







CMS与三色标记算法
CMS(Concurrent Mark Sweep)是一款里程碑式的垃圾收集器,为什么这么说呢?因为在它之前,GC线程和用户线程是无法同时工作的,即使是Parallel Scavenge,也不过是GC时开启多个线程并行回收而已,GC的整个过程依然要暂停用户线程,即Stop The World。这带来的后果就是Java程序运行一段时间就会卡顿一会,降低应用的响应速度,这对于运行在服务端的程序是不能被接收的。
GC时为什么要暂停用户线程?
首先,如果不暂停用户线程,就意味着期间会不断有垃圾产生,永远也清理不干净。
其次,用户线程的运行必然会导致对象的引用关系发生改变,这就会导致两种情况:漏标和错标。
漏标
原本不是垃圾,但是GC的过程中,用户线程将其引用关系修改,导致GC Roots不可达,成为了垃圾。这种情况还好一点,无非就是产生了一些浮动垃圾,下次GC再清理就好了。
错标
原本是垃圾,但是GC的过程中,用户线程将引用重新指向了它,这时如果GC一旦将其回收,将会导致程序运行错误。
针对这些问题,CMS是如何解决的呢?它是如何做到GC线程和用户线程并发工作的呢?
CMS收集器
CMS收集器是⼀种以获取最短回收停顿时间为⽬标的收集器。它⽽⾮常符合在注重⽤户体验的应⽤上使⽤。
CMS收集器是HotSpot虚拟机第⼀款真正意义上的并发收集器,它第⼀次实现了让垃圾收集线程与⽤户线程(基本上)同时⼯作。
Concurrent Mark Sweep,从名字上就可以看出来,这是一款采用「标记清除」算法的垃圾收集器,它运行的示意图大概如下:
 大概可分为四个主要步骤:
大概可分为四个主要步骤:

1、初始标记
初始标记仅仅只是标记一下GC Roots能直接关联到的对象,速度很快。初始标记的过程是需要触发STW的,不过这个过程非常快,而且初试标记的耗时不会因为堆空间的变大而变慢,是可控的,因此可以忽略这个过程导致的短暂停顿。
2、并发标记
并发标记就是将初始标记的对象进行深度遍历,以这些对象为根,遍历整个对象图,这个过程耗时较长,而且标记的时间会随着堆空间的变大而变长。不过好在这个过程是不会触发STW的,用户线程仍然可以工作,程序依然可以响应,只是程序的性能会受到一点影响。因为GC线程会占用一定的CPU和系统资源,对处理器比较敏感。CMS默认开启的GC线程数是:(CPU核心数+3)/4,当CPU核心数超过4个时,GC线程会占用不到25%的CPU资源,如果CPU数不足4个,GC线程对程序的影响就会非常大,导致程序的性能大幅降低。
3、重新标记
由于并发标记时,用户线程仍在运行,这意味着并发标记期间,用户线程有可能改变了对象间的引用关系,可能会发生两种情况:一种是原本不能被回收的对象,现在可以被回收了,另一种是原本可以被回收的对象,现在不能被回收了。针对这两种情况,CMS需要暂停用户线程,进行一次重新标记。
4、并发清理
重新标记完成后,就可以并发清理了。这个过程耗时也比较长,且清理的开销会随着堆空间的变大而变大。不过好在这个过程也是不需要STW的,用户线程依然可以正常运行,程序不会卡顿,不过和并发标记一样,清理时GC线程依然要占用一定的CPU和系统资源,会导致程序的性能降低。
CMS收集器的优缺点:
尽管CMS是一款里程碑式的垃圾收集器,开启了GC线程和用户线程同时工作的先河,但是不管是哪个JDK版本,CMS从来都不是默认的垃圾收集器,究其原因,还是因为CMS不太完美,存在一些缺点。
 1、对处理器敏感
1、对处理器敏感
并发标记、并发清理阶段,虽然CMS不会触发STW,但是标记和清理需要GC线程介入处理,GC线程会占用一定的CPU资源,进而导致程序的性能下降,程序响应速度变慢。CPU核心数多的话还稍微好一点,CPU资源紧张的情况下,GC线程对程序的性能影响非常大。
2、浮动垃圾
并发清理阶段,由于用户线程仍在运行,在此期间用户线程制造的垃圾就被称为“浮动垃圾”,浮动垃圾本次GC无法清理,只能留到下次GC时再清理。
3、并发失败
由于浮动垃圾的存在,因此CMS必须预留一部分空间来装载这些新产生的垃圾。CMS不能像Serial Old收集器那样,等到Old区填满了再来清理。在JDK5时,CMS会在老年代使用了68%的空间时激活,预留了32%的空间来装载浮动垃圾,这是一个比较偏保守的配置。如果实际引用中,老年代增长的不是太快,可以通过-XX:CMSInitiatingOccupancyFraction参数适当调高这个值。到了JDK6,触发的阈值就被提升至92%,只预留了8%的空间来装载浮动垃圾。
如果CMS预留的内存无法容纳浮动垃圾,那么就会导致「并发失败」,这时JVM不得不触发预备方案,启用Serial Old收集器来回收Old区,这时停顿时间就变得更长了。
4、内存碎片
由于CMS采用的是「标记清除」算法,这就意味这清理完成后会在堆中产生大量的内存碎片。内存碎片过多会带来很多麻烦,其一就是很难为大对象分配内存。导致的后果就是:堆空间明明还有很多,但就是找不到一块连续的内存区域为大对象分配内存,而不得不触发一次Full GC,这样GC的停顿时间又会变得更长。
针对这种情况,CMS提供了一种备选方案,通过-XX:CMSFullGCsBeforeCompaction参数设置,当CMS由于内存碎片导致触发了N次Full GC后,下次进入Full GC前先整理内存碎片,不过这个参数在JDK9被弃用了。
三色标记算法(重点)
介绍完CMS垃圾收集器后,我们有必要了解一下,为什么CMS的GC线程可以和用户线程一起工作。
JVM判断对象是否可以被回收,绝大多数采用的都是「可达性分析」算法,关于这个算法,可以查看笔者以前的文章:大白话理解可达性分析算法。
从GC Roots开始遍历,可达的就是存活,不可达的就回收。
CMS将对象标记为三种颜色:

