







我的博客地址:www.lss-coding.top,欢迎大家访问
1. ElasticSearch 简介
官网地址:https://www.elastic.co/
1.1 ElasticSearch 概念
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。是一个分布式、高扩展、高实时的搜索与数据分析引擎,ES 就相当于把 Lucene 的封装。

-
MySQL 有事务性,而 ES 没有事务性,所以删了的数据是无法恢复的
-
ES 没有物理外键这个特性,如果数据强一致性要求比较高,不建议使用
-
ES 和 MySQL 分工不同,MySQL 负责存储数据,ES 负责搜索数据。
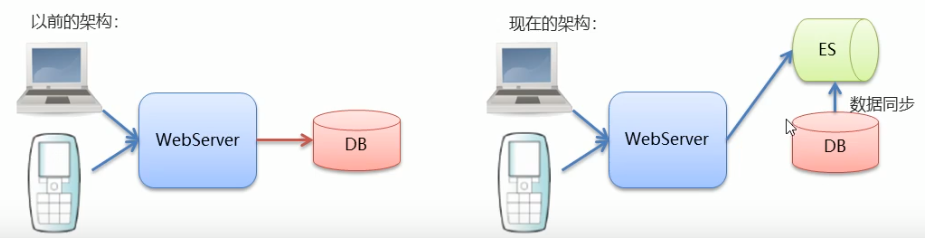
1.2 数据库查询的问题
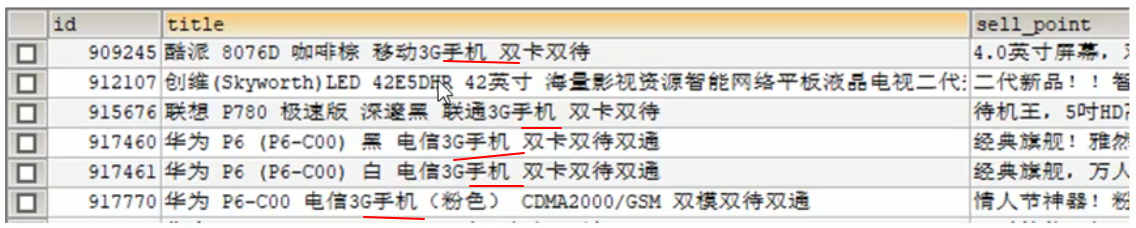
如同上表的情况,想要查询到 title 中包含 手机 的信息,SQL 语句模糊查询:select * from goods where title like '%手机%' 这种查询是一条一条记录进行比对的,记录多了查询的效率会非常的低。
如果使用模糊查询,左边有通配符,不会走索引,会全表扫描,性能低。
关系型数据库提供的查询,功能太弱。
1.3 倒排索引
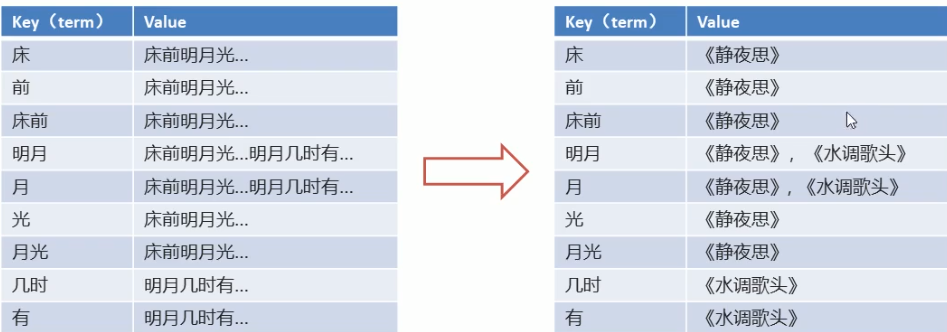
倒排索引:将各个文档中的内容,进行分词,形成词条。然后记录词条和数据的唯一标识(id)的对应关系,形成的产物。
有一个问题,请说出包含 “前” 的诗句?可能这个问题需要思考一下;但是如果说背诵《静夜思》就会直接想到 “床前明月光”,因为我们大脑存储数据是以正向索引的方式存储的,所以找 前 的诗句就会变得困难。

倒排索引
将 “床前明月光” 进行分词操作,将一段文本按照一定的规则,拆分为不同的词条(term),然后记录词条和文本之间的对应关系
反向(倒排)索引

1.4 ES 数据的存储和搜索原理
1.4.1 存储
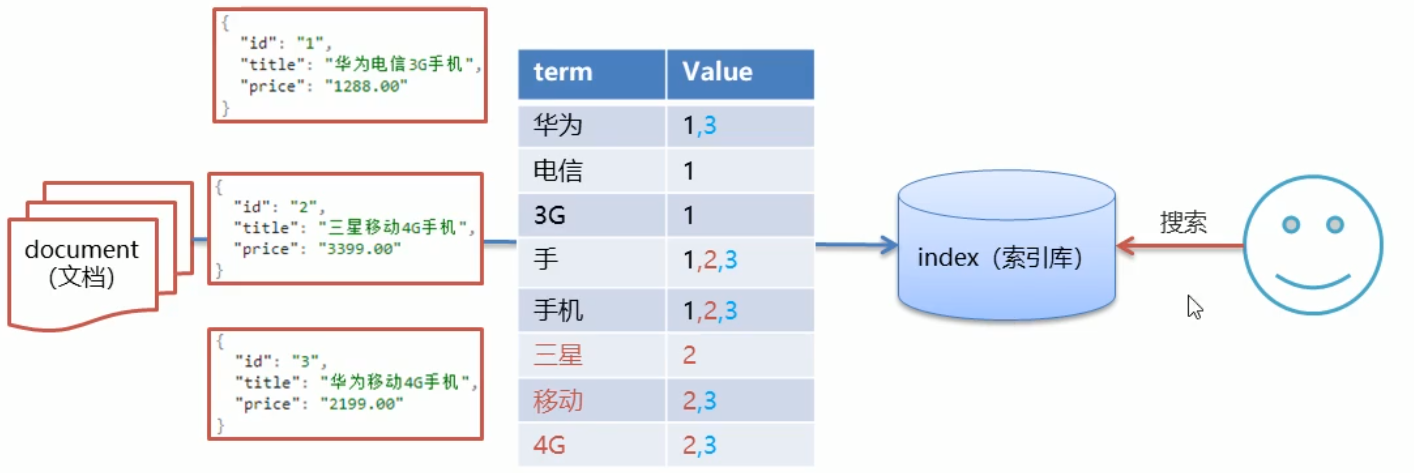
文档就是数据库中的一条一条的记录,用 json 格式进行存储,将文档中的各个数据信息进行拆分,拆分成不同的词条放到 index(索引库)中供搜索使用
1.4.2 搜索
-
假设使用 “手机” 作为关键字查询,在 term 中找到对应的词条,然后根据 Value 返回相对应的记录
生成的倒排索引中,词条会排序,形成一颗树形结构,提升词条的查询速度
-
使用 “华为手机” 作为关键字查询的时候,如果 term 中没有找打相应的词条就会对这个关键字进行拆分,拆分成 华为 和 手机 两个词,然后根据这两个词进行查找
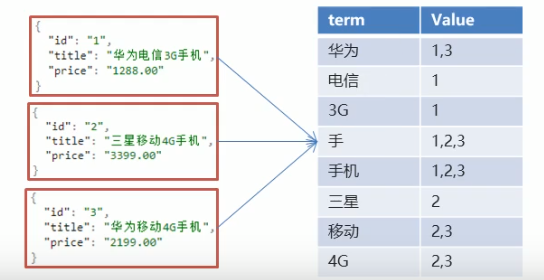
1.5 ES 核心概念
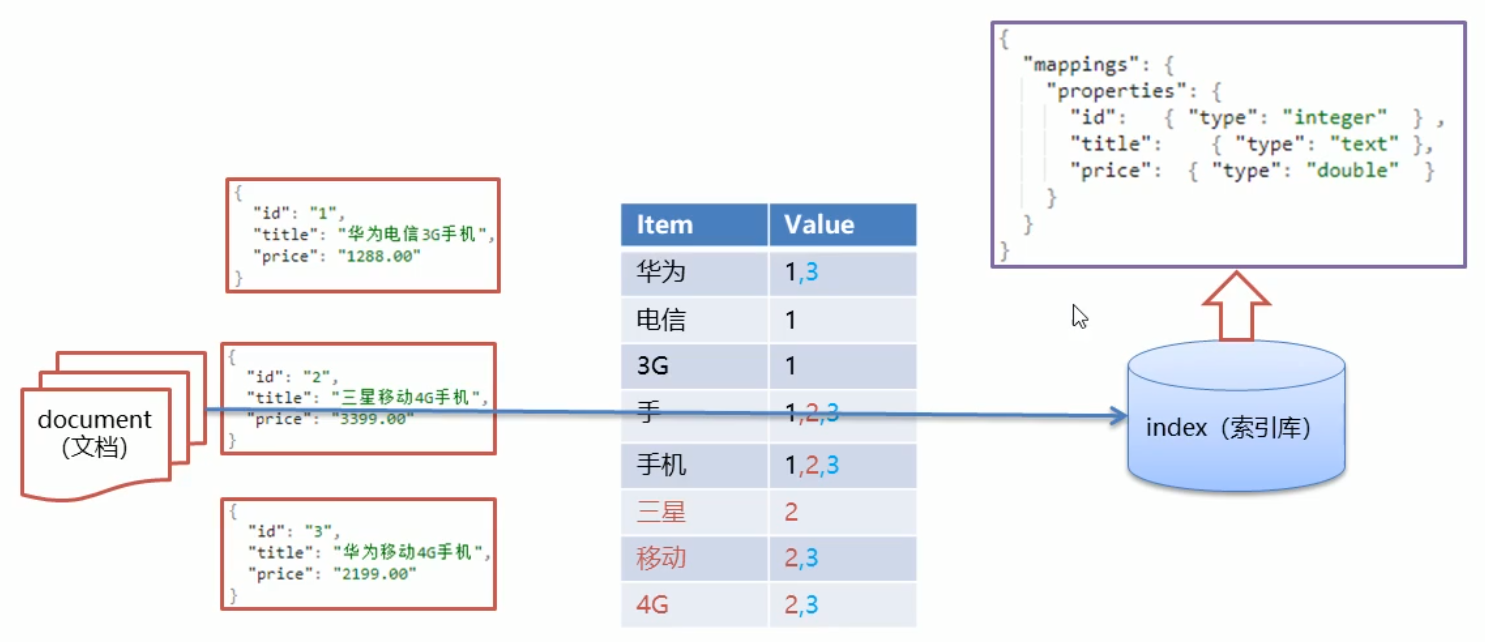
-
索引(index):ES 存储数据的地方,可以理解为关系型数据库中的数据库概念。
-
映射(mapping):mapping 定义了每个字段的类型、字段所使用的分词器等,相当于关系型数据库中的表结构。
-
文档(document):ES 中最小数据单元,常以 json 格式显示,一个 document 相当于关系型数据库中的一行记录。
-
倒排索引:一个倒排索引由文档中所有不重复词的列表组成,对于其中每个词,对应一个包含它的文档 id 列表。
-
类型(type):一种 type 就像一类表,如用户表、角色表等。在 ES 7.x 默认 type 为 _doc
ES5.x 中一个 index 可以有多种 type
ES6.x 中一个 index 只能有一种type
ES7.x 之后,逐步移除type 这个概念,现在的操作已经不再使用,默认 _doc
2. 安装 ElasticSearch
官网:https://www.elastic.co/cn/webinars/getting-started-elasticsearch?elektra=startpage
2.1 安装 ElasticSearch
-
官网下载好了 tar.gz 的压缩包上传到服务器上
-
解压缩
将 es 解压缩到 /opt 目录下
tar -zxvf elasticsearch-7.15.0-linux-x86_64.tar.gz -C /opt
# 安装好之后查看目录中包含一个 jdk 的目录,因为 es 是用 java 写的,所以他内置了一个 jdk,就算服务器不进行安装jdk 也可以使用,官网也是推荐使用内置的jdk,因为es 和 jdk 版本有强依赖性

- 修改 elasticsearch.yml 文件
#------------------ Elasticsearch Configuration ------------------------------
cluster.name: my-application
node.name: node-1
network.host: 0.0.0.0
http.port: 9200
cluster.initial_master_nodes: ["node-1"]
# cluster.name 配置 es 的集群名称,默认是 es,建议修改成一个自己的名称
# node.name 节点名,es 会默认随机指定一个名字,建议制定一个自己的名称,方便管理
# network.host 设置为 0.0.0.0 允许外网进行访问
# http.port es 的 http 访问端口
# cluster.initial_master_nodes 初始化新的集群时需要此配置来进行选举 master
进入 bin 目录,执行命令 ./elasticsearch 启动测试
启动的时候会有一个出错的信息,es 为了安全不能用 root 目录启动
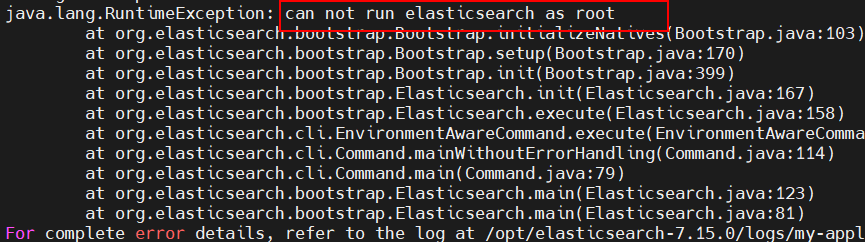
-
创建普通用户
因为安全问题,es 不允许 root 用户直接运行,所以要创建新用户,在 root 用户中创建新用户
useradd lss # 新增 lss 用户
passwd root # 为 lss 用户设置密码
- 为新用户授权
chown -R lss:lss /opt/elasticsearch-7.15.0 # 文件所有者

