







 这篇博客详述了机器学习的基础流程,包括数据清洗、特征工程和预处理。重点介绍了有监督学习的分类与回归算法,如线性回归、逻辑回归、KNN、朴素贝叶斯、SVM和决策树等。此外,还涵盖了XGBoost和无监督学习中的K-means聚类。这些内容适合机器学习初学者,帮助理解常见算法的工作原理和应用场景。
这篇博客详述了机器学习的基础流程,包括数据清洗、特征工程和预处理。重点介绍了有监督学习的分类与回归算法,如线性回归、逻辑回归、KNN、朴素贝叶斯、SVM和决策树等。此外,还涵盖了XGBoost和无监督学习中的K-means聚类。这些内容适合机器学习初学者,帮助理解常见算法的工作原理和应用场景。
说明:贪心科技的机器学习视频,推荐给希望入门机器学习但又找不到合适资源的小伙伴,UP主将常见的机器学习算法分析的通俗易懂,看完后收获很多,下面是我学习的部分笔记,供以后回顾!


机器学习流程

- 数据清洗:丢弃异常值
- 特征工程:将输入的数据比如文本,语音,图片表示成张量的形式。
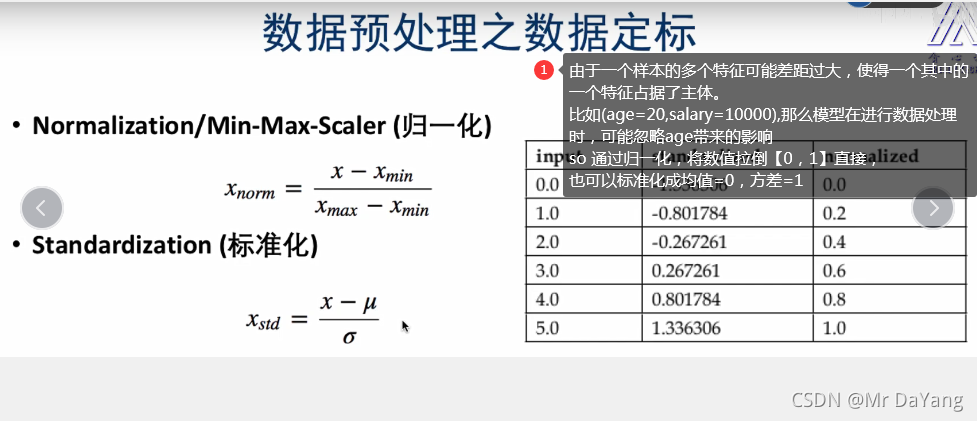
- 数据预处理:特征提取(提取hog直方图,NLP中提取文字n-gram),缺失值处理(均值,使用众数,丢弃),数据标定(归一化,标准化)
- 看模型是否为线性模型,就看它的决策边界是不是线性的。








有监督算法(回归,分类)
1.分类(classification)与回归(regression)的区别与关系
参考

分类通常是建立在回归之上:例如判断一幅图片上的动物是一只猫还是一只狗,还是猪,需要先计算一个连续的概率值,然后分类的最后一层通常要使用softmax函数进行判断其所属类别。
2.线性回归
就是找到一条直线,来拟合上面所有的点(应用:比如进行房价预测,横坐标是面积,纵坐标是价钱)
假设线性回归是个黑盒子,那按照程序员的思维来说,这个黑盒子就是个函数,然后呢,我们只要往这个函数传一些参数作为输入,就能得到一个结果作为输出。那回归是什么意思呢?其实说白了,就是这个黑盒子输出的结果是个连续的值。如果输出不是个连续值而是个离散值那就叫分类。
参考

3.逻辑回归(是一个分类算法,可处理二元分类及多元分类)
视频
前面讲到模型输出是连续值就是回归,输出是离散值就是分类!
逻辑回归虽然叫回归,但通常干的是分类的活,与回归最大的联系就是:在线性回归上套了一个逻辑函数,就得到逻辑回归,输出的是一个连续的值wx+b,用这个连续的值+sigmoid进行概率计算,然后再分类。
逻辑回归的目标函数就是极大化似然函数
3.1逻辑回归解决二分类问题
分类问题:就是一个条件概率问题,主要解决:1.如何定义这个条件概率(使用什么函数f)2.根据条件概率如何分类


