







文章目录
一、新建数据库的时候编码和排序规则尽量和原数据库完全一样
- 这样可以避免过程存在的很多问题
- 在MySQL 5.7版本中,默认排序规则为utf8mb4_general_ci。 在MySQL 8.0版本中,默认排序规则为utf8mb4_0900_ai_ci。 由于utf8mb4_0900_ai_ci是MySQL 8.0引入的排序规则,因此将MySQL 8.0版本的表导入到MySQL 5.7或MySQL 5.6版本时,会存在字符集无法识别的问题。
- 作者建议:日常自己的项目,使用 utf8_general_ci 或者utf8mb4_general_ci 排序规则就好,反正自己的项目兼容性比速度重要。
二、表结构和表数据分开导入,不要同时导入
- 分开导入可以方便处理遇到的问题
- 一般表结构导入的速度快,但是表结构遇到的问题会比较多
Navicat导出表结构
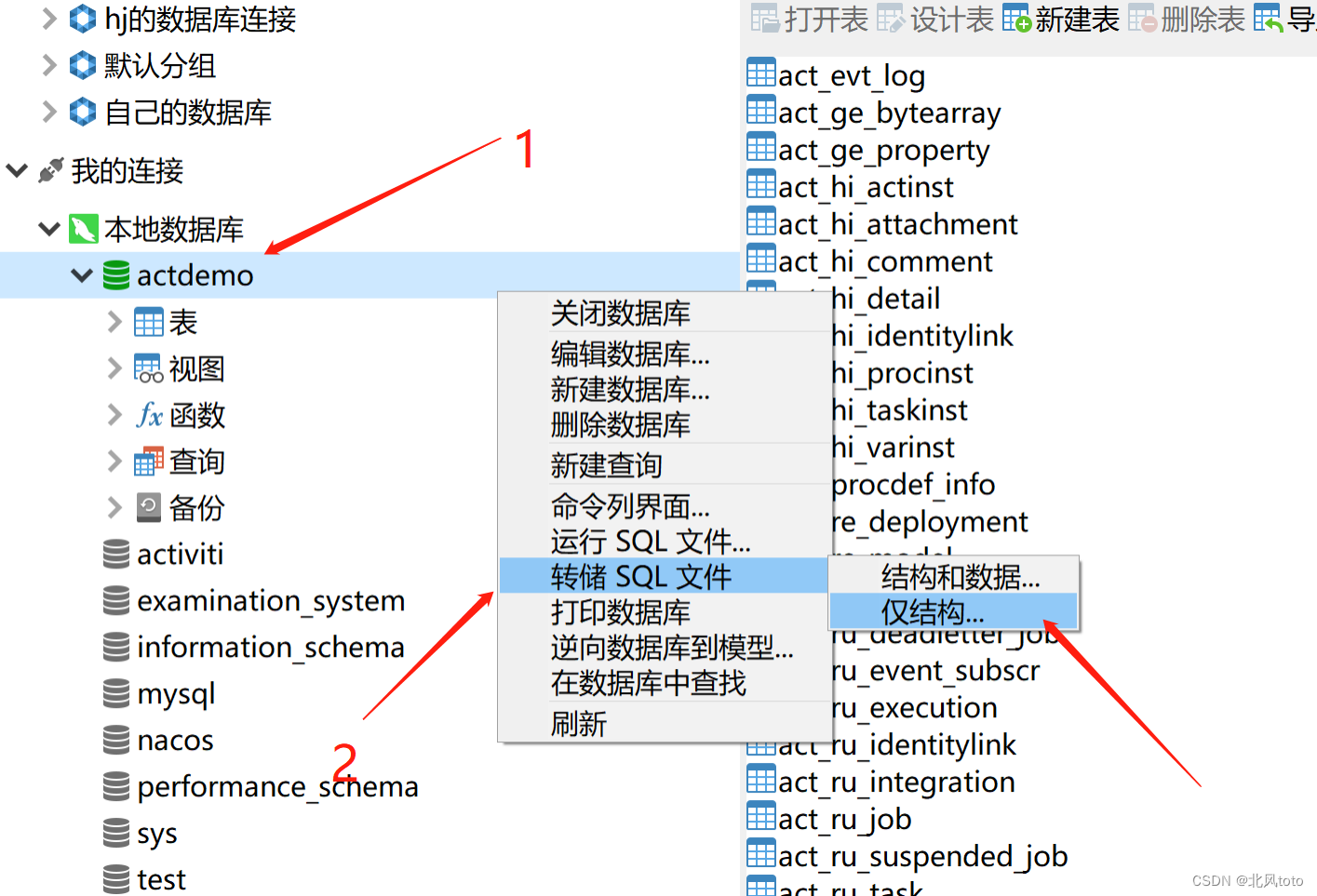
Navicat导入表结构

