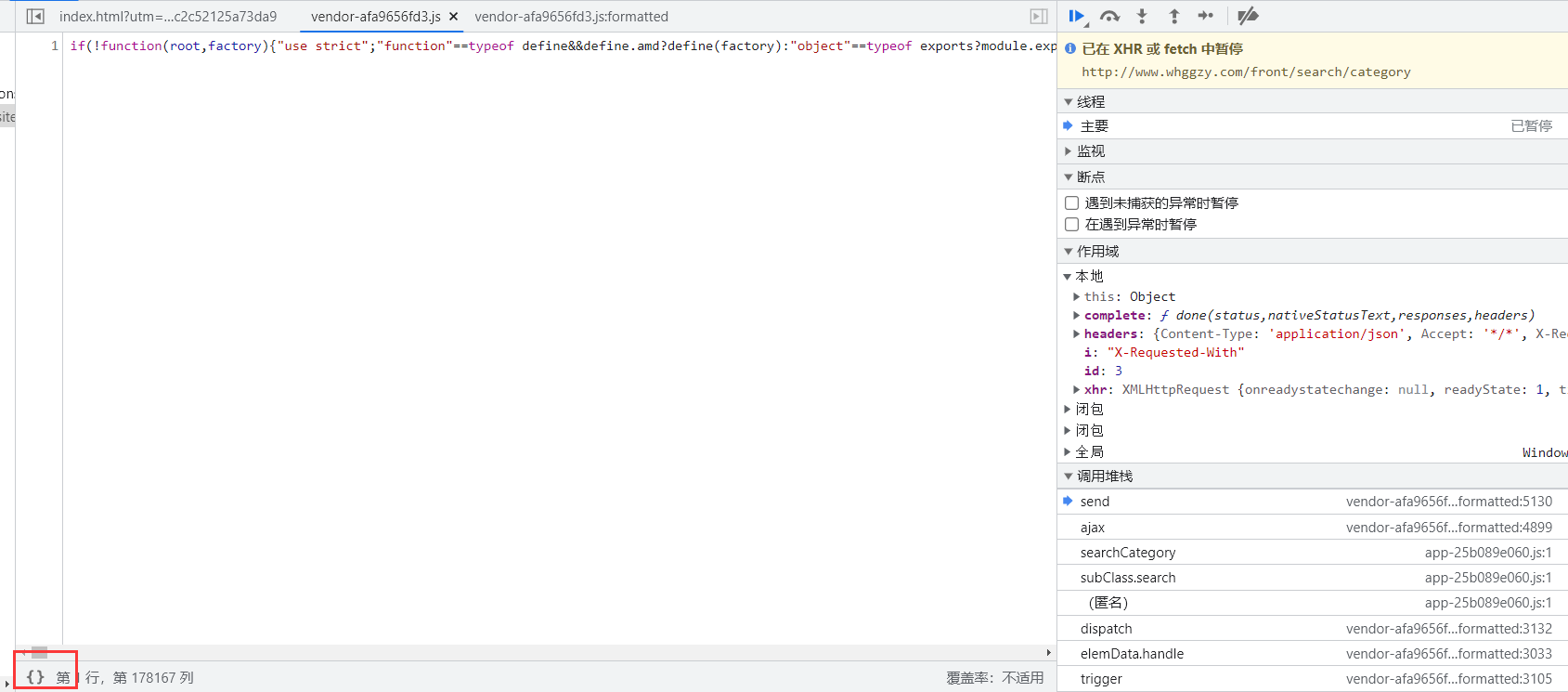
然后连续点击右侧的单步调试,同时观察右侧的作用域内容。
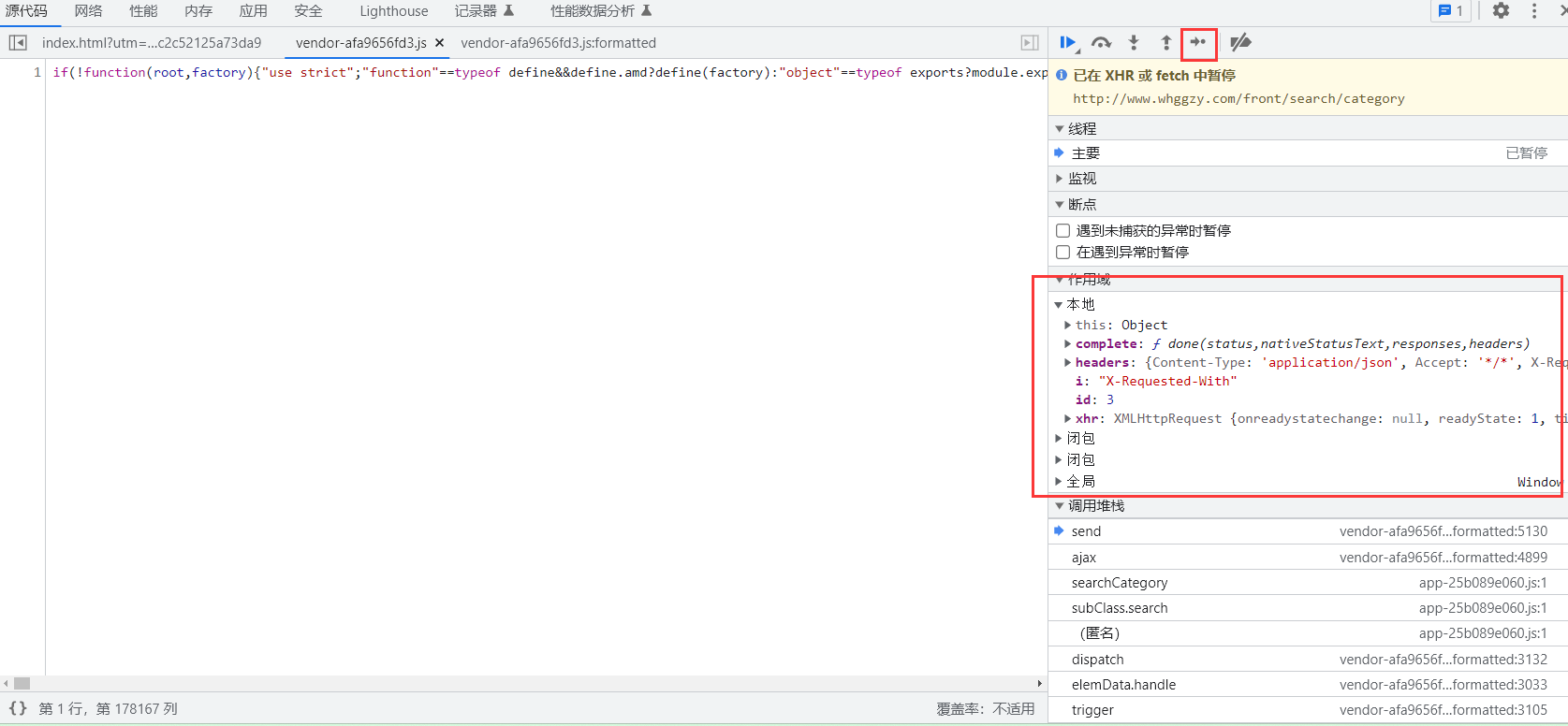
当作用域中出现requestHeaders和options时停止。

这里的requestHeaders和options就是网站在访问成功发送请求的请求头和表单内容。
将其展开,观察内容。
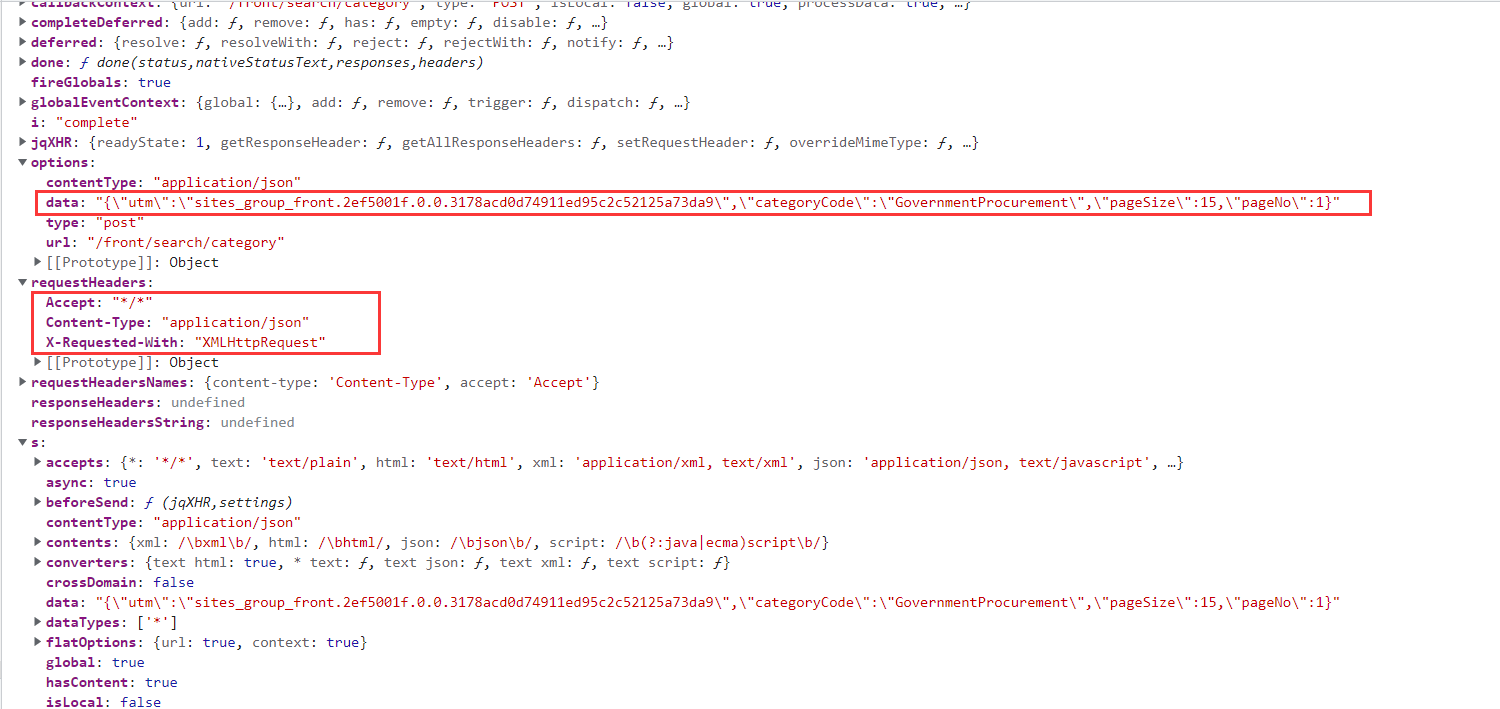
可以发现该数据包在请求时使用的请求头为。
headers = {
