






【推荐】2019 Java 开发者跳槽指南.pdf(吐血整理) >>> 
dict又称为字典,redis整个数据库结构其实就是一个dict,比如执行set msg "Hello World!",那么其存储数据的dict中就有一个键为sds结构的字符串"msg",而值则为字符串"Hello World!"。并且在redis中命令与其对应的执行函数也是用dict存储的。dict的具体数据结构如下
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx;
// 目前正在运行的安全迭代器的数量
int iterators;
} dict;其中type存储了hash函数,key和value的复制,比较以及销毁函数,而privdata则保存了一些私有数据,其和type共同决定了当前dictType结构中所保存的函数的指向,从而实现多态的目的,比如redis提供的hash函数就有两种,一种是Murmurhash函数,另一种是djbhash函数。dictType的具体结构如下:
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;dictht类型对象ht是一个长度为2的数组,正常情况下回使用ht[0]来存储数据,当进行rehash操作时,redis会使用ht[1]来配合进行渐进式rehash操作,而rehashidx是一个整数值,如果当前没有进行rehash操作,则其值为-1,如果正在进行rehash操作,那么其值为当前rehash操作正在执行到的ht[1]中dictEntry数组的索引。dictht的具体数据结构如下:
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;dictht结构中dictEntry中主要存储了key和value的值。size为当前table数组的大小,其由于要经常对hash值与size进行取模运算,而取模运算可以优化为(size - 1) & h,速度上得到了提高,但这要求size为2的倍数,因而会将size的值设置为2的倍数。sizemask则为size减一,用于优化一些后续的运算。used属性存储了当前dictht结构中存储的键值对的数量。以下是dictEntry的存储结构:
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;dictEntry中的key保存有dict的键,而val则保存了值,u64保存了无符号64位的整型,s64保存了有符号64位整型,next则表示该结构为单链存储键值对以解决hash冲突的问题。
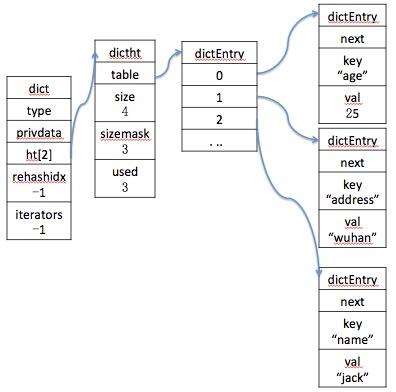
dict中的iterators标识了当前hash表中正在安全运行的迭代器的数量,如果其值不为0,那么是不允许对hash表进行rehash操作的。下图展示了保存有四个节点的hash表的存储结构:
redis采用的hash算法是Murmurhash算法,该算法的特点是即使输入的键是很有规律的也能将其值进行很好的散列,关于该算法具体的描述读者可以查阅相关的文献资料,这里贴出其具体的代码:
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}由于redis是进行大数据量存储的nosql数据库,如果当前存储的数据量非常大,但是hash表的容量不够,此时就要对hash表进行扩容,如果进行一次性扩容并且进行数据迁移的话将导致在一段时间内服务器不能处理其他的请求。为了解决这个问题,redis采用了渐进式rehash的操作。渐进式rehash的思想是将hash表中的数据进行分步rehash,比如有1000w条数据,那么分20次每次rehash 50w条数据,这样就可以将全部的数据rehash完成。具体的,redis的渐进式rehash是每次将dictht中dictEntry数组的一个节点上的链表进行rehash操作,而其是在每次进行添加,删除,查询等操作是进行一次,从而将dictEntry数组的每一个节点都散列完成为止。rehash具体的代码如下:
int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return 0;
// 进行 N 步迁移
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
// T = O(1)
if (d->ht[0].used == 0) {
// 释放 0 号哈希表
zfree(d->ht[0].table);
// 将原来的 1 号哈希表设置为新的 0 号哈希表
d->ht[0] = d->ht[1];
// 重置旧的 1 号哈希表
_dictReset(&d->ht[1]);
// 关闭 rehash 标识
d->rehashidx = -1;
// 返回 0 ,向调用者表示 rehash 已经完成
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// 确保 rehashidx 没有越界
assert(d->ht[0].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// 将链表中的所有节点迁移到新哈希表
// T = O(1)
while(de) {
unsigned int h;
// 保存下个节点的指针
nextde = de->next;
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 插入节点到新哈希表
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
// 更新计数器
d->ht[0].used--;
d->ht[1].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[0].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return 1;
}从上述代码中可以看出,当进行rehash时,首先会将dict.rehashidx置为0,用于开始对dict.ht[0].table[0]的链表进行rehash,当一次rehash完成时,会将dict.rehashidx的值自增一位。渐进式rehash时会将dict.ht[1].table的长度设置为比要扩展的size大的2的倍数,对每个键值对进行rehash时会将其散列到dict.ht[1]中,也就是说当渐进式rehash进行时,dict.ht[0]和dict[1]中都保存有真实的数据。虽然数据保存在了两个dictht对象中,但是在渐进式rehash执行时,用户进行的添加,删除和查找等操作都会对两个表进行查找。当渐进式rehash完成时,服务器会将dict.ht[0]指向dict.ht[1]的值,并且释放dict.ht[1]的对象,并且将dict.rehashidx的值置为-1。
redis服务器会在以下两种情况下进行渐进式rehash操作:
- hash表的负载因子大于等于1,并且服务器没有执行bgsave或bgrewriteaof命令;
- hash表的负载因子大于5;
具体的代码如下:
static int _dictExpandIfNeeded(dict *d)
{
// 渐进式 rehash 已经在进行了,直接返回
if (dictIsRehashing(d)) return DICT_OK;
// 如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
// T = O(1)
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
// 一下两个条件之一为真时,对字典进行扩展
// 1)字典已使用节点数和字典大小之间的比率接近 1:1
// 并且 dict_can_resize 为真
// 2)已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 新哈希表的大小至少是目前已使用节点数的两倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}// 判断是否正在执行bgsave或bgrewriteaof命令
void updateDictResizePolicy(void) {
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
dictEnableResize();
else
dictDisableResize();
}另外还要说明的是,对于hash表的rehash操作,默认是采用分步式rehash操作,即每次rehash dictEntry数组一个索引的链表,如果进行了设置,则可以按照时间段进行rehash,在指定的时间段内每次rehash dictEntry数组的100项链表,直到指定的rehash时长到达,具体的代码如下:
int dictRehashMilliseconds(dict *d, int ms) {
// 记录开始时间
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
// 如果时间已过,跳出
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}以上是redis中hash表的主要功能说明,而诸如添加,删除,修改和查询等操作的具体代码则和一般的hash表区别不大,这里将dict的全部代码贴出,以供读者查阅。
/* Hash Tables Implementation.