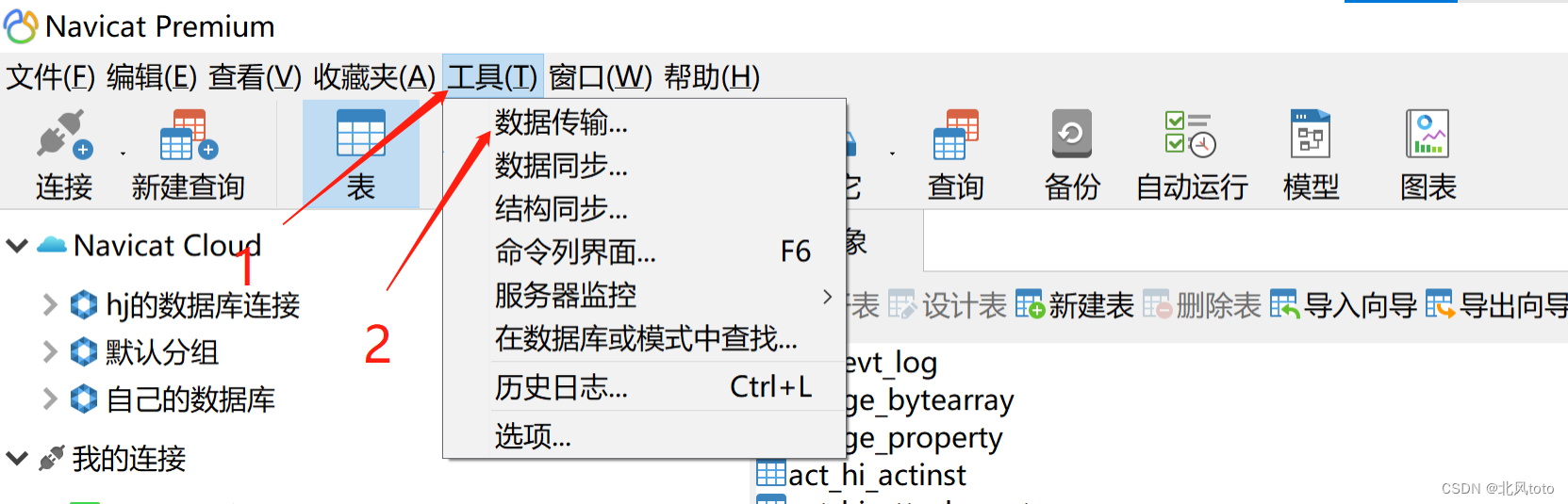
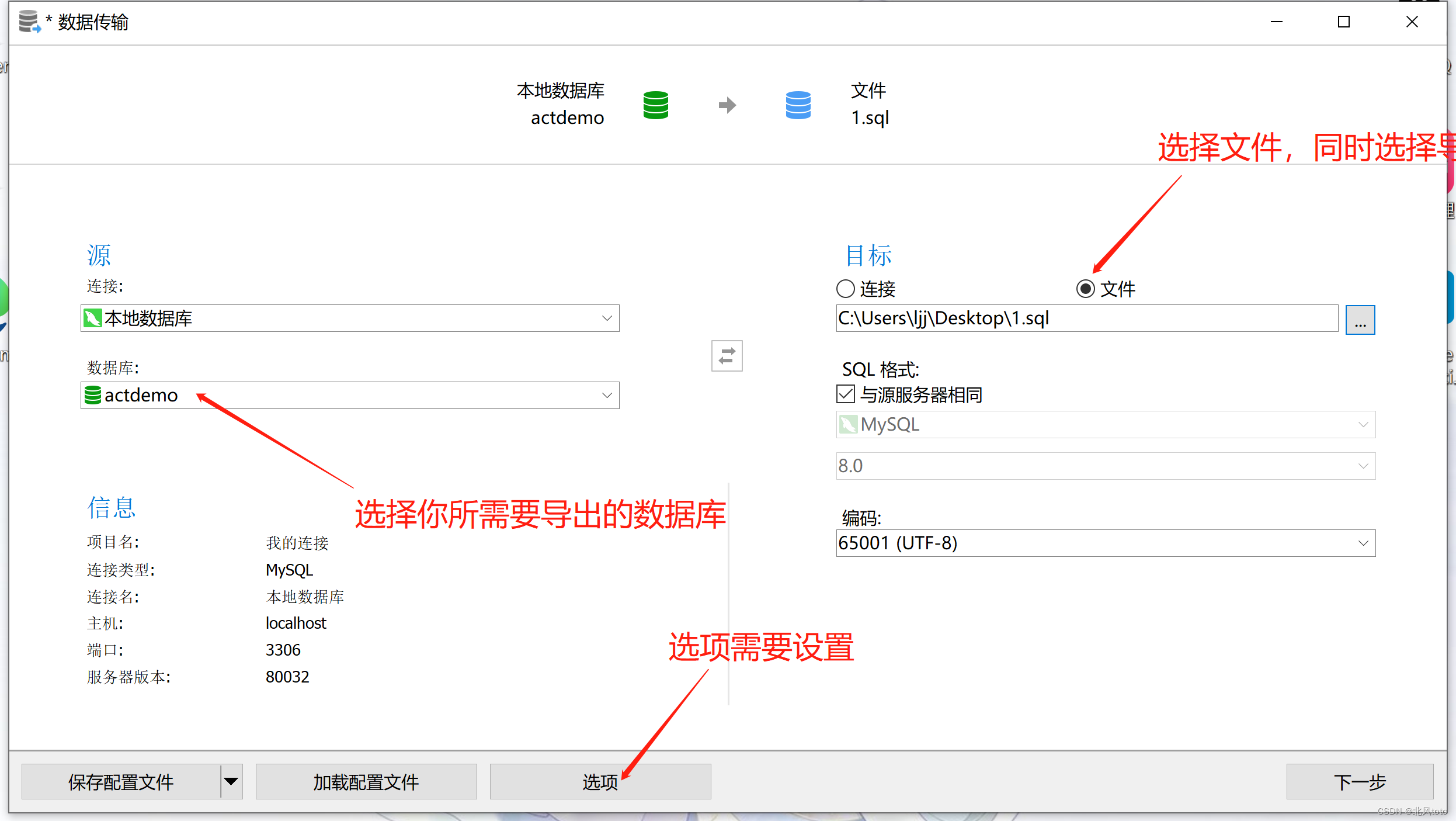
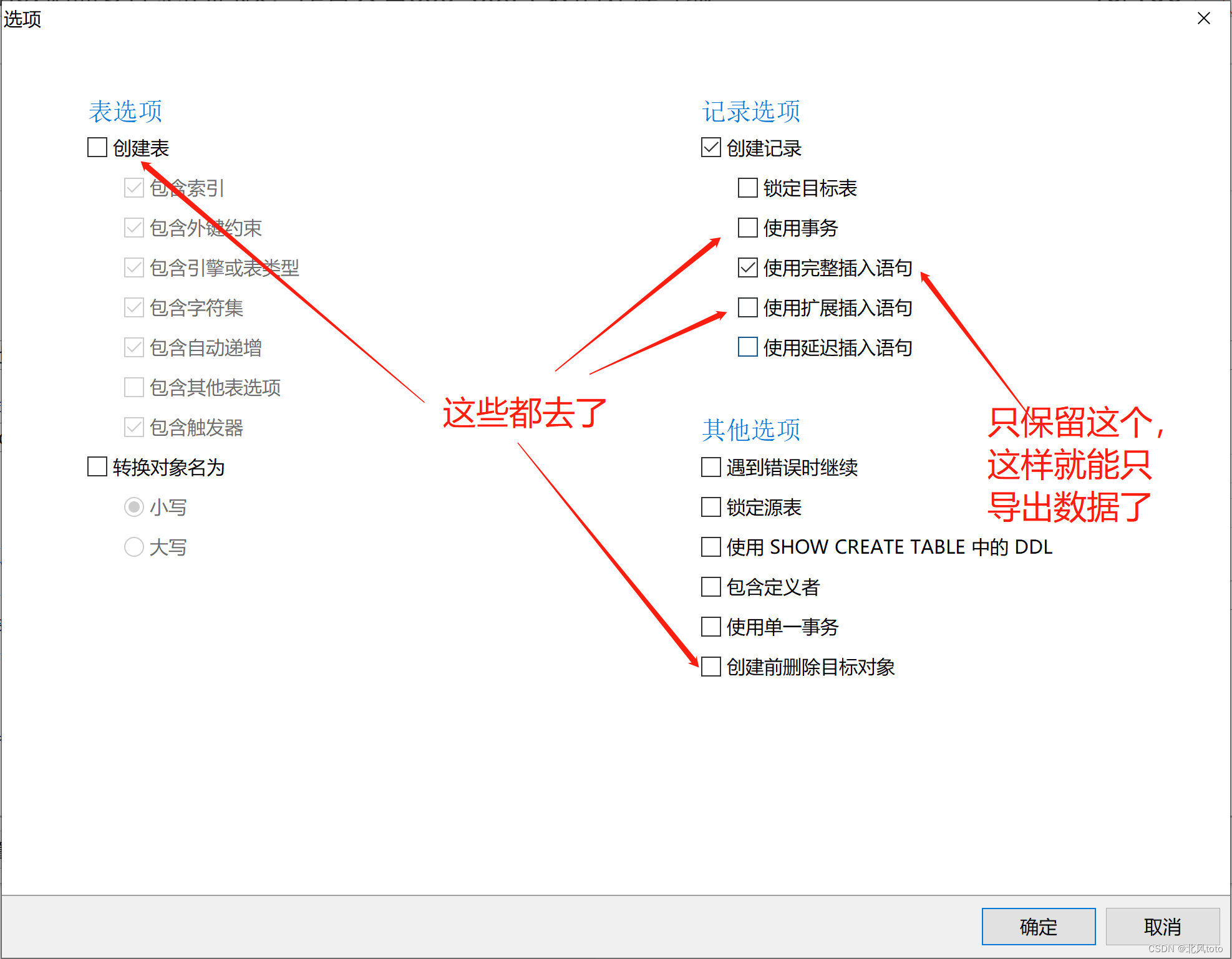
Navicat导出表数据
不使用navicat导出表数据,可以使用mysqldump命令
- 如果在linux系统下直接使用这个命令会找不到的话,那么直接去mysql安装目录下调用即可
cd /usr/mysql/mysql-5.7.18/bin
./mysqldump -t -uroot -p dbname t1 t2 > dbname数据.sql
- 参数-t 表示只导出表的数据
- dbname t1 t2:第一个参数默认为数据库,后面的都为表名
- 如果不写表,则代表把整个数据库的数据都导出
Navicat导入表数据
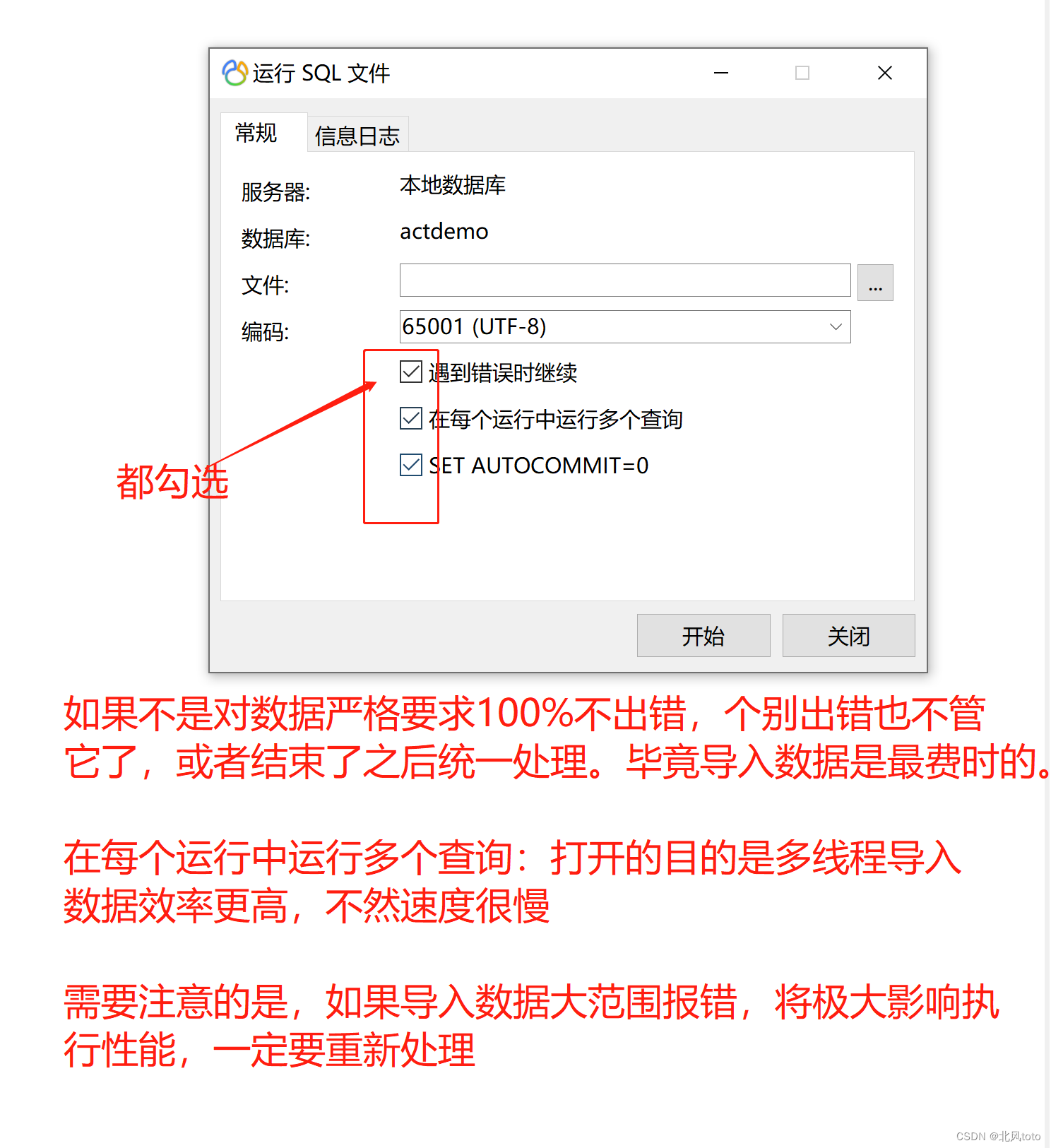
三、编码问题