-
修改配置文件
新创建的 lss 用户最大可创建文件数太小,最大虚拟内存太小,切换到 root 用户,编辑下列配置文件,添加如下内容
# 1. 最大可创建文件数
vim /etc/security/limits.conf
# 在文件末尾增加下面内容
lss soft nofile 65536
lss hard nofile 65536
vim /etc/securitylimits.d/20-nproc.conf
# 在文件末尾增加下面内容
lss soft nofile 65536
lss hard nofile 65536
* hard nproc 4096
# * 代表 Linux 所有用户名称
# 2. 最大虚拟内存
vim /etc/sysctl.conf
# 在文件增加
vm.max_map_count=655360
# 重新加载
sysctl -p
- 启动 es
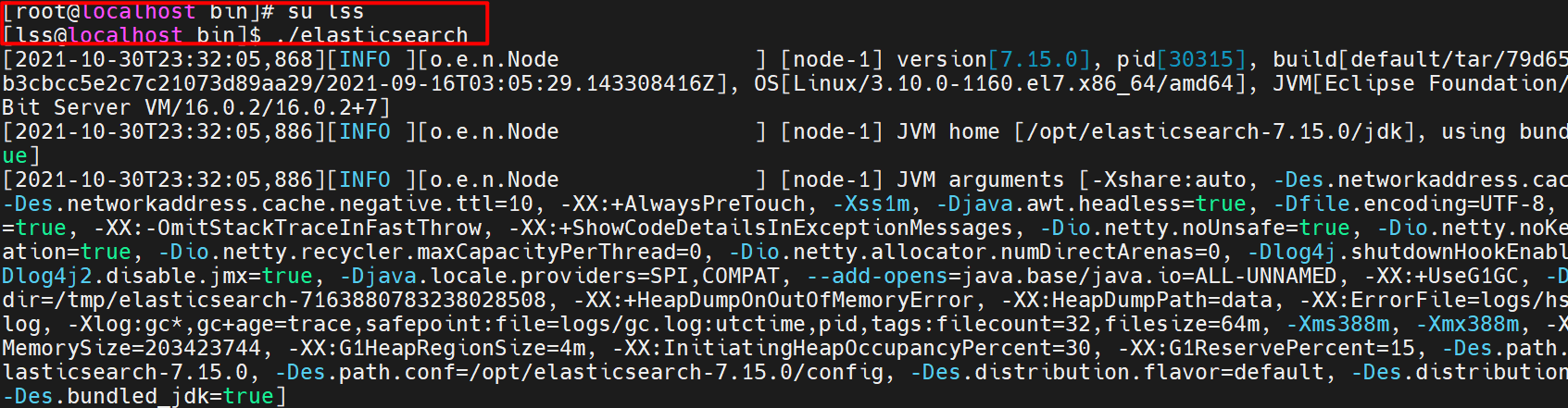
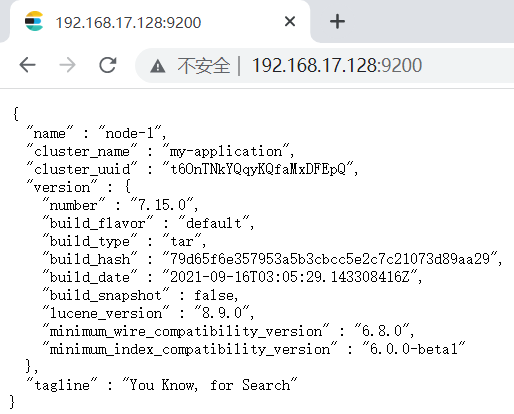
至此,es 安装成功
2.2 安装辅助插件
2.2.1 安装 Postman
Postman 是一个 http 模拟请求的工具
是一个专门测试 API 的工具,Postman 提供功能强大的 WebAPI 和 HTTP 请求的调试,它能够发送任何类型的 HTTP 请求(GET,POST,PUT,DELETE …),并且能附带任何数量的参数和 Headers。还提供测试数据和环境配置数据的导入导出。
百度搜索 postman 下载安装
2.2.2 安装 Kibana
下载地址:https://www.elastic.co/cn/downloads/kibana
Kibana 是一个针对 ElasticSearch 的开源分析及可视化平台,用来搜索、查看交互存储在 ElasticSearch 索引中的数据。使用 Kibana 可以通过各种图标进行高级数据分析及展示。
Kibana 让海量的数据更容易理解,操作简单,基于浏览器的用户界面可以快捷创建仪表板实时显示 ES 查询动态。
-
下载
下载好之后上传到 Linux 服务器
-
解压
tar -zxvf kibana-7.15.0-linux-x86_64.tar.gz -C /opt
- 修改 kibana 配置
vim /opt/kibana-7.15.0/config/kibana.yml
# server.port http 访问端口
# server.host ip 地址,0.0.0.0 表示可以远程访问
# server.name kibana 服务名
# elasticsearch.hosts elasticsearch地址
# elasticsearch.requestTimeout 请求elasticsearch超时时间,默认为 30000,可以根据情况设置
-
启动 kibana
启动的话也是需要设置文件是权限的
# 不设置权限,使用 root 用户启动
cd /opt/kibana-7.15.0/bin
./kibana --allow-root

3. 操作 ElasticSearch
这里使用脚本操作
3.1 RESTful 风格
REST(Representational State Transfer),表述性状态转移,是一组架构约束条件和原则,满足这些约束条件和原则的应用程序或设计就是 RESTful,就是一种定义接口的规范。
基于 HTTP;可以使用 XML 格式定义或 JSON 格式定义;每一个RUL 代表 1 中资源;
客户端使用 GET、POST、PUT、DELETE 4个表示操作方式的动词对服务端资源进行操作:
- GET:用来获取资源
- POST:用来新建资源(也可以用于更新资源)
- PUT:用来更新资源
- DELETE:用来删除资源
3.2 操作索引

使用 postman 工具操作
-
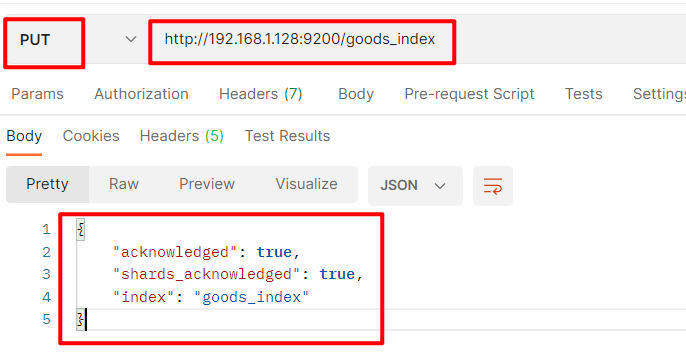
添加索引
使用 PUT 请求,
http://192.168.1.128:9200/索引名称
-
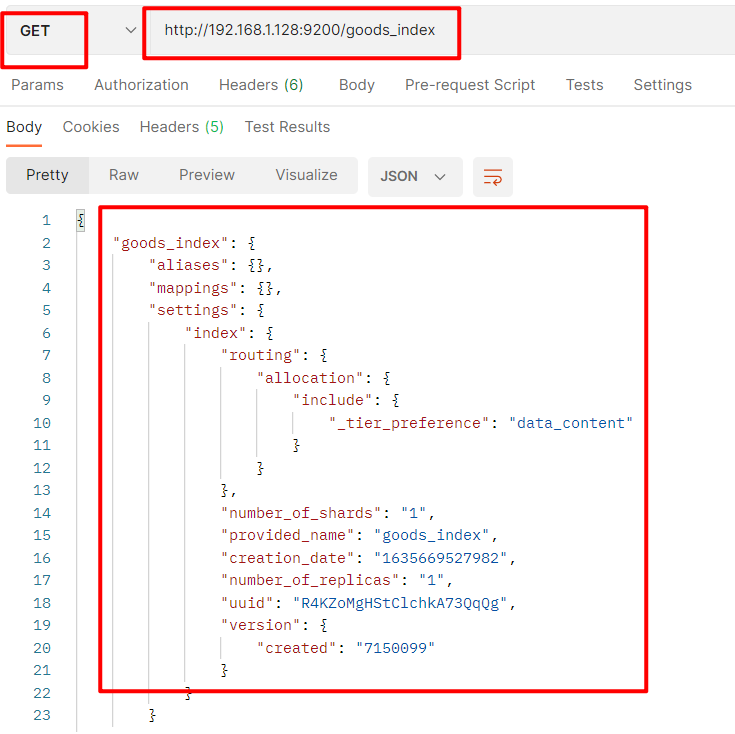
查询索引
使用 GET 请求,
http://192.168.1.128:9200/索引名称查询多个:…/索引名称1,索引名称2
查询全部:…/_all
-
删除索引
使用 DELETE 请求,
http://192.168.1.128:9200/索引名称

-
关闭索引
使用 POST 请求,
http://192.168.1.128:9200/索引名称/_close关闭之后还是可以通过 GET 请求查询到的,但是不能进行添加值的操作

-
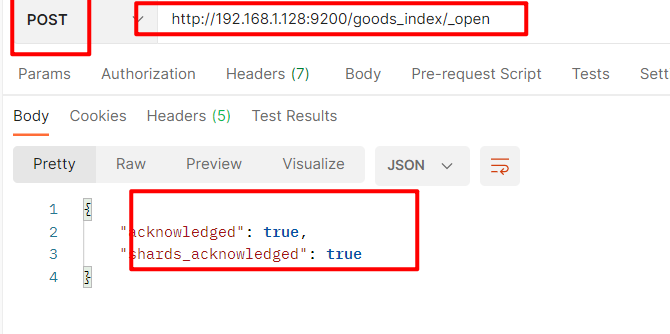
打开索引
使用 POST 请求,
http://192.168.1.128:9200/索引名称/_open
3.3 操作映射
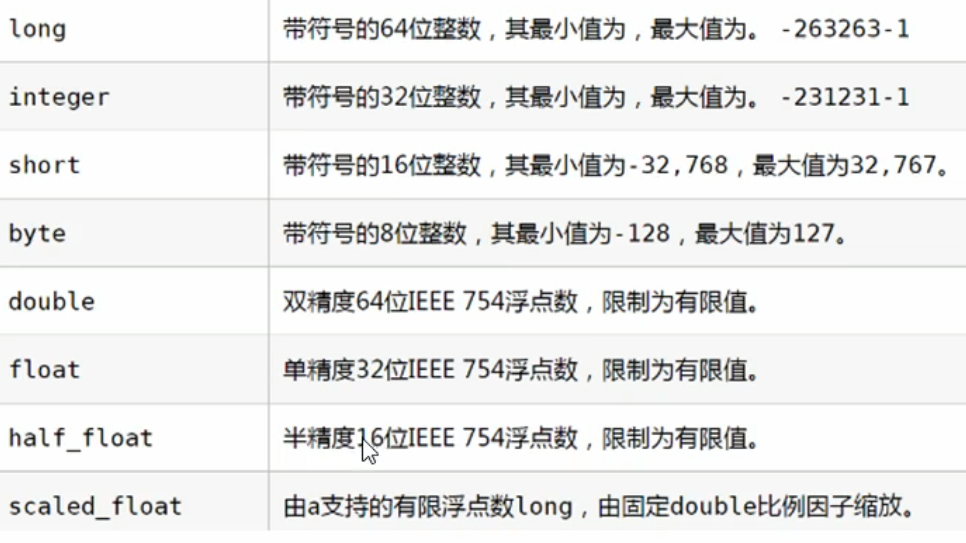
ES 中支持两种数据类型:简单数据类型,复杂数据类型
3.3.1 简单数据类型
- 字符串:
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合

- 数值:
-
布尔:
boolean
-
二进制:
binary
-
范围类型:
- integer_range
- float_range
- long_range
- double_range
- date_range
-
日期:
date
3.3.2 复杂数据类型
- 数组:[]
- 对象:{}
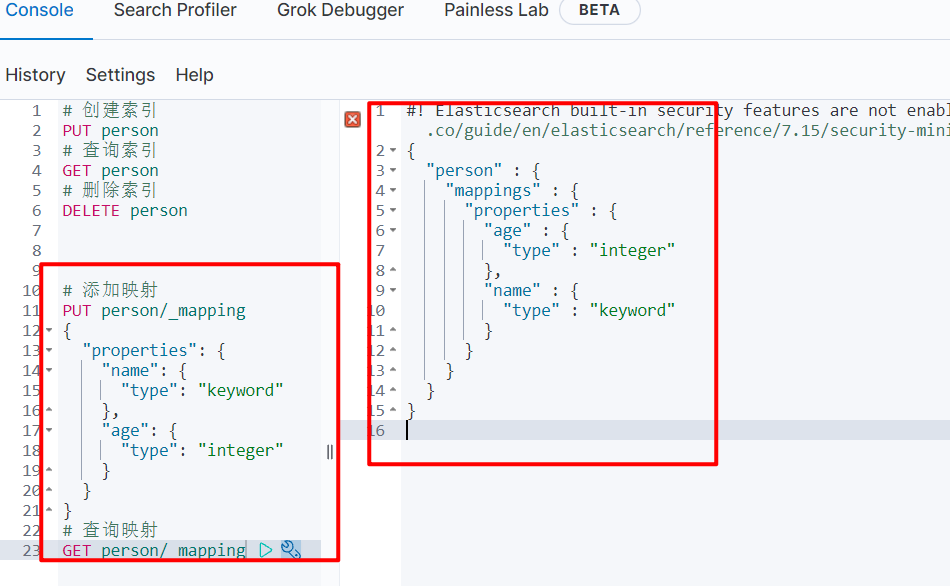
3.3.3 操作
在 kibana 中操作

