







1.数据库表主键选择uuid还是自增id的思考
uuid:优点就是保证唯一,本身具有无序性。 但正是因为UUID是无序性的,本身的size过大,作为主键会涉及大量索引重排。
why id自增和uuid均不适合分布式?
id自增:存储空间小,性能高。
- 但当数据量庞大时,在数据库分库分表后(分表就是把一个表的数据放到多个表中,分库即将一个库的数据拆分到多个库中),数据库自增id不能满足唯一id来标识数据; 因为每个表都按自己节奏自增,会造成id冲突,无法满足需求。
- 很容易被别人知晓业务量;
- 高并发的情况下,竞争自增锁会降低数据库的吞吐能力;
- 数据迁移的时候,特别是发生表格合并这种操作的时候,非常麻烦。
- 因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。 特别是在新系统上线时,新旧系统并行存在,并且是异库异构的数据库的情况下,需要双向同步时,自增主键将是噩梦;
uuid:不会冲突。 数据拆分、合并存储的时候,能达到全局的唯一性; 可以在应用层生成,提高数据库吞吐能力; 是string类型,写代码的时候方便
- UUID长且无序; 主键应越短越好,无序会造成每一次UUID数据的插入都会对主键地城的b+树进行很大的修改。 1)在时间上,uuid由于占用的内存更大,所以查询、排序速度会相对较慢; 2)在存储过程中,自增长id由于主键的值是顺序的,所以InnoDB把每一条记录都存储在上一条记录的后面。 当达到页的最大填充因子时(innodb默认的最大填充因子为页大小的15/16,留出部分空间用于以后修改),下一条记录就会写入新的页面中。 一旦数据按照这种方式加载,主键页就会被顺序的记录填满。 而对于uuid,由于后面的值不一定比前面的值大,所以InnoDB并不能总是把新行插入的索引的后面,而是需要为新行寻找合适的位置(通常在已有行之间)并分配空间。 也就是说,如果发生了随机io,那么就会频繁地移动磁盘块。 当数据量大的时候,写的短板将非常明显。 当然,这个缺点可以通过nosql那些产品解决。
- uuid占空间大,如果你建的索引越多,影响越严重;
- 读取出来的数据也是没有规律的,通常需要order by,其实也很消耗数据库资源;
meta_table表有一个db_id字段关联到sys_connection id字段。 在迁移过程时就会存在修改meta_table表db_id字段值的情况,这无疑增加了业务侧的工作量,如果使用uuid,那关联字段就不需要在迁移时改变了。
注意:1)对于几十万数据量级别的表来说,主键选择自增id或uuid在插入性能上差距不明显,因此对于中小型项目来说,完全不需要考虑插入性能上的差异。 2)对于存在关联关系表的场景下,不管是数据迁移还是插入数据,使用uuid都比自增id来的方便。 3)使用自增id时,尽量不要去指定自增主键id值去插入,一旦这样操作那后续就容易出现主键冲突问题。
评价:用 自增ID 做外键关联表?
自增主键可能会在导表或者数据恢复的情况下出现变动,导致关联错误;
但如果不会分库,那么这样做没什么问题。 就算是分库,跨库的关联操作也肯定是要尽量避免的。 所以,自增ID做外键大部分场景是没有问题的;
在系统集成或割接时,如果新旧系统主键不同是数字型就会导致修改主键数据类型,这也会导致其它有外键关联的表的修改,后果很严重;
雪花雪花算法
SnowFlake算法是Twitter设计的一个可以在分布式系统中生成唯一的ID的算法,它可以满足Twitter每秒上万条消息ID分配的请求,这些消息ID是唯一的且有大致的递增顺序,他既可以保证是连续的也可以保证在分布式系统中是唯一的。
实现雪花算法时候要注意时间回拨带来的影响。 就是在实际使用过程中,程序所处的服务器,时间往前或者往后调个几毫秒,这种情况下会产生重复的 ID。 这种情况在实际几乎是不会遇到的。
1位标识部分:在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以为0;
41位时间戳部分:这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始; 41位的时间戳可以使用69年,(1L<< 41) / (1000L * 60 * 60 * 24 * 365) = 69年;
10位节点部分:Twitter实现中使用前5位作为数据中心标识,后5位作为机器标识,可以部署1024个节点;
12位序列号部分:支持同一毫秒内同一个节点可以生成4096个ID。
整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞,并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右
2.SqlSession工厂:SqlSessionFactory会话工厂——没整太明白
MyBatis(二):SqlSessionFactory和SqlSession - 知乎 (zhihu.com) 写的很深入很详细!