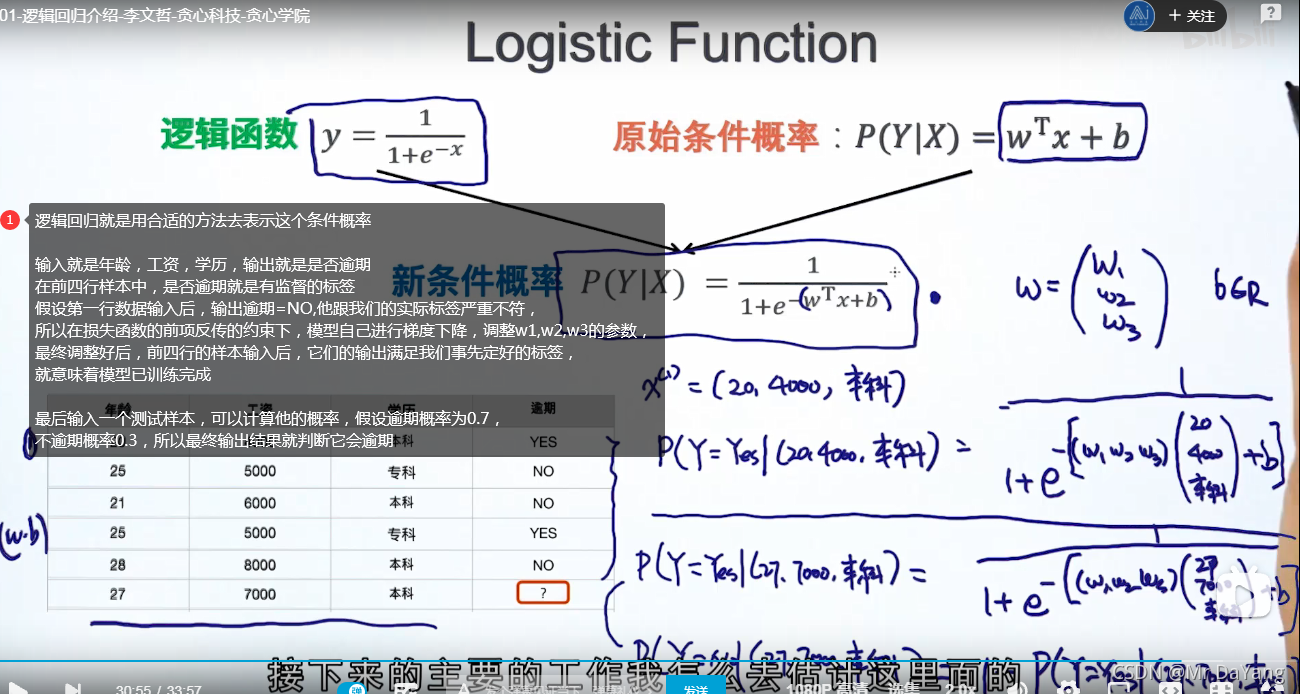
逻辑回归的决策边界是线性的,所以逻辑回归是线性的



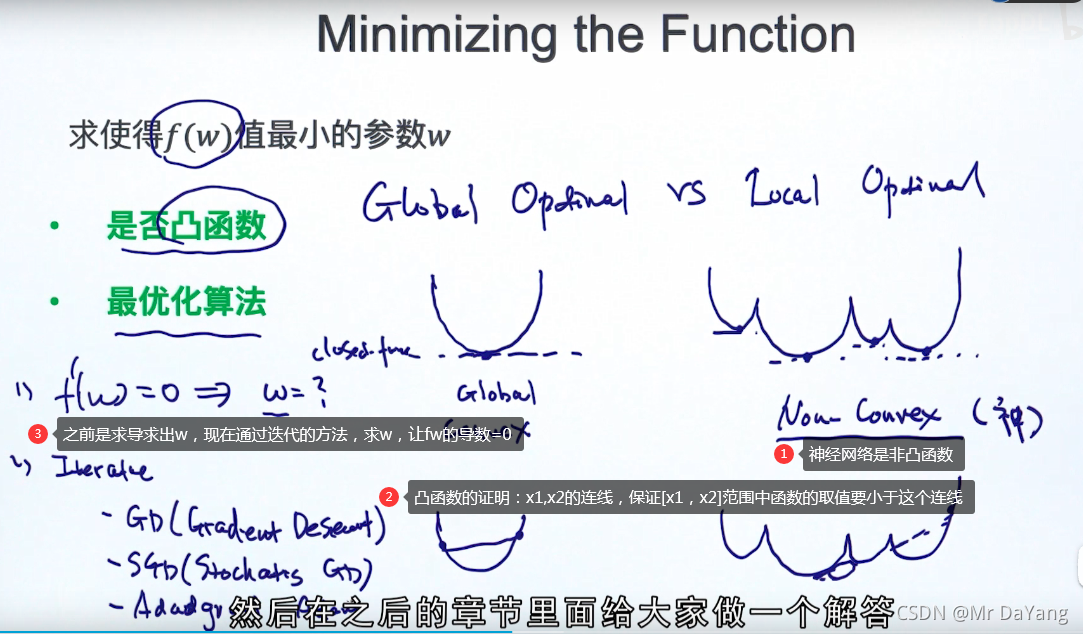
在进行梯度下降时,GD考虑的是全部样本,SGD考虑的是单个样本,MBGD就是折中的每次迭代考虑一小批。
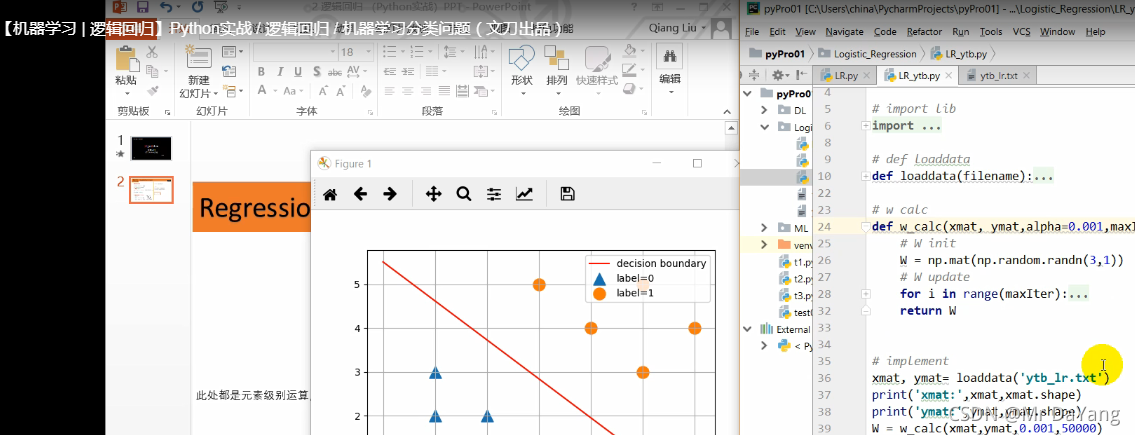
3.2 逻辑回归python实现并可视化
4.K近邻算法(k-nearest neighbor classification算法)
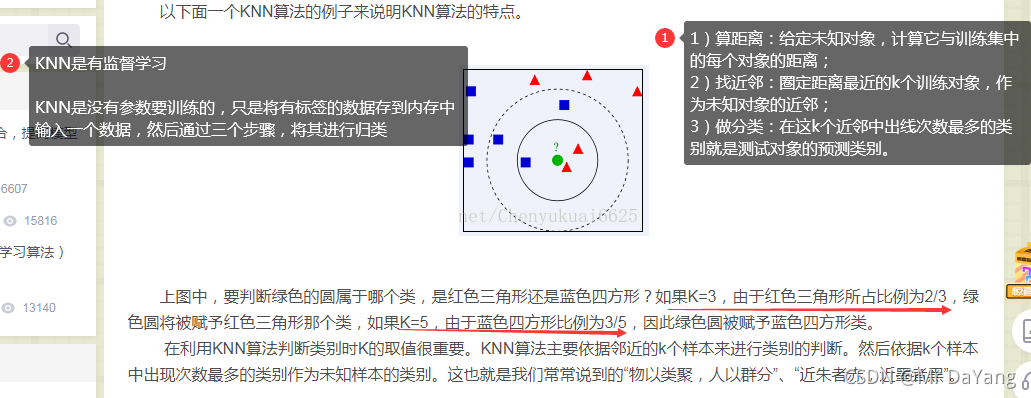