# 添加映射
PUT person/_mapping
{
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
# 查询映射
GET person/_mapping
# 创建索引同时添加映射
PUT person
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"age": {
"type": "integer"
}
}
}
}
# 添加一个字段
PUT person/_mapping
{
"properties": {
"address": {
"type": "text"
}
}
}
3.4 操作文档
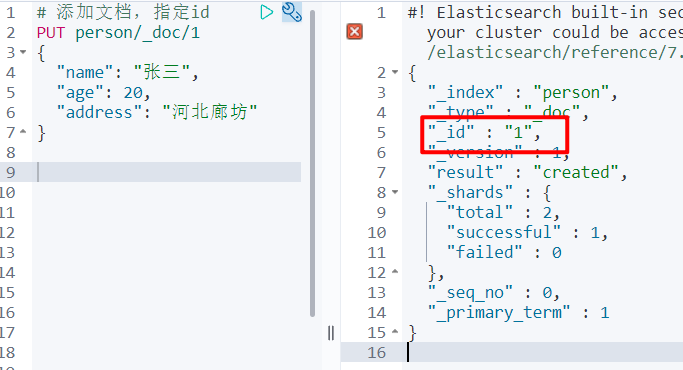
- 添加文档
# 添加文档,指定id,用 put 和 post 请求都可以
PUT person/_doc/1
{
"name": "张三",
"age": 20,
"address": "河北廊坊"
}
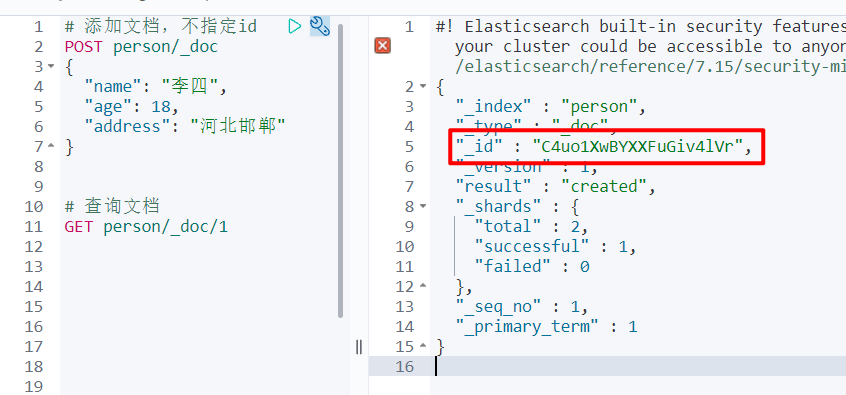
# 添加文档,不指定id,id随机生成,只能用 post 请求
POST person/_doc
{
"name": "李四",
"age": 18,
"address": "河北邯郸"
}
- 查询文档
# 根据 id 查询文档
GET person/_doc/1
# 查询所有文档
GET person/_search
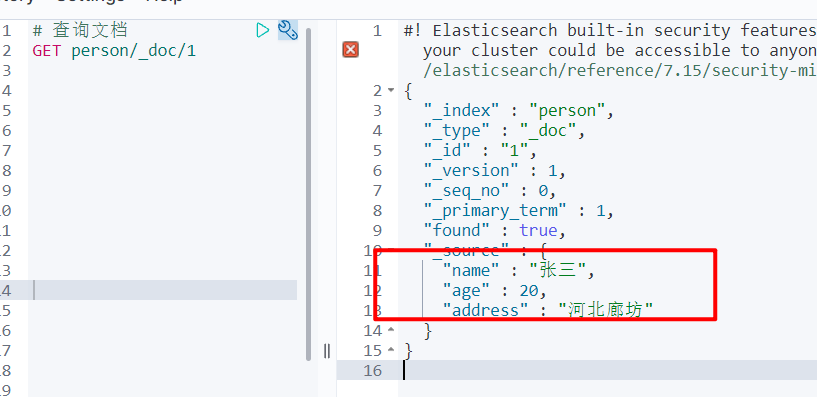
- 修改文档
# 修改就是添加的方式,如果 id 存在修改,不存在创建
PUT person/_doc/1
{
"name": "张三111",
"age": 20,
"address": "河北廊坊"
}
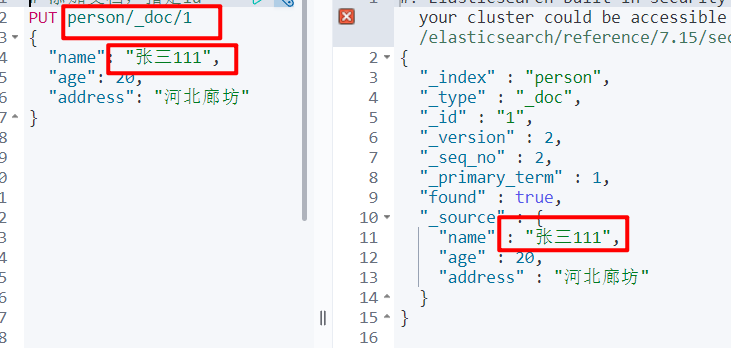
- 根据 id 删除文档
# 删除文档
DELETE person/_doc/id
4. 分词器(Analyzer)
4.1 介绍
-
分词器:将一段文本,按照一定逻辑,分析成多个词语的一种工具。
如:华为手机 ---- 华为、手、手机
-
ElasticSearch 内置分词器
- Standard Analyzer :默认分词器,按词切分,小写处理
- Simple Analyzer:按照非字母切分(符号被过滤),小写处理
- Stop Analyzer:小写处理,停用词过滤(the,a,is)
- Whitespace Analyzer:按照空格切分,不转小写
- Keyword Analyzer:不分词,直接将输入当作输出
- Patter Analyzer:正则表达式,默认 \ W + (非字符分割)
- Language:提供了 30 多种常见语言的分词器
-
ElasticSearch 内置分词器对中文很不友好,处理方式为:一个字一个词
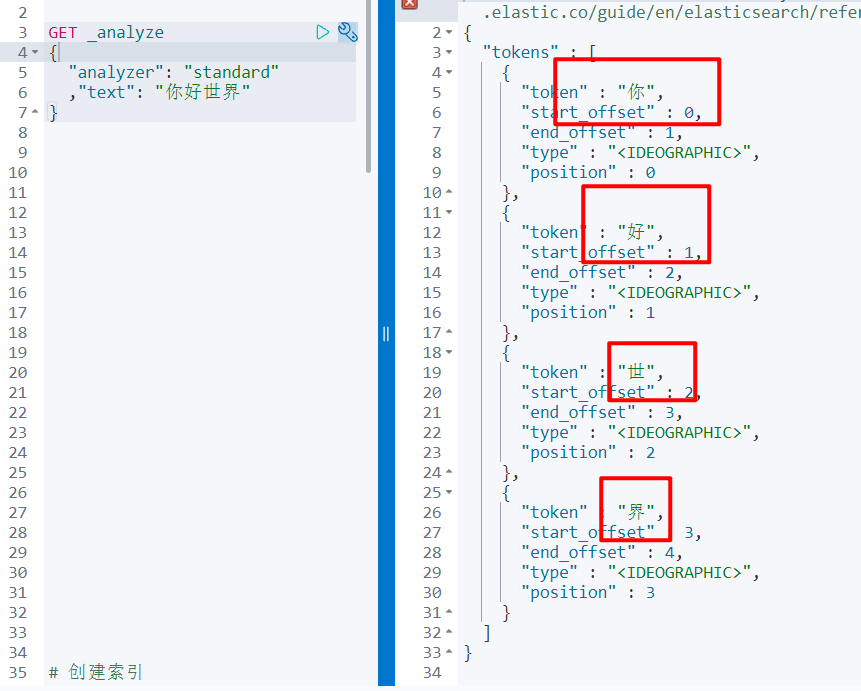
4.2 IK 分词器
4.2.1 介绍
-
IKAnalyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。
-
是一个基于 Maven 构建的项目
-
具有 60 万字/秒的高速处理能力
-
支持用户词典扩展定义
-
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
4.2.2 IK 分词器安装
-
环境准备
ES 要使用 ik,就要先构建 ik 的 jar 包,这里要用到 maven 包管理工具,而 maven 需要 java 环境,而 ES 内置了 jdk,所以可以将 JAVA_HOME 设置为 ES 内置的 jdk
# 设置 JAVA_HOME
vim /etc/profile
# 在 profile 文件末尾进行添加 java environment
export JAVA_HOME=/opt/elasticsearch-7.15.0/jdk
export PATH=$PATH:${JAVA_HOME}/bin
# 保存退出后,重新加载 profile
source /etc/profile
# 下载 maven 安装包并上传到服务器上并
# 解压
tar -xzf apache-maven-3.6.3-bin.tar.gz
# 设置软连接 方便操作
ln -s apache-maven-3.6.3 maven
# 设置 path
vim /etc/profile.d/maven.sh
#
export MAVEN_HOME=/opt/maven
export PATH=${MAVEN_HOME}/bin:${PATH}
#
source /etc/profile.d/maven.sh
#
mvn -v
-
安装 ik 分词器
下载好之后上传到服务器
# 解压
unzip elasticsearch-analysis-ik-7.15.0
# 进入到解压好的目录进行打包
mvn package
打包好之后进行jar 包的移动,package 执行完毕后会在当前目录生成 target/releases 目录,将其中的 elasticsearch-analysis-ik-7.15.0.zip 拷贝到 elasticsearch 目录下的新建的目录 plugin/analysis-ik,并解压
# 进入 elasticsearch-7.15.0/plugins/
cd /opt/elasticsearch-7.15.0/plugins/
# 新建目录
mkdir analysis-ik
cd analysis-ik
# 拷贝文件
cp -R /opt/elasticsearch-analysis-ik-7.15.0/target/releases/elasticsearch-analysis-ik-7.15.0.zip /opt/elasticsearch-7.15.0/plugins/analysis-ik/
# 解压拷贝进去的文件
unzip /opt/elasticsearch-7.15.0/plugins/analysis-ik/elasticsearch-analysis-ik-7.15.0.zip
# 拷贝词典
# 将 elasticsearch-analysis-ik-7.15.0 目录下的 config 目录下的所有文件拷贝到 elasticsearch 的config 目录
cp -R /opt/elasticsearch-analysis-ik-7.15.0/config/* /opt/elasticsearch-7.15.0/config/
# 重启 elasticsearch

4.3 使用 IK 分词器
IK 分词器有两种分词模式:ik_max_word 和 ik_smart 模式。
-
ik_max_word
将文本做最细粒度的拆分,比如会将”乒乓球明年总冠军“ 拆分成 ”乒乓球、乒乓、球、明年、总冠军、冠军“
# ik 分词器,细粒度分词
GET _analyze
{
"analyzer": "ik_max_word"
,"text": "我爱北京天安门"
}
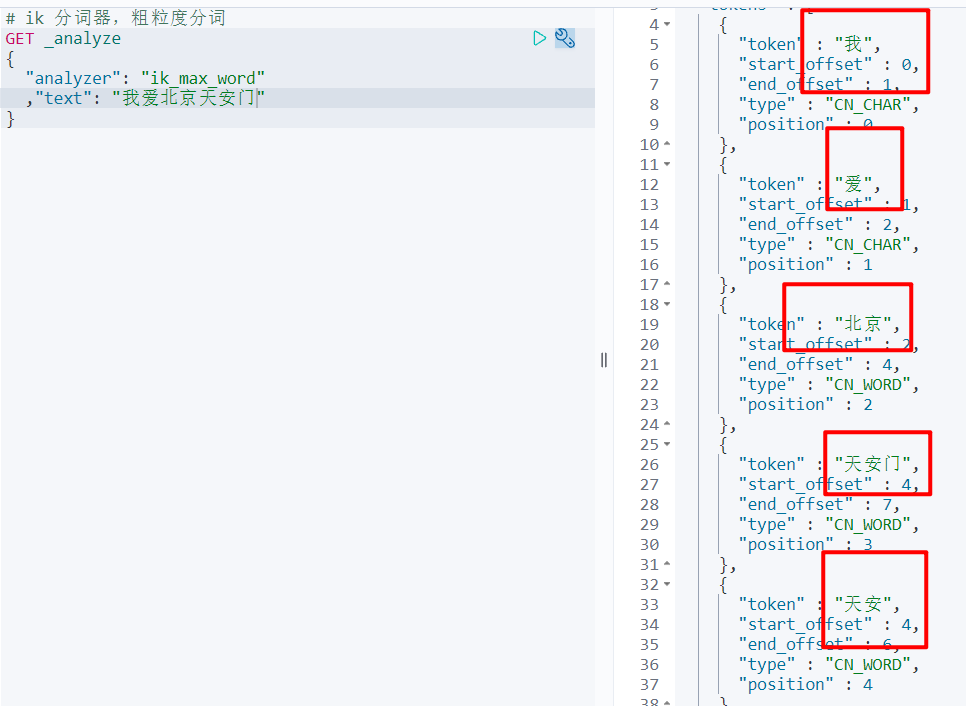
- ik_smart
# ik 分词器,粗粒度分词
GET _analyze
{
"analyzer": "ik_smart"
,"text": "你好世界"
}

