







目录
1、和数组的区别
(1)数组长度固定,集合长度不固定
(2)数组可以存放基本类型和引用类型,集合只能存储引用类型(常用类型的包装类的引用也可以放到集合中)
2、Collection的体系架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RurqqHZi-1608137963166)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125103931590.png)]](https://img-blog.csdnimg.cn/20201217010042239.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
3、Collection的常用方法
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j8a1yZ0J-1608137963175)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125104243806.png)]](https://img-blog.csdnimg.cn/20201217010102576.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
(1)添加元素
//1.创建集合
Collection collection = new ArrayList();
//(1)添加元素
collection.add("苹果");
collection.add("西瓜");
collection.add("榴莲");
System.out.println("元素的个数: "+ collection.size());
System.out.println(collection);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iW7nt4Xh-1608137963177)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125105203066.png)]](https://img-blog.csdnimg.cn/20201217010113460.png)
(2)删除元素
//(2) 删除元素
collection.remove("榴莲");
System.out.println("删除之后: " + collection.size());
System.out.println(collection);
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k42crH5b-1608137963181)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125105454597.png)]](https://img-blog.csdnimg.cn/20201217010130978.png)
//清空元素
collection.clear();
System.out.println("清空之后" + collection.size());
System.out.println(collection);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CRmnIm80-1608137963185)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125105653141.png)]](https://img-blog.csdnimg.cn/20201217010144571.png)
(3)遍历元素
//(3) 遍历元素
//3.1 增强for
System.out.print("增强for遍历元素: ");
for (Object o : collection) {
System.out.print(o + " ");
}
System.out.println();
//3.2 迭代器
System.out.print("使用迭代器遍历元素: ");
Iterator iterator = collection.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RrSWz5AJ-1608137963188)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125110519700.png)]](https://img-blog.csdnimg.cn/2020121701015757.png)
使用迭代器中不能使用其他的方式删除元素,不然会出现异常
while (iterator.hasNext()) {
Object o = iterator.next();
System.out.print(o+ " ");
collection.remove(o);
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vwOvKiLo-1608137963190)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125110928775.png)]](https://img-blog.csdnimg.cn/202012170102083.png)
但是可以使用自带的删除
while (iterator.hasNext()) {
Object o = iterator.next();
System.out.print(o+ " ");
// collection.remove(o);
iterator.remove();
}
System.out.println();
System.out.println("集合中剩余元素" + collection.size());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RbH6q4c8-1608137963192)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125111320415.png)]](https://img-blog.csdnimg.cn/20201217010222753.png)
(4)判断
//(4)判断
System.out.println("西瓜是否存在: " + collection.contains("西瓜"));
System.out.println("元素是否为空:" + collection.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2X1PpPpI-1608137963193)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125111756093.png)]](https://img-blog.csdnimg.cn/20201217010231313.png)
4、List子接口
(1) 添加元素
List list = new ArrayList();
//(1) 添加元素
list.add("苹果");
list.add("小米");
list.add("华为");
System.out.println("添加之后的元素: " + list.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DAdeCU1a-1608137963197)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125121430633.png)]](https://img-blog.csdnimg.cn/20201217010242513.png)
(2) 删除元素
//(2) 删除元素
//按索引删除
list.remove(0);
//按元素删除
list.remove("小米");
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ramvtf4E-1608137963198)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125121455501.png)]](https://img-blog.csdnimg.cn/20201217010252816.png)
(3)遍历元素
//(3)遍历元素
//1.for
System.out.print("使用for循环遍历: ");
for (int i = 0 ; i < list.size() ; i++) {
System.out.print(list.get(i) + " ");
}
System.out.println();
