






一、ComfyUI 简介
ComfyUI 是一款基于图形界面的 Stable Diffusion 前端工具,它使用 Node(节点)方式组织 AI 图像生成流程,使用户可以通过拖拽组件、调整参数来构建可视化的工作流(Workflow)。相比传统的 Web UI 工具,ComfyUI 更注重模块化和可重用性,适合希望深度自定义图像生成过程的用户和开发者。
主要特点:
-
完全基于图形节点化结构构建工作流;
-
支持实时预览与参数调节;
-
支持 SD 1.x 和 SDXL 模型;
-
社区活跃,支持自定义节点和插件扩展。
目前网络上流传的多数 ComfyUI 安装包均已预置大量模型文件,虽然方便了一部分用户,但也导致压缩包体积庞大,安装过程中因模型过多而引发各种兼容性或依赖问题,不利于初学者快速上手学习和理解 ComfyUI 的运行机制。
为此,我们计划推出一系列教程博客,从官方原始版本出发(不附带多余模型),引导大家从零开始学习 ComfyUI 的安装与使用过程。通过逐步引入所需模型,帮助读者避免初期因系统环境或模型问题而受阻,更专注于掌握 ComfyUI 的核心功能和工作流构建方法。
在开始学习之前先放几张 ComfyUI生成的图片,感受一下 ComfyUI的魅力。
动漫风格


素描风格

虚构风格

二、ComfyUI 安装教程(以 Windows 为例)
1. 安装前准备
-
系统:Windows 10/11
-
Python:推荐 Python 3.10.x
-
显卡支持:建议使用带有 CUDA 支持的 NVIDIA 显卡
2. 安装步骤
下载地址:
Releases · comfyanonymous/ComfyUI · GitHub
选择红色部分下载
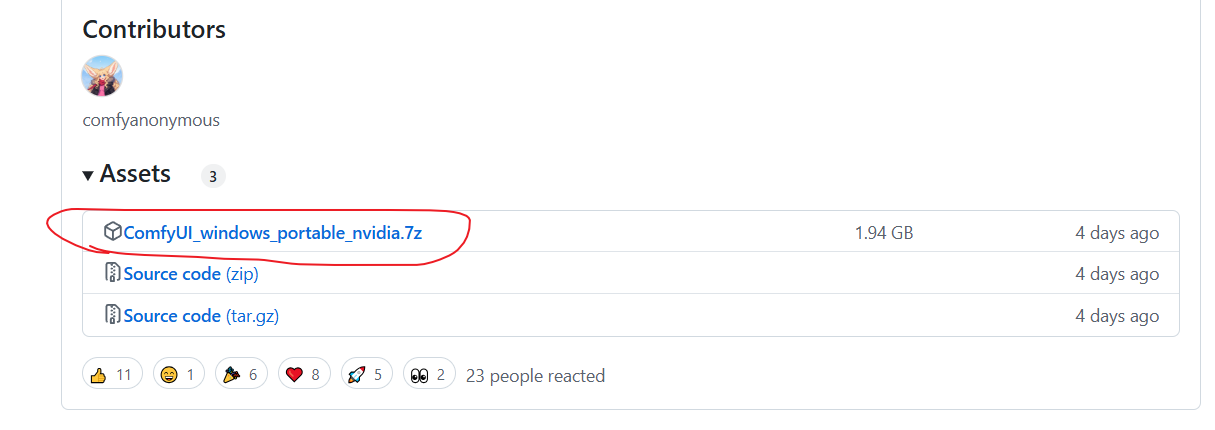
鉴于有部分同学无法进入github,本文给出了下载地址:通过网盘分享的文件:ComfyUI_windows_portable_nvidia.7z 链接: 百度网盘 请输入提取码百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间![]() https://pan.baidu.com/s/1Tlp6TkSx1-uTNUbp806Pbg 提取码: 2580
https://pan.baidu.com/s/1Tlp6TkSx1-uTNUbp806Pbg 提取码: 2580
1.解压
直接将ComfyUI_windows_portable_nvidia.7z文件解压至任意的磁盘中,解压完成后的文件夹名ComfyUI_windows_portable.