*
* This file implements in-memory hash tables with insert/del/replace/find/
* get-random-element operations. Hash tables will auto-resize if needed
* tables of power of two in size are used, collisions are handled by
* chaining. See the source code for more information... :)
*
* 这个文件实现了一个内存哈希表,
* 它支持插入、删除、替换、查找和获取随机元素等操作。
*
* 哈希表会自动在表的大小的二次方之间进行调整。
*
* 键的冲突通过链表来解决。
*
* Copyright (c) 2006-2012, Salvatore Sanfilippo <antirez at gmail dot com>
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of Redis nor the names of its contributors may be used
* to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
#include <stdint.h>
#ifndef __DICT_H
#define __DICT_H
/*
* 字典的操作状态
*/
// 操作成功
#define DICT_OK 0
// 操作失败(或出错)
#define DICT_ERR 1
/* Unused arguments generate annoying warnings... */
// 如果字典的私有数据不使用时
// 用这个宏来避免编译器错误
#define DICT_NOTUSED(V) ((void) V)
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
/*
* 字典类型特定函数
*/
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
/*
* 字典迭代器
*
* 如果 safe 属性的值为 1 ,那么在迭代进行的过程中,
* 程序仍然可以执行 dictAdd 、 dictFind 和其他函数,对字典进行修改。
*
* 如果 safe 不为 1 ,那么程序只会调用 dictNext 对字典进行迭代,
* 而不对字典进行修改。
*/
typedef struct dictIterator {
// 被迭代的字典
dict *d;
// table :正在被迭代的哈希表号码,值可以是 0 或 1 。
// index :迭代器当前所指向的哈希表索引位置。
// safe :标识这个迭代器是否安全
int table, index, safe;
// entry :当前迭代到的节点的指针
// nextEntry :当前迭代节点的下一个节点
// 因为在安全迭代器运作时, entry 所指向的节点可能会被修改,
// 所以需要一个额外的指针来保存下一节点的位置,
// 从而防止指针丢失
dictEntry *entry, *nextEntry;
long long fingerprint; /* unsafe iterator fingerprint for misuse detection */
} dictIterator;
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
/* This is the initial size of every hash table */
/*
* 哈希表的初始大小
*/
#define DICT_HT_INITIAL_SIZE 4
/* ------------------------------- Macros ------------------------------------*/
// 释放给定字典节点的值
#define dictFreeVal(d, entry) \
if ((d)->type->valDestructor) \
(d)->type->valDestructor((d)->privdata, (entry)->v.val)
// 设置给定字典节点的值
#define dictSetVal(d, entry, _val_) do { \
if ((d)->type->valDup) \
entry->v.val = (d)->type->valDup((d)->privdata, _val_); \
else \
entry->v.val = (_val_); \
} while(0)
// 将一个有符号整数设为节点的值
#define dictSetSignedIntegerVal(entry, _val_) \
do { entry->v.s64 = _val_; } while(0)
// 将一个无符号整数设为节点的值
#define dictSetUnsignedIntegerVal(entry, _val_) \
do { entry->v.u64 = _val_; } while(0)
// 释放给定字典节点的键
#define dictFreeKey(d, entry) \
if ((d)->type->keyDestructor) \
(d)->type->keyDestructor((d)->privdata, (entry)->key)
// 设置给定字典节点的键
#define dictSetKey(d, entry, _key_) do { \
if ((d)->type->keyDup) \
entry->key = (d)->type->keyDup((d)->privdata, _key_); \
else \
entry->key = (_key_); \
} while(0)
// 比对两个键
#define dictCompareKeys(d, key1, key2) \
(((d)->type->keyCompare) ? \
(d)->type->keyCompare((d)->privdata, key1, key2) : \
(key1) == (key2))
// 计算给定键的哈希值
#define dictHashKey(d, key) (d)->type->hashFunction(key)
// 返回获取给定节点的键
#define dictGetKey(he) ((he)->key)
// 返回获取给定节点的值
#define dictGetVal(he) ((he)->v.val)
// 返回获取给定节点的有符号整数值
#define dictGetSignedIntegerVal(he) ((he)->v.s64)
// 返回给定节点的无符号整数值
#define dictGetUnsignedIntegerVal(he) ((he)->v.u64)
// 返回给定字典的大小
#define dictSlots(d) ((d)->ht[0].size+(d)->ht[1].size)
// 返回字典的已有节点数量
#define dictSize(d) ((d)->ht[0].used+(d)->ht[1].used)
// 查看字典是否正在 rehash
#define dictIsRehashing(ht) ((ht)->rehashidx != -1)
/* API */
dict *dictCreate(dictType *type, void *privDataPtr);
int dictExpand(dict *d, unsigned long size);
int dictAdd(dict *d, void *key, void *val);
dictEntry *dictAddRaw(dict *d, void *key);
int dictReplace(dict *d, void *key, void *val);
dictEntry *dictReplaceRaw(dict *d, void *key);
int dictDelete(dict *d, const void *key);
int dictDeleteNoFree(dict *d, const void *key);
void dictRelease(dict *d);
dictEntry * dictFind(dict *d, const void *key);
void *dictFetchValue(dict *d, const void *key);
int dictResize(dict *d);
dictIterator *dictGetIterator(dict *d);
dictIterator *dictGetSafeIterator(dict *d);
dictEntry *dictNext(dictIterator *iter);
void dictReleaseIterator(dictIterator *iter);
dictEntry *dictGetRandomKey(dict *d);
int dictGetRandomKeys(dict *d, dictEntry **des, int count);
void dictPrintStats(dict *d);
unsigned int dictGenHashFunction(const void *key, int len);
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len);
void dictEmpty(dict *d, void(callback)(void*));
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);
int dictRehashMilliseconds(dict *d, int ms);
void dictSetHashFunctionSeed(unsigned int initval);
unsigned int dictGetHashFunctionSeed(void);
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, void *privdata);
/* Hash table types */
extern dictType dictTypeHeapStringCopyKey;
extern dictType dictTypeHeapStrings;
extern dictType dictTypeHeapStringCopyKeyValue;
#endif /* __DICT_H */
/* Hash Tables Implementation.
*
* This file implements in memory hash tables with insert/del/replace/find/
* get-random-element operations. Hash tables will auto resize if needed
* tables of power of two in size are used, collisions are handled by
* chaining. See the source code for more information... :)
*
* Copyright (c) 2006-2012, Salvatore Sanfilippo <antirez at gmail dot com>
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* * Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of Redis nor the names of its contributors may be used
* to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
#include "fmacros.h"
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdarg.h>
#include <limits.h>
#include <sys/time.h>
#include <ctype.h>
#include "dict.h"
#include "zmalloc.h"
#include "redisassert.h"
/* Using dictEnableResize() / dictDisableResize() we make possible to
* enable/disable resizing of the hash table as needed. This is very important
* for Redis, as we use copy-on-write and don't want to move too much memory
* around when there is a child performing saving operations.