//2.增强型for
System.out.print("使用增强型的for遍历: ");
for (Object o : list) {
System.out.print(o + " ");
}
System.out.println();
//3.使用迭代器进行遍历
System.out.print("使用迭代器进行遍历: ");
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
System.out.println();
//4.使用列表迭代器(功能比上面的更加强大,可使用的方法看向下面的方法摘要)
System.out.print("使用列表迭代器进行遍历: ");
ListIterator listIterator = list.listIterator();
while (listIterator.hasNext()) {
System.out.print(listIterator.next() + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mvl06bE4-1608137963202)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125123011631.png)]](https://img-blog.csdnimg.cn/20201217010305472.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2JH03mAQ-1608137963203)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125123423276.png)]](https://img-blog.csdnimg.cn/20201217010316712.png)
(4)判断
//5、判断
System.out.println("是否包含苹果: " + list.contains("苹果"));
System.out.println("列表是否为空: " + list.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3FR0uybh-1608137963204)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125124128507.png)]](https://img-blog.csdnimg.cn/20201217010326114.png)
(5)获取
//6、获取位置
System.out.println("华为在列表中的索引: " + list.indexOf("华为"));
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YErNOl50-1608137963207)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125124152967.png)]](https://img-blog.csdnimg.cn/20201217010336754.png)
(6)自动装箱
//7、自动装箱(集合中不能放基本类型,下面是程序内部做了一次封装)
List list1 = new ArrayList();
list1.add(10);
list1.add(20);
list1.add(30);
list1.add(40);
System.out.println(list1);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kwuFqG4B-1608137963208)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125145110754.png)]](https://img-blog.csdnimg.cn/20201217010346499.png)
(7)装箱元素的删除
//8、集合中存放自动装箱元素的删除
//下面这种方式不行,这是删除索引位置的元素
// list1.remove(10);
list1.remove(new Integer(10));
System.out.println("删除后的集合元素为: " + list1);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wYXYRji8-1608137963209)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125145646304.png)]](https://img-blog.csdnimg.cn/20201217010357111.png)
(8)获得子集合
//9、获取子集合
List list2 = list1.subList(2, 3);
System.out.println("子集合为: " + list2);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XthUDRei-1608137963211)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125150045791.png)]](https://img-blog.csdnimg.cn/20201217010406372.png)
5、List实现类
1、ArrayList、 Vector 、LinkedList基本比较

2、ArrayList删除问题
//1、ArrayList插入数据
ArrayList arrayList = new ArrayList<>();
arrayList.add(new Student("黄坤1", 18));
arrayList.add(new Student("黄坤2", 19));
arrayList.add(new Student("黄坤3", 20));
//2、删除元素
arrayList.remove(new Student("黄坤1", 18));
System.out.println("删除后得元素为: " + arrayList);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uLDnZXyu-1608137963212)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125152053329.png)]](https://img-blog.csdnimg.cn/20201217010430104.png)
可以看到**new Student(“黄坤1”, 18)**并没有被删除,这是为什么,这是因为remove方法内部删除元素的比较规则。我们可以重写equals方法来生成我们自己的对应的删除规则
@Override
public boolean equals(Object o) {
//1、判断对象是否相同
if (this == o) {
return true;
}
//2、判断是否为空
if (o == null) {
return false;
}
//3、判断是否是Student类型
if (o instanceof Student) {
Student s = (Student)o;
//4、比较属性
if (this.name.equals(s.getName()) && this.age == s.getAge()) {
return true;
}
}
return false;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6cchf8Li-1608137963214)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125153254113.png)]](https://img-blog.csdnimg.cn/20201217010446573.png)
3、ArrayList源码分析
-
DEFAULT_CAPACITY = 10 : 默认容量(没有元素时,默认为0)
注意:如果没有向集合中添加集合元素时,容量为0。添加一个元素之后,容量为10。元素满之后,扩容到原来的1.5倍。
-
elementData: 存放元素的数据
-
size: 实际元素个数
4、Vector特有的遍历方式
vector除增强型for、迭代器外,还有下面这种枚举器进行遍历
Vector vector = new Vector();
vector.add("西瓜");
vector.add("哈密瓜");
vector.add("猕猴桃");
//使用枚举器进行遍历
System.out.print("使用枚举器遍历的结果为: ");
Enumeration elements = vector.elements();
