







写在前面:在查看本文之前,需要先学习01、VMware中Centos7安装教程搭建好虚拟机以及需要学会克隆虚拟机。因为整个完全分布式集群的搭建至少需要3台机器,需要克隆2台命名为slave1与slave2两个从节点,而被克隆的主机称为主节点master。
1、 修改主机名
本次集群搭建共有三个节点,包括一个主节点master,和两个从节点slave1和slave2。具体操作如下:
1.以主机点master为例,首次切换到root用户:su
2.修改主机名为master: hostnamectl set-hostname <hostsname>

3.永久修改主机名,编辑/etc/sysconfig/network文件,内容如下:
NETWORKING=yes
HOSTNAME=master
保存该文件,重启计算机:reboot 查看是否生效:hostname

可以看到再重启之后主机名修改成功:

2、 配置hosts文件
使各个节点能使用对应的节点主机名连接对应的地址。
hosts文件主要用于确定每个结点的IP地址,方便后续各结点能快速查到并访问。在上述3个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少.
1.可以通过ifconfig命令进行查看。

2.查看节点地址之后将三个节点的ip地址以及其对应的名称写进hosts文件。这里我们设置为 master、slave1、slave2。注意保存退出。

3、 关闭防火墙
centos7中防火墙命令用firewalld取代了iptables,当其状态是dead时,即防火墙关闭。
关闭防火墙:systemctl stop firewalld
查看状态:systemctl status firewalld

4、 时间同步
1.时区一致。要保证设置主机时间准确,每台机器时区必须一致。实验中我们需要同步网络时间, 因此要首先选择一样的时区。先确保时区一样,否则同步以后时间也是有时区差。
可以使用date查看自己的机器时间

2.选择时区:tzselect
由于hadoop集群对时间要求很高,所以集群内主机要经常同步。我们使用ntp进行时间同步,master作为ntp服务器,其余的当做ntp客户端。 下面依次输入Tzselect、 5、 9、 1、 1;

3. NTP是网络时间协议(Network Time Protocol),它是用来同步网络中各个计算机的时间的协议。
yum install –y ntp
4.master作为ntp服务器,修改ntp配置文件。(master上执行)
vi /etc/ntp.conf#以本地时间作为时间服务
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 10 #这行是时间服务器的层次。设为0则为顶级,如果要向别的NTP服务器更。 新时间,请不要把它设为0;stratum设置为其它值也是可以的,其范围为0~15

重启ntp服务。
/bin/systemctl restart ntpd.service
5. 其他机器同步(slave1,slave2) 等待大概五分钟,再到其他机上同步该机器时间。
ntpdate master
5、 配置SSH免密
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
1. 每个结点分别产生公私密钥:ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
-t参数就是指定要生成的密钥类型,你这里指定的是dsa
-P就是你提供的旧密码, ‘’ 表示没有
-f是密钥的生成后的保存文件位置
秘钥产生目录在用户主目录下的.ssh目录中,进入相应目录查看:cd .ssh/
ssh-keygen
ssh-copy-id ip或主机名

6、 JDK简介及其安装
1.首先建立工作路径/usr/java。
mkdir -p /usr/java
tar -zxvf /opt/soft/jdk-8u171-linux-x64.tar.gz -C /usr/java/

2.修改环境变量

修改环境变量:vi /etc/profile
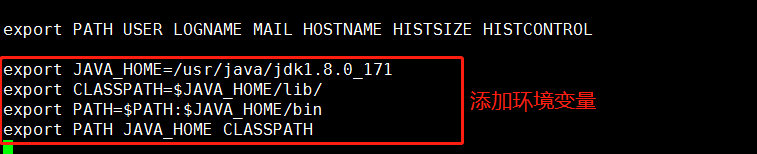
添加内容如下:
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib/ #作用是指定类搜索路径,要使用已经编写好的类,前提当然是能够找到它们了,JVM就是通过CLASSPTH来寻找类的。
export PATH=$PATH:$ JAVA_HOME/bin #我们需要把jdk安装目录下的bin目录增加到现有的PATH变量中,bin目录中包含经常要用到的可执行文件
export PATH JAVA_HOME CLASSPATH
生效环境变量:source /etc/profile
查看java版本:java -version