*
* 通过 dictEnableResize() 和 dictDisableResize() 两个函数,
* 程序可以手动地允许或阻止哈希表进行 rehash ,
* 这在 Redis 使用子进程进行保存操作时,可以有效地利用 copy-on-write 机制。
*
* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio.
*
* 需要注意的是,并非所有 rehash 都会被 dictDisableResize 阻止:
* 如果已使用节点的数量和字典大小之间的比率,
* 大于字典强制 rehash 比率 dict_force_resize_ratio ,
* 那么 rehash 仍然会(强制)进行。
*/
// 指示字典是否启用 rehash 的标识
static int dict_can_resize = 1;
// 强制 rehash 的比率
static unsigned int dict_force_resize_ratio = 5;
/* -------------------------- private prototypes ---------------------------- */
static int _dictExpandIfNeeded(dict *ht);
static unsigned long _dictNextPower(unsigned long size);
static int _dictKeyIndex(dict *ht, const void *key);
static int _dictInit(dict *ht, dictType *type, void *privDataPtr);
/* -------------------------- hash functions -------------------------------- */
/* Thomas Wang's 32 bit Mix Function */
unsigned int dictIntHashFunction(unsigned int key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}
/* Identity hash function for integer keys */
unsigned int dictIdentityHashFunction(unsigned int key)
{
return key;
}
static uint32_t dict_hash_function_seed = 5381;
void dictSetHashFunctionSeed(uint32_t seed) {
dict_hash_function_seed = seed;
}
uint32_t dictGetHashFunctionSeed(void) {
return dict_hash_function_seed;
}
/* MurmurHash2, by Austin Appleby
* Note - This code makes a few assumptions about how your machine behaves -
* 1. We can read a 4-byte value from any address without crashing
* 2. sizeof(int) == 4
*
* And it has a few limitations -
*
* 1. It will not work incrementally.
* 2. It will not produce the same results on little-endian and big-endian
* machines.
*/
unsigned int dictGenHashFunction(const void *key, int len) {
/* 'm' and 'r' are mixing constants generated offline.
They're not really 'magic', they just happen to work well. */
uint32_t seed = dict_hash_function_seed;
const uint32_t m = 0x5bd1e995;
const int r = 24;
/* Initialize the hash to a 'random' value */
uint32_t h = seed ^ len;
/* Mix 4 bytes at a time into the hash */
const unsigned char *data = (const unsigned char *)key;
while(len >= 4) {
uint32_t k = *(uint32_t*)data;
k *= m;
k ^= k >> r;
k *= m;
h *= m;
h ^= k;
data += 4;
len -= 4;
}
/* Handle the last few bytes of the input array */
switch(len) {
case 3: h ^= data[2] << 16;
case 2: h ^= data[1] << 8;
case 1: h ^= data[0]; h *= m;
};
/* Do a few final mixes of the hash to ensure the last few
* bytes are well-incorporated. */
h ^= h >> 13;
h *= m;
h ^= h >> 15;
return (unsigned int)h;
}
/* And a case insensitive hash function (based on djb hash) */
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}
/* ----------------------------- API implementation ------------------------- */
/* Reset a hash table already initialized with ht_init().
* NOTE: This function should only be called by ht_destroy(). */
/*
* 重置(或初始化)给定哈希表的各项属性值
*
* p.s. 上面的英文注释已经过期
*
* T = O(1)
*/
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
/* Create a new hash table */
/*
* 创建一个新的字典
*
* T = O(1)
*/
dict *dictCreate(dictType *type,
void *privDataPtr)
{
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
/* Initialize the hash table */
/*
* 初始化哈希表
*
* T = O(1)
*/
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
// 初始化两个哈希表的各项属性值
// 但暂时还不分配内存给哈希表数组
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
// 设置类型特定函数
d->type = type;
// 设置私有数据
d->privdata = privDataPtr;
// 设置哈希表 rehash 状态
d->rehashidx = -1;
// 设置字典的安全迭代器数量
d->iterators = 0;
return DICT_OK;
}
/* Resize the table to the minimal size that contains all the elements,
* but with the invariant of a USED/BUCKETS ratio near to <= 1 */
/*
* 缩小给定字典
* 让它的已用节点数和字典大小之间的比率接近 1:1
*
* 返回 DICT_ERR 表示字典已经在 rehash ,或者 dict_can_resize 为假。
*
* 成功创建体积更小的 ht[1] ,可以开始 resize 时,返回 DICT_OK。
*
* T = O(N)
*/
int dictResize(dict *d)
{
int minimal;
// 不能在关闭 rehash 或者正在 rehash 的时候调用
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
// 计算让比率接近 1:1 所需要的最少节点数量
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
// 调整字典的大小
// T = O(N)
return dictExpand(d, minimal);
}
/* Expand or create the hash table */
/*
* 创建一个新的哈希表,并根据字典的情况,选择以下其中一个动作来进行:
*
* 1) 如果字典的 0 号哈希表为空,那么将新哈希表设置为 0 号哈希表
* 2) 如果字典的 0 号哈希表非空,那么将新哈希表设置为 1 号哈希表,
* 并打开字典的 rehash 标识,使得程序可以开始对字典进行 rehash
*
* size 参数不够大,或者 rehash 已经在进行时,返回 DICT_ERR 。
*
* 成功创建 0 号哈希表,或者 1 号哈希表时,返回 DICT_OK 。
*
* T = O(N)
*/
int dictExpand(dict *d, unsigned long size)
{
// 新哈希表
dictht n; /* the new hash table */
// 根据 size 参数,计算哈希表的大小
// T = O(1)
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
// 不能在字典正在 rehash 时进行
// size 的值也不能小于 0 号哈希表的当前已使用节点
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
// 为哈希表分配空间,并将所有指针指向 NULL
n.size = realsize;
n.sizemask = realsize-1;
// T = O(N)
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
// 如果 0 号哈希表为空,那么这是一次初始化:
// 程序将新哈希表赋给 0 号哈希表的指针,然后字典就可以开始处理键值对了。
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
// 如果 0 号哈希表非空,那么这是一次 rehash :
// 程序将新哈希表设置为 1 号哈希表,
// 并将字典的 rehash 标识打开,让程序可以开始对字典进行 rehash
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
/* 顺带一提,上面的代码可以重构成以下形式:
if (d->ht[0].table == NULL) {
// 初始化
d->ht[0] = n;
} else {
// rehash
d->ht[1] = n;
d->rehashidx = 0;
}
return DICT_OK;
*/
}
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* 执行 N 步渐进式 rehash 。
*
* 返回 1 表示仍有键需要从 0 号哈希表移动到 1 号哈希表,
* 返回 0 则表示所有键都已经迁移完毕。
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table.
