







前言:
Vision Transformer(ViT)原理介绍
随着深度学习在计算机视觉领域的广泛应用,卷积神经网络(CNN)成为了图像分类、目标检测等任务的主要方法。然而,随着Transformer在自然语言处理(NLP)领域的成功应用,研究者们开始尝试将其引入到计算机视觉中,提出了Vision Transformer(ViT)。ViT的出现标志着计算机视觉领域的一次重要创新,它能够充分发挥Transformer在建模全局依赖关系上的优势。
1. 什么是Transformer?
在深入探讨ViT之前,我们首先需要了解Transformer的基本概念。Transformer模型最初是在自然语言处理(NLP)任务中提出的,特别是在机器翻译任务中取得了显著的成果。Transformer的核心创新是其自注意力机制(Self-Attention),它能够在处理序列数据时捕捉到全局的依赖关系。与传统的循环神经网络(RNN)不同,Transformer通过并行处理输入数据,显著提高了训练效率。
Transformer的结构主要由以下几个部分组成:
-
自注意力机制(Self-Attention):计算输入序列中各个位置之间的相似性,并根据这些相似性调整各个位置的权重。
-
前馈神经网络(Feed-forward Neural Network):每个位置的输出都会经过一个前馈神经网络来进行进一步的特征转换。
-
位置编码(Positional Encoding):由于Transformer是基于位置独立的操作,因此需要引入位置编码来保留输入数据的位置信息。
2. Vision Transformer(ViT)的基本原理
ViT的提出是为了克服传统卷积神经网络(CNN)在处理图像时的局限性,尤其是在建模全局信息方面。ViT的核心思想是,将图像看作一个序列,将图像分割成若干小块(Patch),然后将这些小块作为输入传递给Transformer模型。
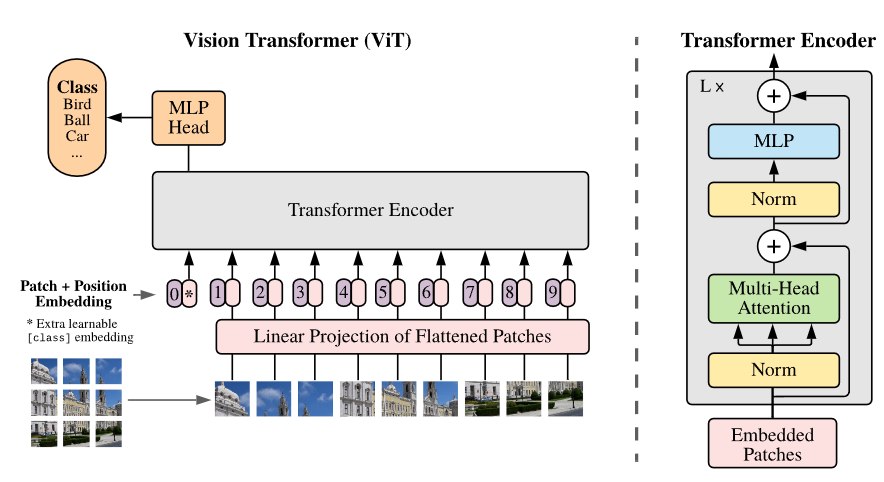
2.1 图像切块(Patch Embedding)
与NLP中的单词一样,ViT将图像分割成固定大小的小块(例如,16×16或32×32的图像块)。每个图像块会被展平成一维向量,并通过一个线性变换(通常是一个全连接层)将其映射到更高维的空间。这些图像块向量就像NLP中的单词嵌入(Word Embeddings)一样,成为Transformer的输入。
2.2 Transformer编码器(Transformer Encoder)
与经典的Transformer架构类似,ViT使用多个Transformer编码器层来处理输入的图像块。这些编码器层由以下几个部分组成:
-
自注意力机制(Self-Attention):通过计算各个图像块之间的关系,ViT能够捕捉图像中的全局信息,而不仅仅是局部信息。
-
前馈神经网络(Feed-forward Neural Network):每个图像块的特征会通过一个前馈神经网络进行非线性转换。
-
残差连接(Residual Connection):为了避免深层网络中的梯度消失问题,ViT使用残差连接来保证信息流动。
此外,ViT在输入时加入了位
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7501
7501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









