







书接上文 Spring源码分析-从@ComponentScan注解配置包扫描路径到IoC容器中的BeanDefinition,经历了什么(一)?
在执行完ClassPathScanningCandidateComponentProvider的scanCandidateComponents方法后,应用上下文已经将在类中添加@Component或者由javax.annotation包中提供的@ManagedBean或者N-amed注解的Class通过ASM技术读取到类元信息并构造成SimpleMetadatReader。
可以看到SimpleMetadataReader中存放了两种信息,一种是Resource对象,这里使用的FileSystemR-esource的实例,在该对象中存放了定义该Class对象的文件位置和文件对象。
另一种就是SimpleAannotationMetadata,在该对象种存放了类名、类的访问修饰符(access)、父类的类名、内部类类名信息等等。
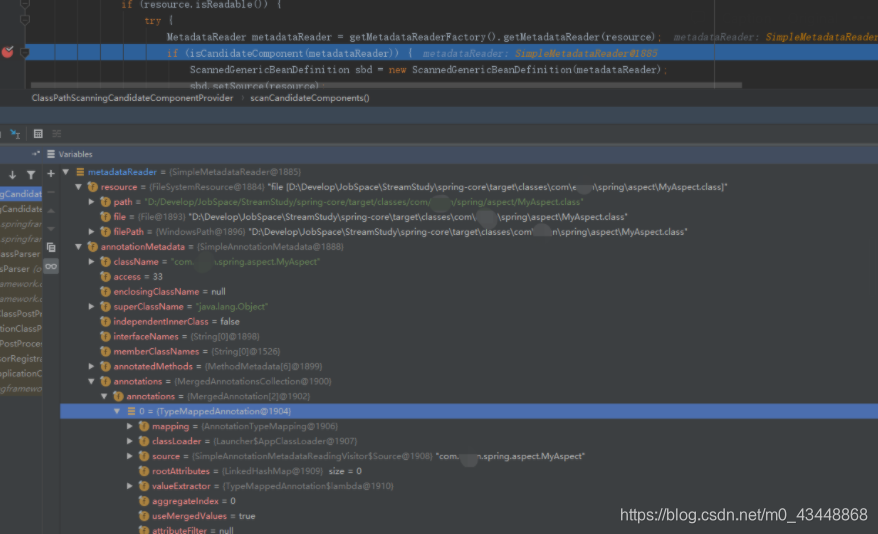
然后再根据这些SimpleMetadataReader构造ScannedGenericBeanDefinition对象,这里会对Scanned-GenericBeanDefinition对象进行过滤,过滤添加注解的接口和那些未添加@Lookup注解的抽象类。
// ClassPathScanningCandidateComponentProvider#scanCandidateComponents
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
} else {
if (debugEnabled) {
logger.debug("Ignored because not a concrete top-level class: " + resource);
}
}
} else {
if (traceEnabled) {
logger.trace("Ignored because not matching any filter: " + resource);
}
}
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
} else {
if (traceEnabled) {
logger.trace("Ignored because not readable: " + resource);
}
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
return candidates;
}
这次的将组件构造成BeanDefinition并不是将所有需要受IoC容器管理的组件都找到了,因为这次IoC容器加载的只是直接受IoC容器管理的组件,而没有加载那些可插拔的组件。还有对加载到的这些类中的@Component、@ComponentScan、@PropertySource等注解还未解析。
这里说下什么是直接受IoC管理的组件,什么是可插拔的组件。
例如在一个类上添加@Component注解或者其派生注解,可以称之为直接受IoC容器管理的组件。而如果在一个类上除了添加@Component注解,还使用@Import注解导入了其它组件,那么通过@Import注解指定导入的组件就可以称之为可插拔组件。
把目光回到触发这个方法的源头处ConfigurationClassParser的doProcessConfigurationClass方法中,在该方法中通过调用ComponentScanAnnotationParser的parse方法获取到用户向IoC容器注册Bean的BeanDefinition信息后,对这些BeanDefinition进行了遍历处理。
// ConfigurationClassParser#doProcessConfigurationClass
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
对于每个通过ConfigurationClassutils的checkConfigurationClassCandidate方法检验的BeanDefinition都会调用parse方法。
在parse方法通过传入的全限定名获取到对应的MetadataReader后,需注意的是这里是重新通过Met-adataReaderFactory来重新创建MetadataReader,并未使用前面scanCandidateComponents方法中创建的MetadataReader对象。
之所以需要重新创建,是因为前面使用到的MetdataReaderFactory定义在ClassPathScanningCandid-ateComponentProvider类中,而ConfirationClassParser并未持有此类对象。并且此次创建MetadtaR-eader对象的过程并不一样。
protected final void parse(@Nullable String className, String beanName) throws IOException {
Assert.notNull(className, "No bean class name for configuration class bean definition");
MetadataReader reader = this.metadataReaderFactory.getMetadataReader(className);
processConfigurationClass(new ConfigurationClass(reader, beanName), DEFAULT_EXCLUSION_FILTER);
}
这里使用到的MetadtaReaderFactory和前面使用倒是一致,都是CachingMetadataReaderFactory,该类继承于SimpleMetadataReaderFactory。其并未实现参数类型为String的getMetdataReader方法。所以这里执行的是父类SimpleMetadataReaderFactory的getMetadtaReader方法。
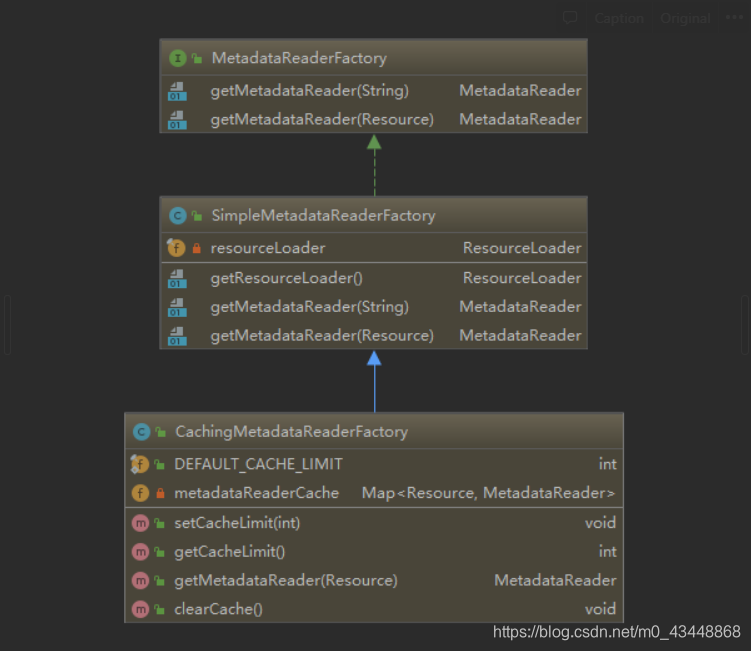
在父类SimpleMetadataReaderFactory的getMetadataReader方法中,首先对传递进来的类的全限定名拼接上“classpath:”前缀和“.class”后缀,把全限定名中的“.”替换为“/”。然后通过ResourcLoader(其实就是当前上下文对象-ApplicationContext的实现类)的getResource方法来获取Resource实例。