while (elements.hasMoreElements()) {
String o = (String)elements.nextElement();
System.out.print(o + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbMEr30U-1608137963217)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125162424070.png)]](https://img-blog.csdnimg.cn/20201217010500943.png)
5、LinkedList源码分析
结构:双向链表
6、泛型
1、泛型类
/**
* 泛型类
* 语法:类名<T>
* T是类型占位符,表示一种引用类型,如果编写多个使用逗号隔开
*/
public class demo6<T> {
//使用泛型T
//1、创建变量
T t;
//2、泛型作为方法的参数
public void show(T t) {
System.out.println(t);
}
//3、通常作为方法的返回值
public T getT() {
return t;
}
}
泛型类测试:
//使用泛型类创建对象
demo6<String> d = new demo6<>();
d.t = "hello";
d.show("大家好,加油");
String string = d.getT();
demo6<Integer> d1 = new demo6<>();
d1.t = 100;
d1.show(200);
Integer integer = d1.getT();
注意:
- 泛型只能使用引用类型
- 不同泛型类型对象之间不能相互赋值
2、泛型接口
/**
* 泛型接口
* 语法:接口名<T>
* 注意:不能泛型静态常量
*/
public interface demo8<T> {
String name = "张三";
T server(T t);
}
实现类:
public class demo8Impl implements demo8<String>{
@Override
public String server(String s) {
System.out.println(s);
return s;
}
}
泛型接口测试:
demo8Impl d8i = new demo8Impl();
String ss = d8i.server("ss");
System.out.println(ss);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n2OJWFKV-1608137963219)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125184310199.png)]](https://img-blog.csdnimg.cn/20201217010517673.png)
3、泛型方法
//泛型方法
public <T> T show(T t) {
System.out.println("泛型方法: " + t);
return t;
}
泛型方法测试:
demo10 d = new demo10();
//根据我们传入的数据决定
String string = d.show("String");
Integer show = d.show(1);
Boolean show1 = d.show(false);
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8hAjXAq4-1608137963221)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125185645009.png)]](https://img-blog.csdnimg.cn/20201217010527926.png)
4、泛型的好处
(1) 提高代码的重用性
(2)防止类型转换异常,提高代码的安全性
5、泛型集合
ArrayList<Student> arrayList = new ArrayList<>();
arrayList.add(new Student("张三", 18));
arrayList.add(new Student("李四", 19));
arrayList.add(new Student("王五", 20));
Iterator<Student> iterator = arrayList.iterator();
while (iterator.hasNext()) {
Student st = iterator.next();
System.out.println(st);
}
泛型集合测试:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wxx04Pc0-1608137963222)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201125190822730.png)]](https://img-blog.csdnimg.cn/20201217010540583.png)
7、Set
特点:元素无序、没有下标、不能重复
1、添加
Set<String> set = new HashSet<>();
//1、添加数据
set.add("华为");
set.add("苹果");
set.add("小米");
System.out.println("数据个数: " + set.size());
System.out.println(set.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HMWgACsO-1608137963224)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126091825065.png)]](https://img-blog.csdnimg.cn/20201217010554771.png)
2、删除
//2、删除元素
set.remove("小米");
System.out.println("数据个数: " + set.size());
System.out.println(set.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rP5qgzUC-1608137963225)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126091937321.png)]](https://img-blog.csdnimg.cn/20201217010604603.png)
3、遍历
//3、遍历(没有下标,不能使用for)
//1、迭代器
System.out.print("使用迭代器: ");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
System.out.print(next + " ");
}
System.out.println("");
//2、增强for
System.out.print("使用增强for: ");
for (String s : set) {
System.out.print(s + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MN0Omjc6-1608137963226)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126092413837.png)]](https://img-blog.csdnimg.cn/20201217010618708.png)
4、判断
//4、判断
System.out.println("是否包含华为: " + set.contains("华为"));
System.out.println("set是否为空: " + set.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rR0ZjLzZ-1608137963229)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126092646316.png)]](https://img-blog.csdnimg.cn/20201217010629830.png)
5、HashSet(散列表)
1、根据hashcode计算保存的位置,如果此位置为空,则直接保存,如果不为空执行第二步
2、在执行equals方法,如果equals方法为true,则认为是重复的,不能放入,否则,形成链表(拉链法解决冲突)
在重写hashcode()时,发现有一个数字31,它有什么功能?