SqlSessionFactory
SQlSqlSessionFactory是MyBatis的关键对象,它是单个数据库映射关系经过编译后的内存镜像。每一个MyBatis的应用程序都以一个SqlSessionFactory对象的实例为核心。SqlSessionFactory是线程安全的,SqlSessionFactory一旦被创建,应该在应用执行期间都存在。在应用运行期间不要重复创建多次,建议使用单例模式。SqlSessionFactory是创建SqlSession的工厂。
运用SqlSession测试mybatis:
SqlSession
- 1. SqlSession是MyBatis操作数据库的核心对象,是执行持久化操作的独享,类似于JDBC中的Connection。SqlSession使用JDBC方式与数据库交互,同时提供了数据表的CRUD(增删改查)对应的api方法。
- 2.它是应用程序与持久层之间执行交互操作的一个单线程对象,也是MyBatis执行持久化操作的关键对象。
- 3.SqlSession对象完全包含以数据库为背景的所有执行SQL操作的方法,它的底层封装了JDBC连接,可以用SqlSession实例来直接执行被映射的SQL语句。
- 4.每个线程都应该有它自己的SqlSession实例。
- 5.SqlSession的实例不能被共享,同时SqlSession也是线程不安全的,绝对不能讲SqlSeesion实例的引用放在一个类的静态字段甚至是实例字段中。也绝不能将SqlSession实例的引用放在任何类型的管理范围中,比如Servlet当中的HttpSession对象中。
- 6.使用完SqlSeesion之后关闭Session很重要,应该确保使用finally块来关闭它
使用:如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try…catch…finally… 语句来保证其正确关闭。
终于明白了!MyBatis执行SQL的两种方式:SqlSession和Mapper接口代理
Mapper接口代理的方式:
1、通过这种配置可以实现不用sqlsession而实现crud,因为都交给sprin来实现了,但是这种方法在service层实现的时候代码会比较冗余,但是这种方法思路比较清晰。
2、可以通过mybatis generator来自动生成 mapper接口、实体Bean、mapper.xml映射文件,开发速度上快...
sqlSession方式:
1、sqlSession来实现dao,这种方法比较灵活
2、这种方式有很明显的缺点就是通过字符串去调用标签定义的SQL,第一容易出错,第二是当XML当中的id修改过以后你不知道在程序当中有多少个地方使用了这个ID,需要手工查找并一一修改,可以改进...