然后调用方法入参类型为Resource的getMetadataReader方法。
public static final String CLASSPATH_URL_PREFIX = "classpath:";
String CLASSPATH_URL_PREFIX = ResourceUtils.CLASSPATH_URL_PREFIX;
/** The ".class" file suffix. */
public static final String CLASS_FILE_SUFFIX = ".class";
public MetadataReader getMetadataReader(String className) throws IOException {
try {
String resourcePath = ResourceLoader.CLASSPATH_URL_PREFIX +
ClassUtils.convertClassNameToResourcePath(className) + ClassUtils.CLASS_FILE_SUFFIX;
Resource resource = this.resourceLoader.getResource(resourcePath);
return getMetadataReader(resource);
}
catch (FileNotFoundException ex) {
// Maybe an inner class name using the dot name syntax? Need to use the dollar syntax here...
// ClassUtils.forName has an equivalent check for resolution into Class references later on.
int lastDotIndex = className.lastIndexOf('.');
if (lastDotIndex != -1) {
String innerClassName =
className.substring(0, lastDotIndex) + '$' + className.substring(lastDotIndex + 1);
String innerClassResourcePath = ResourceLoader.CLASSPATH_URL_PREFIX +
ClassUtils.convertClassNameToResourcePath(innerClassName) + ClassUtils.CLASS_FILE_SUFFIX;
Resource innerClassResource = this.resourceLoader.getResource(innerClassResourcePath);
if (innerClassResource.exists()) {
return getMetadataReader(innerClassResource);
}
}
throw ex;
}
}
AnnotationConfigApplicatioContext并未实现该方法,调用的是其父类GenericApplicationContext的getResource方法,在该方法中,首先判断自己的resourceLoader属性是否为空,如果不为空直接调用其getResource方法,否则调用父类的getResource方法。这里调用的是父类的getResource方法。
需注意的是这里调用是GenericApplicationContext的父类的DefaultResourceLoader的getResource方法(在前面scanCandidateComponents方法中调用的是getResources方法,AbstractAapplicationCont-ext实现了该方法,但并未实现getResource方法。getResources方法是获取多个资源,getResource方法是获取单个资源)。
// org.springframework.context.support.GenericApplicationContext#getResource
public Resource getResource(String location) {
if (this.resourceLoader != null) {
return this.resourceLoader.getResource(location);
}
return super.getResource(location);
}

在DefaultResourceLoader的getResource方法中,首先遍历所有的协议处理器,这里获取到的为空。接下来便是判断传入的路径是否以“/”开始,这里传入的是以“classpath:”开头的所以执行else if分支,该分支的判断逻辑是路径是否以“classpath:”开始,判断成立。返回一个ClassPathResource对象。构造参数为截取掉前缀的路径以及类加载器。
这里为什么使用ClassPathResource而不是向scanCandidateComponents方法中使用FileSystemResou-rce,其实很好理解。因为在scanCandidateComponents方法中还不能确定Class资源存放文件系统的何处,而在这里已经能确定Class资源就是存放在类路径下。
// org.springframework.core.io.DefaultResourceLoader#getResource
public Resource getResource(String location) {
Assert.notNull(location, "Location must not be null");
for (ProtocolResolver protocolResolver : getProtocolResolvers()) {
Resource resource = protocolResolver.resolve(location, this);
if (resource != null) {
return resource;
}
}
if (location.startsWith("/")) {
return getResourceByPath(location);
} else if (location.startsWith(CLASSPATH_URL_PREFIX)) {
return new ClassPathResource(location.substring(CLASSPATH_URL_PREFIX.length()), getClassLoader());
} else {
try {
// Try to parse the location as a URL...