- 31是一个质数,减少了散列冲突。
- 31提高执行效率 31 * i = (i << 5)- i ,将乘法运算转为移位运算和减法运算。
1、添加
HashSet<String> hashSet = new HashSet<>();
//1、添加元素
hashSet.add("黄坤1");
hashSet.add("黄坤2");
hashSet.add("黄坤3");
hashSet.add("黄坤4");
System.out.println("元素个数: " + hashSet.size());
System.out.println(hashSet.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mOSvgTTl-1608137963231)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126093644549.png)]](https://img-blog.csdnimg.cn/20201217010710322.png)
2、删除
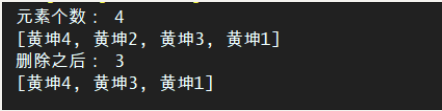
//2、删除元素
hashSet.remove("黄坤2");
System.out.println("删除之后: " + hashSet.size());
System.out.println(hashSet.toString());
3、遍历
//3、遍历元素
//1、使用迭代器
System.out.print("迭代器遍历元素: ");
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
System.out.print(next + " ");
}
System.out.println();
//2、增强for
System.out.print("增强for遍历元素: ");
for(String s : hashSet) {
System.out.print(s + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UosBaJLK-1608137963233)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126094457121.png)]](https://img-blog.csdnimg.cn/20201217010751777.png)
4、判断
//4、判断元素
System.out.println("HashSet中是否包含黄坤2: " + hashSet.contains("黄坤2"));
System.out.println("HashSet是否为空: " + hashSet.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iDVPs7Tu-1608137963234)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126094706860.png)]](https://img-blog.csdnimg.cn/20201217010802975.png)
6、TreeSet(红黑树)
- 基于排列顺序实现元素不重复。
- 实现了SortedSet接口,对集合元素自动排序。
- 元素对象的类型必须实现Comparable接口,指定排序规则。
- 通过CompareTo方法确定是否为重复元素。
1、添加
//创建集合
TreeSet<String> treeSet = new TreeSet<>();
//1、添加元素
treeSet.add("xyz");
treeSet.add("abc");
treeSet.add("hello");
System.out.println("元素个数额: " + treeSet.size());
System.out.println(treeSet.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HzB6HMRg-1608137963235)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126103147016.png)]](https://img-blog.csdnimg.cn/20201217010814184.png)
2、删除
//2、删除元素
treeSet.remove("xyz");
System.out.println("删除之后: " + treeSet.size());
System.out.println(treeSet.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rqA6Dzm7-1608137963237)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126103405341.png)]](https://img-blog.csdnimg.cn/20201217010823514.png)
3、遍历
//3、遍历元素
//1、增强for
System.out.print("增强for遍历元素: ");
for (String s : treeSet) {
System.out.print(s + " ");
}
System.out.println();
//2、迭代器遍历元素
System.out.print("迭代器遍历元素: ");
Iterator<String> iterator = treeSet.iterator();
while (iterator.hasNext()) {
String s = iterator.next();
System.out.priva
nt(s + " ");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8dnr6ood-1608137963238)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126103845637.png)]](https://img-blog.csdnimg.cn/20201217010833986.png)
4、判断
//4、判断
System.out.println("TreeSet中是否包含abc: " + treeSet.contains("abc"));
System.out.println("TreeSet中是否为空: " + treeSet.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nEM2aBYC-1608137963239)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126104102101.png)]](https://img-blog.csdnimg.cn/20201217010843196.png)
5、添加对象
添加对象进入TreeSet中的时候,需要实现对象的Comparable接口,并重写它的compareTo方法
public class User implements Comparable<User>{
//先按姓名比,然后在按年龄比
@Override
public int compareTo(User o) {
int n1 = this.getName().compareTo(o.getName());
int n2 = this.age - o.getAge();
return n1 == 0 ? n2 : n1;
}
如果没有实现的话,会报类型转换异常
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EFCbwO13-1608137963240)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126111634441.png)]](https://img-blog.csdnimg.cn/20201217010855763.png)
实现对象的Comparable接口,并重写它的compareTo方法之后
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EDUJt03w-1608137963241)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126112453700.png)]](https://img-blog.csdnimg.cn/20201217010904796.png)
6、实现比较规则
其实在放入对象的时候也可以不实现对象的Comparable接口,在创建TreeSet的时候指定比较规则也可以。
//创建集合
TreeSet<Student> treeSet = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//先比较年龄,再比较姓名