标记的过程大致如下:
- 刚开始,所有的对象都是白色,没有被访问。
- 将GC Roots直接关联的对象置为灰色。
- 遍历灰色对象的所有引用,灰色对象本身置为黑色,引用置为灰色。
- 重复步骤3,直到没有灰色对象为止。
- 结束时,黑色对象存活,白色对象回收。
这个过程正确执行的前提是没有其他线程改变对象间的引用关系,然而,并发标记的过程中,用户线程仍在运行,因此就会产生漏标和错标的情况。
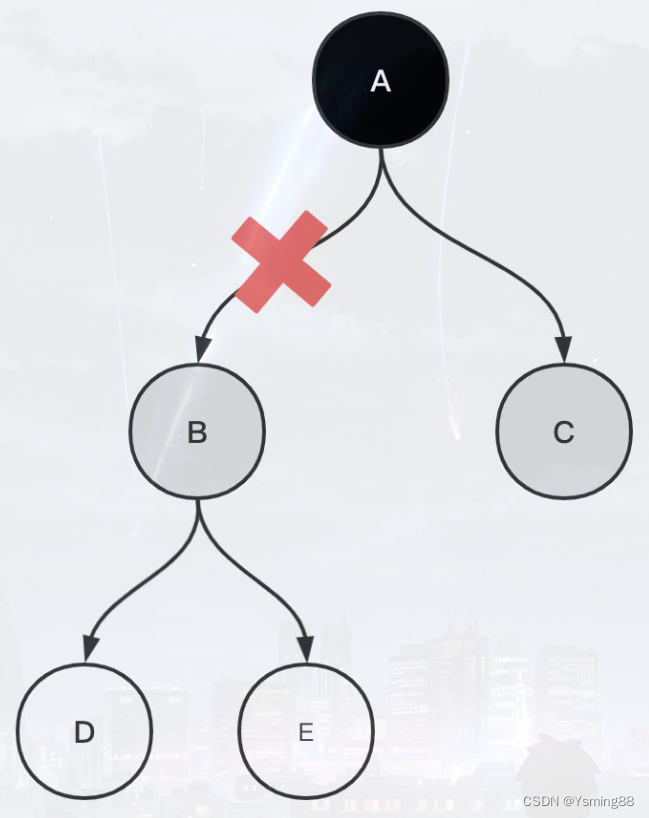
漏标
假设GC已经在遍历对象B了,而此时用户线程执行了A.B=null的操作,切断了A到B的引用。
](https://i-blog.csdnimg.cn/blog_migrate/cf639b324f1cae96ec79efbfdc9aa8f1.png)
本来执行了A.B=null之后,B、D、E都可以被回收了,但是由于B已经变为灰色,它仍会被当做存活对象,继续遍历下去。
最终的结果就是本轮GC不会回收B、D、E,留到下次GC时回收,也算是浮动垃圾的一部分。
实际上,这个问题依然可以通过「写屏障」来解决,只要在A写B的时候加入写屏障,记录下B被切断的记录,重新标记时可以再把他们标为白色即可。
错标
假设GC线程已经遍历到B了,此时用户线程执行了以下操作:
B.D=null;//B到D的引用被切断
A.xx=D;//A到D的引用被建立