URL url = new URL(location);
return (ResourceUtils.isFileURL(url) ? new FileUrlResource(url) : new UrlResource(url));
} catch (MalformedURLException ex) {
// No URL -> resolve as resource path.
return getResourceByPath(location);
}
}
}
方法出栈,返回到getMetadataReader方法帧中,执行接下来的getMetadataReader重载方法,参数类型为Resource。
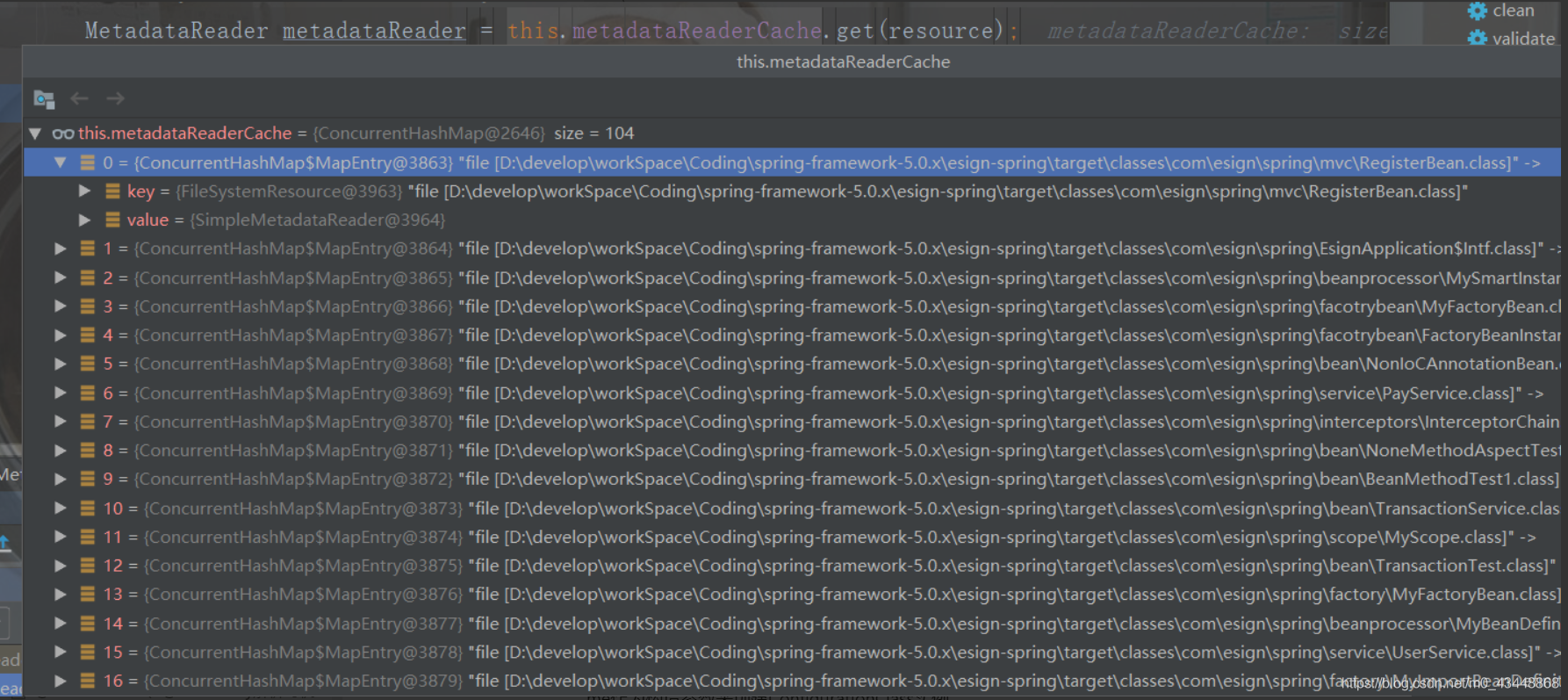
在该方法中,首先判断当前缓存是否是ConcurrentMap类型,当前缓存的实际类型为ConcurrentHas-hMap,因此判断成立(并且这个缓存中还存储了在scanCandidateComponents方法中创建的Metada-Reader,但这明明是两个不同的MetadataReaderFactory。有兴趣追究的小伙伴可以看到最后,我在后面会去追溯这到底是怎么回事)。
如果当前缓存类型不是ConcurrentMap并且该属性不为空,则使用同步锁(synchronized)来保证并发安全。否则不使用缓存。
因为这里使用的ClassPathResource作为key去缓存中查找,所以肯定查找不到,调用父类的getMet-adataReader方法。获取到MetadataReader后,保存到缓存中。
public MetadataReader getMetadataReader(Resource resource) throws IOException {
if (this.metadataReaderCache instanceof ConcurrentMap) {
// 这里使用的是以ClassPathResource作为key来查找,所以第一次肯定查找不到
MetadataReader metadataReader = this.metadataReaderCache.get(resource);
if (metadataReader == null) {
// 调用父类的getMetadataReader方法
metadataReader = super.getMetadataReader(resource);
this.metadataReaderCache.put(resource, metadataReader);
}
return metadataReader;
} else if (this.metadataReaderCache != null) {
synchronized (this.metadataReaderCache) {
MetadataReader metadataReader = this.metadataReaderCache.get(resource);
if (metadataReader == null) {
metadataReader = super.getMetadataReader(resource);
this.metadataReaderCache.put(resource, metadataReader);
}
return metadataReader;
}
} else {
return super.getMetadataReader(resource);
}
}
在父类SimpleMetadataReaderFactory类中,直接创建了SimpleMetadataReader实例(对字节码的元数据的解析就是在该构造函数中完成)。
public MetadataReader getMetadataReader(Resource resource) throws IOException {
return new SimpleMetadataReader(resource, this.resourceLoader.getClassLoader());
}
至此,MetadataReader已经创建完毕,方法返回ConfigurationClassParser的parse方法中,执行接下来的processConfigurationClass方法,在执行该方法前,首先将获取到的MeatdataReader和BeanNa-me作为构造参数来创建ConfigurationClass实例。
这是第二次执行processConfigurationClass方法,第一次是还没有扫描指定包路径下资源,而这一次是已经扫描完包路径下的资源。
在该方法中,首先调用conditionEvaluator的shouldSkip方法来判断当前Class是否需要跳过,这是解析类中@Conditional注解的地方。