3.索引相关
索引定义
- 索引是数据库中一个用于排序的数据结构,用来高效查询数据库中的数据。
- Mysql数据库中的索引实现主要依赖于两个存储引擎,MyISAM和InnoDB,都是使用B+树作为索引结构。
- 建索引的优缺点:优点:大大加快对数据的查询速度 / 缺点:占物理空间,一个索引对应的就是一棵b+树,每一个节点都是一个16KB大小的页。对数据库进行增、删、改的时候也要动态的维护索引。
索引的类型
- UNIQUE (唯一索引):不可能出现相同的值,可以有NULL值,与主键索引不同的是,一个表中唯一索引可以有多个;
- INDEX (普通索引):允许出现相同的索引内容,可以有NULL值;用于快速定位特定数据;
- PRIMARY KEY (主键索引):不允许出现相同的值,不允许有空值,一个表只能有一个主键。
- FULLTEXT INDEX (全文索引):全文索引主要用来查找文本中的关键字,而不是直接与索引中的值相比较。fulltext索引跟其它索引大不相同,它更像是一个搜索引擎,而不是简单的where语句的参数匹配。可以针对值中的某个单词,但效率确实不高;(注意:只能用于MyISAM类型的数据表;只能用于CHAR ,VARCHAR,TEXT数据列类型;使用大型数据集)
- 组合索引:实质上是将多个字段建到一个索引里,列值得组合必须唯一。只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用组合索引时遵循最左前缀集合。
索引的创建/删除
1.创建索引
(1)创建数据时创建索引,语法格式如下:
CREATE TABLE table_name
column_name1 data_type1 [, column_name2 data_type2, …, column_namen data_typen]
[PRIMARY | UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY]
[index_name] (column_name [length])
[ASC | DESC]
(2)使用ALTER语句创建,同时设置索引长度,语法如下:
ALTER TABLE tableName ADD INDEX indexName(columnName(index lenth));
①PRIMARY KEY(主键索引)
mysql > ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
②UNIQUE(唯一索引)
mysql > ALTER TABLE `table_name` ADD UNIQUE (`column` )
③INDEX(普通索引)
mysql > ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
④FULLTEXT(全文索引)
mysql > ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
⑤多列索引(组合索引)
mysql > ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
(3)使用CREATE INDEX创建,语法如下:
CREATE INDEX indexName ON tableName (columnName(length));
①mysql > CREATE INDEX index_name on 表名(column)
②mysql > CREATE unique index_name on 表名(column)
2.查看索引
SHOW INDEX FROM t_user_action_log;
3.删除索引
MySQL中可以使用ALTER TABLE语句和DROP INDEX语句删除索引。
(1)ALTER TABLE语句的语法格式如下:
ALTER TABLE table_name