同理slave节点,相同安装步骤。
注意:如果在slave节点中安装较慢,可以使用scp命令,将相同的文件从master中复制过来。 在master中将JDK复制到slave2中。

7、 Zookeeper讲解及安装
Zookeeper字面上理解就是动物管理员,Hadoop生态圈中很多开源项目使用动物命名,例如:Hive(蜜蜂)、Pig(小猪)。这就需要一个管理员来管理这些“动物”。在集群的管理中Zookeeper起到非常重要的角色负责分布式应用程序协调的工作——它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。

Zookeeper服务自身组成一个集群(2n+1个服务允许n个失效)。Zookeeper服务有两个角色,一个是leader,负责写服务和数据同步,剩下的是follower,提供读服务,leader失效后会在follower中重新选举新的leader。
- 客户端可以连接到每个server,每个server的数据完全相同。
- 每个follower都和leader有连接,接受leader的数据更新操作。
- Server记录事务日志和快照到持久存储。
- 大多数server可用,整体服务就可用。
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和Leader的状态同步以后,恢复模式就结束了。状态同步保证了Leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,Zookeeper采用了递增的事务ID号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。zxid是一个64位的数字,它高32位是epoch用来标识Leader关系是否改变,每次一个Leader被选出来,它都会有一个新的epoch,标识当前属于那个Leader的统治时期。低32位用于递增计数。
每个Server在工作过程中有三种状态:
- LOOKING:当前Server不知道Leader是谁,正在搜寻;
- LEADING:当前Server即为选举出来的Leader;
- FOLLOWING:leader已经选举出来,当前Server与之同步。
Zookeeper的出现解决了这个问题。首先Zookeeper简化了一个选举算法,实现原子广播协议,简称Zab协议。举个例子:一个Zookeeper集群有一个Leader,其他的都是Follower跟随者,这个Leader是怎么选举出来的呢?一开始三台机器ABC,分别启动Zookeeper以后,发现没有Leader,就提议进行Leader选举,只要半数以上通过就算成功,过程为:
- A提案说,我要选自己,B你同意吗?C你同意吗?B说,我同意选A;C说,我同意选A。(注意,这里超过半数了,其实在现实世界选举已经成功了。但是计算机世界是很严格,另外要理解算法,要继续模拟下去。)
- 接着B提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;C说,A已经超半数同意当选,B提案无效。
- 接着C提案说,我要选自己,A你同意吗;A说,我已经超半数同意当选,你的提案无效;B说,A已经超半数同意当选,C的提案无效。
- 选举已经产生了Leader,后面的都是Follower,只能服从Leader的命令。
这个过程产生了leader后,Zookeeper就可以开始工作了,工作的过程中,理论上每个Zookeeper的数据都是一致的,如果某一个节点出了问题,只要还有超过半数的节点正常,那整个集群就可以正常工作,所以Zookeeper首先实现了自己的高可用,然后Zookeeper还可以保存数据,协调控制数据。其角色功能如表

解压压缩包
- mkdir –p /usr/zookeeper
- tar –zxvf /opt/soft/zookeeper-3.4.10.tar.gz –C /usr/zookeeper
修改zookeeper配置文件
- cp zoo_sample.cfg zoo.cfg
- mkdir zkdata
- mkdir zkdatalog
- vi myid
- scp -r /usr/zookeeper root@slave1:/usr/
- scp -r /usr/zookeeper root@slave2:/usr/
修改环境变量
- vi /etc/profile
- source /etc/profile
启动zookeeper
- bin/zkServer.sh start
- bin/zkServer.sh status
1. 修改主机名称到IP地址映射配置。
vi /etc/hosts
192.168.15.104 master master.root
192.168.15.127 slave1 slave1.root
192.168.15.124 slave2 slave2.root