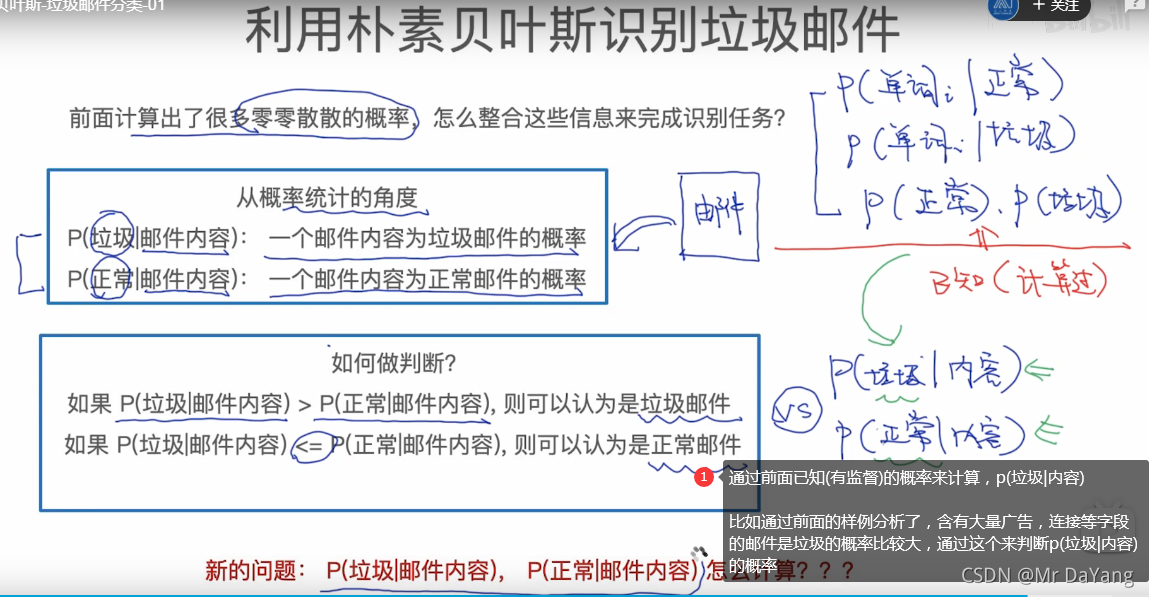
5.朴素贝叶斯分类器(Naive Bayes Classifier)-判垃圾邮件
朴素贝叶斯分类(NBC)是以贝叶斯定理为基础并且假设特征条件之间相互独立的方法,先通过已给定的训练集,以特征词之间独立作为前提假设,学习从输入到输出的联合概率分布,再基于学习到的模型,输入x求出使得后验概率最大的输出y。
通过先验概率和条件概率,求得未知分类的后验概率,利用后验概率进行分类



