







思考这个问题之前 , 我们先来看看什么是并发
并发 : 同时拥有两个或者线程 , 如果程序在单核处理器上运行 , 多个线程将会交替的换入或者换出内存 , 这些线程是同时 " 存在 " 的 , 每个线程都处于执行过程中的某个状态 , 如果运行在多核处理器上 , 此时程序中的每个线程都会被分配到一个对应处理核上 , 因此可以同时运行
那什么是高并发呢 ?
高并发 : 高并发High Concurrency是互联网分布式系统架构设计中必须考虑的因素之一 , 通常指通过设计保证系统能够同时并行处理很多请求 .
那我们在程序设计开发中谈到并发和高并发问题又是指什么呢 ?
并发问题 : 多个线程操作相同的资源 , 保证线程安全 , 合理运用资源
高并发问题 : 服务能同时处理很多请求 , 提高程序性能
talk is cheap ; show me the code
我们通过一个简单的案例看一看并发问题的产生
/**
* @Description
* @Author apdoer
* @Date 2019/8/4 15:39
* @Version 1.0
*/
@Slf4j
public class TestCount {
//线程数
private static int threadTotal = 200;
//系统在短时间内接收到请求数
private static int clientTotal = 5000;
//计数器
private static long count = 0;
public static void main(String[] args) {
//线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//信号量 限制线程并发数量
final Semaphore semaphore = new Semaphore(threadTotal);
for (int i = 0; i < clientTotal; i++) {
executorService.execute(()->{
try {
semaphore.acquire();
add();
semaphore.release();
} catch (InterruptedException e) {
log.error("发生错误:{}",e);
}
});
}
executorService.shutdown();
log.info("count:{}",count);
}
private static void add() {
count++;
}
}
这段代码用线程池和信号量模拟200个线程的5000次请求 , 在执行这段代码之前 , 我们先来预期一下 , 理论上5000次请求 , 结果就应该是5000
对于线程池和信号量不熟的童鞋 , 可以自行学习 , 也可翻阅本博客后面的相关文章
那我们来验证下

无论执行多少次 , 结果都不符合期望
好的,我们再来看看下面这段代码
/**
* @Description
* @Author apdoer
* @Date 2019/8/4 15:48
* @Version 1.0
*/
@Slf4j
public class TestMap {
private static Map<Integer,Integer> map = new HashMap<>();
//线程数
private static int threadNum = 200;
//模拟请求数量
private static int clientNum = 5000;
public static void main(String[] args) {
//线程池
ExecutorService executorService = Executors.newCachedThreadPool();
//信号量 , 同一时刻限制200个线程执行
Semaphore semaphore = new Semaphore(threadNum);
for (int i = 0; i < clientNum; i++) {
//每次请求过来的时候,把索引和值放到map中
final int threadNum = i;
executorService.execute(()->{
try {
semaphore.acquire();
func(threadNum);
semaphore.release();
} catch (InterruptedException e) {
log.error("exception occured:{}",e);
}
});
}
executorService.shutdown();
log.info("size:{}",map.size());
}
private static void func(int threadNum) {
map.put(threadNum,threadNum);
}
}
依然是模拟200个线程5000次请求 , 这次我们用了map来作为计数器 , 那么这次是否能达到我们的预期结果呢

很显然 , 依然是不可以
接下来我们把线程数改为 1
再执行两段代码 , 可以发现无论多少次执行 , 都成功的输出了5000 , 这也解释了很多设计多线程并发的问题为什么我们本地测的明明可以 , 拿到线上就不符合预期 , 因为我们本地自测基本都是一个线程在跑
以上我们都是在描述一个现象 , 在并发时,普通的累加操作结果可能是错的 , 那么产生这个现象的原因是什么呢 ?
先来认识一下 CPU
CPU 多级缓存

在上图中:
- 应用了高速缓存 ; CPU和高速缓存中间有一条快速的通道
- 主存memory和高速缓存都连在系统总线上 , 这条总线还用于其他组件的通信
- 在高速缓存出现后不久 , 系统变得更为复杂 , 高速缓存和主存之间速度差距更大 , 但是加大一级缓存的做法在经济的角度考虑是行不通的 , 所有后面出现了二级缓存和三级缓存
为什么需要 CPU Cache ?
CPU的频率太快了 , 快到主存跟不上 , 这样在处理器的时钟周期内 ,CPU经常需要等待主存 , 浪费资源 , 所以cache的出现 , 是为了缓解CPU和内存之间速度的不匹配问题
结构 :CPU->cache->memory
既然缓存不能包含CPU所需的所有数据
CPU cache有什么意义
1 . 时间局部性 : 如果某个数据被访问 , 那么他在不久的将来很可能再次被访问
2 . 空间局部性 : 如果某个数据被访问 , 那么与他相邻的数据很快也可能被访问
在这里插入图片描述
CPU多级缓存 - 缓存一致性MESI
用于保证多个
CPU cache之间缓存共享的数据的一致