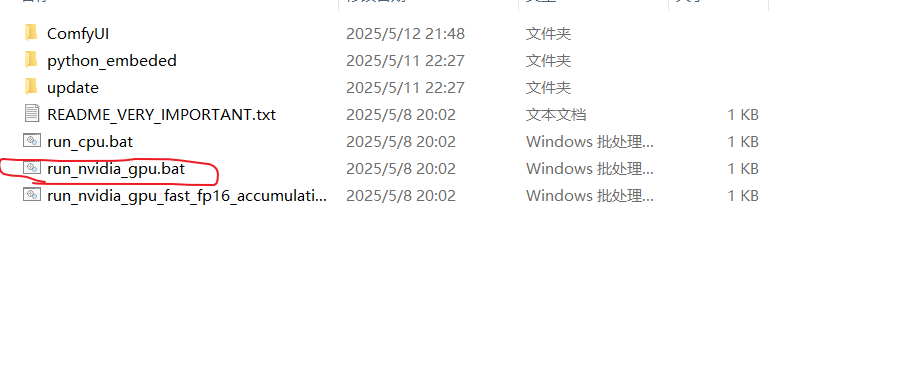
2.运行.bat文件,值得注意的是这个.bat文件知识针对nvidia版本的gpu。
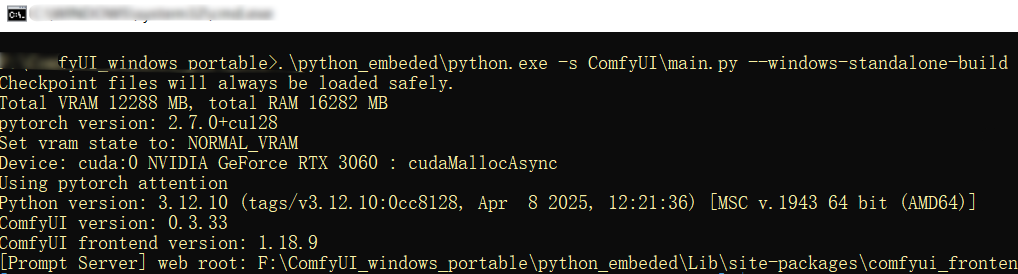
在CMD中运行完成后,会自动打开一个网页。
运行过程
三.创建第一个工作流
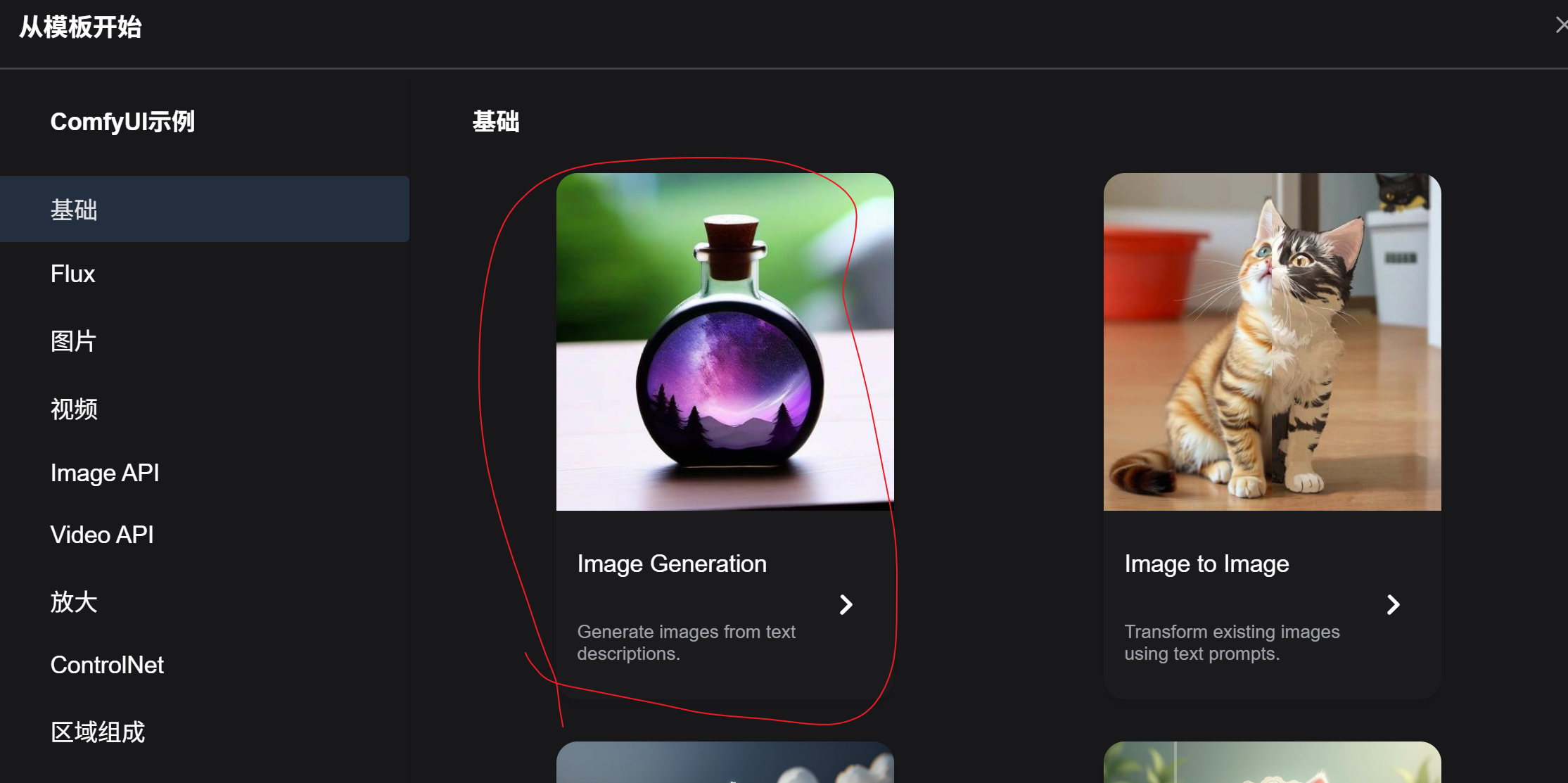
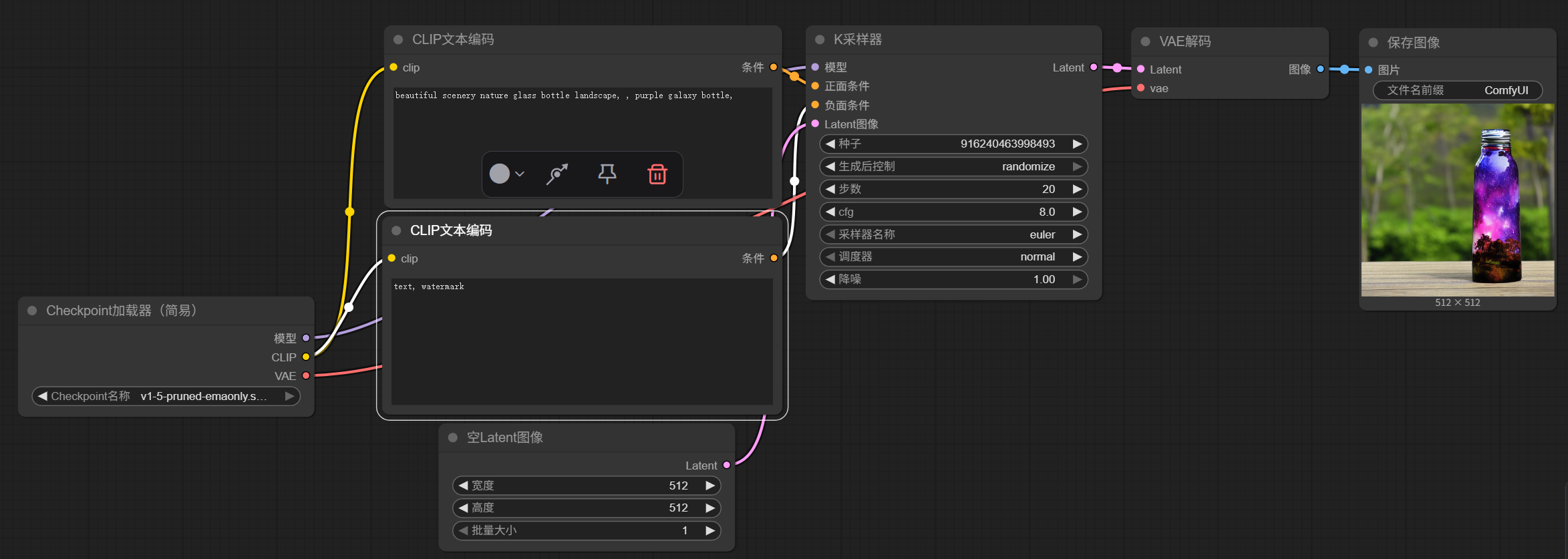
在工作流中选择浏览模版,将紫色水晶瓶作为我们的工作流模版,
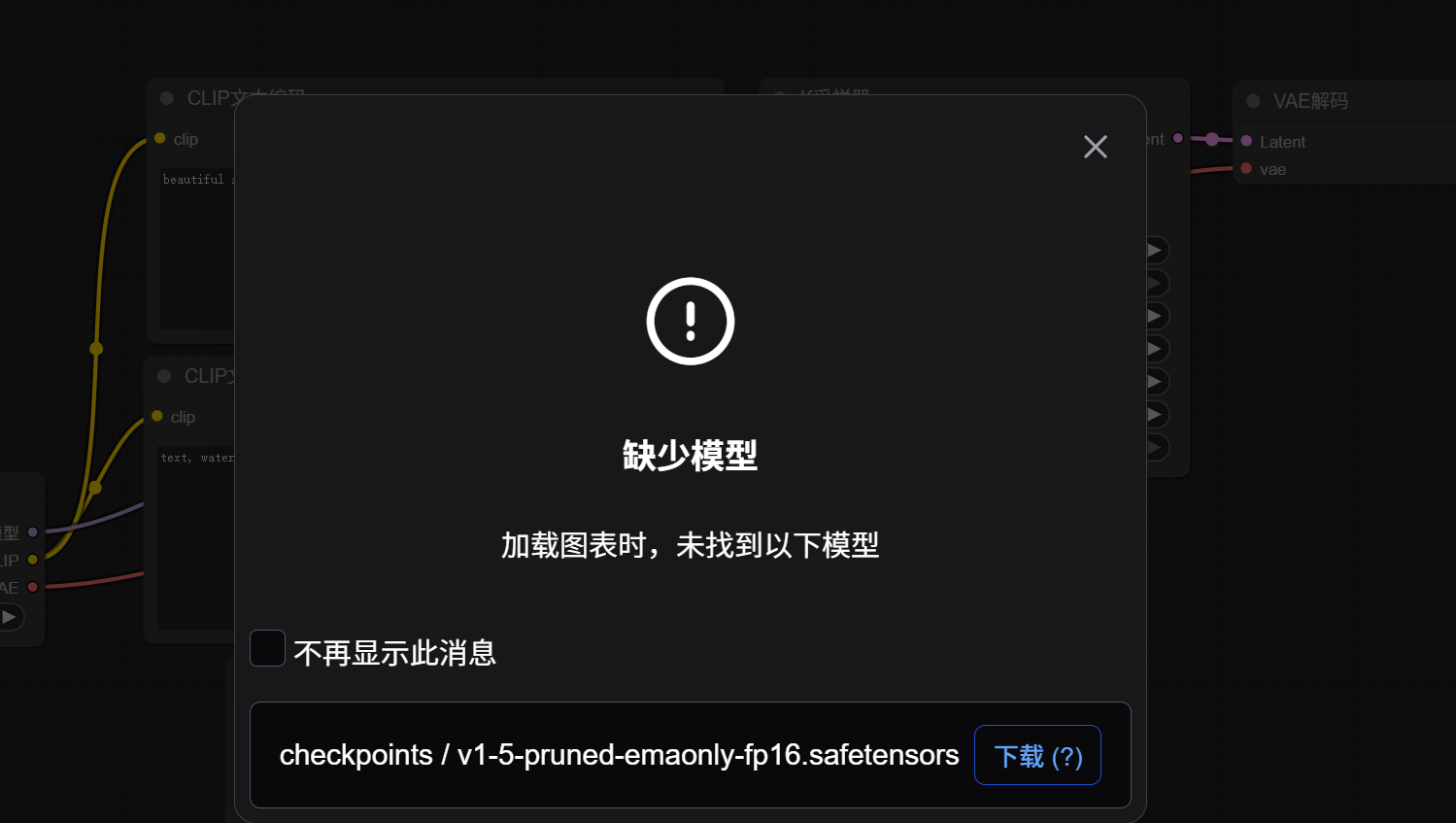
如果出现以下提示,我们直接下一步就可以,这是因为,我们下载的Comfyui安装包是不带任何模型文件的,我们在后续的工作中加入即可。
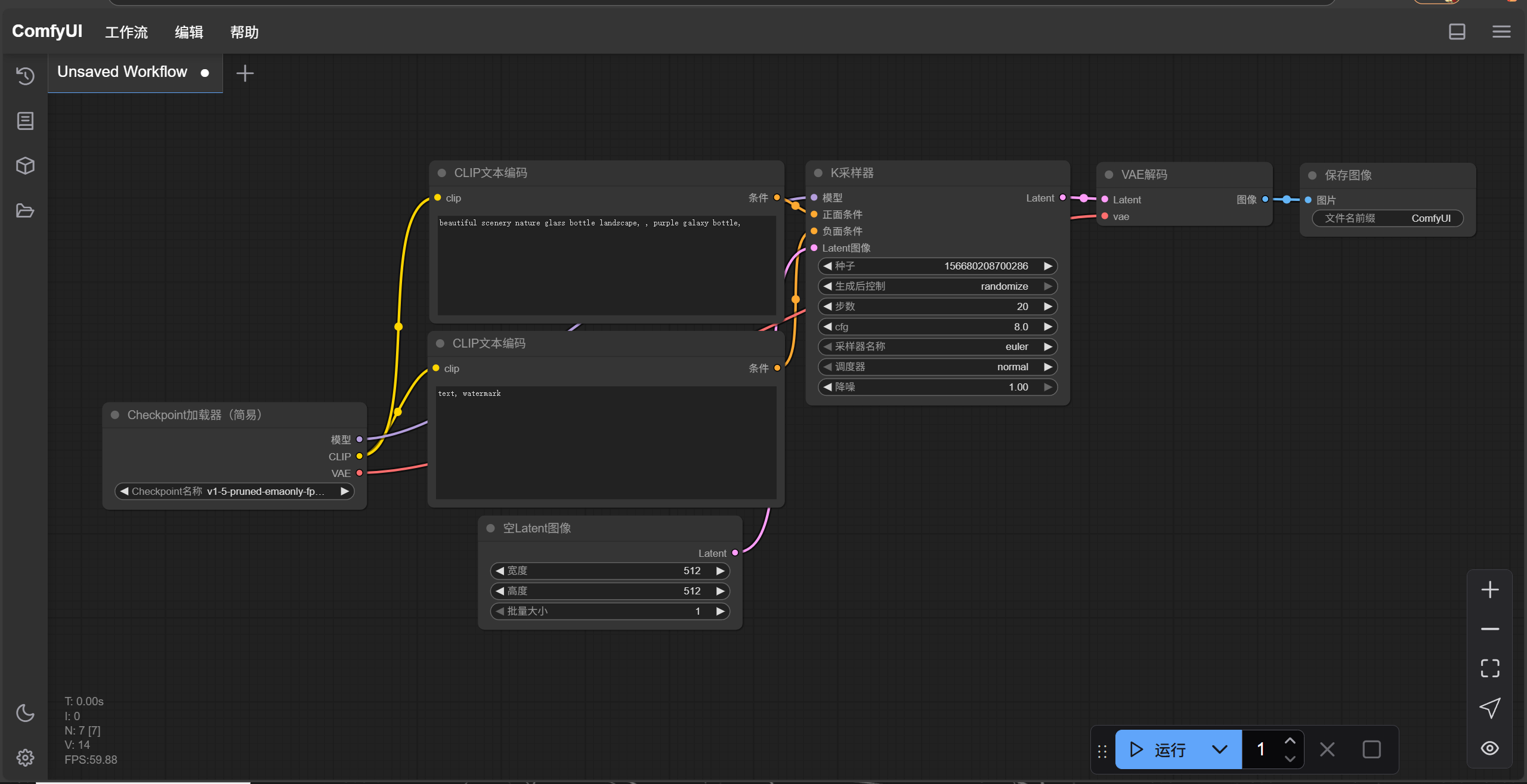