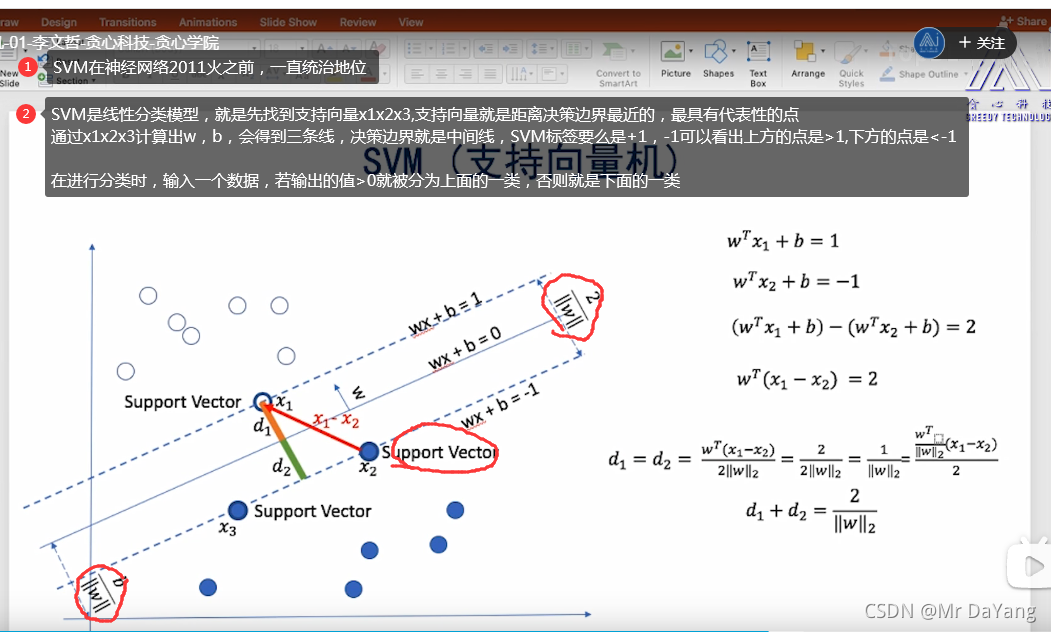
6.SVM(支持向量机-线性分类器)
- 逻辑回归也线性分类器,它考虑的是每一个数据,SVM线性分类器只考虑支持向量,只考虑边界上具有代表性的点(最好是三个点确定唯一性)。
- 若数据的位置发生变化,则逻辑回归的w,b也要发生变化,但SVM不会变化,也就是说SVM对奇异值不敏感。




7.决策树(处理非线情况)
将不同的条件当成节点构建一棵树,然后进行分类,因为节点有多个,那么如何构建一棵树才是最合理的呢:即保证信息增益最大化
信息增益=信息熵-条件熵。





7.1使用决策树判断是否打golf





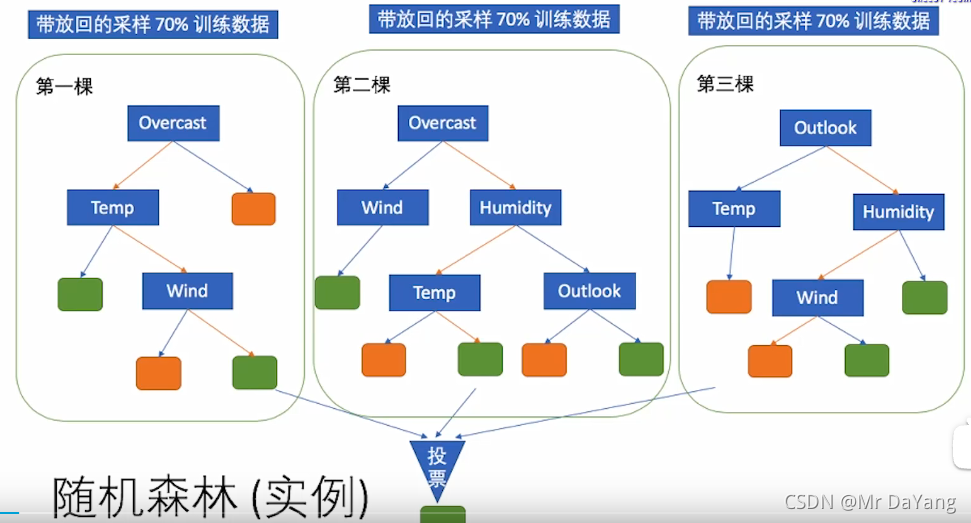
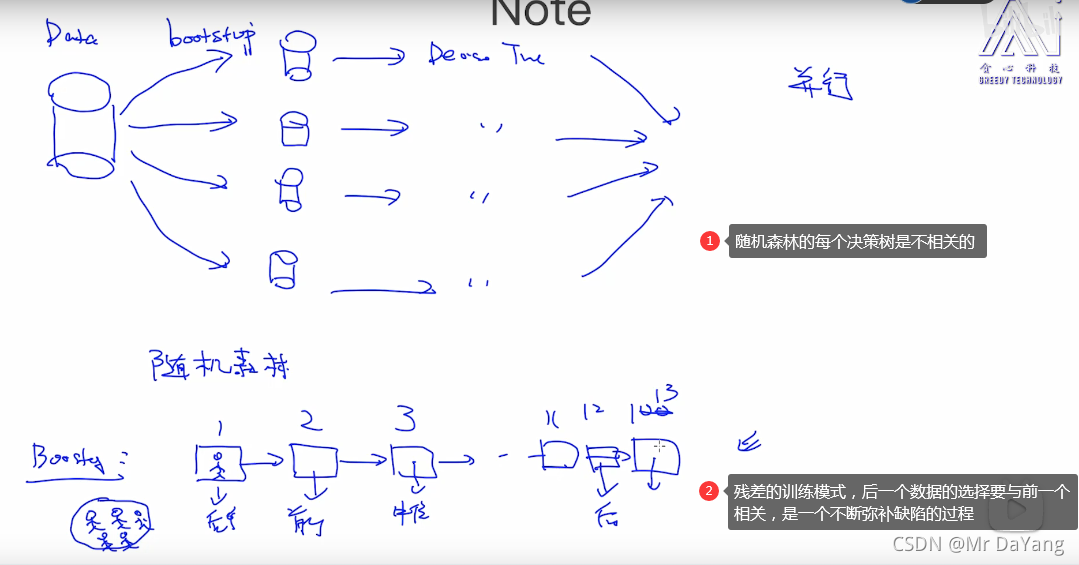
8.随机森林
- 随机森林同时训练多个决策树,预测的时候,综合考虑多个结果做预测.例如取多个结果的均值(回归情况),或者众数(分类情况)
- 随机森林的随机体现在每次生成决策树时,只使用一部分训练数据集(有放回的)比如70%,再者随机性体现在选择分叉特征时,也只使用一部分特征,比如一共4个特征,那么生成决策树时只使用3个特征。
- 减小过拟合,减小预测结果因为训练数据小的变化带来的影响