经过一系列判断和参数准备后,最后又是调用doProcessConfigurationClass方法。这里为什么又会调用回doProcessConfigurationClass方法呢?
要回答这个问题,我们首先要捋清两次调用doProcessConfigurationClass方法的不同背景。
第一次调用doProcessConfigurationClass方法时,IoC容器还没有去扫描用户指定路径下的Class资源,所以要通过该方法去解析@ComponentScan注解,去扫描并加载指定路径下的资源;
而第二次调用doProcessConfigurationClass,是因为通过第一次调用已经获取到了用户指定路径下的Class资源,并且已经经过了初步过滤,还需要进行再一步的过滤,例如如果用户在这些类中添加了@Conditional注解,并且还没有解析这些Class中的注解,例如@Component、@PropertySource等。
书归正传,在之前的那篇文章中虽然讲过processConfigurationClass这个方法,但没有详细解析这个do…while循环,在这里就详细解析这个do…while循环的处理逻辑。
可以看到这个do…while循环的条件是sourceClass不等于空,doProcessConfigurationClass方法也会返回这个sourceClass,所以就要去看这个方法是怎么返回这个sourceClass的。
protected void processConfigurationClass(ConfigurationClass configClass, Predicate<String> filter) throws IOException {
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
return;
} else {
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
this.configurationClasses.put(configClass, configClass);
}
在doProcessConfigurationClass方法中,先判断方法入参configClass是否添加了@Component注解,如果添加了该注解,则调用processMemberClasses方法处理内部类,详细处理可以参考 内部类是如何被加载进IoC容器的?
注意,只有获取@Component注解的时候是从ConfigurationClass,接下来的对@PropertySource、@ComponentScan、@Import、@ImportResource、@Bean、@ComponentScan注解的获取都是从SourceClass中获取。理清这点特别重要。
处理完内部类之后,接下来就是处理@PropertySource注解。如果类中添加了该注解则调用process-PropertySource方法。
处理完@PropertySource注解后,接下来便是处理@ComponentScan注解,这里就不详细介绍了,在之前的 Spring源码分析-从@ComponentScan注解配置包扫描路径到IoC容器中的BeanDefinition,经历了什么(一)? 文章中已经介绍过了。
// ConfigurationClassParser#doProcessConfigurationClass
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
processMemberClasses(configClass, sourceClass, filter);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}
接下来便是解析类中的@Import注解信息,在解读processImports方法前,这里需要注意的一点是这个getImports方法,它奠定了我们在自定义注解中(无论关系多么复杂)添加@Import注解,应用上下文依然可以解析的原因。详细原因请查看 自定义注解中的@Import是如何被Spring所解析的?
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
processImports方法定义在ConfigurationClassParser类中。在该方法中,首先判断从Class中获取到的注解集合是否为空,其实就是getImports方法的返回值。如果为空,直接返回。否则遍历该集合,判断导入的Class是否是ImportSelector类型,是否ImportBeanDefinitionRegistrar类型,如果不是以上两种类型则认为导入的Class是普通的Bean类型。
这里牵涉出另一个问题,实现ImportSelector或ImportBeanDefinitionRegistrar接口的类会被注册进IoC容器中吗?