进入到工作流界面
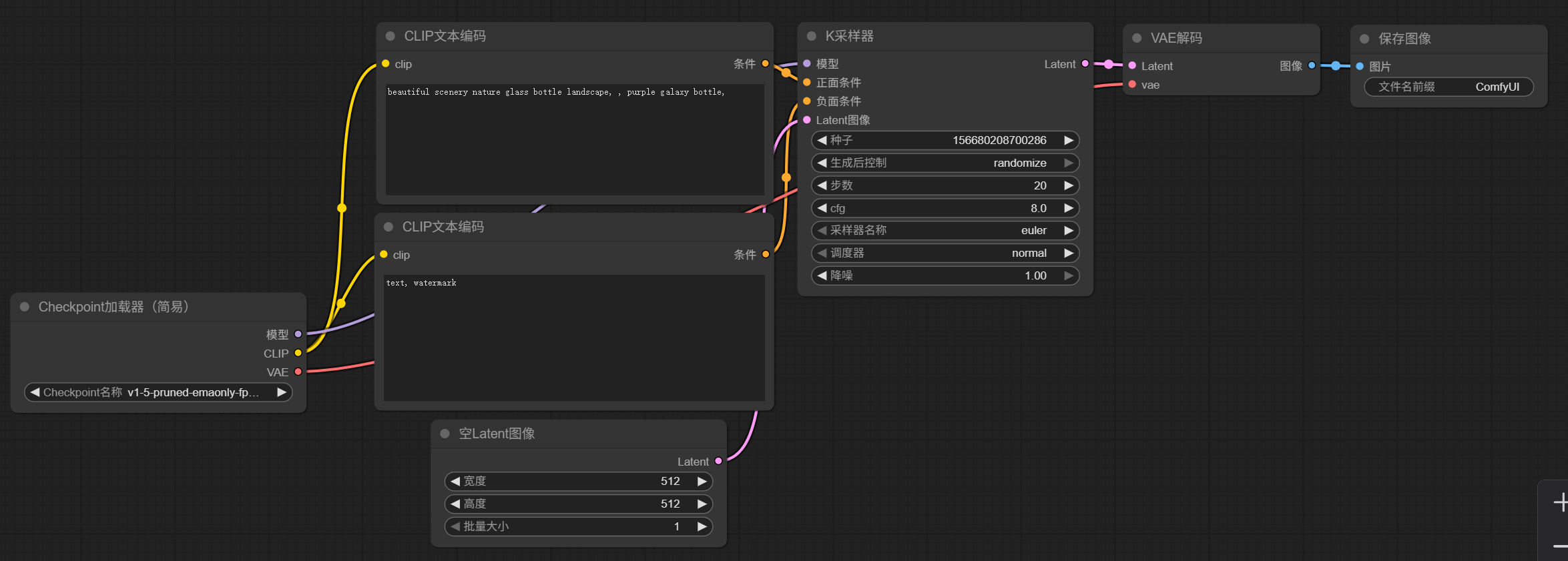
从左到右介绍这一个简单的工作流模版
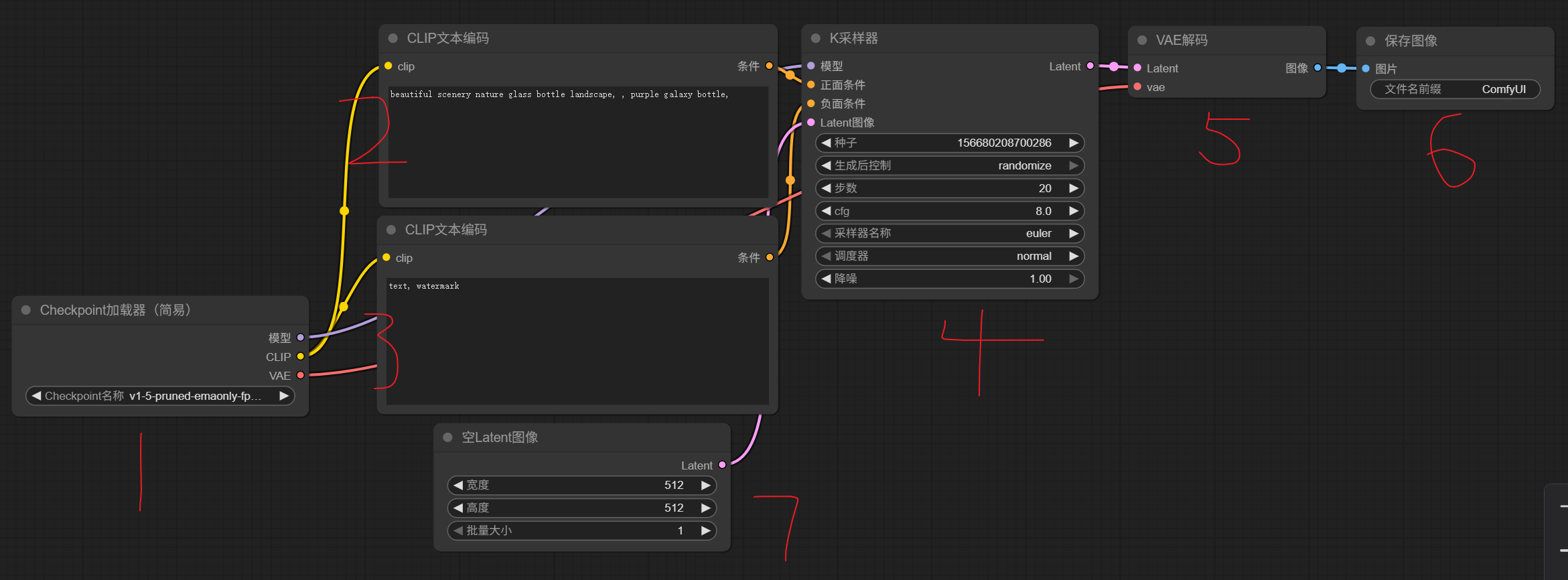
(1)调用大模型文件,我们在日常的深度学习实验中经常会调用别人的模型文件,可以使我们的网络更快收敛。在这里我们直接调用SD1.5通用大模型。当然我们需要先将SD1.5大模型下载至本地,下载链接:https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.safetensors
同样的如果不能魔法下载的,我们也给出了网盘的下载链接:通过网盘分享的文件:v1-5-pruned-emaonly.safetensors 链接: 百度网盘 请输入提取码百度网盘为您提供文件的网络备份、同步和分享服务。空间大、速度快、安全稳固,支持教育网加速,支持手机端。