4.4 查询文档
- 词条查询:term:词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索。
- 全文查询:match:全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集。
# 添加几条文档信息
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "person",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"properties" : {
"name" : "张三",
"age" : 21,
"phone" : "华为手机"
}
}
},
{
"_index" : "person",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"properties" : {
"name" : "李四",
"age" : 22,
"phone" : "华为5G手机"
}
}
},
{
"_index" : "person",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"properties" : {
"name" : "王五",
"age" : 25,
"phone" : "华为荣耀"
}
}
},
{
"_index" : "person",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"properties" : {
"name" : "丁丁",
"age" : 24,
"phone" : "手机"
}
}
}
]
}
}
# term 词条查询,查询的条件字符串和词条完全匹配
# es 默认使用的分词器是 stanard,一个字一个词
GET person/_search
{
"query": {
"term": {
"properties.phone": {
"value": "手"
}
}
}
}
# 删除掉之前的person,重新创建索引,添加映射,指定使用 ik 分词器
PUT person
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
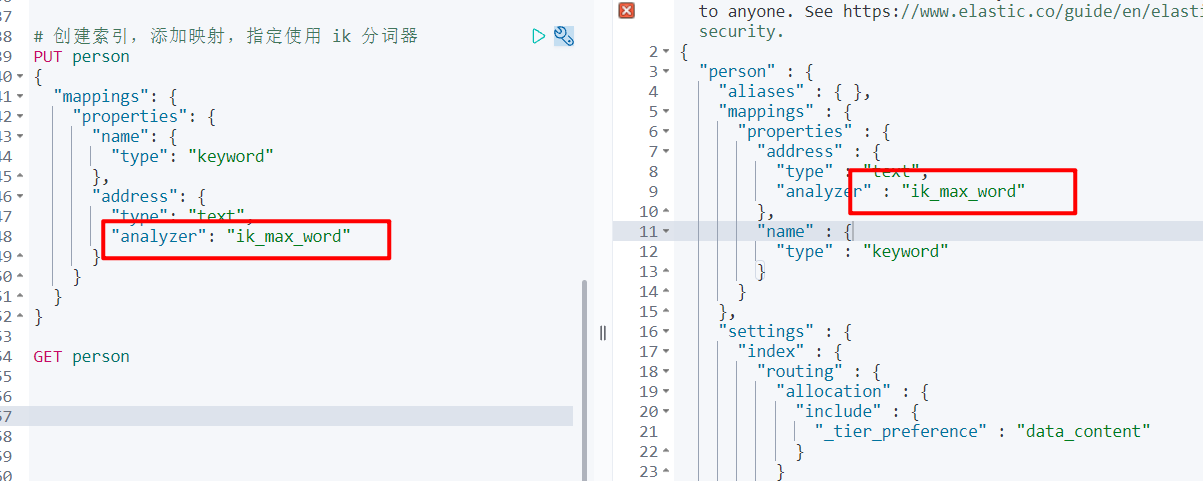
# 这块内容与上面不一样
# 创建索引,other 使用 "analyzer": "ik_max_word" ik 分词器
PUT person
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"other": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
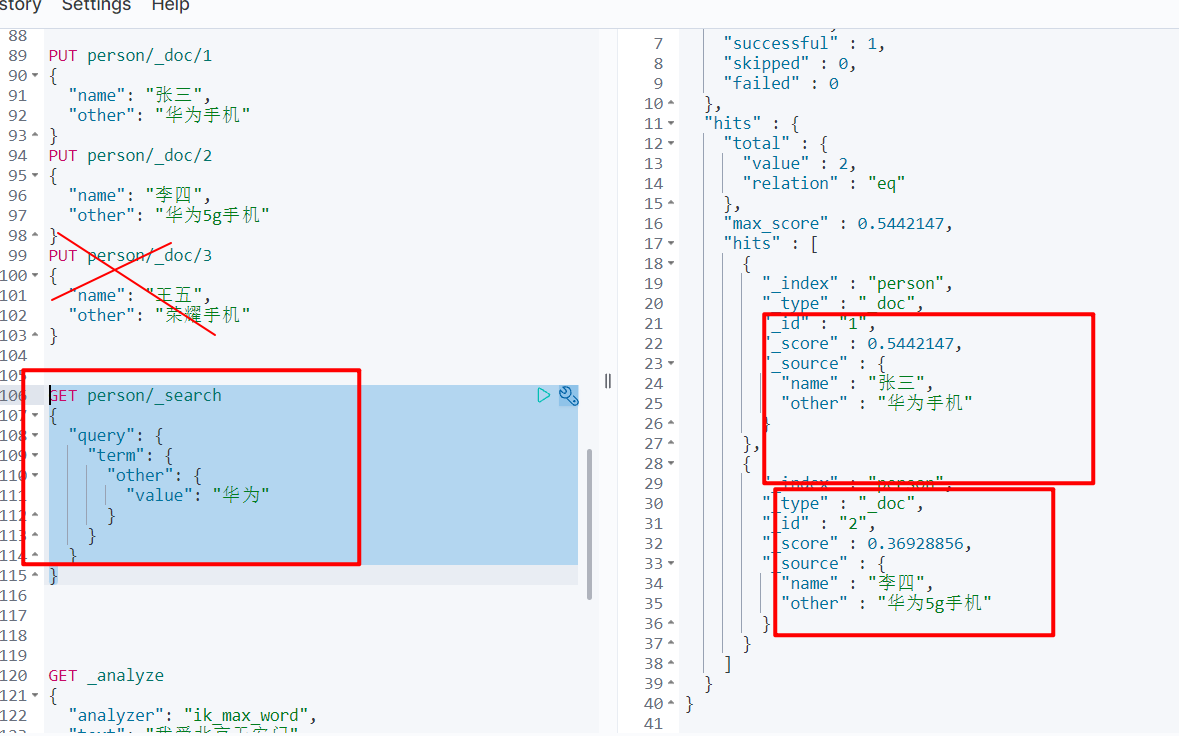
# 添加几个文档
PUT person/_doc/1
{
"name": "张三",
"other": "华为手机"
}
PUT person/_doc/2
{
"name": "李四",
"other": "华为5g手机"
}
PUT person/_doc/3
{
"name": "王五",
"other": "荣耀手机"
}
# 查询包含手机的文档
# term 词条查询,查询的条件字符串和词条完全匹配
GET person/_search
{
"query": {
"term": {
"other": {
"value": "华为"
}
}
}
}
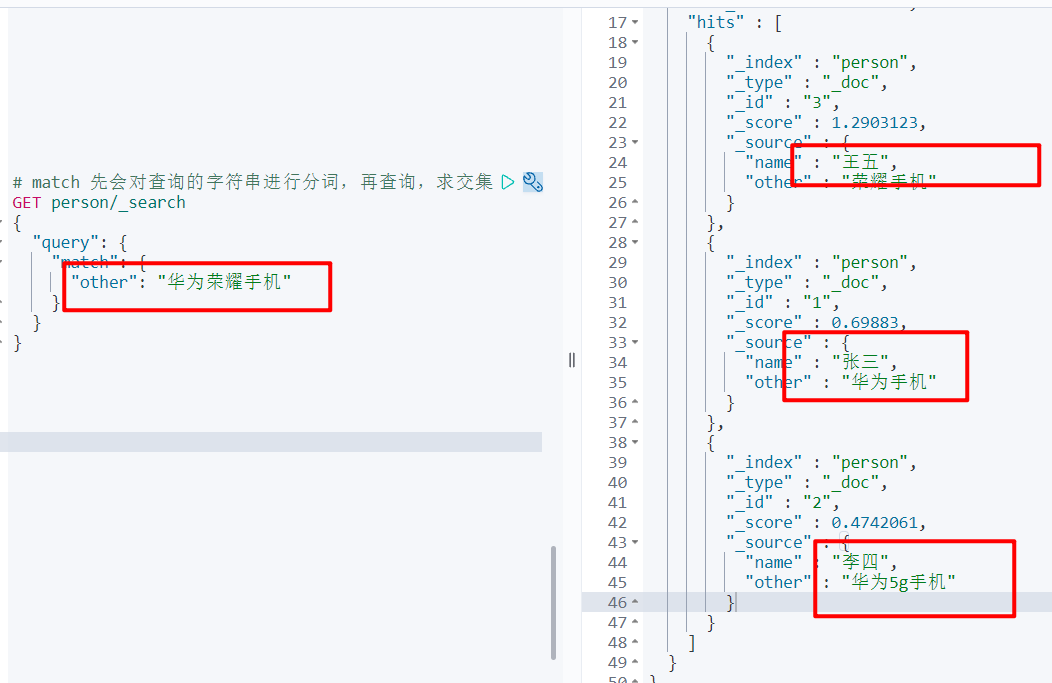
# match 先会对查询的字符串进行分词,再查询,求交集
GET person/_search
{
"query": {
"match": {
"other": "华为荣耀手机"
}
}
}
# 这块会对 华为荣耀手机 进行分词,华为 荣耀 手机,然后三个词查询完之后求交集就是最终的结果
5. SpringBoot 整合 ES
5.1 整合
- 创建 一个 Spring Boot 项目 elasticsearch-demo
- 引入依赖坐标
<!--引入 ES 相关坐标-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.1 5.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.15.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.15.0</version>
</dependency>
- 测试
// 使用测试类简单创建一个 ES 客户端测试
@Test
void contextLoads() {
// 1. 创建 ES 的客户端
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("192.168.11.11",9200,"http")
));
System.out.println(client);
}
输出:org.elasticsearch.client.RestHighLevelClient@5ec46cdd //测试成功
整合到 Spirng Boot
// 创建一个RestHighLevelClient 的配置类
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Bean(value = "client")
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(new HttpHost(host, port, "http")));
}
}
# yml 配置文件
elasticsearch:
host: 192.168.11.11
port: 9200
5.2 操作索引
5.2.1 添加索引
/**
* 添加索引
*/
@Test
void addIndex() throws IOException{
// 1. 使用 client 获取操作索引的对象
IndicesClient indicesClient = client.indices();
// 2. 具体的操作,获取返回值
CreateIndexRequest createIndexRequest = new CreateIndexRequest("spring");
// 2.1 创建所以的同时也可以指定 mapping
String mapping = "{\n" +
" \"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"address\": {\n" +
" \"type\": \"text\"\n" +
" , \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }";
createIndexRequest.mapping(mapping, XContentType.JSON);
CreateIndexResponse response = indicesClient.create(createIndexRequest, RequestOptions.DEFAULT);
// 3. 根据返回值判断是否创建成功
System.out.println(response.isAcknowledged());
}
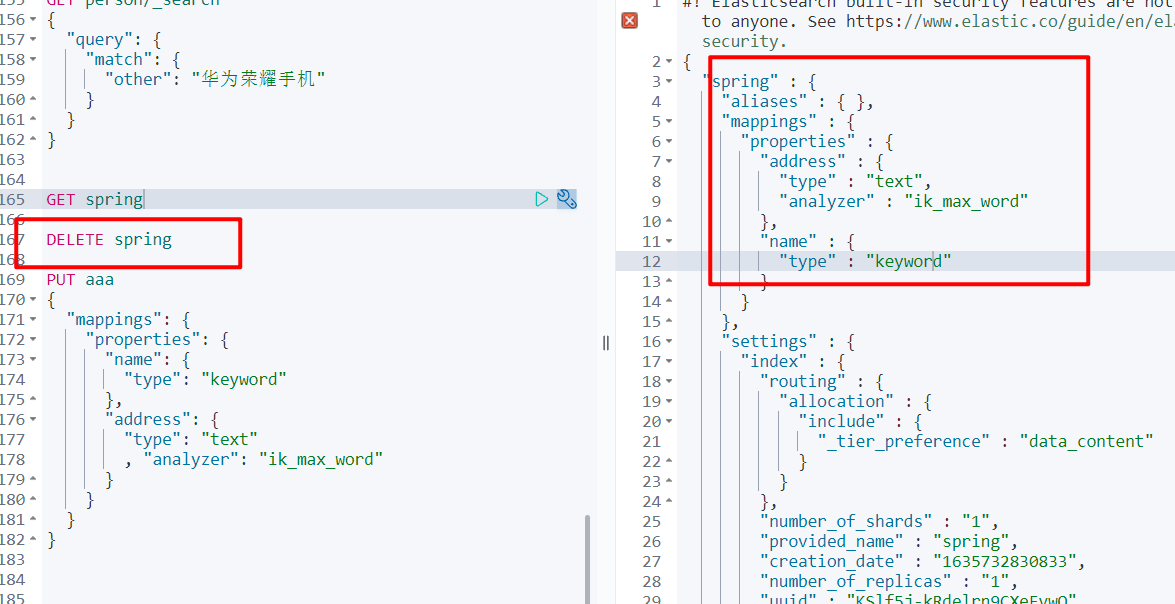
5.2.2 查询索引
/**
* 查询索引
* @throws IOException
*/
@Test
void queryIndex() throws IOException {
IndicesClient indicesClient = client.indices();
GetIndexRequest createIndexRequest = new GetIndexRequest("spring");
GetIndexResponse response = indicesClient.get(createIndexRequest, RequestOptions.DEFAULT);
Map<String, MappingMetadata> mappings = response.getMappings();
// 获取结果
for (String key : mappings.keySet()) {
System.out.println(key + ":" + mappings.get(key).getSourceAsMap());
}
}
5.2.3 删除索引
/**
* 删除索引
*/
@Test
void delIndex() throws IOException {
IndicesClient indices = client.indices();
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("spring");
AcknowledgedResponse response = indices.delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
5.2.4 判断索引是否存在
/**
* 判断索引是否存在
*/
@Test
void isExists() throws IOException {
IndicesClient indices = client.indices();
GetIndexRequest getIndexRequest = new GetIndexRequest("spring");
boolean exists = indices.exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
5.3 操作文档
5.3.1 添加文档
/**
* 添加文档,使用 map 作为添加的数据
*/
@Test
void addDoc() throws IOException {
// 数据对象
Map data = new HashMap();
data.put("name","张三");
data.put("address","河北廊坊");
// 1. 获取操作文档的对象
IndexRequest request = new IndexRequest("spring").id("1").source(data);
// 添加数据,获取结果
IndexResponse response = client.index(request, RequestOptions.DEFAULT);
// 2. 打印相应结果
System.out.println(response.getId());
}
/**
* 添加文档 对象方式
*/
@Test
void addDockByJavaObject() throws IOException {
Person person = new Person();
person.setName("李四");
person.setAddress("北京房山区");
// 将 Person 对象转换成 json
String data = JSON.toJSONString(person);
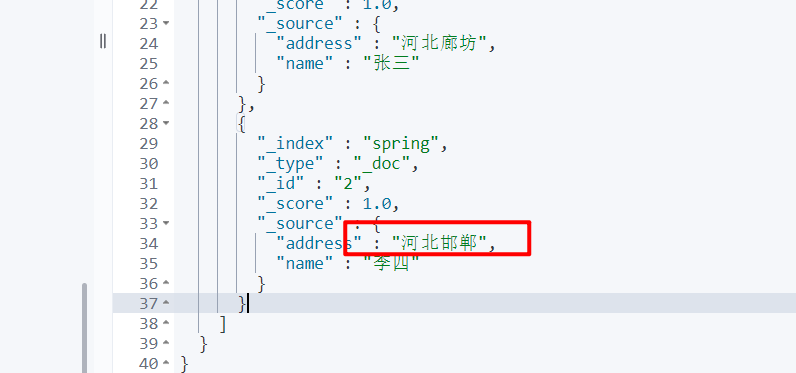
IndexRequest indexRequest = new IndexRequest("spring").id("2").source(data,XContentType.JSON);
IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(index.getId());
}