答案是不会。仔细阅读贴出processImports方法源码,可以看到当判断Class实现了ImportSelect-or或者ImportBeanDefinitionRegistrar接口时,都是通过ParserStrategyUtils的instantiateClass方法来实例化。
如果是实现了ImportSelector接口,那么则调用其selectImports方法获取到方法返回值,然后转换为SourceClass,递归调用方法本身,方法形参importCandidates为转换好的方法返回值。可以看到对于ImportSelector实现类实例没有进行任何保存动作。
而如果实现了ImportBeanDefinitionRegistrar接口,实例化后,并没有立即调用其registerBeanDefin-itions方法,而是先保存进ConfigurationClass中。可以明确告知的一点,该实例最终并没有保存进IoC容器中。
// ConfigurationClassParser#doProcessConfigurationClass 方法片段
// org.springframework.context.annotation.ConfigurationClassParser#processImports
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass,
Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter,
boolean checkForCircularImports) {
if (importCandidates.isEmpty()) {
return;
}
if (checkForCircularImports && isChainedImportOnStack(configClass)) {
this.problemReporter.error(new CircularImportProblem(configClass, this.importStack));
}
else {
this.importStack.push(configClass);
try {
for (SourceClass candidate : importCandidates) {
if (candidate.isAssignable(ImportSelector.class)) {
// Candidate class is an ImportSelector -> delegate to it to determine imports
Class<?> candidateClass = candidate.loadClass();
// 通过反射来进行实例化
ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class,
this.environment, this.resourceLoader, this.registry);
Predicate<String> selectorFilter = selector.getExclusionFilter();
if (selectorFilter != null) {
exclusionFilter = exclusionFilter.or(selectorFilter);
}
if (selector instanceof DeferredImportSelector) {
this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector);
} else {
// 调用selectImports方法
String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata());
Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames, exclusionFilter);
// 递归调用方法本身
processImports(configClass, currentSourceClass, importSourceClasses, exclusionFilter, false);
}
} else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) {
// Candidate class is an ImportBeanDefinitionRegistrar ->
// delegate to it to register additional bean definitions
Class<?> candidateClass = candidate.loadClass();
ImportBeanDefinitionRegistrar registrar =
ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class,
this.environment, this.resourceLoader, this.registry);
configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata());
} else {
// Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar ->
// process it as an @Configuration class
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
processConfigurationClass(candidate.asConfigClass(configClass), exclusionFilter);
}
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configClass.getMetadata().getClassName() + "]", ex);
}
finally {
this.importStack.pop();
}
}
}
而对于导入的普通类,则是回调processConfigurationClass方法来解析可能会存在的@Component、@ComponentScan、@Bean、@Configuration等注解。
把目光回到doProcessConfigurationClass方法中,执行完processImports方法后,接下来便是解析类中可能存在的@ImportResource注解以及类中方法可能添加的@Bean注解。这些注解的解析过程比较简单就不再解读了。
// ConfigurationClassParser#doProcessConfigurationClass 方法片段
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
比较重要的是接下来的processInterface方法,这能解释为什么我们在接口的默认方法上添加@Bean注解也会被处理。
// ConfigurationClassParser#doProcessConfigurationClass 方法片段
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
在该方法中,遍历当前类实现的所有接口以及接口继承的接口,这是一个递归。然后调用retrieveBe-anMethodMetadata方法来获取接口中所有添加了@Bean注解的方法。
最后遍历这些方法,对于每一个遍历到的方法,都会判断是否是抽象的,如果不是抽象的,则添加到当前ConfigurationClass的beanMethods集合中。
// ConfigurationClassParser#processInterfaces
private void processInterfaces(ConfigurationClass configClass, SourceClass sourceClass) throws IOException {
for (SourceClass ifc : sourceClass.getInterfaces()) {
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(ifc);
for (MethodMetadata methodMetadata : beanMethods) {
if (!methodMetadata.isAbstract()) {
// A default method or other concrete method on a Java 8+ interface...
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
}
processInterfaces(configClass, ifc);
}
}
在retrieveBeanMethoMetadata方法中,Spring首先基于JVM提供的反射技术来获取接口中所有添加了@Bean注解的方法,然后判断获取到的方法集合长度是否大于1,注意理解这个集合长度是否大于1十分重要,因为它和接下来的注释配合解释了为什么要通过ASM技术再次读取字节码获取类中的注解元信息。
Spring对此解释是JVM的反射是以任意方式返回方法顺序,而Spring需要确定方法的声明顺序。如果通过JVM反射技术获取的方法集合长度小于或等于1,那就没有必要去确定顺序了。
// ConfigurationClassParser#retrieveBeanMethodMetadata
private Set<MethodMetadata> retrieveBeanMethodMetadata(SourceClass sourceClass) {
AnnotationMetadata original = sourceClass.getMetadata();
Set<MethodMetadata> beanMethods = original.getAnnotatedMethods(Bean.class.getName());
if (beanMethods.size() > 1 && original instanceof StandardAnnotationMetadata) {
// Try reading the class file via ASM for deterministic declaration order...