注册使用百度网盘即可享受免费存储空间![]() https://pan.baidu.com/s/1X6g3T0MJ8DUfnBCoKluMmw 提取码: 2580
https://pan.baidu.com/s/1X6g3T0MJ8DUfnBCoKluMmw 提取码: 2580
将下载后的大模型放入F:\ComfyUI_windows_portable\ComfyUI\models\checkpoints中。
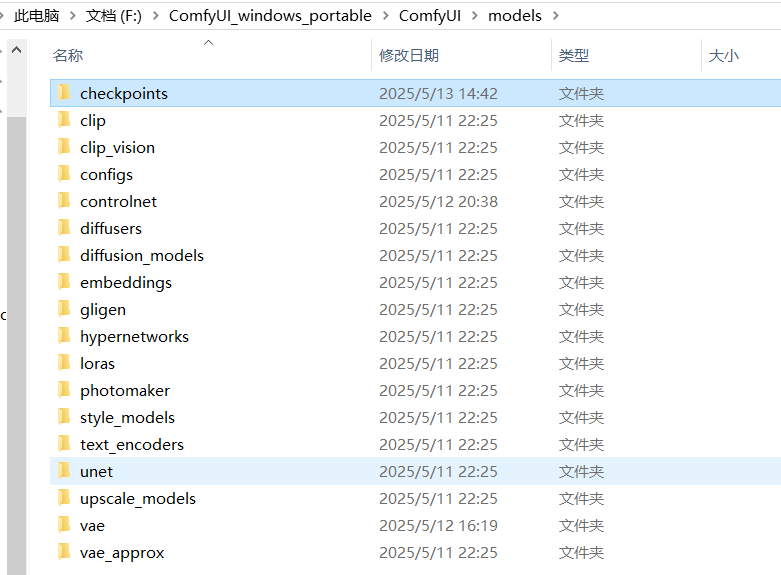
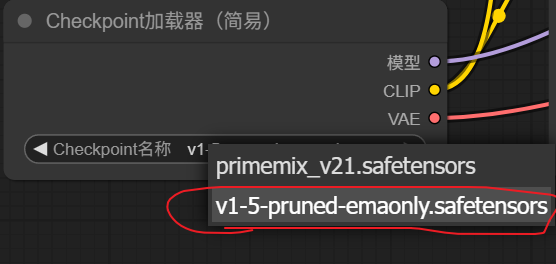
记得重新启动run_nvidia_gpu.bat文件,.bat文件会自动打开网页我们将进入工作流的编辑中。重复之前的额操作,先在浏览模版中选择一个基础的工作流。
这时在权重加载器中选择刚才我们下载的SD1.5大模型:
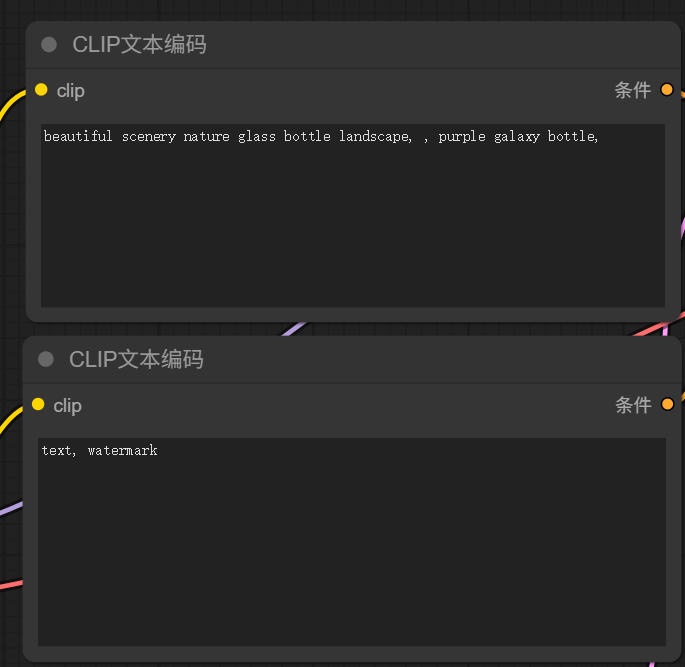