DROP INDEX index_name
(2)DROP INDEX语句的语法格式如下:
DROP INDEX index_name
ON table_nameB+树原理详解
大部分数据库系统及文件系统都采用B Tree或其变种B+Tree作为索引结构。
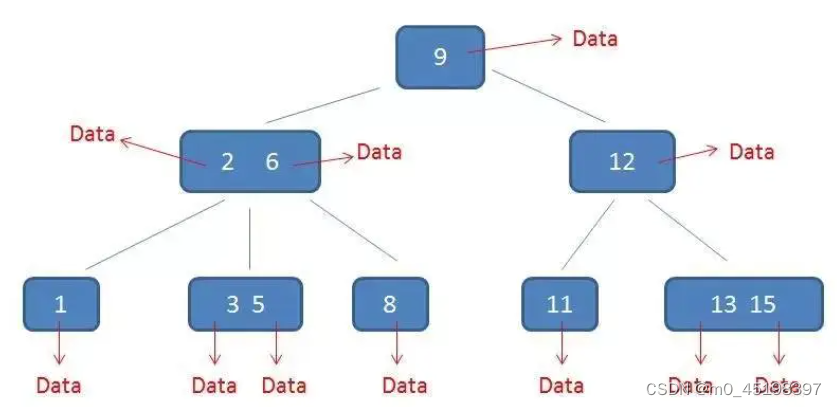
1. B+树的新特征:
- 有k个子树的中间节点不保存数据,只用来索引,所有数据都保存在叶子节点;
- 所有的叶子节点中包含了全部元素的信息,且叶子节点本身依关键字的大小自小而大顺序用链表链接;(每个叶子节点都带有指向下一个节点的指针,形成了一个有序链表。)
- 每个父节点中的元素都出现在了子节点中,是子节点中的最大(或最小)元素。
- 在B树中,无论中间节点还是叶子节点都带有卫星数据;而在B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有任何数据关联。见下图:
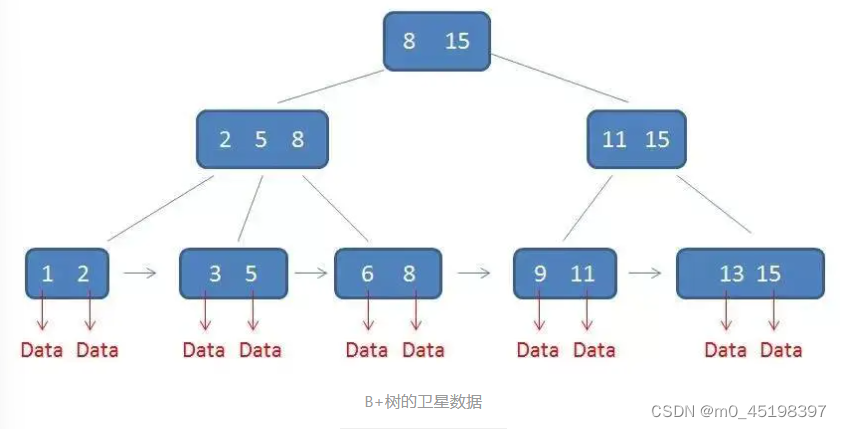
2.在查询过程中B+树的优势(相对于B树):
- 首先,B+树中间节点没有卫星数据,只存索引数据,所以同样大小的磁盘页可以容纳更多的节点元素,这就意味着,数据量相同的情况下B+树比B树更加的”矮胖“,相应会减小IO次数。其次,B+树的查询必须最终查找到叶子节点,而B树只要找到匹配元素即可,无论匹配元素处于中间节点还是叶子节点。因此,B树的查找性能并不稳定,而B+树每一次查找都是稳定的。
- B树只能靠中序遍历,而B+树只需在链表上做遍历即可,便于范围查询。
InnoDB索引模型
lnnoDB使用了B+树索引模型,每一个索引在InnoDB里面对应―棵B+树。
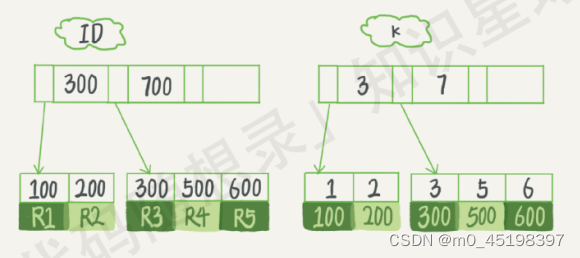
根据叶子节点的内容,索引类型分为主键索引(上图ID)和非主键索引(上图k字段):
- 主键索引的叶子节点存的是整行数据。在InnoDB 里,主键索引也被称为聚簇索引 (clustered index)
- 非主键索引的叶子节点存的是主键的值,在InnoDB里,非主键索引也被称为二级索引 (secondary index)
主键查询vs.普通索引查询:
- 主键查询:直接在主键索引所在的B+树中查询,然后直接返回查询到的叶子节点(此时,叶子节点里面就是整行记录)
- 普通索引查询::首先,在普通索引所在的B+树中,查询到待查询记录的主键;然后,再根据这些查到的主键,执行“主键查询”(即,回表)
- 基于非主键索引的查询需要多扫描―棵索引树。因此,我们在应用中应该尽量使用主键查询。
适合/不适合索引的场景
1.不适合索引的场景:
- 在查询中很少使用或者是参考的列不适合创建索引。因为有无索引并不能提高查询速度。相反,增加了索引反而降低了系统的维护速度且增大了空间需求。
- 只有很少数据值的列不适合创建索引。
- 被定义为text, image和bit数据类型的列不适合创建索引。因为这些列的数据量要么相当大,要么取值很少。
- 当修改性能远远大于检索性能时不应该创建索引。修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。
- 经常插入、删除、修改的表。
- 不会出现在where条件中的字段不适合建立索引。
2.适合索引的场景
- 表的主键、外键必须有索引;
- 数据量特别大的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;经常连接查询,需要有索引
- 经常出现在Where子句中的字段,加快判断速度,特别是大表的字段,应该建立索引,建立索引,一般用在select ……where f1 and f2 ,我们在f1或者f2上建立索引是没用的。只有两个使用联合索引才能有用
- 经常用到排序的列上,因为索引已经排序。
- 经常用于范围内搜索的列上创建索引,因为索引已经排序了,其指定的范围是连续的
