







一、查询基本语法
1.查询基本结构
写顺序
select
from
join on
group by
having
order by
sort by
limit
union / union all
执行顺序
from
on
join
where
group by
having
select
distinct
order by
limit
查询注意事项
尽量不要使用子查询、尽量不要使用 in not in
select * from aa1
where id in (select id from bb);
查询尽量避免join连接查询,但是这种操作咱们是永远避免不了的。
查询永远是小表驱动大表(永远是小结果集驱动大结果集)
二、Join的语法与特点
1. 表之间的关系
在关系型数据库里面,每个实体有自己的一张表(table),所有属性都是这张表的字段 (field),表与表之间根据关联字段"连接"(join)在一起。所以,表的连接是关系型数据 库的核心问题。
所谓"连接",就是两张表根据关联字段,组合成一个数据集。
问题是,两张表的关联字段的值往往是不一致的,如果关联字段不匹配,怎么处理?
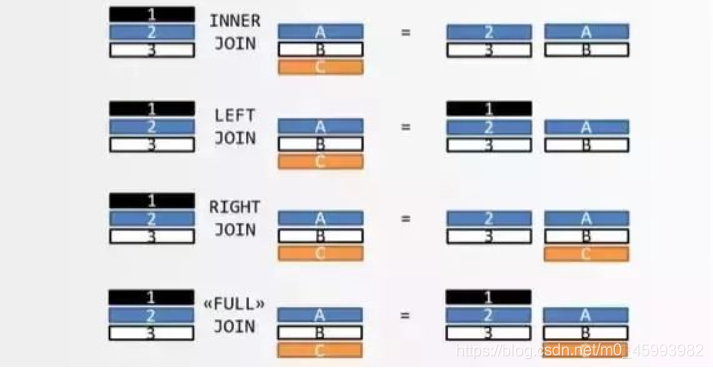
比如,表 A 包含张三和李四,表 B 包含李四和王五,匹配的只有李四这一条记录
只返回两张表匹配的记录,这叫内连接(inner join)。
返回匹配的记录,以及表 A 多余的记录,这叫左连接(left join)。
返回匹配的记录,以及表 B 多余的记录,这叫右连接(right join)。
返回匹配的记录,以及表 A 和表 B 各自的多余记录,这叫全连接(full join)。
2. Hive专有Jion的特点
2.1 left semi join
在hive中,有一种专有的join操作,left semi join,我们称之为半开连接。它是left join的一种优化形式,只能查询左表的信息,主要用于解决hive中左表的数据是否存在的问题。相当于exists关键字的用法。
2.2 子查询
hive对子查询支持不是很友好,特别是 "="问题较多;
分区字段对outer join 中的on条件无效,对inner join 中的on条件有效
2.3 map-side join
如果所用的表中有小表,将会把小表缓存在内存中,然后在map端进行连接查找。hive在map端 查找时会减小整体查询量,从内存中读取缓存的小表数据,效率较快,还省去大量数据传输和shuffle耗时
三、查询字句
1.where
后不能跟聚合函数
2.group by:
分组,通常和聚合函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