(2,3)文本提示词。在CLIP模型中文本提示是图像生成的关键因素,好的提示词可以帮助模型更加准确的生成我们想要的图片。在工作流中提示词分为正向提示词与反向提示词。提示词是分权重的,越靠前的提示词越会得到模型的重视,所以在写提示词时我们需要将这幅图最重要的特征写在最前面。
比如:我们一般希望图片是高清的,质量好的,所以我们在正向提示词中将“杰作,质量高的”放在最前面,在反向提示词中将“低质量的”放在最前面。
总之我们在提示词中首先要抓住主要矛盾,其次在优化细节。
就像我们选择的模版中给出的文本这样的提示词:
(4)K采样器(KSampler)简介
什么是 K 采样器?
在基于扩散模型的图像生成过程中,我们从一张纯噪声图像逐步“去噪”,直到得到最终图像。这个去噪过程称为“采样”(Sampling),而 K采样器(KSampler) 就是 ComfyUI 和其他 Stable Diffusion 框架中用于控制这个过程的核心节点。
它的“去噪策略”与“去噪速度”决定了图像的风格、清晰度、细节程度以及生成速度。
KSampler 的关键参数说明
| 参数名 | 含义 |
|---|---|
Sampler name | 采样器算法名称(如 Euler, DPM++ 2M 等) |
Scheduler | 时间步调度器,控制采样时如何选择每一步时间点 |
Steps | 步数,越高画质越好但耗时增加 |
CFG (Classifier-Free Guidance) | 引导系数,决定 prompt 影响程度 |
Seed | 随机种子,控制图像是否可复现 |
Noise | 初始噪声图像 |
Model | 选择使用的基础模型(如 SD 1.5) |
常见采样器简析
| 采样器名称 | 特点 | 推荐用途 |
|---|---|---|
| Euler a | 快速、略带随机性 | 动漫、草图类风格 |
| DPM++ 2M Karras | 高质量、均衡稳定 | 写实图像、高清写实风格 |