// Unfortunately, the JVM's standard reflection returns methods in arbitrary
// order, even between different runs of the same application on the same JVM.
try {
AnnotationMetadata asm =
this.metadataReaderFactory.getMetadataReader(original.getClassName()).getAnnotationMetadata();
Set<MethodMetadata> asmMethods = asm.getAnnotatedMethods(Bean.class.getName());
if (asmMethods.size() >= beanMethods.size()) {
Set<MethodMetadata> selectedMethods = new LinkedHashSet<>(asmMethods.size());
for (MethodMetadata asmMethod : asmMethods) {
for (MethodMetadata beanMethod : beanMethods) {
if (beanMethod.getMethodName().equals(asmMethod.getMethodName())) {
selectedMethods.add(beanMethod);
break;
}
}
}
if (selectedMethods.size() == beanMethods.size()) {
// All reflection-detected methods found in ASM method set -> proceed
beanMethods = selectedMethods;
}
}
}
catch (IOException ex) {
logger.debug("Failed to read class file via ASM for determining @Bean method order", ex);
// No worries, let's continue with the reflection metadata we started with...
}
}
return beanMethods;
}
执行完processInterfaces方法后,接下来便是解释前面提到的processConfigurationClass方法中的d-o…while循环。
在processConfigurationClass方法的do…while循环的判断条件是当前方法返回的SourceClass不为nu-ll,这里便是返回SourceClass的地方。首先判断当前SourceClass是否存在父类,如果不存在父类直接返回null。
如果存在父类,则先获取到父类的全限定名,判断条件为父类的全限定名不为null,并且父类的全限定名不以“java”开始并且不是已知的父类型(因为可能多个类继承与一个父类,没必要每次处理其子类的时候都处理一遍父类)。如果判断成立,直接返回当前类的父类。
注意这里返回当前类的父类意味着什么?这意味这即便父类是抽象类,你也可以在其中添加任何应用上下文支持的注解,一样会得到处理。
// ConfigurationClassParser#doProcessConfigurationClass
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
也许有小伙伴会有疑问,那如果在抽象父类中添加内部类,在内部类上添加@Component注解,那么会被注册进IoC容器吗?因为前面解释只有在Class上添加@Component注解才会去解析其内部类信息,答案是肯定。
这需要把目光回到processConfigurationClass方法中的do…while循环中,可以看到在这个循环中唯一会发生变化的就是SourceClass。前面提到过在doProcessConfigurationClass中只有在获取@Compo-nent的时候是基于ConfigurationClass,而获取和解析其它注解的时候是基于SourceClass。
这里就很好解释了ConfigurationClass和SourceClass的不同。ConfigurationClass和SourceClass虽然在do…while循环开始的时候,持有的都是同一个Class的信息,但是当进入第二次循环的时候,Conf-igurationClasss持有的Class信息不变,而SourceClass中的Class信息已经变为当前类的父类或者爷爷类甚至祖宗类(这个要看类的继承结构有多深)的信息。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2zpTLkgT-1610455543440)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/9af76c69-26f6-4323-803a-cd19a7564ddb/Untitled.png)]](https://img-blog.csdnimg.cn/20210113094046922.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQzNDQ4ODY4,size_16,color_FFFFFF,t_70)
解惑:两个不同的CachingMetadataReaderFacotry实例,为什么其metadataR-eaderCache中存放的数据却是一致的?
要回答这个问题这就要分析当前属性metadataReaderCache是何时被初始化的?而要追溯这个属性是何时被初始化的,就要追溯CachingMetadataReaderFacotry是何时被初始化的,因为这是该类里面的一个属性。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FS5ih8qZ-1610455543442)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/082bb364-df39-417e-b386-9db8a5f95b03/Untitled.png)]](https://img-blog.csdnimg.cn/20210113094123390.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQzNDQ4ODY4,size_16,color_FFFFFF,t_70)
这就要回到ConfigurationClassPostProcessor类中,因为在其proccessConfigBeanDefinitions方法中创建的ConfigurationClassParser,并将自己的metadataReaderFactory属性值作为构造函数参数一并传入。
// ConfigurationClassPostProcessor#processConfigBeanDefinitions
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
// 省略其它代码.....
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
// 省略其它代码.....
}
在ConfigurationClassPostProcessor类中,对metadataReaderFactory参数直接进行了实例化,这意味这ConfigurationClassPostProcessor构造函数执行完毕时,metadataReaderFactory属性已经有值。但这里使用的CachingMetadataReaderFactory的无参构造函数,这点特别重要。
private MetadataReaderFactory metadataReaderFactory = new CachingMetadataReaderFactory();
因为使用无参构造函数初始化的CahingMetadataReaderFactory其所使用的缓存是LocalResourceCac-he而不是ConcurrentHashMap,LocalResourceCache继承于LinkedHashMap。
而如果ConfigurationClassPostProcessor传递给ConfigurationClassParser的MetadataReaderFactory是这个CachingMetadataReaderFactory实例的话,那不可能出现前面我们所看到缓存类型是Concurren-tHashMap类型。
public CachingMetadataReaderFactory() {
super();
setCacheLimit(DEFAULT_CACHE_LIMIT);
}
public void setCacheLimit(int cacheLimit) {
if (cacheLimit <= 0) {
this.metadataReaderCache = null;
}
else if (this.metadataReaderCache instanceof LocalResourceCache) {
((LocalResourceCache) this.metadataReaderCache).setCacheLimit(cacheLimit);
}
else {
this.metadataReaderCache = new LocalResourceCache(cacheLimit);
}
}
private static class LocalResourceCache extends LinkedHashMap<Resource, MetadataReader> {
//....