9.XGBoost
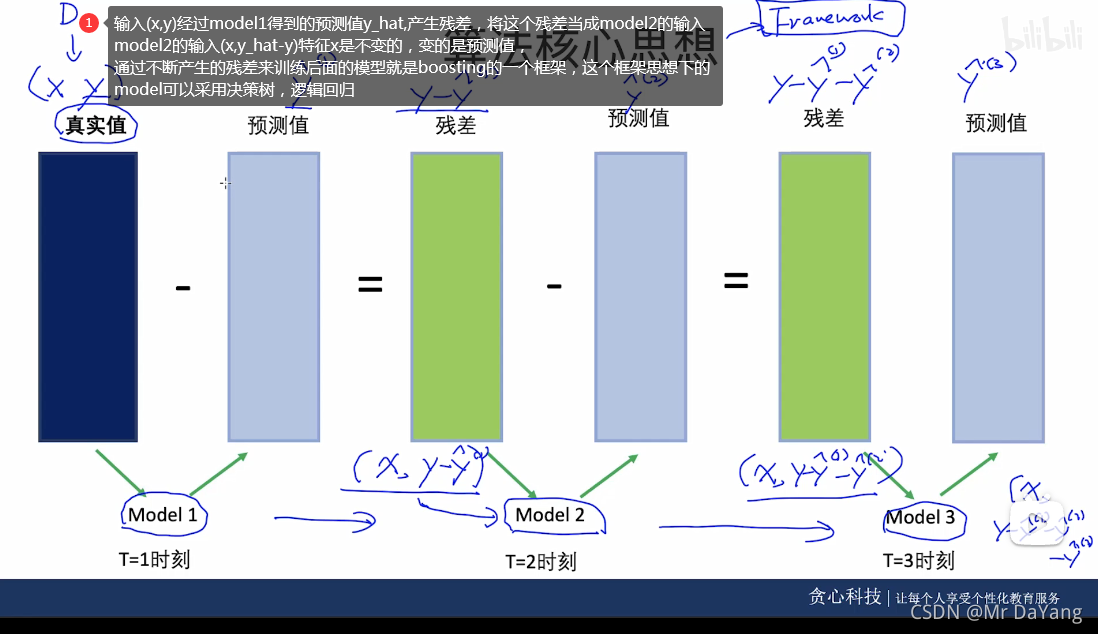
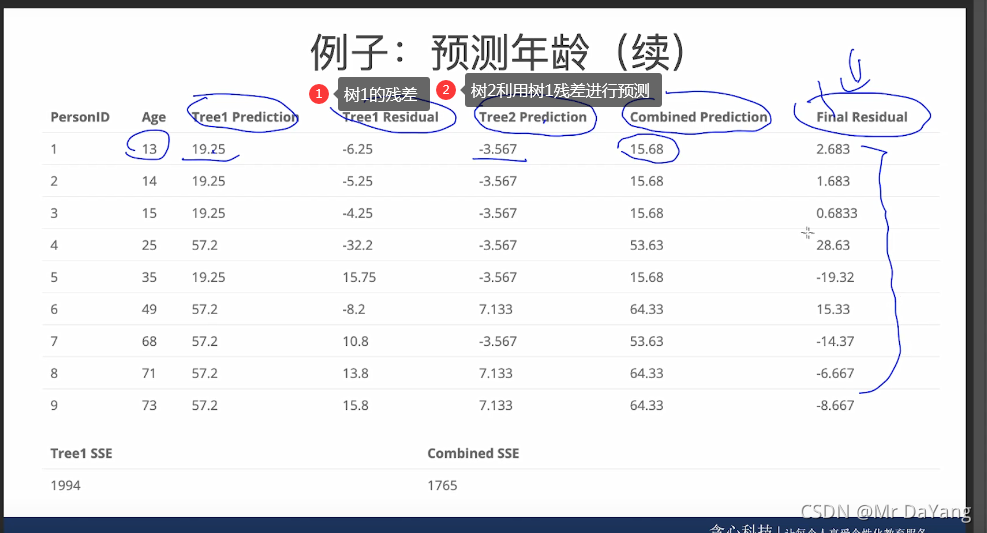
XGBoost(eXtreme Gradient Boosting)全名叫极端梯度提升,XGBoost是集成学习方法的王牌,在Kaggle数据挖掘比赛中,大部分获胜者用了XGBoost,XGBoost在绝大多数的回归和分类问题上表现的十分顶尖,主要是一种残差思想。
参考