int n1 = o1.getAge() - o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1==0?n2:n1;
}
});
treeSet.add(new Student("黄坤2", 18));
treeSet.add(new Student("黄坤1", 18));
treeSet.add(new Student("黄坤3", 20));
System.out.println("集合的大小为: " + treeSet.size());
System.out.println(treeSet.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xQhOojuZ-1608137963243)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126115432401.png)]](https://img-blog.csdnimg.cn/20201217010916281.png)
7、联系比较字符串
/**
* 练习比较字符串
* helloWorld 、pingguo 、lisi 、zhangsan 、beijing 、 cat 、nanjing 、xian
*/
public class demo17 {
public static void main(String[] args) {
//创建集合,并制定比较规则
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int n1 = o1.length() - o2.length();
int n2 = o1.compareTo(o2);
return n1==0 ? n2 : n1;
}
});
//添加数据
treeSet.add("helloWorld");
treeSet.add("pingguo");
treeSet.add("lisi");
treeSet.add("zhangsan");
treeSet.add("beijing");
treeSet.add("cat");
treeSet.add("nanjing");
treeSet.add("xian");
System.out.println(treeSet.toString());
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tPRH3ko1-1608137963245)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126133539552.png)]](https://img-blog.csdnimg.cn/20201217010929188.png)
8、Map体系架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-L5HrOF10-1608137963247)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126133844439.png)]](https://img-blog.csdnimg.cn/20201217010938341.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
1、添加
//创建Map集合
Map<String, String> map = new HashMap<>();
//1、添加元素
map.put("cn", "中国");
map.put("uk", "英国");
map.put("us", "美国");
System.out.println("元素个数为: " + map.size());
System.out.println(map.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XuAMKi0F-1608137963249)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126134759710.png)]](https://img-blog.csdnimg.cn/20201217010948688.png)
2、删除
//2、删除
map.remove("us");
System.out.println("删除之后: " + map.size());
System.out.println(map.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jcmxm6yV-1608137963252)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126135003399.png)]](https://img-blog.csdnimg.cn/20201217011000174.png)
3、遍历
//3、遍历
//1、使用keySet()
System.out.print("keySet遍历结果: ");
Set<String> set = map.keySet();
for (String key : set) {
System.out.print("(key: " + key + " value: " + map.get(key) + ")");
}
System.out.println();
//2、使用entrySet()
System.out.print("entrySet遍历结果: ");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.print("(key: " + entry.getKey() + " value: " + entry.getValue() + ")");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9xKuN4a0-1608137963253)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126140324350.png)]](https://img-blog.csdnimg.cn/20201217011013412.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dsp0algW-1608137963254)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126140425297.png)]](https://img-blog.csdnimg.cn/20201217011024315.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
4、判断
//4、判断
System.out.println("map中是否包含日本: " + map.containsKey("日本"));
System.out.println("map中是否为空: " + map.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1KYnYW9K-1608137963255)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126140649350.png)]](https://img-blog.csdnimg.cn/20201217011034197.png)
5、HashMap
key的插入依据(key不能相同): 通过 hashcode 和 equals 方法的内部逻辑来判断key是否重复
1、添加
//创建集合
HashMap<Student, String> students = new HashMap<>();
//1、添加元素
Student s1 = new Student("黄坤1", 10);
Student s2 = new Student("黄坤2", 11);
Student s3 = new Student("黄坤3", 12);
students.put(s1, "北京");
students.put(s2, "天津");
students.put(s3, "长沙");
System.out.println("元素个数: " + students.size());
System.out.println(students.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JUJ0nH5q-1608137963257)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126142601420.png)]](https://img-blog.csdnimg.cn/20201217011045659.png)
思考下面这样一个问题:添加下面的代码,集合中会发生什么变化?