2. 修改ZooKeeper配置文件。在其中一台机器(master)上,用tar -zxvf 命令解压缩zookeeper-3.4.6.tar.gz。

3. 配置文件zoo.cfg 进入zookeeper配置文件夹conf,将zoo_sample.cfg文件拷贝一份命名为zoo.cfg,Zookeeper 在启动时会找这个文件作为默认配置文件。
- cd /usr/zookeeper/zookeeper-3.4.10/conf/
- cp zoo_sample.cfg zoo.cfg
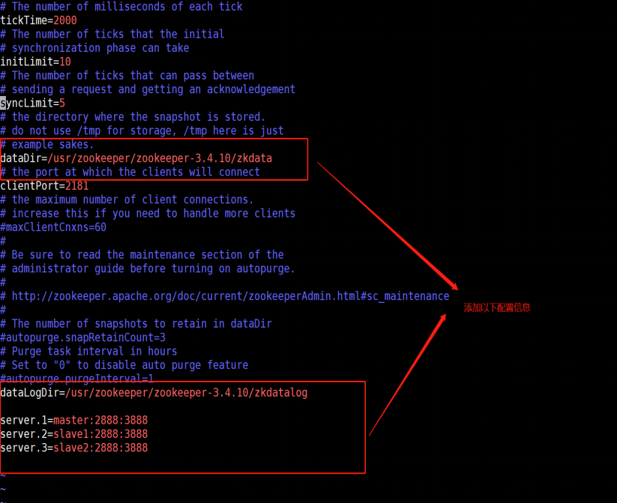
对zoo.cfg文件配置如下:
tickTime=2000
#基本事件单元,以毫秒为单位。它用来指示心跳,最小的session过期时间为两倍的tickTime
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
#dataDir 为存储内存中数据库快照的位置,如果不设置参数,更新事务日志将被存储到默认位置。这里使用我们自己设定位置。
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
#指定zookeeper产生日志村放目录路径
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
1.tickTime:CS通信心跳数
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime:该参数用来定义心跳的间隔时间,zookeeper的客户端和服务端之间也有和web开发里类似的session的概念,而zookeeper里最小的session过期时间就是tickTime的两倍。
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间 初始连接 时能容忍的最多心跳数(tickTime的数量)。
此配置表示,允许 follower (相对于 leader 而言的“客户端”)连接 并同步到 leader 的初始化连接时间,它以 tickTime 的倍数来表示。当超过设置倍数的 tickTime 时间,则连接失败。
3.syncLimit:LF同步通信时限
集群中的follower服务器(F)与leader服务器(L)之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)。
此配置表示, leader 与 follower 之间发送消息,请求 和 应答 时间长度。如果 follower 在设置的时间内不能与leader 进行通信,那么此 follower 将被丢弃。
server.A=B:C:D
Master.1=master:2888:3888
A:是一个数字(机器重启默认从0开始),表示这个是第几号服务器;
B:是这个服务器的ip地址,zookeeper是在hosts中映射了本机的IP,因此也可以写为服务器的映射名;
C:表示的是这个服务器与集群中的Leader服务器交换信息的端口;
D:表示的是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
2888端口号是服务之间通信的端口,而3888是zookeeper与其他应用程序通信的端口。
在zookeeper的目录中,创建配置中所需的zkdata和zkdatalog两个文件夹。
mkdir zkdata
mkdir zkdatalog

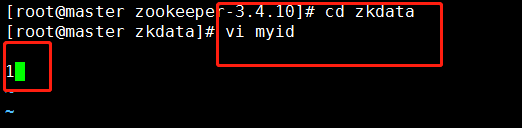
5. 进入zkdata文件夹,创建文件myid,用于表示是几号服务器。master主机中,设置服务器id为1。
6.远程复制分发安装文件。
以上已经在主节点master上配置完成ZooKeeper,现在可以将该配置好的安装文件远程拷贝到集群中的各个结点对应的目录下(这时候子节点):
scp -r /usr/zookeeper root@slave1:/usr/
scp -r /usr/zookeeper root@slave2:/usr/

7. 设置myid。在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字。 cd /usr/zookeeper/zookeeper-3.4.10/zkdata实验中设置slave1中为2;

slave2中为3:

8. 修改/etc/profile文件,配置zookeeper环境变量。
vi /etc/profile
#set zookeeper environment
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10 PATH=$PATH:$ZOOKEEPER_HOME/bin

9. 启动ZooKeeper集群。在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本。注意在zookeeper目录下:
bin/zkServer.sh start
bin/zkServer.sh status
通过上面状态查询结果可见,一个节点是Leader,其余的结点是Follower。 至此,zookeeper安装成功。




















 165
165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