B到D的引用被切断,且A到D的引用被建立。
此时GC线程继续工作,由于B不再引用D了,尽管A又引用了D,但是因为A已经标记为黑色,GC不会再遍历A了,所以D会被标记为白色,最后被当做垃圾回收。
可以看到错标的结果比漏表严重的多,浮动垃圾可以下次GC清理,而把不该回收的对象回收掉,将会造成程序运行错误。
错标只有在满足下面两种情况下才会发生:
 只要打破任一条件,就可以解决错标的问题,以下为两种解决方法:原始快照和增量更新,通过写屏障来记录。
只要打破任一条件,就可以解决错标的问题,以下为两种解决方法:原始快照和增量更新,通过写屏障来记录。
原始快照和增量更新
原始快照打破的是第一个条件:当灰色对象指向白色对象的引用被断开时,就将这条引用关系记录下来。当扫描结束后,再以这些灰色对象为根,重新扫描一次。相当于无论引用关系是否删除,都会按照刚开始扫描时那一瞬间的对象图快照来扫描。
增量更新打破的是第二个条件:当黑色指向白色的引用被建立时,就将这个新的引用关系记录下来,等扫描结束后,再以这些记录中的黑色对象为根,重新扫描一次。相当于黑色对象一旦建立了指向白色对象的引用,就会变为灰色对象。
写屏障
这个写屏障指的可不是并发编程里的写屏障哦!这里的写屏障指的是属性赋值的前后加入一些处理,类似于AOP。
CMS采用的方案就是:写屏障+增量更新来实现的,打破的是第二个条件:
当黑色指向白色的引用被建立时,通过写屏障来记录引用关系,等扫描结束后,再以引用关系里的黑色对象为根重新扫描一次即可。
伪代码大致如下:
class A{
private D d;
public void setD(D d) {
writeBarrier(d);// 插入一条写屏障
this.d = d;
}
private void writeBarrier(D d){
// 将A -> D的引用关系记录下来,后续重新扫描
}
}
为什么CMS采用“标记-清除”算法而不采用“标记-整理”算法
因为CMS作为第一款实现用户线程和收集线程并发执行的收集器!当时的设计理念是减少停顿时间,最好是能并发执行!但是问题来了,如要用户线程也在执行,那么就不能轻易的改变堆中对象的内存地址!不然会导致用户线程无法定位引用对象,从而无法正常运行!而标记整理算法和标记复制算法都会移动存活的对象,这就与上面的策略不符!因此CMS采用的是标记清理算法!
结语
CMS为了让GC线程和用户线程一起工作,回收的算法和过程比以前旧的收集器要复杂很多。究其原因,就是因为GC标记对象的同时,用户线程还在修改对象的引用关系。因此CMS引入了三色算法,将对象标记为黑、灰、白三种颜色的对象,并通过「写屏障」技术将用户线程修改的引用关系记录下来,以便在「重新标记」阶段可以修正对象的引用。
虽然CMS从来没有被JDK当做默认的垃圾收集器,存在很多的缺点,但是它开启了「GC并发收集」的先河,为后面的收集器提供了思路,光凭这一点,就依然值得记录下来。
参考:https://blog.csdn.net/qq_32099833/article/details/109558171
G1收集器
从JDK(1.3)开始,HotSpot团队一直努力朝着高效收集、减少停顿(STW: Stop The World)的方向努力,也贡献了从串行Seria收集器、到并行收集器Parallerl收集器,再到CMS并发收集器,乃至如今的G1在内的一系列优秀的垃圾收集器。
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一。早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术。同优秀的CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器,也同样适合大尺寸堆内存的垃圾收集,官方也推荐使用G1来代替选择CMS。
G1 (Garbage-First)是⼀款⾯向服务器的垃圾收集器,主要针对配备多颗处理器及⼤容量内存的机器。以极⾼概率满⾜GC停顿时间要求的同时,还具备⾼吞吐量性能特征。被视为JDK1.7中HotSpot虚拟机的⼀个重要进化特征。
G1收集器采用“标记-复制”和“标记-整理”。从整体上看是基于“标记-整理”,从局部看,两个region之间是“标记-复制”。
它具备以下特点:
①分区收集:虽然G1可以不需要其他收集器配合就能独⽴管理整个GC堆,但是还是保留了分代的概念。G1最大的特点是引入分区的思路,弱化了分代的概念。
②并⾏与并发:G1能充分利⽤CPU、多核环境下的硬件优势,使⽤多个CPU(CPU或者CPU核⼼)来缩短Stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执⾏的GC动作,G1收集器仍然可以通过并发的⽅式让java程序继续执⾏。
③算法,空间整合:与CMS的“标记–清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
④可预测的停顿:这是G1相对于CMS的另⼀个⼤优势,降低停顿时间是G1 和 CMS 共同的关注点,但G1 除了追求低停顿外,还能建⽴可预测的停顿时间模型,能让使⽤者明确指定在⼀个⻓度为M毫秒的时间⽚段内,消耗在垃圾收集上的时间不得超过N毫秒。
G1的堆内存算法
G1之前的JVM内存模型