5.3.2 修改文档
/**
* 修改文档,添加文档时,如果 id 存在则修改,不存在则添加
*/
@Test
void updDoc() throws IOException {
Person person = new Person();
person.setName("李四");
// 修改地址为 河北邯郸
person.setAddress("河北邯郸");
// 将 Person 对象转换成 json
String data = JSON.toJSONString(person);
IndexRequest indexRequest = new IndexRequest("spring").id("2").source(data,XContentType.JSON);
IndexResponse index = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(index.getId());
}
5.3.3 根据 id 查询文档
/**
* 根据 id 查询文档
*/
@Test
void queryDoc() throws IOException {
GetRequest getRequest = new GetRequest("spring","1");
GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);
// 获取数据对应的 json
System.out.println(response.getSourceAsString());
}
5.3.4 删除文档
/**
* 删除文档
*/
@Test
void delDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("spring","1");
DeleteResponse response = client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(response.getId());
}
6. ElasticSearch 高级操作
6.1 批量操作
6.1.1 脚本操作
Bulk 批量操作是将文档的增删改查一系列操作,通过一次请求全部做完,减少网络传输次数。
- 语法格式
# 语法格式
POST /_bulk
{"action": {"metadata"}}
{"data"}
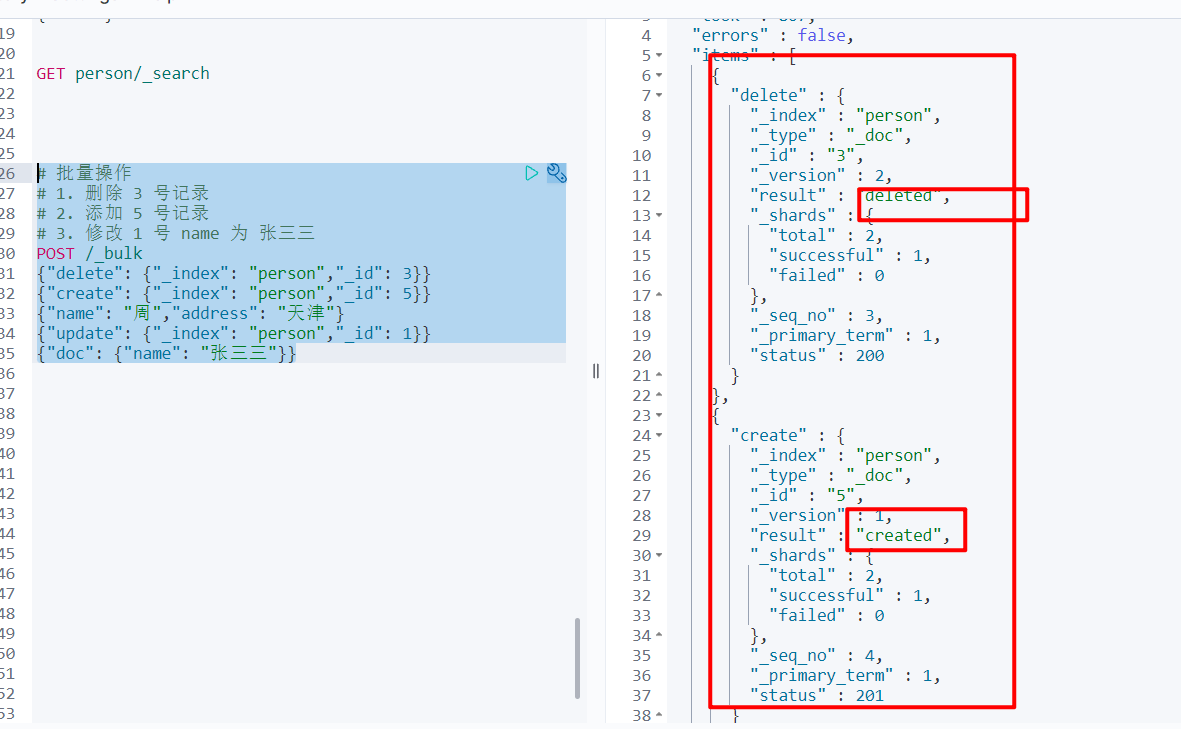
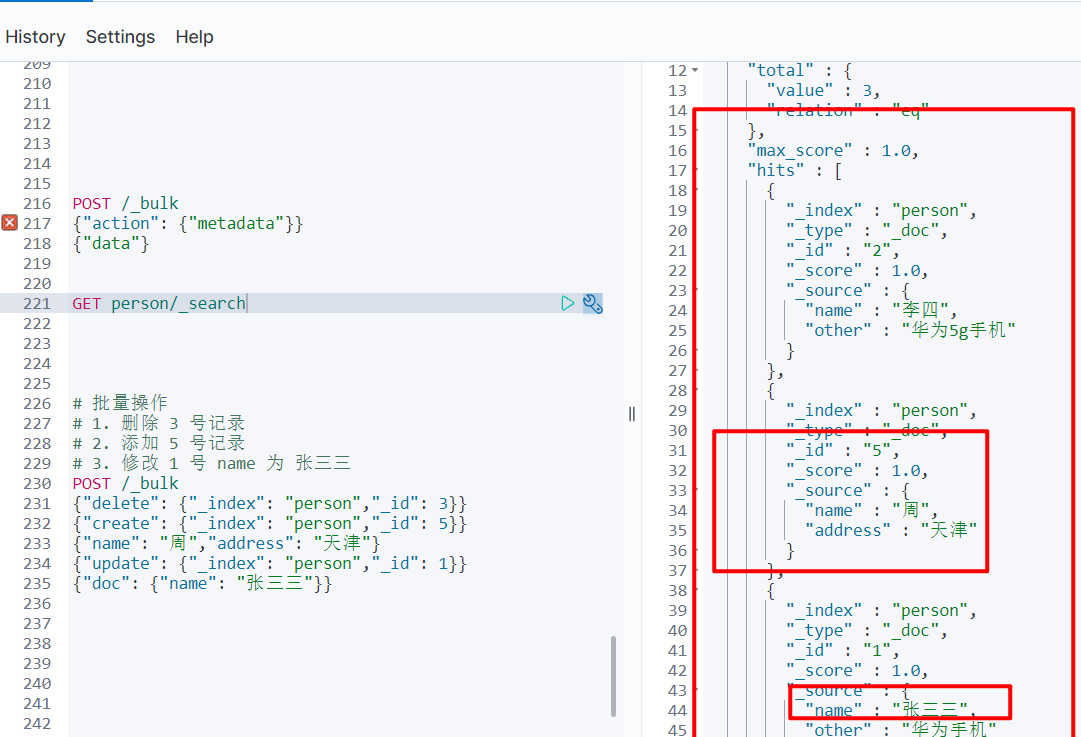
# 批量操作
# 1. 删除 3 号记录
# 2. 添加 5 号记录
# 3. 修改 1 号 name 为 张三三
POST /_bulk
{"delete": {"_index": "person","_id": 3}}
{"create": {"_index": "person","_id": 5}}
{"name": "周","address": "天津"}
{"update": {"_index": "person","_id": 1}}
{"doc": {"name": "张三三"}}
6.1.2 JavaAPI
/**
* 批量操作 bulk
*/
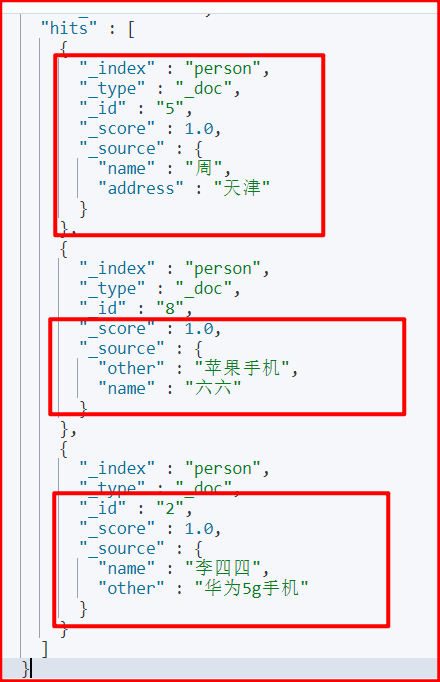
@Test
void testBulk() throws IOException {
// 创建 bulkRequest 对象,整合所有操作
BulkRequest bulkRequest = new BulkRequest();
/**
* # 批量操作
* # 1. 删除 1 号记录
* # 2. 添加 8 号记录
* # 3. 修改 4 号 name 为 李四四
*/
// 添加对应的操作
// 删除 1 号记录
DeleteRequest deleteRequest = new DeleteRequest("person","1");
bulkRequest.add(deleteRequest);
// 添加 8 号记录
HashMap data = new HashMap();
data.put("name","六六");
data.put("other","苹果手机");
IndexRequest indexRequest = new IndexRequest("person").id("8").source(data);
bulkRequest.add(indexRequest);
// 修改 4 号 name 为 李四四
HashMap docData = new HashMap();
docData.put("name","李四四");
UpdateRequest updateRequest = new UpdateRequest("person","4").doc(docData);
bulkRequest.add(updateRequest);
// 执行批量操作
BulkResponse response = client.bulk(bulkRequest, RequestOptions.DEFAULT);
RestStatus status = response.status();
System.out.println(status);
}
6.2 导入数据
将数据库中 student表的数据导入到 ElasticSearch 中
实现步骤:
- 创建 student 索引
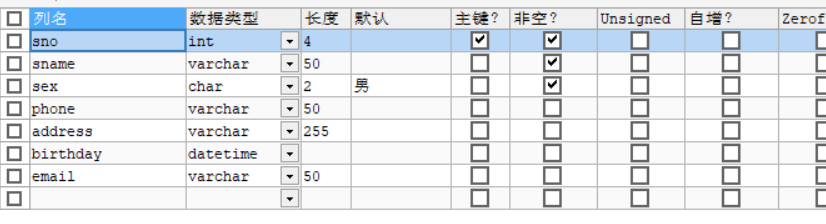
根据数据库表创建索引
PUT students
{
"mappings": {
"properties": {
"sno": {
"type": "integer"
},
"sname": {
"type": "text",
"analyzer": "ik_smart"
},
"sex": {
"type": "keyword"
},
"phone": {
"type": "text"
},
"address": {
"type": "text",
"analyzer": "ik_smart"
},
"birthday": {
"type": "date"
},
"email": {
"type": "text"
}
}
}
}
GET students
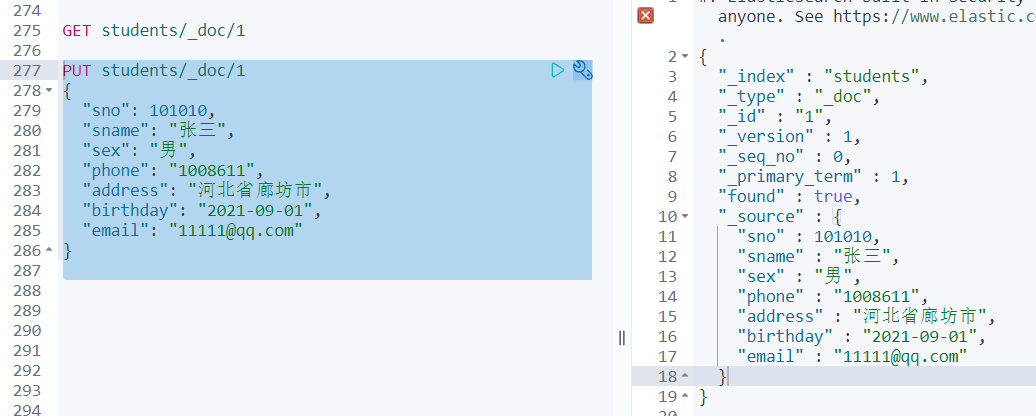
# 加入一条数据验证是否创建成功
PUT students/_doc/1
{
"sno": 101010,
"sname": "张三",
"sex": "男",
"phone": "1008611",
"address": "河北省廊坊市",
"birthday": "2021-09-01",
"email": "11111@qq.com"
}
-
查询 student 表数据
使用 MyBatis 与数据库建立连接,查询数据库的数据
@Autowired
private StudentMapper studentMapper;
@Test
void importData() throws IOException {
// 从数据库中得到数据
List<Student> students = studentMapper.getAll();
// bulk 导入
BulkRequest bulkRequest = new BulkRequest();
// 循环 students,创建 indexRequest 添加数据
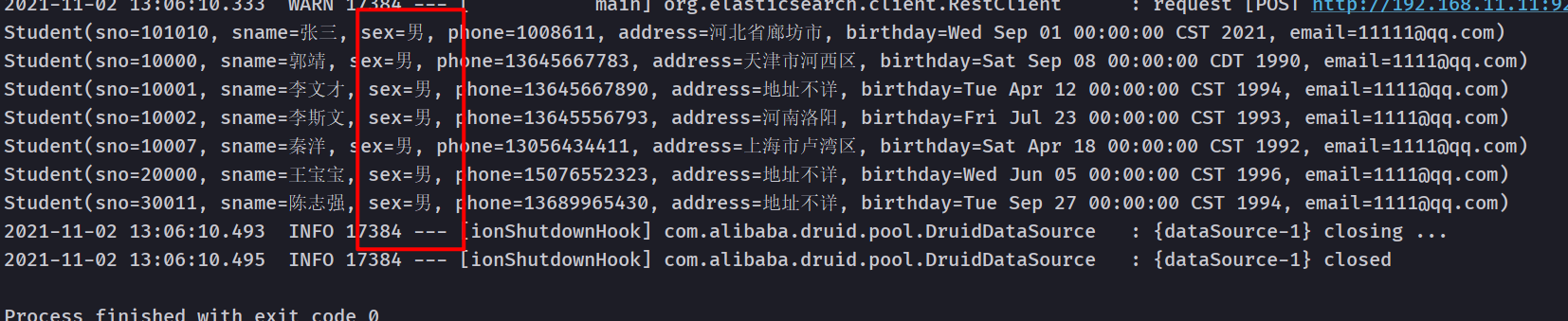
for (Student student : students) {
student.setEmail("1111@qq.com");
IndexRequest indexRequest = new IndexRequest("students");
indexRequest.id(student.getSno() + "").source(JSON.toJSONString(student), XContentType.JSON);
bulkRequest.add(indexRequest);
}
client.bulk(bulkRequest,RequestOptions.DEFAULT);
}
- 批量添加到 ES 中