*
* 注意,每步 rehash 都是以一个哈希表索引(桶)作为单位的,
* 一个桶里可能会有多个节点,
* 被 rehash 的桶里的所有节点都会被移动到新哈希表。
*
* T = O(N)
*/
int dictRehash(dict *d, int n) {
// 只可以在 rehash 进行中时执行
if (!dictIsRehashing(d)) return 0;
// 进行 N 步迁移
// T = O(N)
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
// 如果 0 号哈希表为空,那么表示 rehash 执行完毕
// T = O(1)
if (d->ht[0].used == 0) {
// 释放 0 号哈希表
zfree(d->ht[0].table);
// 将原来的 1 号哈希表设置为新的 0 号哈希表
d->ht[0] = d->ht[1];
// 重置旧的 1 号哈希表
_dictReset(&d->ht[1]);
// 关闭 rehash 标识
d->rehashidx = -1;
// 返回 0 ,向调用者表示 rehash 已经完成
return 0;
}
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
// 确保 rehashidx 没有越界
assert(d->ht[0].size > (unsigned)d->rehashidx);
// 略过数组中为空的索引,找到下一个非空索引
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
// 指向该索引的链表表头节点
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
// 将链表中的所有节点迁移到新哈希表
// T = O(1)
while(de) {
unsigned int h;
// 保存下个节点的指针
nextde = de->next;
/* Get the index in the new hash table */
// 计算新哈希表的哈希值,以及节点插入的索引位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
// 插入节点到新哈希表
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
// 更新计数器
d->ht[0].used--;
d->ht[1].used++;
// 继续处理下个节点
de = nextde;
}
// 将刚迁移完的哈希表索引的指针设为空
d->ht[0].table[d->rehashidx] = NULL;
// 更新 rehash 索引
d->rehashidx++;
}
return 1;
}
/*
* 返回以毫秒为单位的 UNIX 时间戳
*
* T = O(1)
*/
long long timeInMilliseconds(void) {
struct timeval tv;
gettimeofday(&tv,NULL);
return (((long long)tv.tv_sec)*1000)+(tv.tv_usec/1000);
}
/* Rehash for an amount of time between ms milliseconds and ms+1 milliseconds */
/*
* 在给定毫秒数内,以 100 步为单位,对字典进行 rehash 。
*
* T = O(N)
*/
int dictRehashMilliseconds(dict *d, int ms) {
// 记录开始时间
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
// 如果时间已过,跳出
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* 在字典不存在安全迭代器的情况下,对字典进行单步 rehash 。
*
* 字典有安全迭代器的情况下不能进行 rehash ,
* 因为两种不同的迭代和修改操作可能会弄乱字典。
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used.
*
* 这个函数被多个通用的查找、更新操作调用,
* 它可以让字典在被使用的同时进行 rehash 。
*
* T = O(1)
*/
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
/* Add an element to the target hash table */
/*
* 尝试将给定键值对添加到字典中
*
* 只有给定键 key 不存在于字典时,添加操作才会成功
*
* 添加成功返回 DICT_OK ,失败返回 DICT_ERR
*
* 最坏 T = O(N) ,平滩 O(1)
*/
int dictAdd(dict *d, void *key, void *val)
{
// 尝试添加键到字典,并返回包含了这个键的新哈希节点
// T = O(N)
dictEntry *entry = dictAddRaw(d,key);
// 键已存在,添加失败
if (!entry) return DICT_ERR;
// 键不存在,设置节点的值
// T = O(1)
dictSetVal(d, entry, val);
// 添加成功
return DICT_OK;
}
/* Low level add. This function adds the entry but instead of setting
* a value returns the dictEntry structure to the user, that will make
* sure to fill the value field as he wishes.
*
* This function is also directly exposed to user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned.
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
/*
* 尝试将键插入到字典中
*
* 如果键已经在字典存在,那么返回 NULL
*
* 如果键不存在,那么程序创建新的哈希节点,
* 将节点和键关联,并插入到字典,然后返回节点本身。
*
* T = O(N)
*/
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
// 如果条件允许的话,进行单步 rehash
// T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
// 计算键在哈希表中的索引值
// 如果值为 -1 ,那么表示键已经存在
// T = O(N)
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
// T = O(1)
/* Allocate the memory and store the new entry */
// 如果字典正在 rehash ,那么将新键添加到 1 号哈希表
// 否则,将新键添加到 0 号哈希表
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
// 为新节点分配空间
entry = zmalloc(sizeof(*entry));
// 将新节点插入到链表表头
entry->next = ht->table[index];
ht->table[index] = entry;
// 更新哈希表已使用节点数量
ht->used++;
/* Set the hash entry fields. */
// 设置新节点的键
// T = O(1)
dictSetKey(d, entry, key);
return entry;
}
/* Add an element, discarding the old if the key already exists.
*
* 将给定的键值对添加到字典中,如果键已经存在,那么删除旧有的键值对。
*
* Return 1 if the key was added from scratch, 0 if there was already an
* element with such key and dictReplace() just performed a value update
* operation.
*
* 如果键值对为全新添加,那么返回 1 。
* 如果键值对是通过对原有的键值对更新得来的,那么返回 0 。
*
* T = O(N)
*/
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
/* Try to add the element. If the key
* does not exists dictAdd will suceed. */
// 尝试直接将键值对添加到字典
// 如果键 key 不存在的话,添加会成功
// T = O(N)
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* It already exists, get the entry */
// 运行到这里,说明键 key 已经存在,那么找出包含这个 key 的节点
// T = O(1)
entry = dictFind(d, key);
/* Set the new value and free the old one. Note that it is important
* to do that in this order, as the value may just be exactly the same
* as the previous one. In this context, think to reference counting,
* you want to increment (set), and then decrement (free), and not the
* reverse. */
// 先保存原有的值的指针
auxentry = *entry;
// 然后设置新的值
// T = O(1)
dictSetVal(d, entry, val);
// 然后释放旧值
// T = O(1)
dictFreeVal(d, &auxentry);
return 0;
}
/* dictReplaceRaw() is simply a version of dictAddRaw() that always
* returns the hash entry of the specified key, even if the key already
* exists and can't be added (in that case the entry of the already
* existing key is returned.)