"Accept": "*/*",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
}
表单为:
data = '{"utm":"sites_group_front.188479ff.0.0.48148460d60811ed992ee5ef25d2e7eb","categoryCode":"GovernmentProcurement","pageSize":15,"pageNo":1}'
注意:这里的表单不是字典,而是一个字符串内容,部分网站会使用这种方式去限制用户访问,在内部进行校验时网站自己会将字符串转化为字典进行校验。
修改代码重新发送请求。
# 乌海市公共资源交易中心 http://www.whggzy.com/
# 路径搜索/front/search/category,XHR断点查看真正的数据加载方式
import requests
url = 'http://www.whggzy.com/front/search/category'
headers = {
"Accept": "*/*",
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
}
data = '{"utm":"sites_group_front.188479ff.0.0.48148460d60811ed992ee5ef25d2e7eb","categoryCode":"GovernmentProcurement","pageSize":15,"pageNo":1}'
response = requests.post(url, headers=headers, data=data)
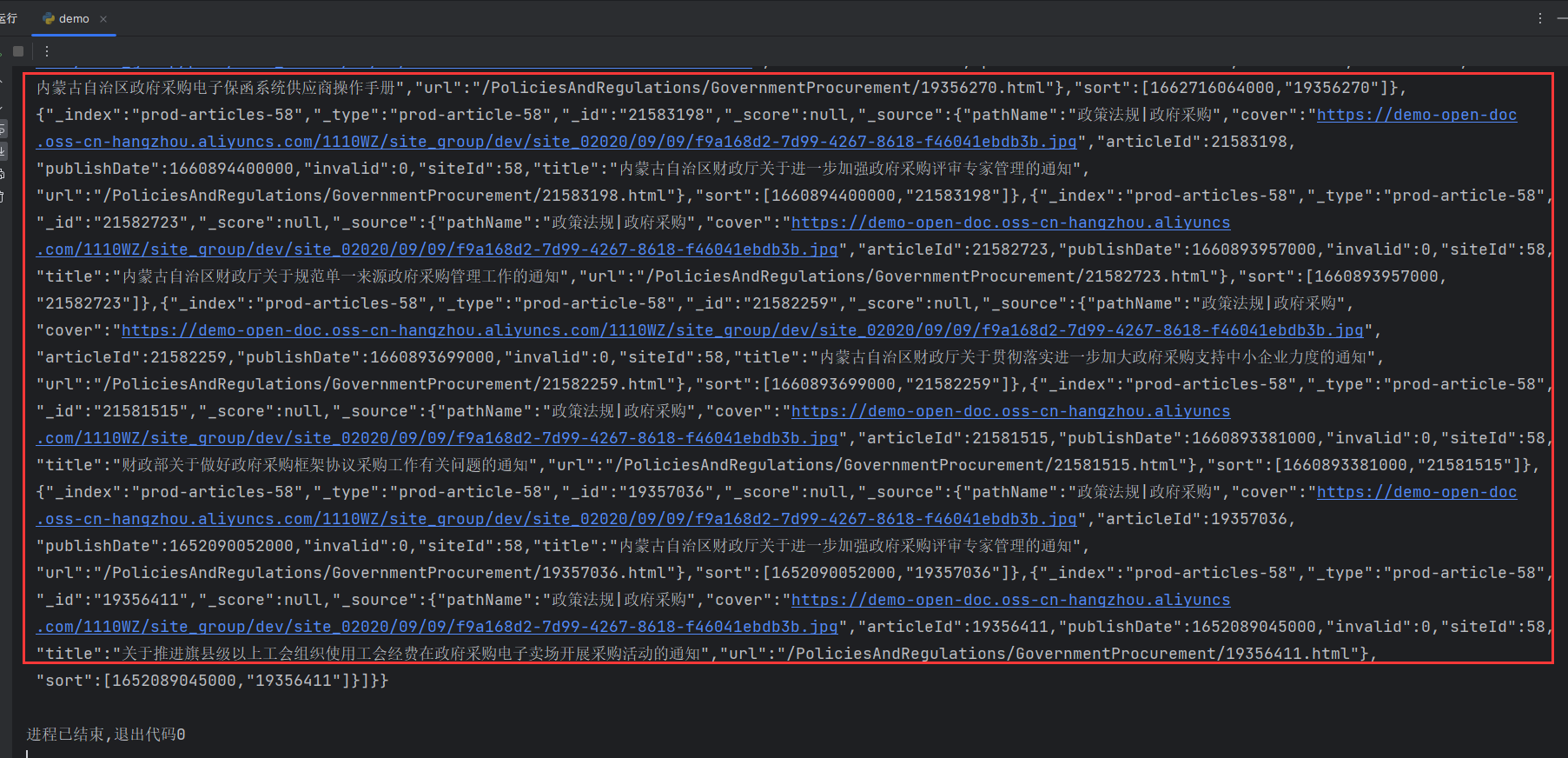
print(response.text)















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