6.3 各种查询
6.3.1 matchAll 查询-脚本
查询所有文档
# 默认情况下 ES 一次展示10 条数据
# from 从 0 号记录开始,size 表示每页展示 20 条
GET students/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 20
}
# 查询的结果
{
"took" : 2, # 查询的时间,第一次较慢,第二次变快,因为有缓存
"timed_out" : false, # 超时
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : { # 命中的条数
"total" : {
"value" : 14,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [ # 命中的记录数组
{
"_index" : "students",
"_type" : "_doc", # 文档类型
"_id" : "1", # 文档的唯一标识
"_score" : 1.0,
"_source" : {
"sno" : 101010,
"sname" : "张三",
"sex" : "男",
"phone" : "1008611",
"address" : "河北省廊坊市",
"birthday" : "2021-09-01",
"email" : "11111@qq.com"
}
},
{
6.3.2 term 查询
脚本操作
不会对查询条件进行分词
# term 查询,不分词查询
GET students/_search
{
"query": {
"term": {
"sex": {
"value": "男"
}
}
}
}

Java API 操作
/**
* 词条查询
*/
@Test
void testTermQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryBuilder query = QueryBuilders.termQuery("sex","男");// term 词条查询
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
// 获取记录数
long value = searchHits.getTotalHits().value;
SearchHit[] hits = searchHits.getHits();
List<Student> students = new ArrayList<>();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
// 转为 Java 对象
Student student = JSON.parseObject(sourceAsString, Student.class);
students.add(student);
}
students.forEach(System.out::println);
}
6.3.3 match 查询
脚本操作
- 会对查询条件进行分词
- 然后将分词后的查询条件和词条进行等值匹配
- 默认取并集(OR)
GET students/_search
{
"query": {
"match": {
"sex": "男"
}
}
}
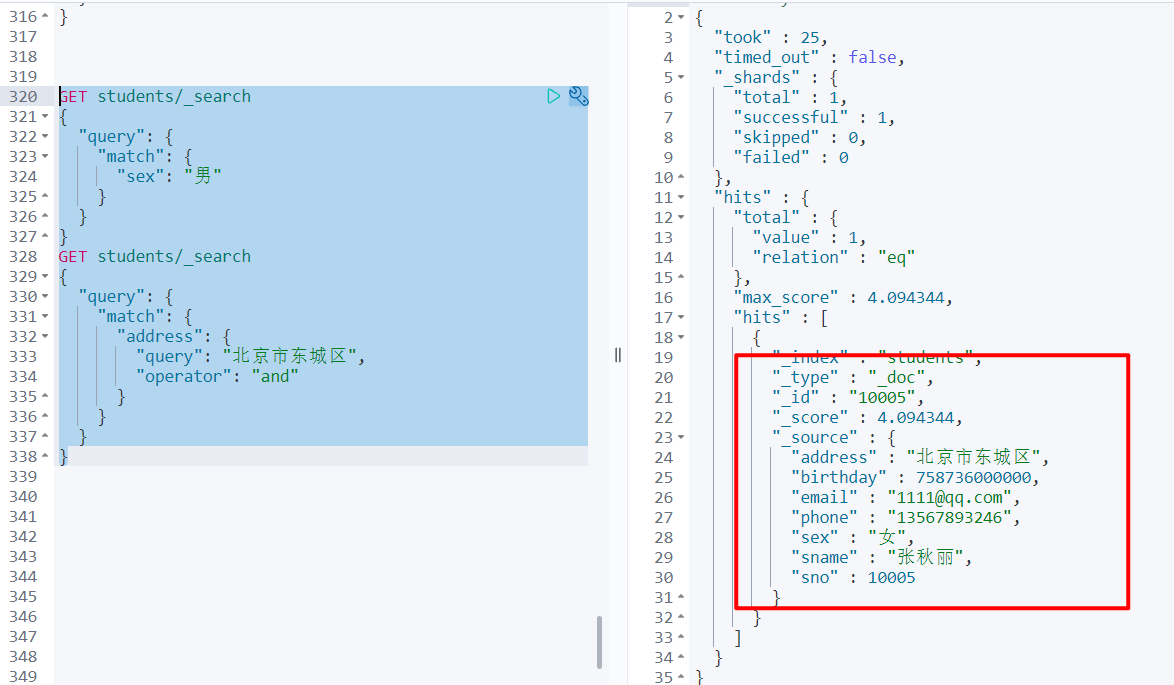
GET students/_search
{
"query": {
"match": {
"address": {
"query": "北京市东城区",
"operator": "and"
}
}
}
}
Java API 操作
/**
* match查询
*/
@Test
void testMatchQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder query = QueryBuilders.matchQuery("address","北京东城区");
query.operator(Operator.OR);// 求交集
sourceBuilder.query(query);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = searchResponse.getHits();
// 获取记录数
long value = searchHits.getTotalHits().value;
SearchHit[] hits = searchHits.getHits();
List<Student> students = new ArrayList<>();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
// 转为 Java 对象
Student student = JSON.parseObject(sourceAsString, Student.class);
students.add(student);
}
students.forEach(System.out::println);
}

6.3.4 模糊查询
脚本操作
wildcard 查询:会对查询条件进行分词,还可以使用通配符 ?(任意单个字符)和 * (0个或多个字符)
regexp 查询:正则查询
prefix 查询: 前缀查询
# wildcard 查询,查询分词条件,模糊查询
GET students/_search
{
"query": {
"wildcard": {
"sname": {
"value": "李?"
}
}
}
}
# 正则查询
GET students/_search
{
"query": {
"regexp": {
"sname": "\\w+(.)*"
}
}
}
# 前缀查询
GET students/_search
{
"query": {
"prefix": {
"sname": {
"value": "张"
}
}
}
}
Java API 操作
- wildcard
/**
* 模糊查询
*/
@Test
void testWildcardQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("sname", "李*");
sourceBuilder.query(wildcardQueryBuilder);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}

- **regexp **
/**
* 正则查询
*/
@Test
void testRegexpQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
RegexpQueryBuilder regexpQuery = QueryBuilders.regexpQuery("address", "\\w+(.)*");
sourceBuilder.query(regexpQuery);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}
- prefix
/**
* 前缀查询
*/
@Test
void testPrefixQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryBuilder queryBuilder = QueryBuilders.prefixQuery("sname", "李");
sourceBuilder.query(queryBuilder);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}

6.3.5 范围查询
脚本操作
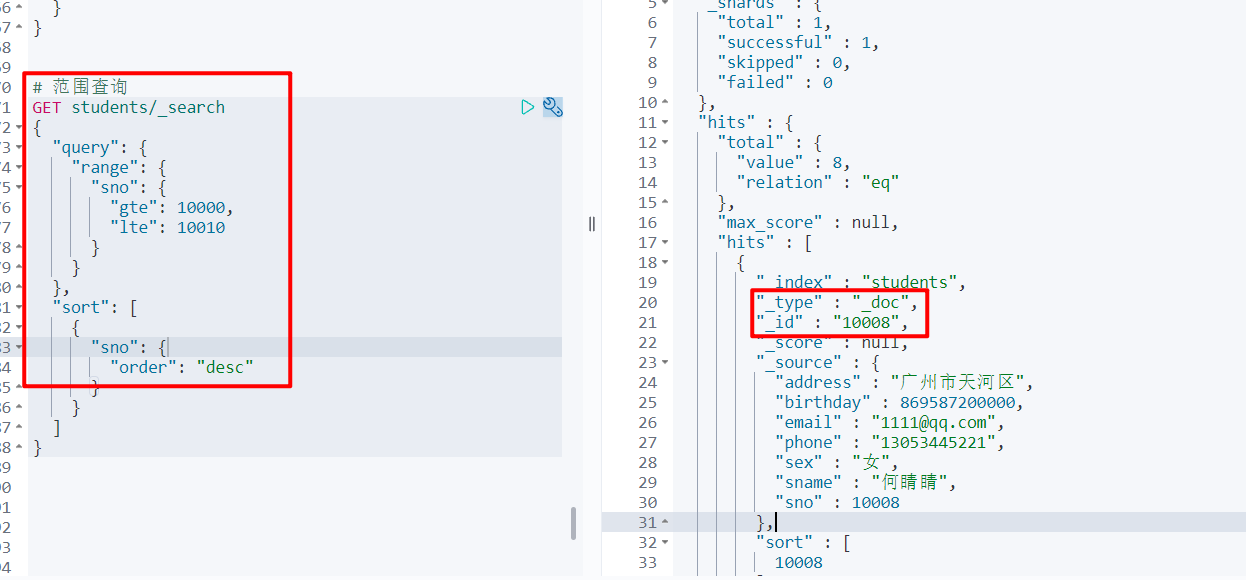
range 范围查询:查找指定字段在指定范围内包含值
# 范围查询
GET students/_search
{
"query": {
"range": {
"sno": {
"gte": 10000,
"lte": 10010
}
}
},
"sort": [
{
"sno": {
"order": "desc"
}
}
]
}
Java API 操作
/**
* 范围查询 range
*/
@Test
void testRangeQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
RangeQueryBuilder query = QueryBuilders.rangeQuery("sno");
// 上限
query.gte(10000);
// 下限
query.lte(10010);
sourceBuilder.query(query);
// 排序
sourceBuilder.sort("sno", SortOrder.DESC);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}

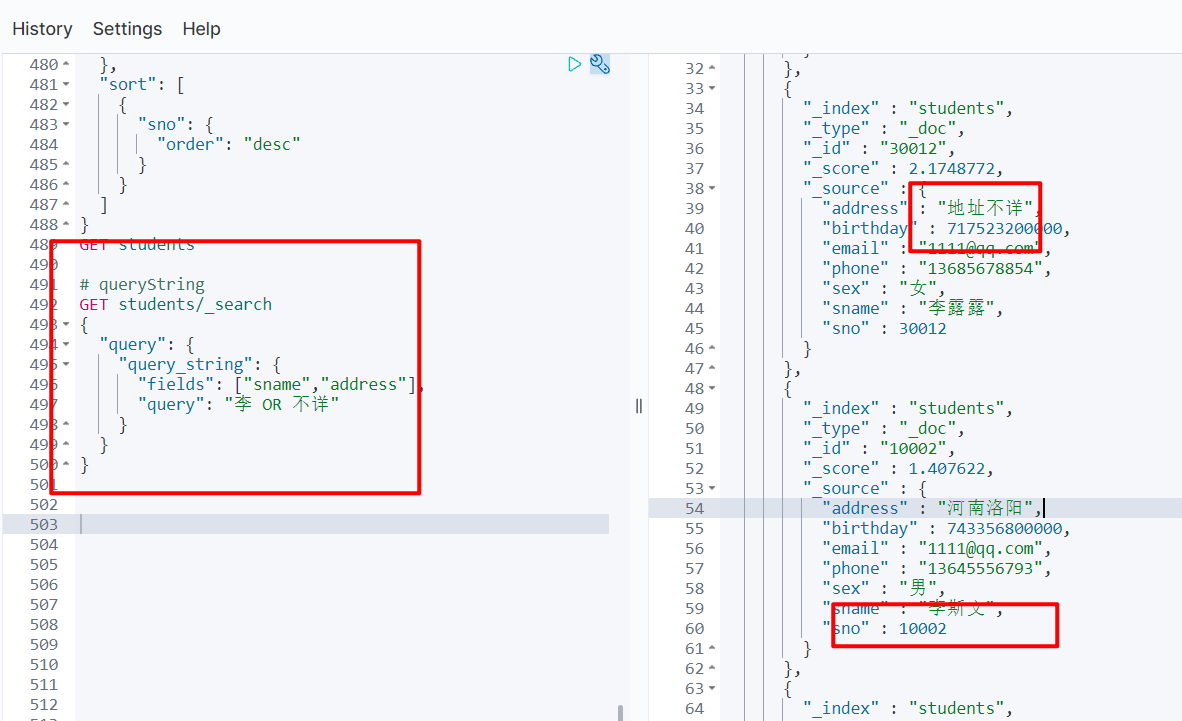
6.3.6 queryString 查询
脚本操作
- 会对查询条件进行分词;然后将分词后的查询条件和词条进行等值匹配;默认取并集(OR);可以指定多个查询字段
# queryString
GET students/_search
{
"query": {
"query_string": {
"fields": ["sname","address"],
"query": "李 OR 不详"
}
}
}
# simple_query_string 与 query_string 的区别,前者不支持在 query 查询条件中写 AND 或 OR
Java API 操作
/**
* queryString
*/
@Test
void testQueryString() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery("李不详")
.field("sname").field("address").defaultOperator(Operator.OR);
sourceBuilder.query(queryStringQueryBuilder);
// 排序
sourceBuilder.sort("sno", SortOrder.DESC);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}