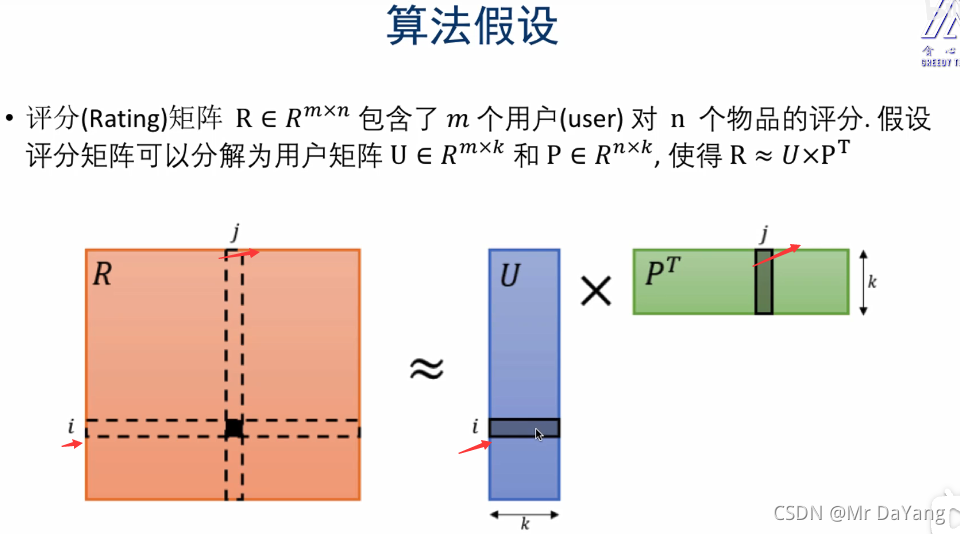
10.矩阵分解–推荐系统






无监督学习(聚类)
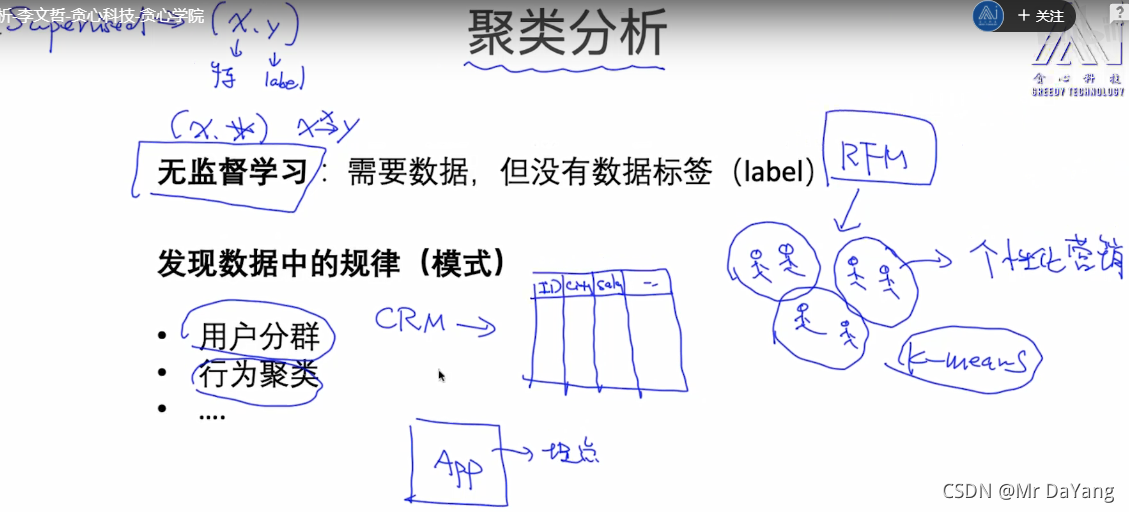


1.K-means聚类
K-means聚类包含两部分:
- k-means就是将样本分为 k类,所以先随机选k个点,作为初始化的中心点,每个点就是一个group
- 接下来就是一个迭代的过程,a.计算每个点到中心点的距离,并根据最近原则将所有点进行分组
b.针对每一组的点计算它们的均值得到新的中心点。 - 最后就是迭代的过程,根据新的中心点进行聚类,再获得新的中心点,直到中心点不发生变化,聚类结束