- 新生代:伊甸园区(eden space) +2个幸存区
- 老年代
- 持久代(perm space): JDK1.8之前
- 元空间(metaspace): JDK1.8之后取代持久代
G1收集器的内存模型

1)G1堆内存结构:
堆内存会被切分成为很多个固定大小区域(Region),每个是连续范围的虚拟内存。
堆内存中一个区域(Region)的大小可以通过-XX:G1HeapRegionSize参数指定,大小区间最小1M、最大32M,总之是2的幂次方。
默认把堆内存按照2048份均分。
2)G1堆内存分配
每个Region被标记了E、S、O和H,这些区域在逻辑上被映射为Eden,Survivor和老年代。
存活的对象从一个区域转移(即复制或移动)到另一个区域。区域被设计为并行收集垃圾,可能会暂停所有应用线程。
如上图所示,区域可以分配到Eden,survivor和老年代。此外,还有第四种类型,被称为巨型区域(Humongous Region),Humongous区域是为了那些存储超过50%标准region大小的对象而设计的,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
G1收集器采用“标记-复制”和“标记-整理”。从整体上看是基于“标记-整理”,从局部看,两个region之间是“标记-复制”。
G1回收流程
在执行垃圾收集时,G1以类似于CMS收集器的方式运行。
G1收集器的阶段分以下几个步骤:

1)G1执行的第一阶段:初始标记(Initial Marking )
这个阶段是STW(Stop the World )的,所有应用线程会被暂停,标记出从GC Root开始直接可达的对象。
2)G1执行的第二阶段:并发标记
从GC Roots开始对堆中对象进行可达性分析,找出存活对象,耗时较长。当并发标记完成后,开始最终标记(Final Marking )阶段
3)最终标记(标记那些在并发标记阶段发生变化的对象,将被回收),这阶段需要停顿线程,但是可以并行执行。
4)筛选回收
暂停用户线程,筛选阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划。
G1收集器在后台维护了⼀个优先列表,每次根据允许的收集时间,优先选择回收价值最⼤的Region(这也就是它的名字Garbage-First的由来)。这种使⽤Region划分内存空间以及有优先级的区域回收⽅式,保证了GF收集器在有限时间内可以尽可能⾼的收集效率(把内存化整为零)。
对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉个旧的Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多条收集器线程并行完成的。
G1收集器只有并发标记不会stop the world,而CMS并发标记和并发清除不会stop the world
最后,G1中还提供了两种垃圾回收模式,Young GC和Mixed GC,两种都是Stop The World(STW)的。
G1的GC模式
1.YoungGC年轻代收集
在分配一般对象(非巨型对象)时,当所有eden region使用达到最大阀值并且无法申请足够内存时,会触发一次YoungGC。每次younggc会回收所有Eden以及Survivor区,并且将存活对象复制到Old区以及另一部分的Survivor区。YoungGC的回收过程如下:
- 根扫描,跟CMS类似,Stop the world,扫描GC Roots对象。
- 处理Dirty card,更新RSet.
- 扫描RSet,扫描RSet中所有old区对扫描到的young区或者survivor去的引用。
- 拷贝扫描出的存活的对象到survivor2/old区
- 处理引用队列,软引用,弱引用,虚引用
2.mixed gc
当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即mixed gc,该算法并不是一个old gc,除了回收整个young region,还会回收一部分的old region,这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些old region进行收集,从而可以对垃圾回收的耗时时间进行控制。
G1没有fullGC概念,需要fullGC时,调用serialOldGC进行全堆扫描(包括eden、survivor、o、perm)。















 6971
6971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