6.3.7 布尔查询
脚本操作
boolQuery:对多个查询条件连接。
- must(and):条件必须成立
- must_not(not):条件必须不成立
- should(or):条件可以成立
- filter:条件必须成立,性能比 must 高,不会计算得分。
# boolquery
GET students/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"sname": {
"value": "李"
}
}
},
{
"term": {
"address": {
"value": "北京"
}
}
}
]
}
}
}

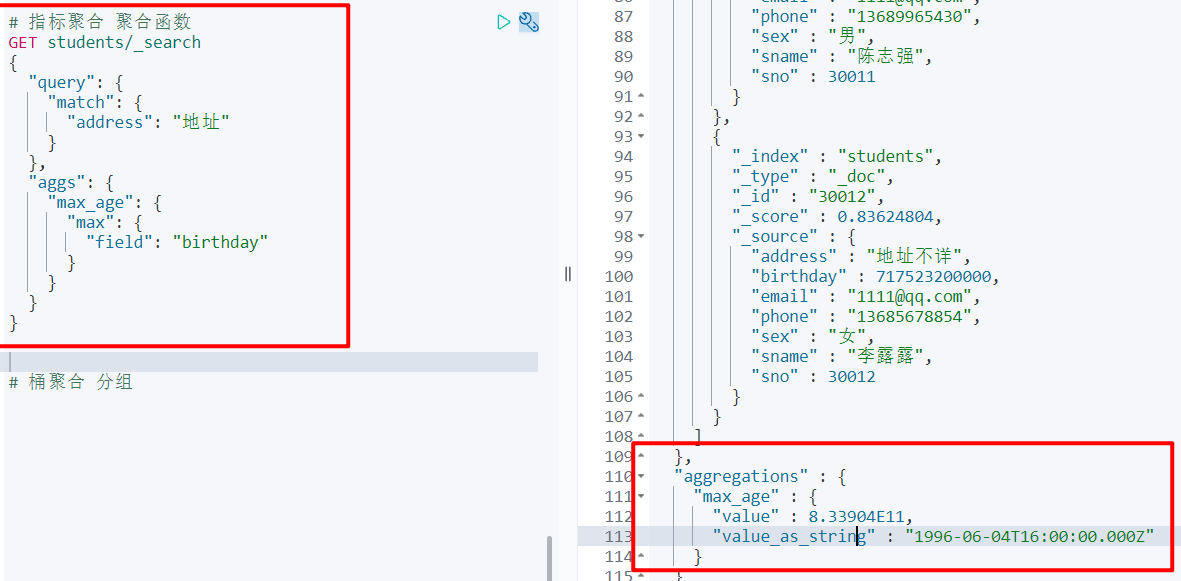
6.3.8 聚合查询
脚本操作
- 指标聚合:相当于 MySQL 的聚合函数,max、min、avg、sum 等
- 桶聚合:相当于 MySQL 的 group by 操作,注意不要对 text 类型的数据进行分组,会失败
# 指标聚合 聚合函数
GET students/_search
{
"query": {
"match": {
"address": "地址"
}
},
"aggs": {
"max_age": {
"max": {
"field": "birthday"
}
}
}
}
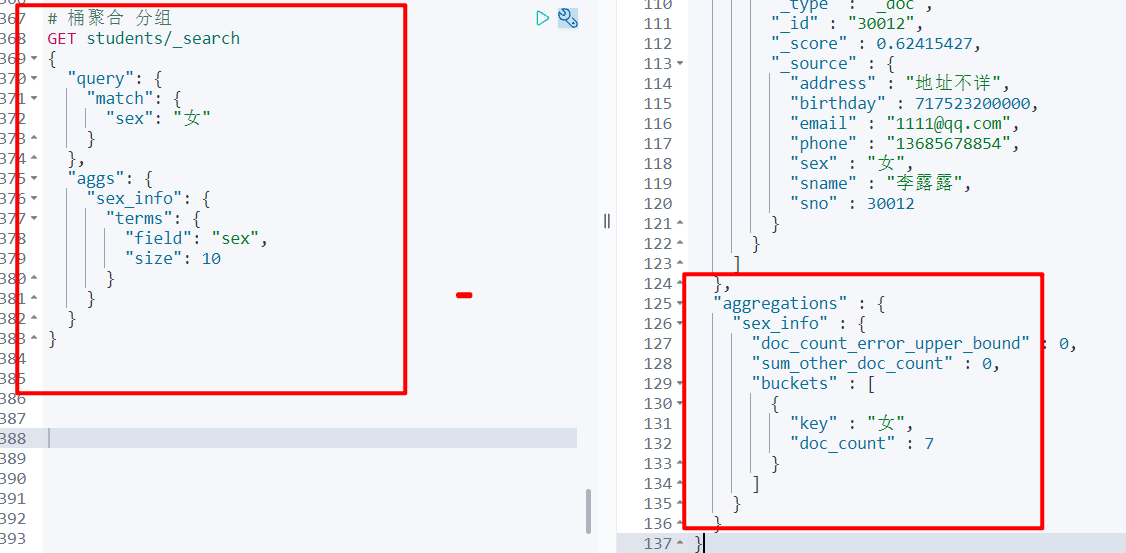
# 桶聚合 分组
GET students/_search
{
"query": {
"match": {
"sex": "女"
}
},
"aggs": {
"sex_info": {
"terms": {
"field": "sex",
"size": 10
}
}
}
}
Java API 操作
/**
* 聚合查询:桶聚合,分组查询
* 1. 查询姓名包含 李 的记录
* 2. 查询性别列表
*/
@Test
void testAggString() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//1. 查询姓名包含 李 的记录
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("sname", "李");
sourceBuilder.query(matchQueryBuilder);
//2. 查询性别列表
/*
参数
1. 自定义的名称,用于获取数据
2. 分组的字段
*/
AggregationBuilder agg = AggregationBuilders.terms("sex_info").field("sex").size(20);
sourceBuilder.aggregation(agg);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = search.getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
// 获取聚合结果
Aggregations aggregations = search.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
Terms sex_info = (Terms) aggregationMap.get("sex_info");
List<? extends Terms.Bucket> buckets = sex_info.getBuckets();
List brands = new ArrayList();
for (Terms.Bucket bucket : buckets) {
Object key = bucket.getKey();
brands.add(key);
}
brands.forEach(System.out::println);
}

6.3.9 高亮查询
脚本操作
# 高亮查询
GET students/_search
{
"query": {
"match": {
"sname": "李"
}
},
"highlight": {
"fields": {
"sname": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>"
}
}
}
}
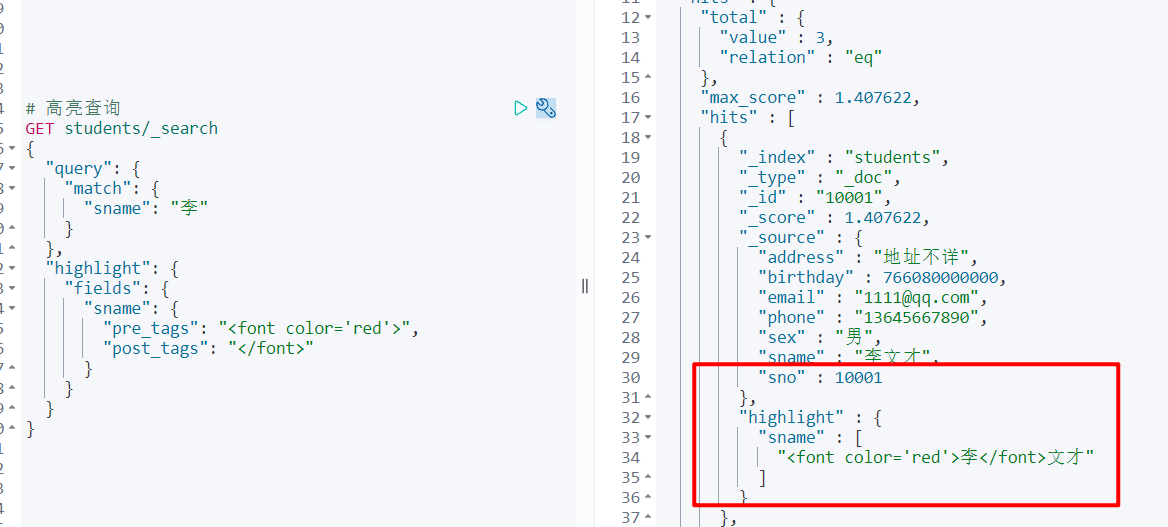
Java API 操作
/**
* 1. 高亮查询
* 高亮字段
* 前缀
* 后缀
* 2. 将高亮的字段数据,替换原来的数据
*/
@Test
void testHightLightString() throws IOException {
SearchRequest searchRequest = new SearchRequest("students");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//1. 查询姓名包含 李 的记录
MatchQueryBuilder query = QueryBuilders.matchQuery("sname", "李");
sourceBuilder.query(query);
// 设置高亮
HighlightBuilder hightlighter = new HighlightBuilder();
// 设置三要素
hightlighter.field("sname");
hightlighter.preTags("<font color='red'>");
hightlighter.postTags("</font>");
sourceBuilder.highlighter(hightlighter);
AggregationBuilder agg = AggregationBuilders.terms("sex_info").field("sex").size(20);
sourceBuilder.aggregation(agg);
searchRequest.source(sourceBuilder);
SearchResponse search = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits searchHits = search.getHits();
SearchHit[] hits = searchHits.getHits();
List list = new ArrayList();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
// 转为 Java 对象
Student student = JSON.parseObject(sourceAsString, Student.class);
// 获取高亮结果,替换为 Student 中的 sname
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField hightLightField = highlightFields.get("sname");
Text[] fragments = hightLightField.fragments();
// 替换
student.setSname(fragments[0].toString());
list.add(student);
}
list.forEach(System.out::println);
// 获取聚合结果
Aggregations aggregations = search.getAggregations();
Map<String, Aggregation> aggregationMap = aggregations.asMap();
Terms sex_info = (Terms) aggregationMap.get("sex_info");
List<? extends Terms.Bucket> buckets = sex_info.getBuckets();
List brands = new ArrayList();
for (Terms.Bucket bucket : buckets) {
Object key = bucket.getKey();
brands.add(key);
}
brands.forEach(System.out::println);
}

6.4 索引别名和重建索引
6.4.1 重建索引
随着业务需求的变更,索引的结构可能发生变化。
ES 索引一旦创建,只允许添加字段,不允许改变字段。因为改变字段,需要重建倒排索引,影响内部缓存结构,性能太低。这种情况就需要重建一个新的索引,并将原有索引的数据导入到新索引中。