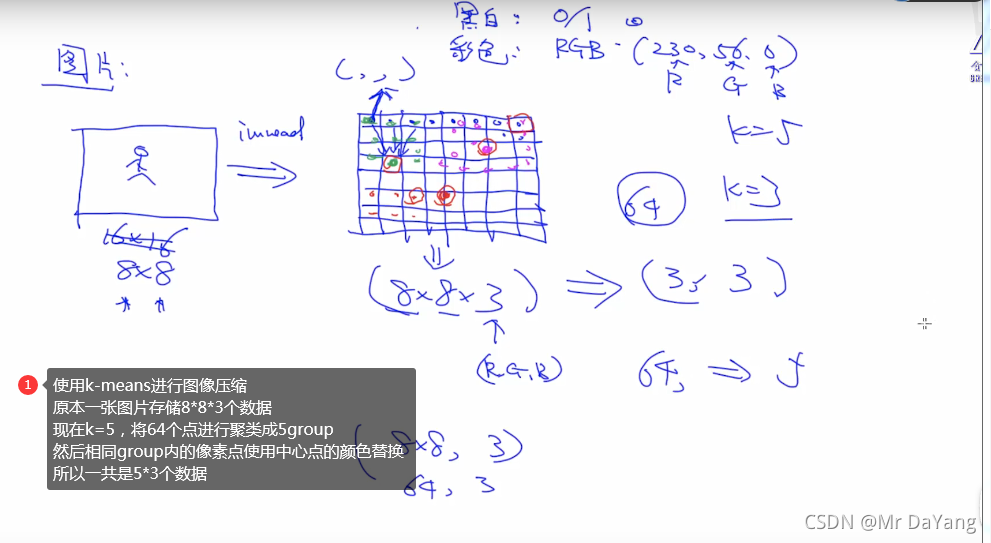
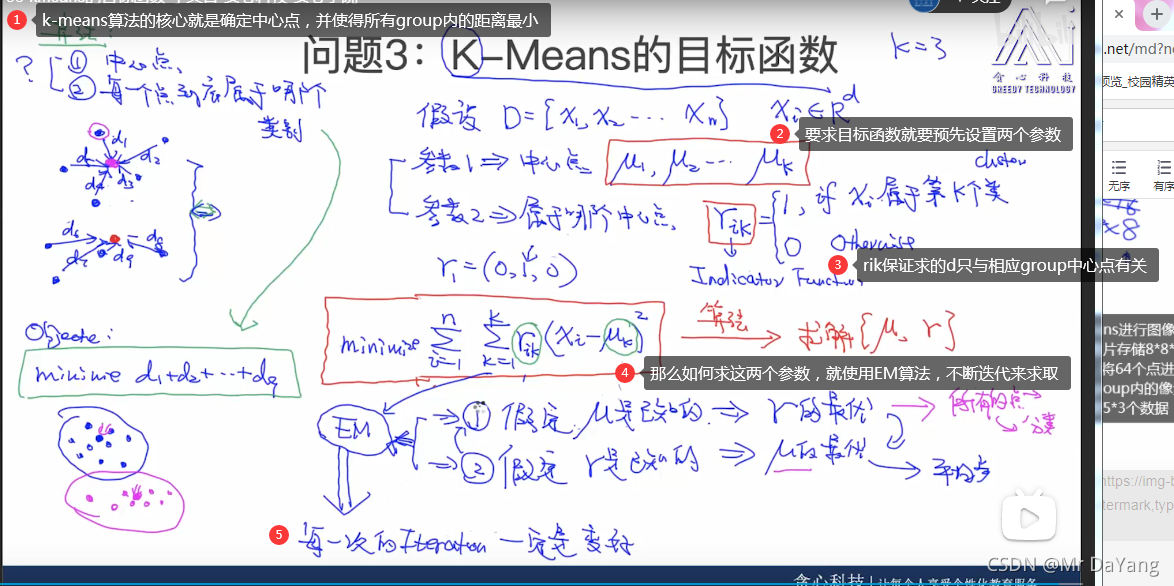
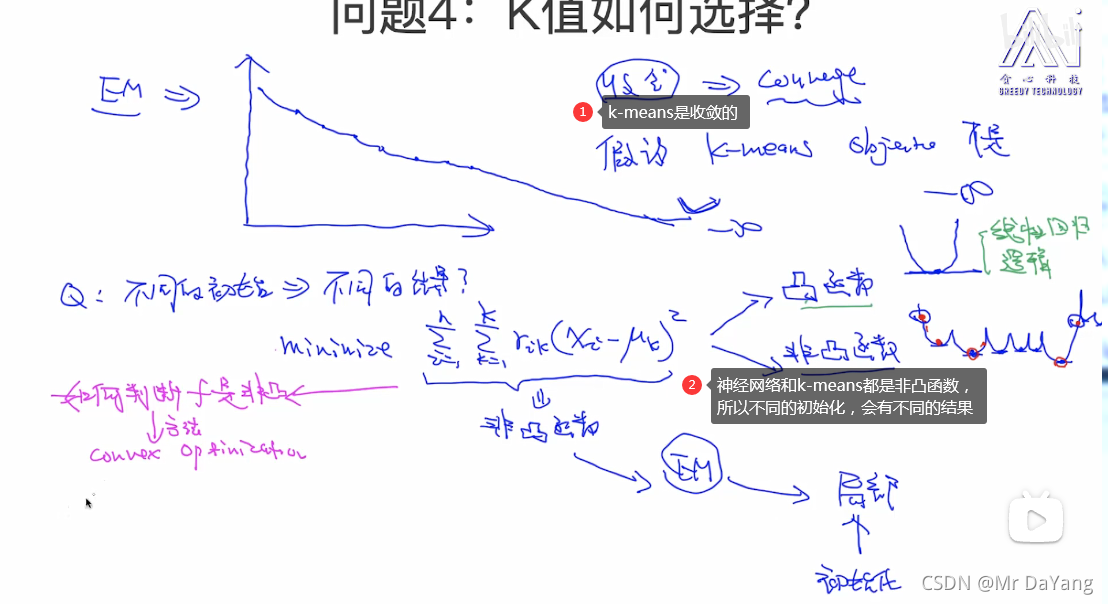
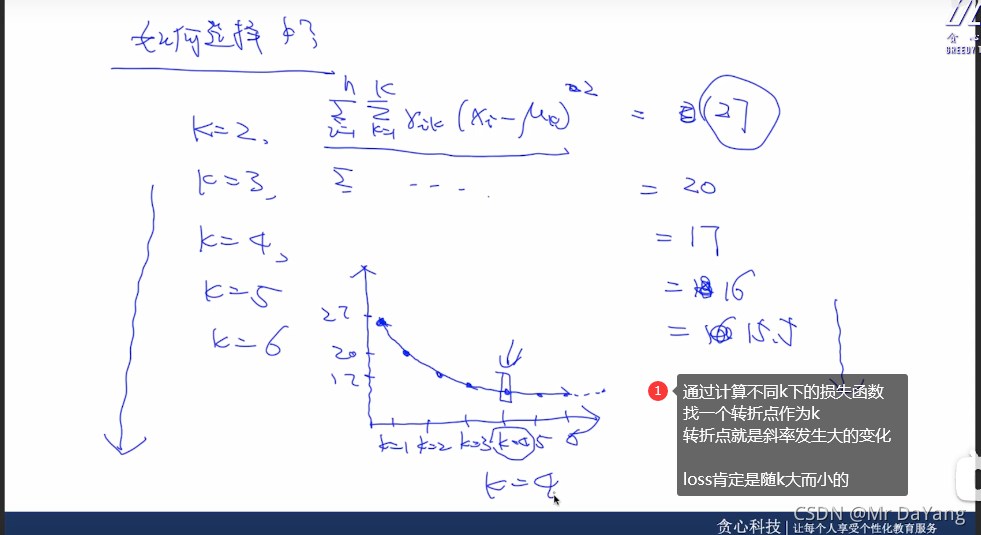
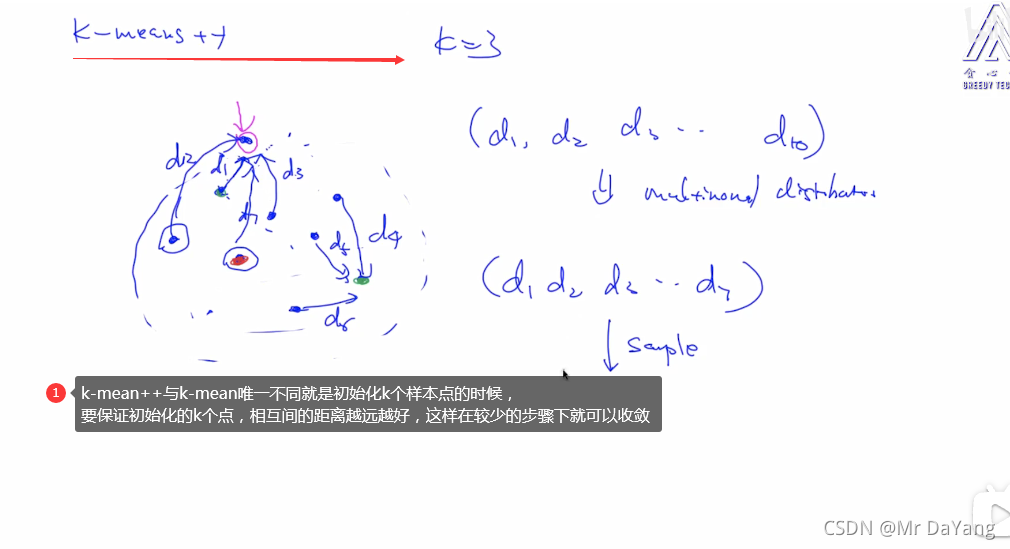
K-means一个点就属于一个group,hard clusting
GMM与K-means相似,只不过一个点可能属于多个类,每个类的喜好不同
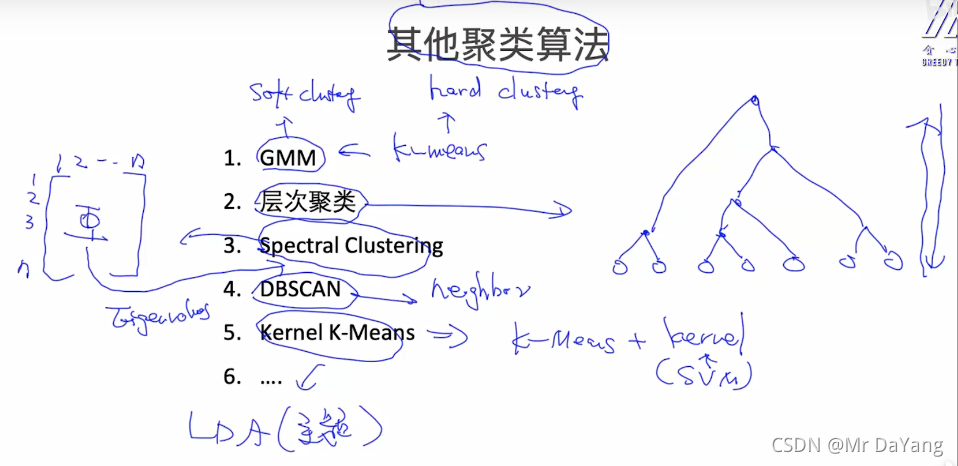