*
* See dictAddRaw() for more information. */
/*
* dictAddRaw() 根据给定 key 释放存在,执行以下动作:
*
* 1) key 已经存在,返回包含该 key 的字典节点
* 2) key 不存在,那么将 key 添加到字典
*
* 不论发生以上的哪一种情况,
* dictAddRaw() 都总是返回包含给定 key 的字典节点。
*
* T = O(N)
*/
dictEntry *dictReplaceRaw(dict *d, void *key) {
// 使用 key 在字典中查找节点
// T = O(1)
dictEntry *entry = dictFind(d,key);
// 如果节点找到了直接返回节点,否则添加并返回一个新节点
// T = O(N)
return entry ? entry : dictAddRaw(d,key);
}
/* Search and remove an element */
/*
* 查找并删除包含给定键的节点
*
* 参数 nofree 决定是否调用键和值的释放函数
* 0 表示调用,1 表示不调用
*
* 找到并成功删除返回 DICT_OK ,没找到则返回 DICT_ERR
*
* T = O(1)
*/
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
// 字典(的哈希表)为空
if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */
// 进行单步 rehash ,T = O(1)
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算哈希值
h = dictHashKey(d, key);
// 遍历哈希表
// T = O(1)
for (table = 0; table <= 1; table++) {
// 计算索引值
idx = h & d->ht[table].sizemask;
// 指向该索引上的链表
he = d->ht[table].table[idx];
prevHe = NULL;
// 遍历链表上的所有节点
// T = O(1)
while(he) {
if (dictCompareKeys(d, key, he->key)) {
// 超找目标节点
/* Unlink the element from the list */
// 从链表中删除
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
// 释放调用键和值的释放函数?
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
// 释放节点本身
zfree(he);
// 更新已使用节点数量
d->ht[table].used--;
// 返回已找到信号
return DICT_OK;
}
prevHe = he;
he = he->next;
}
// 如果执行到这里,说明在 0 号哈希表中找不到给定键
// 那么根据字典是否正在进行 rehash ,决定要不要查找 1 号哈希表
if (!dictIsRehashing(d)) break;
}
// 没找到
return DICT_ERR; /* not found */
}
/*
* 从字典中删除包含给定键的节点
*
* 并且调用键值的释放函数来删除键值
*
* 找到并成功删除返回 DICT_OK ,没找到则返回 DICT_ERR
* T = O(1)
*/
int dictDelete(dict *ht, const void *key) {
return dictGenericDelete(ht,key,0);
}
/*
* 从字典中删除包含给定键的节点
*
* 但不调用键值的释放函数来删除键值
*
* 找到并成功删除返回 DICT_OK ,没找到则返回 DICT_ERR
* T = O(1)
*/
int dictDeleteNoFree(dict *ht, const void *key) {
return dictGenericDelete(ht,key,1);
}
/* Destroy an entire dictionary */
/*
* 删除哈希表上的所有节点,并重置哈希表的各项属性
*
* T = O(N)
*/
int _dictClear(dict *d, dictht *ht, void(callback)(void *)) {
unsigned long i;
/* Free all the elements */
// 遍历整个哈希表
// T = O(N)
for (i = 0; i < ht->size && ht->used > 0; i++) {
dictEntry *he, *nextHe;
if (callback && (i & 65535) == 0) callback(d->privdata);
// 跳过空索引
if ((he = ht->table[i]) == NULL) continue;
// 遍历整个链表
// T = O(1)
while(he) {
nextHe = he->next;
// 删除键
dictFreeKey(d, he);
// 删除值
dictFreeVal(d, he);
// 释放节点
zfree(he);
// 更新已使用节点计数
ht->used--;
// 处理下个节点
he = nextHe;
}
}
/* Free the table and the allocated cache structure */
// 释放哈希表结构
zfree(ht->table);
/* Re-initialize the table */
// 重置哈希表属性
_dictReset(ht);
return DICT_OK; /* never fails */
}
/* Clear & Release the hash table */
/*
* 删除并释放整个字典
*
* T = O(N)
*/
void dictRelease(dict *d)
{
// 删除并清空两个哈希表
_dictClear(d,&d->ht[0],NULL);
_dictClear(d,&d->ht[1],NULL);
// 释放节点结构
zfree(d);
}
/*
* 返回字典中包含键 key 的节点
*
* 找到返回节点,找不到返回 NULL
*
* T = O(1)
*/
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
// 字典(的哈希表)为空
if (d->ht[0].size == 0) return NULL; /* We don't have a table at all */
// 如果条件允许的话,进行单步 rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// 计算键的哈希值
h = dictHashKey(d, key);
// 在字典的哈希表中查找这个键
// T = O(1)
for (table = 0; table <= 1; table++) {
// 计算索引值
idx = h & d->ht[table].sizemask;
// 遍历给定索引上的链表的所有节点,查找 key
he = d->ht[table].table[idx];
// T = O(1)
while(he) {
if (dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
// 如果程序遍历完 0 号哈希表,仍然没找到指定的键的节点
// 那么程序会检查字典是否在进行 rehash ,
// 然后才决定是直接返回 NULL ,还是继续查找 1 号哈希表
if (!dictIsRehashing(d)) return NULL;
}
// 进行到这里时,说明两个哈希表都没找到
return NULL;
}
/*
* 获取包含给定键的节点的值
*
* 如果节点不为空,返回节点的值
* 否则返回 NULL
*
* T = O(1)
*/
void *dictFetchValue(dict *d, const void *key) {
dictEntry *he;
// T = O(1)
he = dictFind(d,key);
return he ? dictGetVal(he) : NULL;
}
/* A fingerprint is a 64 bit number that represents the state of the dictionary
* at a given time, it's just a few dict properties xored together.
* When an unsafe iterator is initialized, we get the dict fingerprint, and check
* the fingerprint again when the iterator is released.
* If the two fingerprints are different it means that the user of the iterator
* performed forbidden operations against the dictionary while iterating. */
long long dictFingerprint(dict *d) {
long long integers[6], hash = 0;
int j;
integers[0] = (long) d->ht[0].table;
integers[1] = d->ht[0].size;
integers[2] = d->ht[0].used;
integers[3] = (long) d->ht[1].table;
integers[4] = d->ht[1].size;
integers[5] = d->ht[1].used;
/* We hash N integers by summing every successive integer with the integer
* hashing of the previous sum. Basically:
*
* Result = hash(hash(hash(int1)+int2)+int3) ...