| Heun | 高细节、锐利 | 写实和艺术画风 |
| LMS | 稳定、对细节友好 | 需要高还原度的图像 |
| DDIM | 稳定且较快 | 风格稳定、不失细节 |
| DPM++ SDE Karras | 高质量、拟真效果好 | 摄影、写真风格生成 |
(5)VAE 解码器(VAE Decoder) 是将“潜空间图像”转换成“真实可见图像”的关键一步。
VAE 解码器(VAE Decoder)详解
什么是 VAE?
VAE(Variational Autoencoder),变分自编码器,是 Stable Diffusion 模型中的一部分,作用是:
-
编码器(Encoder):把原始图像压缩成一个低维的“潜空间”表示(latent space)。
-
解码器(Decoder):把“潜空间图像”还原为真实图像。
Stable Diffusion 实际是先在潜空间中生成图片(高效、低内存),然后通过 VAE Decoder 把这个图片还原出来。
为什么需要 VAE Decoder?
因为扩散模型的核心生成过程发生在一个压缩的潜空间中(而不是 512x512 的真实图像),所以我们需要:
-
利用 VAE 节省计算资源
-
最后用 VAE Decoder 还原成用户能看到的高清图像
在 ComfyUI 中如何使用?
-
通常在工作流末尾使用。
-
输入是 Latent 图像(潜空间图像)。
-
输出是 最终的 RGB 图像,可保存或后处理。
(6)用于查看我们生成的图片。
(7)规定一个图像的输出大小。
给出一个完整的工作流
今天我们主要学习ComfyUI的安装流程与工作流的创建过程。为了就是我们从零来学习ComfyUI。
后续我们将一步一步的学习ComfyUI的更多功能,欢迎大家一起讨论相关问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