}
这里面肯定是又重新创建了该对象,并且还不是使用这个无参构造函数。那再看看还有没有其它构造函数,可以发现CachingMetadataReaderFactory还存在另外两个有参构造函数,其中一个构造函数的参数类型为ClassLoader,另一个构造函数参数类型为ResourceLoader。
构造函数参数类型为ClassLoader的明显不是我们所要寻找的目标函数,因为它调用的还是setCache-Limit方法。那就只有构造参数类型为ResourceLoader的构造函数了。
public CachingMetadataReaderFactory(@Nullable ClassLoader classLoader) {
super(classLoader);
setCacheLimit(DEFAULT_CACHE_LIMIT);
}
public CachingMetadataReaderFactory(@Nullable ResourceLoader resourceLoader) {
super(resourceLoader);
if (resourceLoader instanceof DefaultResourceLoader) {
this.metadataReaderCache =
((DefaultResourceLoader) resourceLoader).getResourceCache(MetadataReader.class);
}
else {
setCacheLimit(DEFAULT_CACHE_LIMIT);
}
}
在这个构造函数中,多了一个逻辑判断,判断传递的ResourceLoader类型是不是DefaultResource类型,我们先假设判断条件成立。看看这个getResourceCache方法做了什么。
该方法定义在DefaultResourceLoader类中,可以看到其就是通过调用Map的computeIfAbsent方法来保证key和值只会被设置一次。问题就在这个Key上,只要能保证创建不同CachingMetadataFactory都使用参数类型为ResourceLoader的构造函数,传递的ResourceLoader是DefaultResourceLoader类型或者相同的子类型就能保证它们的缓存都是同一个。
那我们就可以推断ConfigurationClassPostProcessor在某个时机又重新创建了一次CachingMetadata-ReaderFactory实例,并且使用的是参数类型为ResourceLoader构造函数。然后把这个实例作为Conf-igurationClassParser的构造参数传递。
private final Map<Class<?>, Map<Resource, ?>> resourceCaches = new ConcurrentHashMap<>(4);
// org.springframework.core.io.DefaultResourceLoader#getResourceCache
public <T> Map<Resource, T> getResourceCache(Class<T> valueType) {
return (Map<Resource, T>) this.resourceCaches.computeIfAbsent(valueType, key -> new ConcurrentHashMap<>());
}
目光回到ConfigurationClassPostProcessor类中,查看ConfigurationClassPostProcessor类的继承关系图(Idea快捷键ctrl+alt+shift+u或者ctrl+alt+u)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zV7Twmx0-1610455543443)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/2ce40a48-8674-4528-9d20-10f17a8d0c8e/Untitled.png)]](https://img-blog.csdnimg.cn/20210113094155851.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQzNDQ4ODY4,size_16,color_FFFFFF,t_70)
可以看到该类除了实现BeanDefinitionRegistryPostProcessor接口还实现了EnvironmentAware、Reso-urceLoaderAware、BeanClassLoaderAware这些接口。我们都知道实现这些接口意味着在IoC容器实例化该Bean的时候会对这些接口方法进行回调并传入相应的方法参数。
这其中最值得注意的便是实现了ResourceLoader接口,这意味着IoC容器会给其传递ResourceLoader实例。再看看其实现的setResourceLoader方法,可以发现这里又重新对属性metadataReaderFactory进行赋值(setMeatdataReaderFactoryCalled属性默认为false)。
private boolean setMetadataReaderFactoryCalled = false;
public void setResourceLoader(ResourceLoader resourceLoader) {
Assert.notNull(resourceLoader, "ResourceLoader must not be null");
this.resourceLoader = resourceLoader;
if (!this.setMetadataReaderFactoryCalled) {
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
}
}
对ClassPathScanningCandidateComponentProvider的scanCandidateComponents方法进行断点计算可以发现其使用的CachingMatadataReaderFactory实例中的metadataReaderCache属性的具体类型为ConcurrentHashMap。
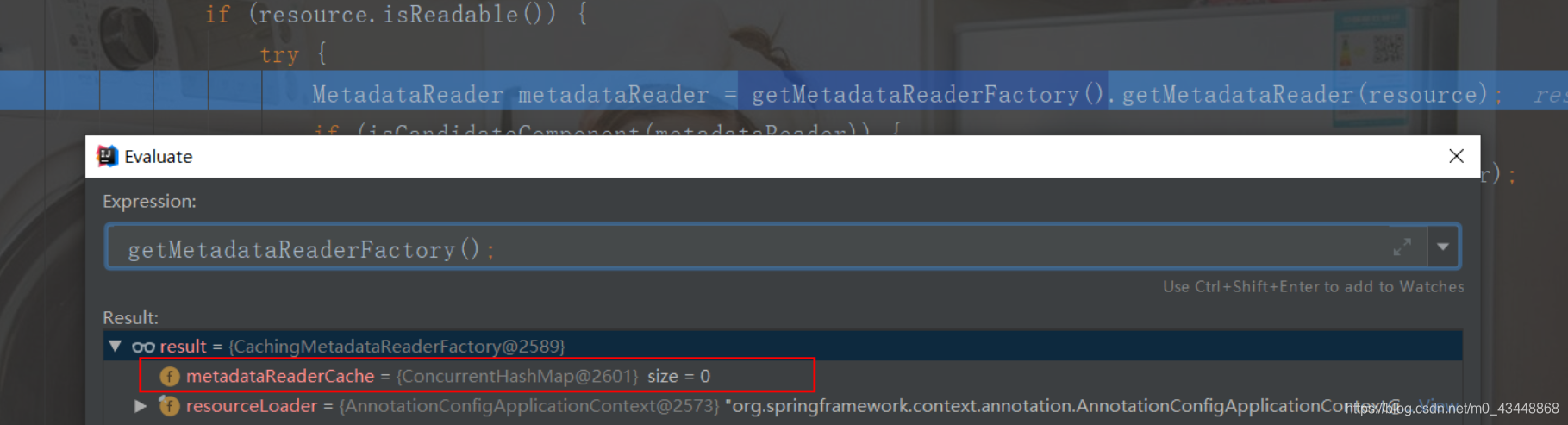
综合前文分析的CachingMatadataReaderFactory的构造函数来分析,只有使用参数类型为ResourceL-oader的构造函数才能创建ConcurrentHashMap类型的Map,而这个Map在DefaultResourceLoader中被限定为只要传递的相同的DefaultResourceLoader或者其具体子类性就会得到相同的Map。
显然在ClassPathScanningCandidateComponentProvider创建CachingMetadataReaderFactory时使用的ResourceLoader和ConfigurationClassPostProcessor的setResourceLoader方法中使用ResourceLoa-der是同一个。