索引命中/索引失效/索引优化
索引命中:即怎么写sql能使用到索引;
索引失效:不能用到索引的情况:
- 模糊匹配当中以“%”开头时,索引失效
- OR有一边的条件字段没有索引时,索引失效
- 使用复合索引的时候,没有使用左侧的列查找,索引失效
- 在where当中索引列参加了运算,索引失效
- 在where当中索引列使用了函数,索引失效
如何使索引命中
- 尽量避免在where字句中对字段进行空值判断,这会导致引擎放弃使用索引,进行全表扫描
- 字段值分布很稀少的字段,不适合建立索引
- 不要用字符字段做主键
- 字符字段只建立前缀索引
- 不要用外键和UNIQUE
- 使用多列索引时,注意顺序和查询条件保持一致,同时删除不必要的单列索引
索引优化
1. 覆盖索引:在普通索引树中,就可以直接查到待查结果,而不需要回表。例如当执行如下语句时,这时只需要查ID的值,而ID的值已经在k索引树上了,因此可以直接提供查询结果,不需要回表(查主键)
select ID from T where k between 3 and 5由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
2. 最左前缀原则:
- 最左前缀:可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符
场景︰当单独为一个不频繁的请求创建索引时,会造成空间浪费;但是,如果直接让它走全表查询(一个一个找),那效率也太低了吧?此时,应该怎么做?
答:B+树这种索引结构,可以利用索引的“最左前缀",来定位记录。
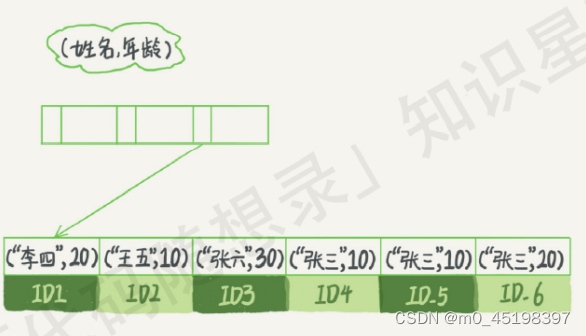
使用"最左前缀"查询:见上图(name,age)索引示意图。当查询语句是where name like ‘张%'时,也能够用上这个索引:1)首先,查找到第一个符合条件的记录是ID3;2)然后,向后遍历,直到不满足条件为止
- Note︰1)使用'like %张"时,索引失效(即,必须使用最左前缀)
- 2)考虑到′最左前缀原则",可以通过调整组合索引中的字段顺序,可以少维护一个索引)
3.索引下推:
索引下推:可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。还是上面的例子,根据前缀索引规则,这个语句在搜索索引树的时候,只能用“张",找到第一个满足条件的记录ID3,然后在MySQL5.6之前,只能从ID3开始一个个回表,到主键索引上找出数据行,再对比字段值。而MySQL 5.6引入的索引下推优化。
select * from tuser
where name like '张 %'
and age=10
and ismale=1;
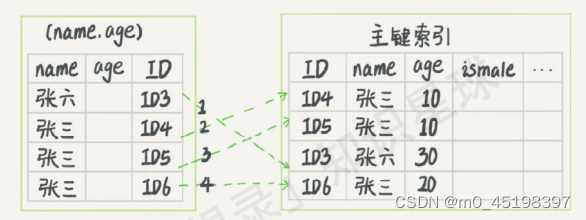
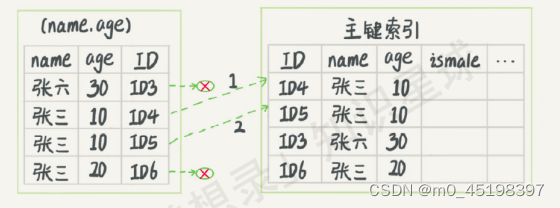
由上两个图可知本例中无索引优化时,需要回表4次;采用索引下推优化,直接在索引遍历的过程中,过滤了不符合条件的记录(ID3、ID6),只用回表2次。
索引进一步思考
- 1.索引不会包含有NULL值的列:只要列中包含有NULL值都将不会被包含在索引中,复合索引中只要有一列含有NULL值,那么这一列对于此复合索引就是无效的。所以我们在数据库设计时不要让字段的默认值为NULL。
- 2.使用短索引:索引时应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,不要对整个列进行索引,取前10个/20个进行索引即可。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
- 3.索引列排序:MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。
- 4.like语句操作:一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