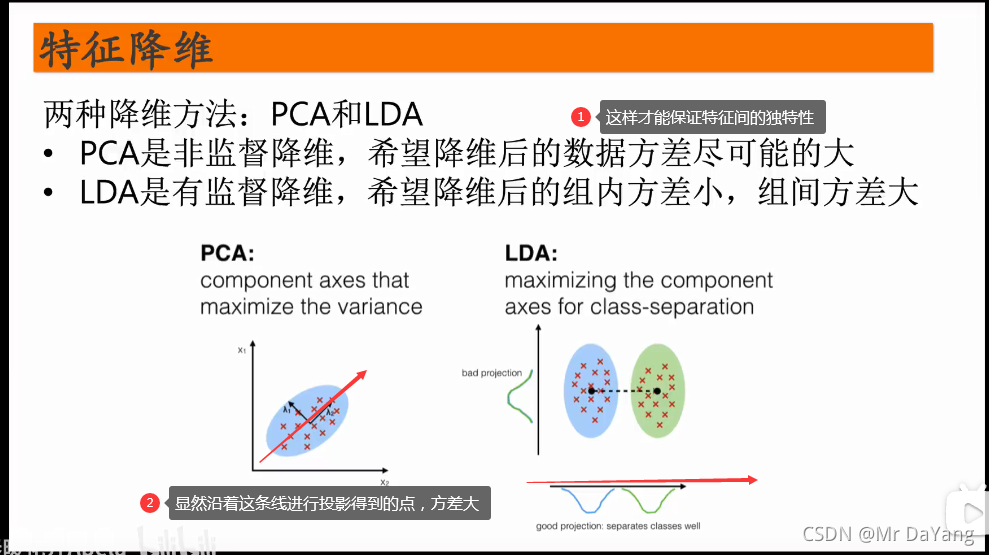



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