students.put(s3, "长沙1");
students.put(new Student("黄坤3", 12), "长沙2");
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TY20QUFP-1608137963259)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126144027278.png)]](https://img-blog.csdnimg.cn/20201217011054889.png)
由上图可以看出,原集合中键为引用new Student(“黄坤”, 12) 的引用s3,值为"长沙"的键值对,现在被键为引用new Student(“黄坤”, 12) 的引用s3,值为"长沙1"的键值对所取代,因为他们的键相同,都指向new Student(“黄坤3”, 12);。
而键为new Student(“黄坤3”, 12),值为"长沙2"的元素成功加入到集合中,这是由于上面的键是引用,这个键是真实对象。
那么可不可以不管引用,还是对象,只要里面的姓名和学号相同就认定是同一个元素
可以通过重写hashcode和equals来实现
2、删除
//2、删除
students.remove(s1);
System.out.println("元素个数: " + students.size());
System.out.println(students.toString());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kHbtwssy-1608137963260)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126145716591.png)]](https://img-blog.csdnimg.cn/20201217011104549.png)
3、遍历
//3、遍历
//1、keySet
System.out.print("使用keySet进行遍历: ");
for (Student key : students.keySet()) {
System.out.print("(key: " + key + " " + " value: " + students.get(key) + ")");
}
System.out.println();
//2、entrySet
System.out.print("使用entrySet进行遍历: ");
Set<Map.Entry<Student, String>> entries = students.entrySet();
for (Map.Entry<Student, String> entry : entries) {
System.out.print("(key: " + entry.getKey() + " " + " value: " + entry.getValue() + ")");
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QOag4UeN-1608137963261)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126150449163.png)]](https://img-blog.csdnimg.cn/20201217011119373.png)
4、判断
//4、判断
System.out.println("集合中是否包含s1: " + students.containsKey(s1));
System.out.println("集合是否为空: " + students.isEmpty());
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9QCMaK2j-1608137963263)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126150727699.png)]](https://img-blog.csdnimg.cn/20201217011130213.png)
5、源码解析
- 默认的初始容量为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
- 最大的容量为2的30次方
static final int MAXIMUM_CAPACITY = 1 << 30;
- 默认的装载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
- 当一个桶中的元素个数大于等于8时进行树化
static final int TREEIFY_THRESHOLD = 8;
- 当一个桶中的元素个数小于等于6时把树转化为链表
static final int UNTREEIFY_THRESHOLD = 6;
- 当桶的个数达到64的时候才进行树化
static final int MIN_TREEIFY_CAPACITY = 64;
- 数组,又叫作桶(bucket)
transient Node<K,V>[] table;
- 作为entrySet()的缓存
transient Set<Map.Entry<K,V>> entrySet;
- 元素的数量
transient int size;
- 修改次数,用于在迭代的时候执行快速失败策略
transient int modCount;
- 当桶的使用数量达到多少时进行扩容
threshold = capacity * loadFactor
*/
int threshold;
- 装载因子
final float loadFactor;
总结:
- HashMap刚创建时,table为null,为了节省空间,当添加第一个元素时,table容量调整为16。
- 当元素个数大于阈值(16*0.75=12)时,会进行扩容,扩容后的大小会变为原来的2倍,目的时减少调整元素的个数。
- jdk1.8 当每个链表长度大于8,并且数组元素个数大于或等于64时,会调整为红黑树,目的是提高执行效率。
- jdk1.8 当链表长度小于6时,调整成链表。
- jdk1.8以前,链表时头插,jdk1.8以后是尾插