*
* This way the same set of integers in a different order will (likely) hash
* to a different number. */
for (j = 0; j < 6; j++) {
hash += integers[j];
/* For the hashing step we use Tomas Wang's 64 bit integer hash. */
hash = (~hash) + (hash << 21); // hash = (hash << 21) - hash - 1;
hash = hash ^ (hash >> 24);
hash = (hash + (hash << 3)) + (hash << 8); // hash * 265
hash = hash ^ (hash >> 14);
hash = (hash + (hash << 2)) + (hash << 4); // hash * 21
hash = hash ^ (hash >> 28);
hash = hash + (hash << 31);
}
return hash;
}
/*
* 创建并返回给定字典的不安全迭代器
*
* T = O(1)
*/
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
/*
* 创建并返回给定节点的安全迭代器
*
* T = O(1)
*/
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
// 设置安全迭代器标识
i->safe = 1;
return i;
}
/*
* 返回迭代器指向的当前节点
*
* 字典迭代完毕时,返回 NULL
*
* T = O(1)
*/
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
// 进入这个循环有两种可能:
// 1) 这是迭代器第一次运行
// 2) 当前索引链表中的节点已经迭代完(NULL 为链表的表尾)
if (iter->entry == NULL) {
// 指向被迭代的哈希表
dictht *ht = &iter->d->ht[iter->table];
// 初次迭代时执行
if (iter->index == -1 && iter->table == 0) {
// 如果是安全迭代器,那么更新安全迭代器计数器
if (iter->safe)
iter->d->iterators++;
// 如果是不安全迭代器,那么计算指纹
else
iter->fingerprint = dictFingerprint(iter->d);
}
// 更新索引
iter->index++;
// 如果迭代器的当前索引大于当前被迭代的哈希表的大小
// 那么说明这个哈希表已经迭代完毕
if (iter->index >= (signed) ht->size) {
// 如果正在 rehash 的话,那么说明 1 号哈希表也正在使用中
// 那么继续对 1 号哈希表进行迭代
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
// 如果没有 rehash ,那么说明迭代已经完成
} else {
break;
}
}
// 如果进行到这里,说明这个哈希表并未迭代完
// 更新节点指针,指向下个索引链表的表头节点
iter->entry = ht->table[iter->index];
} else {
// 执行到这里,说明程序正在迭代某个链表
// 将节点指针指向链表的下个节点
iter->entry = iter->nextEntry;
}
// 如果当前节点不为空,那么也记录下该节点的下个节点
// 因为安全迭代器有可能会将迭代器返回的当前节点删除
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
// 迭代完毕
return NULL;
}
/*
* 释放给定字典迭代器
*
* T = O(1)
*/
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
// 释放安全迭代器时,安全迭代器计数器减一
if (iter->safe)
iter->d->iterators--;
// 释放不安全迭代器时,验证指纹是否有变化
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}
/* Return a random entry from the hash table. Useful to
* implement randomized algorithms */
/*
* 随机返回字典中任意一个节点。
*
* 可用于实现随机化算法。
*
* 如果字典为空,返回 NULL 。
*
* T = O(N)
*/
dictEntry *dictGetRandomKey(dict *d)
{
dictEntry *he, *orighe;
unsigned int h;
int listlen, listele;
// 字典为空
if (dictSize(d) == 0) return NULL;
// 进行单步 rehash
if (dictIsRehashing(d)) _dictRehashStep(d);
// 如果正在 rehash ,那么将 1 号哈希表也作为随机查找的目标
if (dictIsRehashing(d)) {
// T = O(N)
do {
h = random() % (d->ht[0].size+d->ht[1].size);
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
// 否则,只从 0 号哈希表中查找节点
} else {
// T = O(N)
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
/* Now we found a non empty bucket, but it is a linked
* list and we need to get a random element from the list.
* The only sane way to do so is counting the elements and
* select a random index. */
// 目前 he 已经指向一个非空的节点链表
// 程序将从这个链表随机返回一个节点
listlen = 0;
orighe = he;
// 计算节点数量, T = O(1)
while(he) {
he = he->next;
listlen++;
}
// 取模,得出随机节点的索引
listele = random() % listlen;
he = orighe;
// 按索引查找节点
// T = O(1)
while(listele--) he = he->next;
// 返回随机节点
return he;
}
/* This is a version of dictGetRandomKey() that is modified in order to
* return multiple entries by jumping at a random place of the hash table
* and scanning linearly for entries.
*
* Returned pointers to hash table entries are stored into 'des' that
* points to an array of dictEntry pointers. The array must have room for
* at least 'count' elements, that is the argument we pass to the function
* to tell how many random elements we need.
*
* The function returns the number of items stored into 'des', that may
* be less than 'count' if the hash table has less than 'count' elements
* inside.
*
* Note that this function is not suitable when you need a good distribution
* of the returned items, but only when you need to "sample" a given number
* of continuous elements to run some kind of algorithm or to produce
* statistics. However the function is much faster than dictGetRandomKey()
* at producing N elements, and the elements are guaranteed to be non
* repeating. */
int dictGetRandomKeys(dict *d, dictEntry **des, int count) {
int j; /* internal hash table id, 0 or 1. */
int stored = 0;
if (dictSize(d) < count) count = dictSize(d);
while(stored < count) {
for (j = 0; j < 2; j++) {
/* Pick a random point inside the hash table 0 or 1. */
unsigned int i = random() & d->ht[j].sizemask;
int size = d->ht[j].size;
/* Make sure to visit every bucket by iterating 'size' times. */
while(size--) {
dictEntry *he = d->ht[j].table[i];
while (he) {
/* Collect all the elements of the buckets found non
* empty while iterating. */
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
i = (i+1) & d->ht[j].sizemask;
}
/* If there is only one table and we iterated it all, we should
* already have 'count' elements. Assert this condition. */
assert(dictIsRehashing(d) != 0);
}
}
return stored; /* Never reached. */
}
/* Function to reverse bits. Algorithm from:
* http://graphics.stanford.edu/~seander/bithacks.html#ReverseParallel */
static unsigned long rev(unsigned long v) {
unsigned long s = 8 * sizeof(v); // bit size; must be power of 2
unsigned long mask = ~0;
while ((s >>= 1) > 0) {
mask ^= (mask << s);
v = ((v >> s) & mask) | ((v << s) & ~mask);
}
return v;
}
/* dictScan() is used to iterate over the elements of a dictionary.
*
* dictScan() 函数用于迭代给定字典中的元素。
*
* Iterating works in the following way:
*
* 迭代按以下方式执行:
*
* 1) Initially you call the function using a cursor (v) value of 0.
* 一开始,你使用 0 作为游标来调用函数。
* 2) The function performs one step of the iteration, and returns the
* new cursor value that you must use in the next call.
* 函数执行一步迭代操作,
* 并返回一个下次迭代时使用的新游标。
* 3) When the returned cursor is 0, the iteration is complete.
* 当函数返回的游标为 0 时,迭代完成。
*
* The function guarantees that all the elements that are present in the
* dictionary from the start to the end of the iteration are returned.
* However it is possible that some element is returned multiple time.