# 重建索引
# 新建student_index_v1 索引名称必须全部小写
PUT student_index_v1
{
"mappings": {
"properties": {
"birthday":{
"type": "date"
}
}
}
}
GET student_index_v1
PUT student_index_v1/_doc/1
{
"birthday":"2021-11-03"
}
# 上面的添加文档是成功的,但是随着业务的变更需要变成 2021年11月03日,在用这种方式添加就会报错了,所以需要将这个date 类型换成 text 类型
# 1. 创建一个新的索引 student_index_v2;
PUT student_index_v2
{
"mappings": {
"properties": {
"birthday": {
"type": "text"
}
}
}
}
GET student_index_v2
# 2. 将 v1 的数据拷贝到 v2
# _reindex 拷贝数据
POST _reindex
{
"source": {
"index": "student_index_v1"
},
"dest": {
"index": "student_index_v2"
}
}
PUT student_index_v2/_doc/2
{
"birthday": "2021年11月3日"
}
# 在 java 代码中操作的是 es 的老的索引名称v1
# 解决1,修改 java 代码,不推荐的
# 解决2,索引别名
# 步骤:
# 1. 删除 v1
DELETE student_index_v1
# 2. 给 v2 索引起个别名 v1
POST student_index_v2/_alias/student_index_v1
GET student_index_v2/_search
7. ElasticSearch 集群
7.1 ES 集群介绍
集群和分布式:
- 集群:多个人做一样的事,解决的问题:让系统高可用,分担请求压力(负载均衡)
- 分布式:多个人做不一样的事,解决问题:分担存储和计算的压力,提速,解耦操作
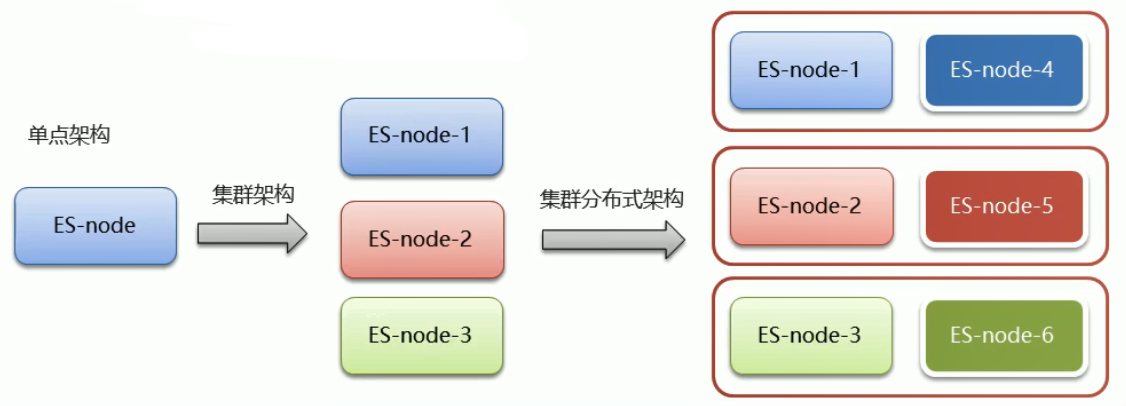
ES 集群特点:
- ES 天然支持分布式
- ES 的设计隐藏了分布式本身的复杂性
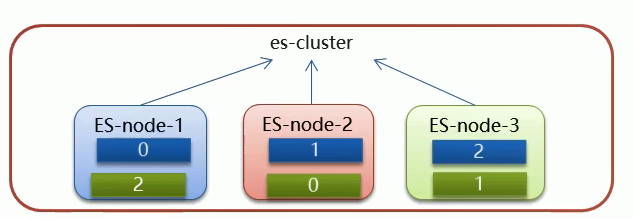
7.2 ES 集群分布式架构相关概念
- 集群(cluster):一组拥有共同的 cluster name 的节点
- 节点(node):集群中的一个 ES 实例
- 索引(index):es 存储数据的地方。相当于关系数据库中的 database 概念
- 分片(shard):索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
- 主分片(Primary shard):相当于副本分片的定义
- 副本分片(Replica shard):每个分片可以有一个或者多个副本,数据和主分片一样。
7.3 ES 集群搭建
ES 如果做集群的话 Master 节点至少三台服务器或者三个 Master 实例加入相同的集群,三个 Master 节点最多只能故障一台 Master 节点,如果故障两个 Master 节点,ES 将无法组成集群会报错,Kibana 也无法启动,因为 Kinaba 无法获取集群中的节点信息。
这里只使用一台虚拟机,所以在虚拟机中安装三个 ES 实例,搭建伪集群,所以把虚拟机设置内存 4G,CPU 个数 4 个
步骤:
拷贝 /opt 目录下的 elasticsearch-7.15.0 安装包 3 个,分别命名:
- elasticsearch-7.15.0-es1
- elasticsearch-7.15.0-es2
- elasticsearch-7.15.0-es3
配置三个节点
- 创建日志目录
cd /opt
mkdir logs
mkdir data
# 授权给 lss 用户
chown -R lss:lss ./logs
chown -R lss:lss ./data
chown -R lss:lss ./elasticsearch-7.15.0-es1
chown -R lss:lss ./elasticsearch-7.15.0-es2
chown -R lss:lss ./elasticsearch-7.15.0-es3
- 分别修改 elasticsearch.yml 配置,分别配置三个节点的配置文件
vim /opt/elasticsearch-7.15.0-es1/config/elasticsearch.yml
vim /opt/elasticsearch-7.15.0-es2/config/elasticsearch.yml
vim /opt/elasticsearch-7.15.0-es3/config/elasticsearch.yml
# es1
# 集群名称
cluster.name: lss-es
# 节点名称
node.name: es-1
# 是不是有资格作为主节点
node.master: true
# 是否存储数据
node.data: true
# 最大集群节点数
node.max_local_storage_nodes: 3
# ip 地址
network.host: 0.0.0.0
# 端口
http.port: 9201
# 内部节点之间沟通端口
transport.tcp.port: 9700
# es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["localhost:9700","localhost:9800","localhost:9900"]
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["es-1","es-2","es-3"]
# 数据和日志存储路径
path.data: /opt/data
path.logs: /opt/logs
# es2 es3 与之类似
cluster.name: lss-es
node.name: node-1
node.master: true
node.data: true
node.max_local_storage_nodes: 3
network.host: 0.0.0.0
http.port: 9201
transport.tcp.port: 9700
discovery.seed_hosts: ["192.168.11.129:9700","192.168.11.130:9800","192.168.11.131:9900"]
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
path.data: /opt/data
path.logs: /opt/logs
-
上面的配置后就可以启动
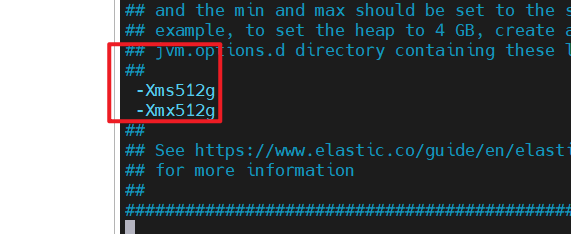
启动前配置一下,设置 ES 的 JVM 占用内存参数,防止内存不足失败
vim /opt/elasticsearch-7.15.0-es1/config/jvm.options # 修改这个文件
启动 3 个节点
启动后访问地址:http://192.168.11.11:9201/_cat/health?v 可以看到集群信息

# 健康状态结果
cluster 集群名称
status 集群状态
green 表示健康
yellow 表示分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整
red 表示部分主分片不可用,可能已经丢失数据
node.total 代表在线的节点总数量
node.data 代表在线的数据节点的数量
shards 存活的分片数量
pri 存活的主分片数量,正常情况下,shards 的数量是 pri 的两倍
relo 迁移中的分片数量,正常情况下为 0
init 初始化中的分片数量,正常情况为 0
unassign 未分配的分片,正常情况为 0
pending_tasks 准备中的任务,任务指迁移分片等,正常情况为 0
max_task_wait_time 任务最长等待时间
active_shards_percent 正常分片百分比,正常情况为 100%
7.4 Kibana 集群配置和管理
之前单机使用的时候用到 Kibana,先复制出来一个,然后修改它的集群配置
cd /opt/
cp -R kibana-7.15.0 kibana-7.15.0-cluster
# kibana 中文件多,需要等待时间较长
修改 Kibana 的集群配置
vim /opt/kibana-7.15.0-cluster/kibana-7.15.0/config/kibana.yml
# 修改内容
elasticsearch.hosts: ["http://127.0.0.1:9201","http://localhost:9202","http://localhost:9203"]
启动 Kibana
cd /opt/kibana-7.15.0-cluster/kibana-7.15.0/bin
./kibana --allow-root
这块集群搭建的 有问题,但是步骤是对的,可能换个环境的话会成功
7.5 Java API 访问集群
- 修改配置类
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private int port;
@Value("${elasticsearch.host2}")
private String host2;
@Value("${elasticsearch.port2}")
private int port2;
@Value("${elasticsearch.host3}")
private String host3;
@Value("${elasticsearch.port3}")
private int port3;
@Bean(value = "client")
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient(RestClient.builder(
new HttpHost(host, port, "http"),
new HttpHost(host2,port2,"http"),
new HttpHost(host3,port3,"http"))
);
}
}
- 修改 yml 配置文件
elasticsearch:
host: 192.168.11.11
port: 9700
host2: 192.168.11.11
port2: 9800
host3: 192.168.11.11
port3: 9800
-
新建一个索引
-
测试
/**
* 通过集群的方式访问 es
*/
@Test
public void testCluster() throws IOException {
GetRequest request = new GetRequest("test_index");
//设置查询的 id
request.id("1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
使用Java 操作集群和单机没有太大的区别
7.6 分片配置
在创建索引的时候,如果不指定分片配置,则默认主分片1 ,副本分片 1
在创建索引的时候可以通过 setting 来设置分片
分片与自平衡:当节点挂掉后,挂掉的节点分片会自动平衡到其他节点上
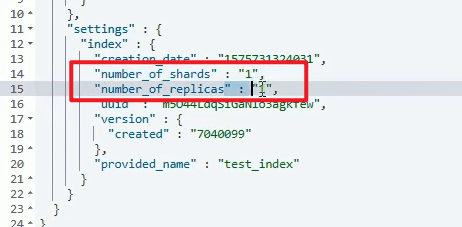
创建索引的时候设置分片信息
GET test_index
# 创建索引,设置分片,一共会有 6 个分片,
PUT test_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"type": "text"
}
}
}
}
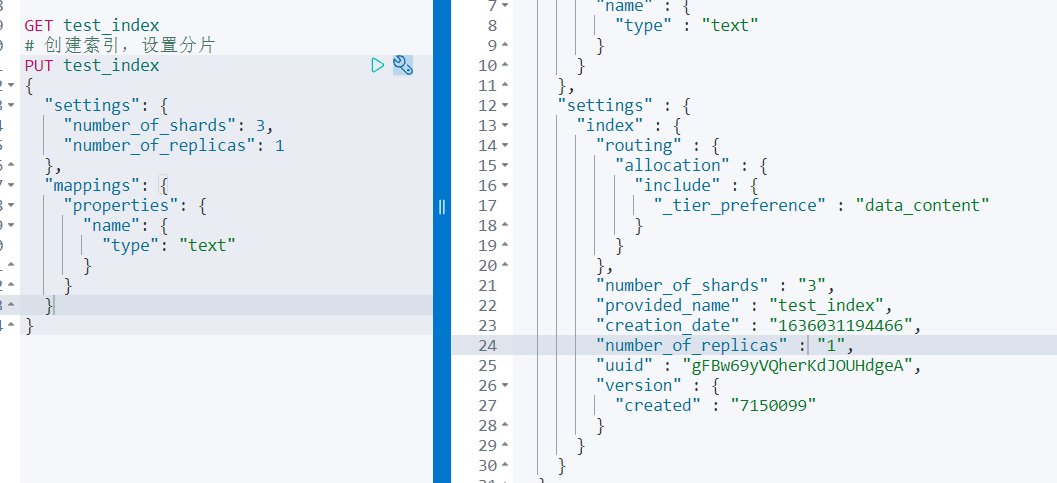
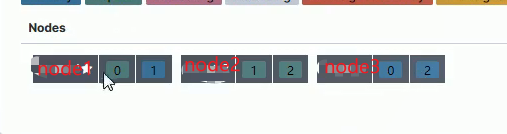
停掉了 node2 节点,又会进行重新划分
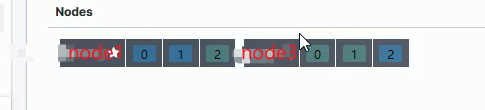
在 ES 中,每个查询在每个分片的单线程中执行,但是,可以并行处理多个切片。
分片数量一旦确定好,不能进行修改
索引分片推荐方案:
- 每个分片推荐大小 10G ~ 30G
- 分片数量推荐 = 节点数量 * 1 ~ 3 倍
假如有 10000G 数据,每个分片推荐大小 25G,需要 40个分片,需要20个节点
7.7 路由原理
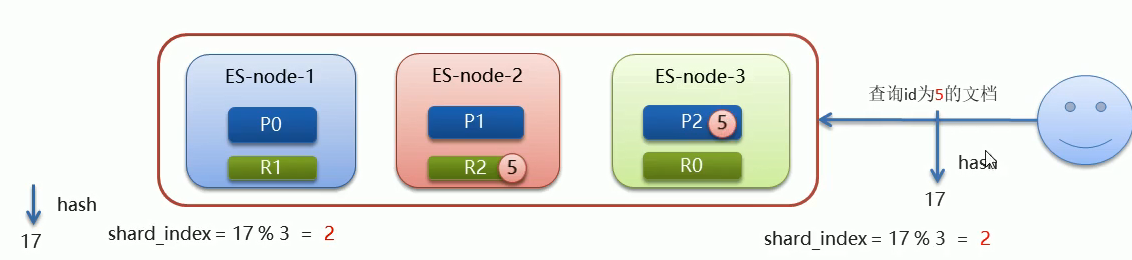
文档存入对应的分片,ES 计算分片编号的过程,称为路由。
问题:ES 是怎么知道一个文档应该存放到那个分片中呢?查询时,根据文档id查询文档,ES 又该去哪个分片中查询数据?
路由算法:shard_index = hash(id) % number_of_primary_shards
-
shard_index :需要计算分片对应的一个索引
-
hash(id) :id 指的是文档id,使用 hash 算法
-
number_of_primary_shards:主分片的数量

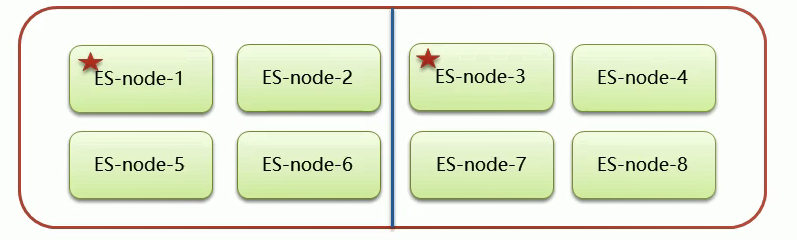
7.8 脑裂
一个正常 es 集群中只有一个主节点(Master),主节点负责管理整个集群,如创建或删除索引,跟踪那些节点是集群的一部分,并决定哪些分片分配给相关的节点。
集群的所有节点都会选择同一个节点作为主节点。
脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态。
下图中出现两个主节点,分裂成了两个集群
脑裂产生的原因
-
网络的原因:网络延迟
- 一般 es 集群会在内网部署,也可能在外网部署,比如阿里云。
- 内网一般不会出现此问题,外网出现此问题的可能性较大
-
节点负载
- 节点的角色既为 master 又为 data,数据访问量较大时,可能会导致 Master 节点停止响应(假死状态)。
-
JVM 内存回收
- 当 Master 节点设置的 JVM 内存较小时,引发 JVM 的大规模内存回收,造成 ES 进程失去响应。
避免脑裂
-
网络原因:discovery.zen.ping.timeout 超时时间配置大一点,默认是 3S
-
节点负载:角色分离策略:
- 候选节点配置为:
- node.master: true;
- node.data: false
- 数据节点配置为:
- node.master: false
- node.data: true
- 候选节点配置为:
-
JVM 内存回收:修改 config/jvm.options 文件的 -Xms 和 -Xms 为服务器的内存一半
**学习参考视频地址:**https://www.bilibili.com/video/BV1Sy4y1G7LL?p=1














 2545
2545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