6、HashMap 和 Hashtable的区别:
-
HashMap:
jdk1.2版本,线程不安全,运行效率快;允许用null作为key或是value
-
Hashtable(现在很少用了):
jdk1.0版本,线程安全,运行效率慢;不允许null作为key或是value
-
Properties:
Hashtable的子类,要求key和value都是String。通常用于配置文件的读取
7、TreeMap添加问题
TreeMap<Student, String> treeMap = new TreeMap<>();
treeMap.put(new Student("黄坤1", 10),"北京");
treeMap.put(new Student("黄坤2", 11),"长沙");
treeMap.put(new Student("黄坤3", 12),"上海");
System.out.println(treeMap.size());
System.out.println(treeMap.toString());
执行上述代码会发生下面的异常,这是由于TreeMap内部没有实现数据的比较规则
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B9oDMcpO-1608137963265)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126185911265.png)]](https://img-blog.csdnimg.cn/20201217011157981.png)
实现其comparable接口的compareTo方法后
public class Student implements Comparable<Student>{
@Override
public int compareTo(Student o) {
int n2 = this.stuNo - o.getStuNo();
return n2;
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ArhNjRap-1608137963266)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126190349199.png)]](https://img-blog.csdnimg.cn/20201217011210105.png)
遍历使用keySet和entrySet
9、Collections工具类
package collections;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collectors;
/**
* Collections常用方法
*/
public class collections {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(5);
list.add(12);
list.add(30);
list.add(6);
//1、sort:排序
System.out.println("排序之前: " + list.toString());
Collections.sort(list);
System.out.println("排序之后: " + list.toString());
//2、binarySearch: 二分查找
//查找12在元素中的位置
int i = Collections.binarySearch(list, 30);
System.out.println(i);
//3、copy: 复制
List<Integer> dest = new ArrayList<>();
for (int i1 = 0; i1 < list.size(); i1++) {
dest.add(0);
}
Collections.copy(dest, list);
System.out.println(dest.toString());
//4、reverse: 反转
Collections.reverse(list);
System.out.println("反转: " + list);
//shuffle: 打乱
Collections.shuffle(list);
System.out.println("打乱之后: " + list);
//补充: list转数组
Integer[] integers = list.toArray(new Integer[0]);
System.out.println(Arrays.toString(integers));
//补充: 数组转集合
String name[] = {"张三", "李四", "王五"};
//转后的集合是一个受限集合,不能添加和删除
List<String> strings = Arrays.asList(name);
System.out.println(strings);
//能把基本类型数组转为集合时,需要修改为包装类
Integer[] nums = {100, 200, 300, 400, 500};
List<Integer> list1 = Arrays.asList(nums);
System.out.println(list1);
}
}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bqeM4387-1608137963268)(C:/Users/lenovo/AppData/Roaming/Typora/typora-user-images/image-20201126194128784.png)]](https://img-blog.csdnimg.cn/20201217011224240.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L20wXzQ1MDI1NjU4,size_16,color_FFFFFF,t_70)
10、其他
Arrays.sort 对基本类型的使用就是改进过的快排算法















 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