*
* 函数保证,在迭代从开始到结束期间,一直存在于字典的元素肯定会被迭代到,
* 但一个元素可能会被返回多次。
*
* For every element returned, the callback 'fn' passed as argument is
* called, with 'privdata' as first argument and the dictionar entry
* 'de' as second argument.
*
* 每当一个元素被返回时,回调函数 fn 就会被执行,
* fn 函数的第一个参数是 privdata ,而第二个参数则是字典节点 de 。
*
* HOW IT WORKS.
* 工作原理
*
* The algorithm used in the iteration was designed by Pieter Noordhuis.
* The main idea is to increment a cursor starting from the higher order
* bits, that is, instead of incrementing the cursor normally, the bits
* of the cursor are reversed, then the cursor is incremented, and finally
* the bits are reversed again.
*
* 迭代所使用的算法是由 Pieter Noordhuis 设计的,
* 算法的主要思路是在二进制高位上对游标进行加法计算
* 也即是说,不是按正常的办法来对游标进行加法计算,
* 而是首先将游标的二进制位翻转(reverse)过来,
* 然后对翻转后的值进行加法计算,
* 最后再次对加法计算之后的结果进行翻转。
*
* This strategy is needed because the hash table may be resized from one
* call to the other call of the same iteration.
*
* 这一策略是必要的,因为在一次完整的迭代过程中,
* 哈希表的大小有可能在两次迭代之间发生改变。
*
* dict.c hash tables are always power of two in size, and they
* use chaining, so the position of an element in a given table is given
* always by computing the bitwise AND between Hash(key) and SIZE-1
* (where SIZE-1 is always the mask that is equivalent to taking the rest
* of the division between the Hash of the key and SIZE).
*
* 哈希表的大小总是 2 的某个次方,并且哈希表使用链表来解决冲突,
* 因此一个给定元素在一个给定表的位置总可以通过 Hash(key) & SIZE-1
* 公式来计算得出,
* 其中 SIZE-1 是哈希表的最大索引值,
* 这个最大索引值就是哈希表的 mask (掩码)。
*
* For example if the current hash table size is 16, the mask is
* (in binary) 1111. The position of a key in the hash table will be always
* the last four bits of the hash output, and so forth.
*
* 举个例子,如果当前哈希表的大小为 16 ,
* 那么它的掩码就是二进制值 1111 ,
* 这个哈希表的所有位置都可以使用哈希值的最后四个二进制位来记录。
*
* WHAT HAPPENS IF THE TABLE CHANGES IN SIZE?
* 如果哈希表的大小改变了怎么办?
*
* If the hash table grows, elements can go anyway in one multiple of
* the old bucket: for example let's say that we already iterated with
* a 4 bit cursor 1100, since the mask is 1111 (hash table size = 16).
*
* 当对哈希表进行扩展时,元素可能会从一个槽移动到另一个槽,
* 举个例子,假设我们刚好迭代至 4 位游标 1100 ,
* 而哈希表的 mask 为 1111 (哈希表的大小为 16 )。
*
* If the hash table will be resized to 64 elements, and the new mask will
* be 111111, the new buckets that you obtain substituting in ??1100
* either 0 or 1, can be targeted only by keys that we already visited
* when scanning the bucket 1100 in the smaller hash table.
*
* 如果这时哈希表将大小改为 64 ,那么哈希表的 mask 将变为 111111 ,
*
* By iterating the higher bits first, because of the inverted counter, the
* cursor does not need to restart if the table size gets bigger, and will
* just continue iterating with cursors that don't have '1100' at the end,
* nor any other combination of final 4 bits already explored.
*
* Similarly when the table size shrinks over time, for example going from
* 16 to 8, If a combination of the lower three bits (the mask for size 8
* is 111) was already completely explored, it will not be visited again
* as we are sure that, we tried for example, both 0111 and 1111 (all the
* variations of the higher bit) so we don't need to test it again.
*
* WAIT... YOU HAVE *TWO* TABLES DURING REHASHING!
* 等等。。。在 rehash 的时候可是会出现两个哈希表的阿!
*
* Yes, this is true, but we always iterate the smaller one of the tables,
* testing also all the expansions of the current cursor into the larger
* table. So for example if the current cursor is 101 and we also have a
* larger table of size 16, we also test (0)101 and (1)101 inside the larger
* table. This reduces the problem back to having only one table, where
* the larger one, if exists, is just an expansion of the smaller one.
*
* LIMITATIONS
* 限制
*
* This iterator is completely stateless, and this is a huge advantage,
* including no additional memory used.
* 这个迭代器是完全无状态的,这是一个巨大的优势,
* 因为迭代可以在不使用任何额外内存的情况下进行。
*
* The disadvantages resulting from this design are:
* 这个设计的缺陷在于:
*
* 1) It is possible that we return duplicated elements. However this is usually
* easy to deal with in the application level.
* 函数可能会返回重复的元素,不过这个问题可以很容易在应用层解决。
* 2) The iterator must return multiple elements per call, as it needs to always
* return all the keys chained in a given bucket, and all the expansions, so
* we are sure we don't miss keys moving.
* 为了不错过任何元素,
* 迭代器需要返回给定桶上的所有键,
* 以及因为扩展哈希表而产生出来的新表,
* 所以迭代器必须在一次迭代中返回多个元素。
* 3) The reverse cursor is somewhat hard to understand at first, but this
* comment is supposed to help.
* 对游标进行翻转(reverse)的原因初看上去比较难以理解,
* 不过阅读这份注释应该会有所帮助。
*/
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de;
unsigned long m0, m1;
// 跳过空字典
if (dictSize(d) == 0) return 0;
// 迭代只有一个哈希表的字典
if (!dictIsRehashing(d)) {
// 指向哈希表
t0 = &(d->ht[0]);
// 记录 mask
m0 = t0->sizemask;
/* Emit entries at cursor */
// 指向哈希桶
de = t0->table[v & m0];
// 遍历桶中的所有节点
while (de) {
fn(privdata, de);
de = de->next;
}
// 迭代有两个哈希表的字典
} else {
// 指向两个哈希表
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
// 确保 t0 比 t1 要小
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
// 记录掩码
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
// 指向桶,并迭代桶中的所有节点
de = t0->table[v & m0];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
// Iterate over indices in larger table // 迭代大表中的桶
// that are the expansion of the index pointed to // 这些桶被索引的 expansion 所指向
// by the cursor in the smaller table //
do {
/* Emit entries at cursor */
// 指向桶,并迭代桶中的所有节点
de = t1->table[v & m1];
while (de) {
fn(privdata, de);
de = de->next;
}
/* Increment bits not covered by the smaller mask */
v = (((v | m0) + 1) & ~m0) | (v & m0);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits of the smaller table */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
return v;
}
/* ------------------------- private functions ------------------------------ */
/* Expand the hash table if needed */
/*
* 根据需要,初始化字典(的哈希表),或者对字典(的现有哈希表)进行扩展
*
* T = O(N)
*/
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
// 渐进式 rehash 已经在进行了,直接返回
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
// 如果字典(的 0 号哈希表)为空,那么创建并返回初始化大小的 0 号哈希表
// T = O(1)
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
// 一下两个条件之一为真时,对字典进行扩展
// 1)字典已使用节点数和字典大小之间的比率接近 1:1
// 并且 dict_can_resize 为真
// 2)已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 新哈希表的大小至少是目前已使用节点数的两倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
/* Our hash table capability is a power of two */
/*
* 计算第一个大于等于 size 的 2 的 N 次方,用作哈希表的值
*
* T = O(1)
*/
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned.