接下来便进行求证,目光回到ComponentScanAnnotationParser的parse方法,因为在该方法中创建了ClassPathBeanDefinitionScanner实例(ClassPathBeanDefinitionScanner是ClassPathScanningCandi-dateComponentProvider的子类,详细了解请查看该系列的第一篇文章),传入的resourceLoader为当前实例属性。
// ComponentScanAnnotationParser#parse
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, final String declaringClass) {
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
//省略其它代码...
}
先看看ClassPathBeanDefinitionScanner的构造函数,可以看到在该方法的最后调用一个名为setReso-urceLoader的方法。该方法由其父类实现。
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(resourceLoader);
}
再次回到ClassPathScanningCandidateComponentProvider的setResourceLoader方法中,可以看到其调用了参数类型为ResourceLoder的构造函数来实例化CachingMetadataReaderFactory。
// ClassPathScanningCandidateComponentProvider#setResourceLoader
public void setResourceLoader(@Nullable ResourceLoader resourceLoader) {
this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader);
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
this.componentsIndex = CandidateComponentsIndexLoader.loadIndex(this.resourcePatternResolver.getClassLoader());
}
现在最后的问题就是ComponentScanAnnotationParser的ResourceLoader属性的值是如何而来。在该类中其将ResourceLoader属性设置为final类型,这意味着只能在构造函数中进行赋值,并且只能赋一次值。因此只需要找到是何时创建该类实例即可。
private final ResourceLoader resourceLoader;
public ComponentScanAnnotationParser(Environment environment, ResourceLoader resourceLoader,
BeanNameGenerator beanNameGenerator, BeanDefinitionRegistry registry) {
this.environment = environment;
this.resourceLoader = resourceLoader;
this.beanNameGenerator = beanNameGenerator;
this.registry = registry;
}
我们把调用链继续往前移,回到ConfigurationClassParser的doProcessConfigurationClass方法,因为在该方法中调用了ComponentScanAnnotationParser的parse方法,那就继续排查什么时候初始化的该实例。
// ConfigurationClassParser#doProcessConfigurationClass
protected final SourceClass doProcessConfigurationClass(
ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter)
throws IOException {
// 省略其它代码...
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// 省略其它代码...
}
可以看到是在ConfigurationClassParser的构造函数中实例化的ComponentScanAnnotationParser,并且使用的都是同一个ResourceLoader,这就不难解释为什么我们看到两个不同的CachingMetadataR-eaderFactory实例,但是它们的缓存(Map)对象却是同一个。
public ConfigurationClassParser(MetadataReaderFactory metadataReaderFactory,
ProblemReporter problemReporter, Environment environment, ResourceLoader resourceLoader,
BeanNameGenerator componentScanBeanNameGenerator, BeanDefinitionRegistry registry) {
this.metadataReaderFactory = metadataReaderFactory;
this.problemReporter = problemReporter;
this.environment = environment;
this.resourceLoader = resourceLoader;
this.registry = registry;
this.componentScanParser = new ComponentScanAnnotationParser(
environment, resourceLoader, componentScanBeanNameGenerator, registry);
this.conditionEvaluator = new ConditionEvaluator(registry, environment, resourceLoader);
}
在哪里调用ConfigurationClassPostProcessor这里就不再解释了,因为在 从@ComponentScan注解配置包扫描路径到IoC容器中的BeanDefinition,经历了什么(一)?中已经全链路分析过了。















 3644
3644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