- 如果导入sql的过程中表示排序规则不存在,那么对sql文件一键处理即可,把这个排序规则一键替换为存在的排序规则(作者通过这种方式解决了问题)
- utf8转换为uft8mb4,uft8mb4字符长度比utf8长,在处理表结构编码问题的时候,可能导致一个新的问题出现,单条记录的存储长度大于设定值。
四、执行顺序的问题
- 如果表存在外键依赖,那么外键的表需要更早创建
- Navicat生成的sql文件,视图的执行顺序比方法更早,但是某些视图创建的过程用到了某些方法。如果按照默认执行顺序将会报错,解决办法是把方法放在视图创建之前执行。提前把方法创建好(作者遇到)
五、迁移数据大小和速度的问题
- 作者迁移的是研发网的数据,我师傅和我说迁移部分表的数据,我感觉麻烦,于是把所有的数据都迁移了。总共500多万条的数据,导出大约6分钟,导入大约25分钟。
六、数据库表结构导入常见问题
Navicat版本导致的问题,数据库分区分片问题
- 同一个数据库,不同版本的Navicat导出的sql竟然会有略微的差异(不可思议),导致存在小问题(可能会出现错误)。可以用下面作者的sql作为尝试。
- Navicat15版本出现了问题,但是我的Navicat12版本没有出现这个问题
- sqldemo文件
DROP TABLE IF EXISTS `t_dm_test`; CREATE TABLE `t_dm_test`( `id` varchar(42) NOT NULL COMMENT 'id', `name` VARCHAR(64) NOT NULL COMMENT '名字', `org_id` VARCHAR(64) NOT NULL COMMENT '组织id' ) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT='临时表' /*!50500 PARTITION BY LIST COLUMNS(org_id) (PARTITION p01000 VALUES IN ('01000') ENGINE=INNODB, PARTITION p01001 VALUES IN ('01001') ENGINE=INNODB, PARTITION p01002 VALUES IN ('01002') ENGINE=INNODB) */; - 执行之后Navicat查看执行结果
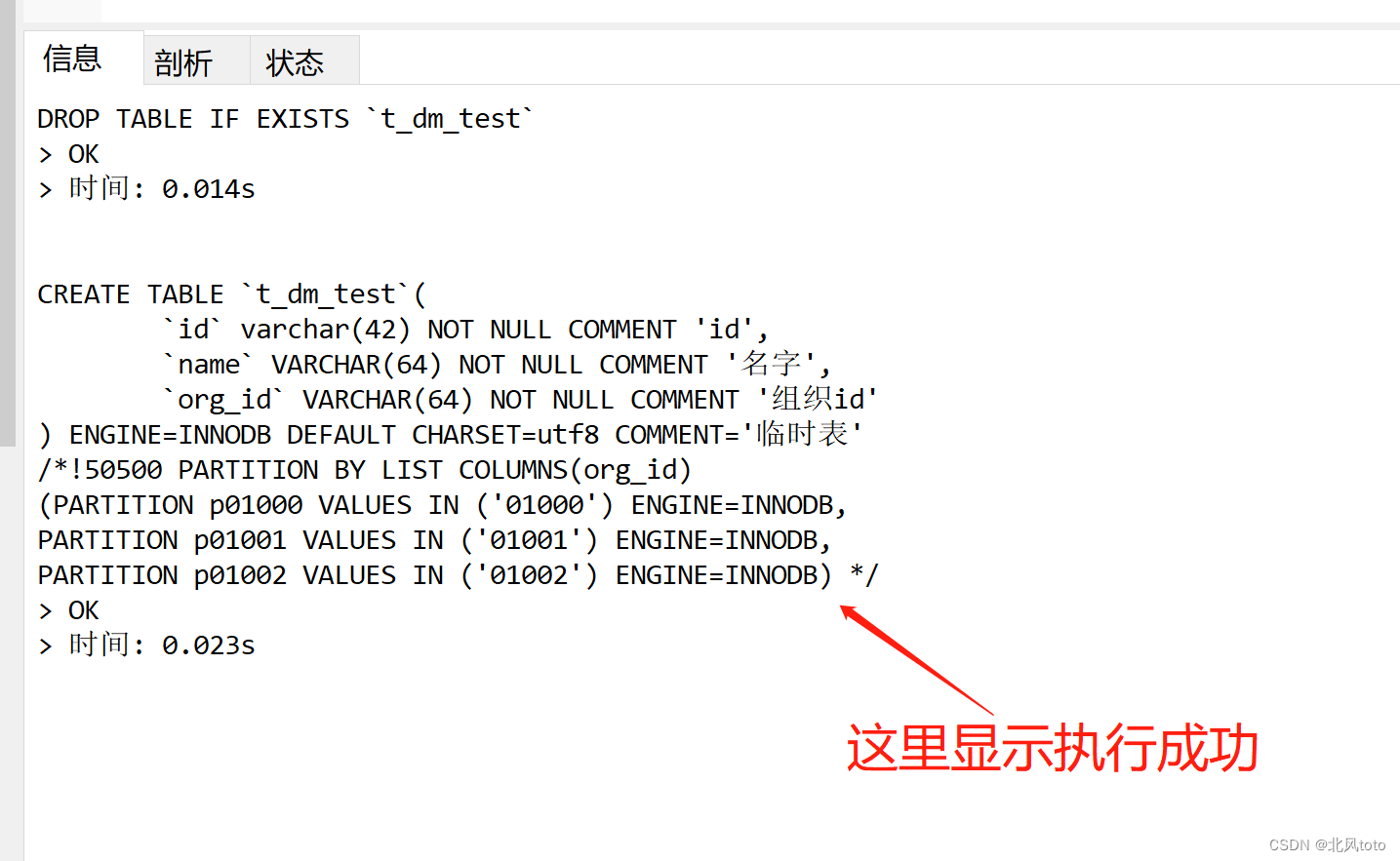
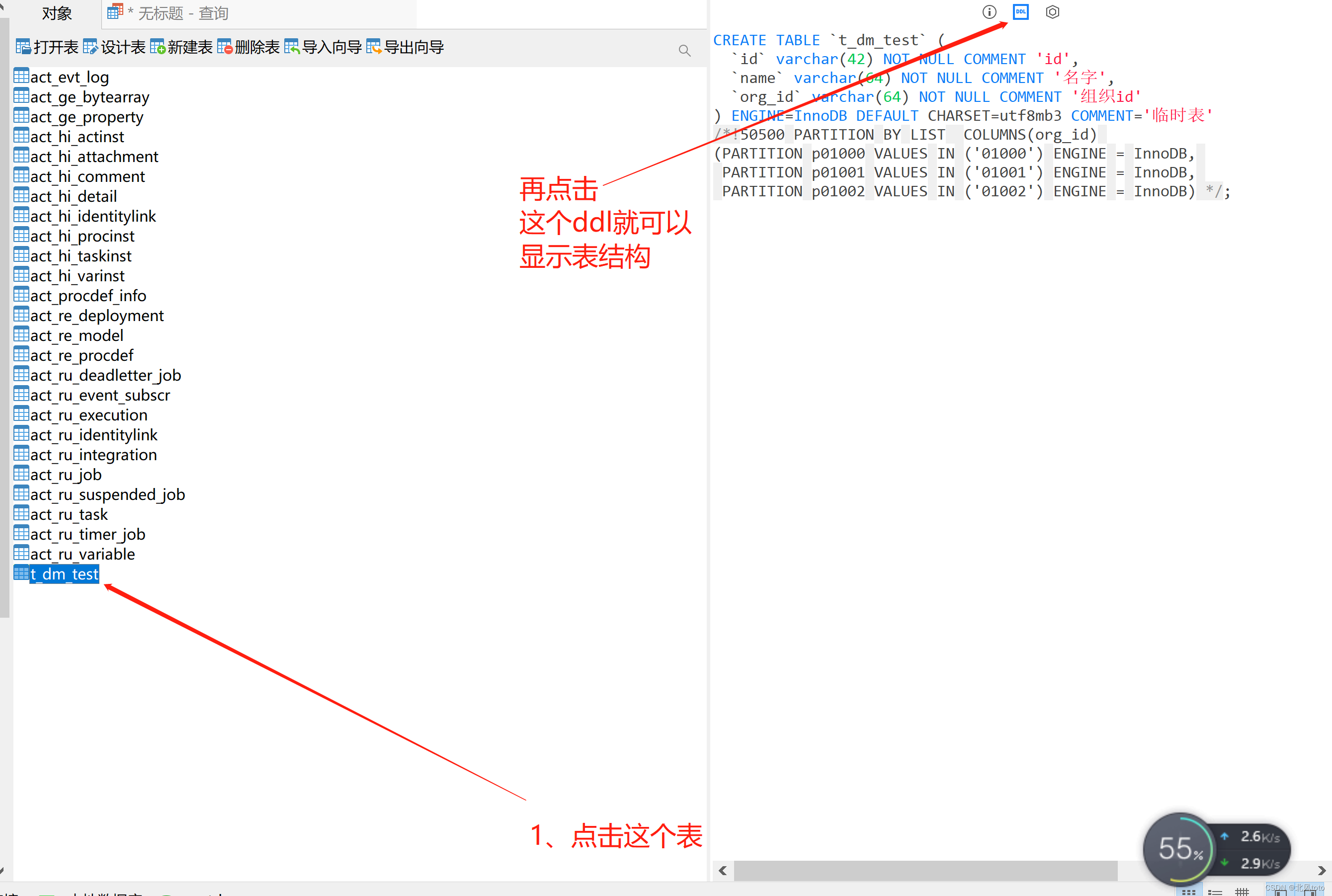
- 使用Navicat15把这个表重新导出得到的sql
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for t_dm_test -- ---------------------------- DROP TABLE IF EXISTS `t_dm_test`; CREATE TABLE `t_dm_test` ( `id` varchar(42) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT 'id', `name` varchar(64) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '名字', `org_id` varchar(64) CHARACTER SET utf8mb3 COLLATE utf8mb3_general_ci NOT NULL COMMENT '组织id' ) ENGINE = InnoDB CHARACTER SET = utf8mb3 COLLATE = utf8mb3_general_ci COMMENT = '临时表' ROW_FORMAT = Dynamic PARTITION BY LIST COLUMNS (`org_id`) PARTITIONS 3 (PARTITION `p01000` ENGINE = InnoDB MAX_ROWS = 0 MIN_ROWS = 0 , PARTITION `p01001` ENGINE = InnoDB MAX_ROWS = 0 MIN_ROWS = 0 , PARTITION `p01002` ENGINE = InnoDB MAX_ROWS = 0 MIN_ROWS = 0 ) ; SET FOREIGN_KEY_CHECKS = 1; - 重新执行看看能不能执行


- sqldemo文件
创建视图和存储过程,权限报错的问题,语句上带了上个数据库账号信息
- 错误原文
Access denied; you neea (at least oneof) the SUPER privilege(s) for this operation
- 解决方式
DEFINER=`root`@`%` 这段全删了,或者把用户名改成你登录的用户名
数据库版本导致的索引长度问题
- 错误原文,这个是数据库版本过低导致的
Specified key was too long; max keylength is 767 bytes
- 解决方式,设置mysql的innodb参数:
#开启
set global innodb_large_prefix = ON;
set GLOBAL innodb_file_format=Barracuda;
set GLOBAL innodb_file_per_table=ON;
#查询
show variables like 'innodb_large_prefix';
#关闭
set global innodb_large_prefix = OFF;
其他
- 导入导出的过程中,电脑不要黑屏,不要睡眠,同时也一定不要动Navicat。动了很容易直接导致Navicat死机,进程死亡
- 用navicat对比两个数据库表结构
- notepad++中将换行替换为空格
导出单个表的部分数据
- 生成新的student_new表,然后把数据部分导出即可
CREATE TABLE student_new
AS
SELECT *
FROM student
WHERE student.id="1"
















 8802
8802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