*
* 返回可以将 key 插入到哈希表的索引位置
* 如果 key 已经存在于哈希表,那么返回 -1
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table.
*
* 注意,如果字典正在进行 rehash ,那么总是返回 1 号哈希表的索引。
* 因为在字典进行 rehash 时,新节点总是插入到 1 号哈希表。
*
* T = O(N)
*/
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
/* Expand the hash table if needed */
// 单步 rehash
// T = O(N)
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
/* Compute the key hash value */
// 计算 key 的哈希值
h = dictHashKey(d, key);
// T = O(1)
for (table = 0; table <= 1; table++) {
// 计算索引值
idx = h & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
// 查找 key 是否存在
// T = O(1)
he = d->ht[table].table[idx];
while(he) {
if (dictCompareKeys(d, key, he->key))
return -1;
he = he->next;
}
// 如果运行到这里时,说明 0 号哈希表中所有节点都不包含 key
// 如果这时 rehahs 正在进行,那么继续对 1 号哈希表进行 rehash
if (!dictIsRehashing(d)) break;
}
// 返回索引值
return idx;
}
/*
* 清空字典上的所有哈希表节点,并重置字典属性
*
* T = O(N)
*/
void dictEmpty(dict *d, void(callback)(void*)) {
// 删除两个哈希表上的所有节点
// T = O(N)
_dictClear(d,&d->ht[0],callback);
_dictClear(d,&d->ht[1],callback);
// 重置属性
d->rehashidx = -1;
d->iterators = 0;
}
/*
* 开启自动 rehash
*
* T = O(1)
*/
void dictEnableResize(void) {
dict_can_resize = 1;
}
/*
* 关闭自动 rehash
*
* T = O(1)
*/
void dictDisableResize(void) {
dict_can_resize = 0;
}
#if 0
/* The following is code that we don't use for Redis currently, but that is part
of the library. */
/* ----------------------- Debugging ------------------------*/
#define DICT_STATS_VECTLEN 50
static void _dictPrintStatsHt(dictht *ht) {
unsigned long i, slots = 0, chainlen, maxchainlen = 0;
unsigned long totchainlen = 0;
unsigned long clvector[DICT_STATS_VECTLEN];
if (ht->used == 0) {
printf("No stats available for empty dictionaries\n");
return;
}
for (i = 0; i < DICT_STATS_VECTLEN; i++) clvector[i] = 0;
for (i = 0; i < ht->size; i++) {
dictEntry *he;
if (ht->table[i] == NULL) {
clvector[0]++;
continue;
}
slots++;
/* For each hash entry on this slot... */
chainlen = 0;
he = ht->table[i];
while(he) {
chainlen++;
he = he->next;
}
clvector[(chainlen < DICT_STATS_VECTLEN) ? chainlen : (DICT_STATS_VECTLEN-1)]++;
if (chainlen > maxchainlen) maxchainlen = chainlen;
totchainlen += chainlen;
}
printf("Hash table stats:\n");
printf(" table size: %ld\n", ht->size);
printf(" number of elements: %ld\n", ht->used);
printf(" different slots: %ld\n", slots);
printf(" max chain length: %ld\n", maxchainlen);
printf(" avg chain length (counted): %.02f\n", (float)totchainlen/slots);
printf(" avg chain length (computed): %.02f\n", (float)ht->used/slots);
printf(" Chain length distribution:\n");
for (i = 0; i < DICT_STATS_VECTLEN-1; i++) {
if (clvector[i] == 0) continue;
printf(" %s%ld: %ld (%.02f%%)\n",(i == DICT_STATS_VECTLEN-1)?">= ":"", i, clvector[i], ((float)clvector[i]/ht->size)*100);
}
}
void dictPrintStats(dict *d) {
_dictPrintStatsHt(&d->ht[0]);
if (dictIsRehashing(d)) {
printf("-- Rehashing into ht[1]:\n");
_dictPrintStatsHt(&d->ht[1]);
}
}
/* ----------------------- StringCopy Hash Table Type ------------------------*/
static unsigned int _dictStringCopyHTHashFunction(const void *key)
{
return dictGenHashFunction(key, strlen(key));
}
static void *_dictStringDup(void *privdata, const void *key)
{
int len = strlen(key);
char *copy = zmalloc(len+1);
DICT_NOTUSED(privdata);
memcpy(copy, key, len);
copy[len] = '\0';
return copy;
}
static int _dictStringCopyHTKeyCompare(void *privdata, const void *key1,
const void *key2)
{
DICT_NOTUSED(privdata);
return strcmp(key1, key2) == 0;
}
static void _dictStringDestructor(void *privdata, void *key)
{
DICT_NOTUSED(privdata);
zfree(key);
}
dictType dictTypeHeapStringCopyKey = {
_dictStringCopyHTHashFunction, /* hash function */
_dictStringDup, /* key dup */
NULL, /* val dup */
_dictStringCopyHTKeyCompare, /* key compare */
_dictStringDestructor, /* key destructor */
NULL /* val destructor */
};
/* This is like StringCopy but does not auto-duplicate the key.
* It's used for intepreter's shared strings. */
dictType dictTypeHeapStrings = {
_dictStringCopyHTHashFunction, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
_dictStringCopyHTKeyCompare, /* key compare */
_dictStringDestructor, /* key destructor */
NULL /* val destructor */
};
/* This is like StringCopy but also automatically handle dynamic
* allocated C strings as values. */
dictType dictTypeHeapStringCopyKeyValue = {
_dictStringCopyHTHashFunction, /* hash function */
_dictStringDup, /* key dup */
_dictStringDup, /* val dup */
_dictStringCopyHTKeyCompare, /* key compare */
_dictStringDestructor, /* key destructor */
_dictStringDestructor, /* val destructor */
};
#endif
读者朋友如果觉得本文还不错,可以点击下面的广告链接,这可以为作者带来一定的收入,从而激励作者创作更好的文章,非常感谢!















 406
406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