- 5.避免在索引上使用计算:
-
select id from userinfo where YEAR(adddate)<2007; //将在每个行上进行运算,这将导致索引失效而进行全表扫描,因此我们可以改成 select id from userinfo where adddate<‘2007-01-01’; - 6.尽量避免使用in和NOT IN和<>操作,否则会导致全表扫描,因为逻辑判断会让索引失效。
-
select id from t where num in(1,2,3) //对于连续的数值,能用 between 就不要用 in 了 select id from t where num between 1 and 3 - 7.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如下面这句可以写成:
-
select id from t where num=10 or num=20; -
select id from t where num=10 union all select id from t where num=20
SQL执行计划的获取:加上explain关键词即可
为什么关注sql的执行计划:因为一个sql的执行计划可以告诉我们很多关于如何优化sql的信息 。
- 了解SQL如何访问表中的数据
- 了解SQL如何使用表中的索引
- 了解SQL所使用的查询类型
各个字段的含义:
1.id 表示执行的顺序,id越大越先执行,id一样的从上往下执行。
2.select_type 表示查询类型,通常有:
simple:表示不需要union操作或者不包含子查询的简单查询。
primary:表示最外层查询。
union:union操作中第二个及之后的查询。
dependent union:union操作中第二个及之后的查询,并且该查询依赖于外部查询。
subquery:子查询中的第一个查询。
dependent subquery:子查询中的第一个查询,并且该查询依赖于外部查询。
derived:派生表查询,既from字句中的子查询。
materialized:物化查询。
uncacheable subquery:无法被缓存的子查询,对外部查询的每一行都需要重新进行查询。
uncacheable union:union操作中第二个及之后的查询,并且该查询属于uncacheable subquery。
3.table 表名或者表的别名。
4.partitions 分区信息,非分区表为null。
5.type 访问类型,表示找到所查询数据的方法,也是本文重点介绍的属性。该属性的常见值如下,性能从好到差:
NULL:无需访问表或者索引,比如获取一个索引列的最大值或最小值。
system/const:当查询最多匹配一行时,常出现于where条件是=的情况。system是const的一种特殊情况,既表本身只有一行数据的情况。
eq_ref:多表关联查询时,根据唯一非空索引进行查询的情况。
ref:多表查询时,根据非唯一非空索引进行查询的情况。
range:在一个索引上进行范围查找。
index:遍历索引树查询,通常发生在查询结果只包含索引字段时。
ALL:全表扫描,没有任何索引可以使用时。这是最差的情况,应该避免。
6.possible_keys 表示mysql此次查询中可能使用的索引。
7.key 表示mysql实际在此次查询中使用的索引。
8.key_len 表示mysql使用的索引的长度。该值越小越好。
9.ref 表示连接查询的连接条件。
10.rows 表示mysql估计此次查询所需读取的行数。该值越小越好。
11.extra 表示mysql解决查询的其他信息,有几十种不同的值,该信息也是我们优化sql可以专注的一个值
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