下图代表了保证缓存一致性的逻辑
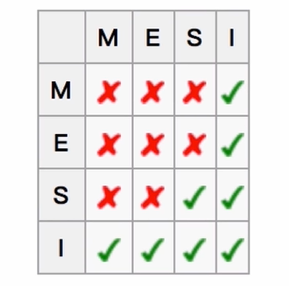
java内存模型 JMM(java memory model)

这里有个很重要的概念就是 : 如果两个线程都持有同一个对象的引用 , 实际上操作的是各自线程拥有的私有拷贝

缓存的存在都是因为主存远远慢于CPU的频率 , 所以需要高速缓存来即时的跟上CPU的速度
java内存模型抽象结构图

到了这里前面的计数器为什么不是5000就很明了了
- 线程A拿着主存中的共享变量拷贝到本地内存中然后在线程栈中执行计数操作
- 线程B也拿着主存的共享变量拷贝到本地内存中在自己的线程栈中执行技术操作
- 但是线程A对共享变量的改变其他的线程并不知道 , 这就是无法同步的原因
有没有什么办法能够让某个线程对共享变量的改变可以即使的通知到其他的线程呢 ? 或者说让每个线程在对共享变量操作时总是先去主存中再加载一次呢 ?
java内存模型 - 同步操作与规则

八中同步操作
lock(锁定) : 作用于主存的变量 , 把变量标识为一个线程独占状态unlock(解锁) : 作用于主存的变量 , 把一个处于锁定状态的变量释放 , 释放后的变量才可以被其他线程锁定 , 一个线程只能释放自己锁定的变量read(读取) : 作用于主存的变量 , 把一个变量的值从主存中传输到工资内存的中的变量中 , 以便后续的load操作使用load(载入) :作用于工作内存的变量 , 它把read操作从主存中读取的变量值放到工作内存保存的副本中use(使用) : 使用工作内存中的变量 , 把内存中的一个变量值传给执行引擎assign(赋值) : 作用于工作内存中的变量 , 它把一个从执行引擎接收到值赋值给工作内存的变量store(存储) : 作用于工作内存的变量 , 把工作内存的一个变量值传递到主存中 , 以便后续的write操作- write(写入) : 作用于主存的变量 , 它把
store操作从一个工作内存的变量的值传送到一个主内存的变量中
同步规则
- 主内存的变量有两种状态
lock和unlock, 当锁定的时候就不会执行load到工作内存 / 本地内存的操作,自然线程栈也就无法使用主存中的这块变量 - 反过来 , java线程栈对从主存中拿到的变量操作时会先提交到本地内存 / 工作内存 ,然后执行存写的操作 , 将改变同步到主存中,
- 当然这些操作都得是在主存中的这块变量处于
unlock的状态才行 - 通过这样的机制来保证共享变量的数据一致性
- 值得注意的是 read 和 load 不是连续执行的 , 可能会有别的指令提交 , 同理 write 和 store 也是
- 不允许没有任何操作的变量同步回主存 , 即没经过
Assign操作 - 一个新的内存变量只能在主存中诞生 , 不允许在工作内存中直接使用一个未被初始化的变量 , 就是对一个变量进行
use和store操作之前 , 必须经过了assign和load操作 - 如果执行了
lock, 本地内存中的变量会清空,重载 - 只有自己
lock的线程才能对lock的变量执行unlock操作 , 但是lock操作可以被一个线程执行多次 , 执行多次lock,必须执行相同次数的unlock, 该变量才会解锁 ,lock和unlock必须成对的出现read - 不允许
read和load,store,write操作之一单独出现 - 不允许一个线程丢弃它最近的assign操作 , 即变量在工作区域改变了之后必须同步回主内存
- 对一个变量执行
unlock之前 , 必须先把变量同步到主内存中 ,(执行store和write操作)
并发的优势和风险

总结
CPU多级缓存 : 缓存一致性 , 乱序执行优化
java内存模型 : JMM规定 , 抽象结构 , 同步八种操作及同步策略
并发的优势和风险















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









