






本篇文章将介绍lnk文件的一些主要结构并使用C++实现读取lnk目标文件的路径
末尾附有源码
.lnk文件结构
因为我们的需求只有读取lnk的目标文件的路径,所以不需要了解lnk文件所有的结构
(想了解lnk文件具体有哪些结构,可以参考微软文档 [MS-SHLLINK]:Structures )
因此,我们需要了解的结构有:SHELL_LINK_HEADER, LINKTARGET_IDLIST
SHELL_LINK_HEADER
SHELL_LINK_HEADER,lnk文件头,是每个.lnk文件都会有的结构,主要包含一些识别信息,具体结构如下
typedef struct _tagLinkFileHeader {
DWORD HeaderSize; //文件头的大小
GUID LinkCLSID; //CLSID
DWORD Flags; //lnk文件标志
DWORD FileAttributes; //文件属性(目标文件的)
FILETIME CreationTime; //创建时间(目标文件的)
FILETIME AccessTime; //访问时间
FILETIME WriteTime; //修改时间
DWORD FileSize; //文件大小
DWORD IconIndex;
DWORD ShowCommand; //显示方式
WORD Hotkey; //热键
BYTE retain[10]; //保留的10byte数据
}LINKFILE_HEADER, * LPLINKFILE_HEADER;大小为76字节
只需要向文件无脑读取76字节就可以完美读取出来了。 这个结构中我们只需要用到Flags变量,结构可以参考微软文档 [MS-SHLLINK]:LinkFlags
其它的就不做介绍了,很简单
LINKTARGET_IDLIST
LINKTARGET_IDLIST结构是一个可选结构,具体定义如下
typedef struct _tagLinkTagrgetIDList {
WORD IDListSize;
ITEMID* sIDList;
WORD TerminalID;
}LINK_TARGET_ID_LIST, IDLIST;绝大多数lnk文件都会有这个结构,因为目标文件的完整路径就藏在这个结构里,本篇文章读取lnk目标文件路径的前提就是存在这个结构。如何证明文件中是否存在该结构呢?这就需要用到刚才讲到的Flags了,当读取完lnk文件头后Flags里就会有一个32位数据,当第一位为1时就说明 LinkTargetIDList 结构存在,为0就不存在,因此我们可以通过Flags第一位来判断该结构是否存在
可能很多人都会有疑问:ITEMID是什么类型?
ItemID结构如下
typedef struct _tagLinkItemID {
WORD Size;
BYTE* Data;
}ITEMID, * LPITEMID;我们需要了解ItemID是干什么的。lnk文件生成时若有LinkTargetIDList结构,则会将目标文件的路径拆分成多个文件或文件夹名称分别存入ItemID中,比如现在有一个lnk文件指向本机的C:\Windows\explorer.exe路径下,其完整路径其实是 CLSID_MyComputer\C:\Windows\explorer.exe (具体可以使用010 Editor查看任意lnk文件),之后系统就会将其各级目录名称拆出来,分别是 CLSID_MyComputer,C:\,Windows,explorer.exe,然后就会将它们按文件类型分类,存入ItemID中的Data里并附加一些详细信息
在一个LinkTargetIDList里可能会存在多个ItemID结构,所以使用ItemID*声明
现在还没完,我们还没有了解Data里的数据
Data里的第1个字节数据是该级文件或文件夹类型,低四位表示当前一级目录是什么类型(根或盘符或文件或等其它的),高四位不用管,接下来Data的数据结构就是通过这个类型来确定的,而目录名称等重要信息就存储在里面
可能很多人读到这里一头雾水,我举个例子说一下,并具体介绍Data
假设现在有一个lnk文件,指向的目标文件是D:\Apps\App.exe且存在LinkTargetIDList结构
1.我们先无脑读取76字节获取文件头
2.判断lnk文件头结构中的Flags的第一位是否为1,因为存在LinkTargetIDList结构所以Flags的第一位是为1
3.我们读取2个字节以获取LinkTargetIDList总大小
4.继续读取2字节获取ITEMID大小,若大小为0,说明读取到TerminaID,跳到第8步
5.继续读取1字节,设其内容存储在类型为BYTE的变量Type中,则Type的低四位表示当前一级目录是什么类型,高四位不用去管
6.判断Type低四位类型并解析
(例:若Type低四位为2(VOLUME),代表它是一个卷,接下来的所有数据都是一个char*字符串,内容为一个盘符,包含反斜杠)
7.回到第4步
8.结束(忽略后面的其他结构)
关于Type低四位各值代表什么意思:
当其等于1时,代表它是一个根(ROOT),需要向后读17个字节,其中第一个字节我也不太了解,
当其等于80时代表本机(MY_COMPUTER),是放在目标文件路径最开始的盘符前面的,比如MY_COMPUTER\D:\Apps\App.exe,后面16个字节是一个GUID,不需要管它
当其等于2时,代表它是一个卷(VOLUME),像C:\,D:\这样的叫做卷,接下来的所有数据都是一个char*字符串,内容为一个盘符(包含反斜杠"\")
当其等于3时,代表它是一个文件或文件夹(FILE),设当前ITEMID大小为 szItemID, 则需要向后读取 (szItemID-3) 个字节。
其中第一个字节固定为0,
2~5字节(向后4个字节)表示该文件大小,若是一个文件夹则该值为0,
6~9字节(向后4个字节)表示一个时间,不需要知道用处
7~8字节(向后2个字节)表示文件或文件夹属性,
9字节后就是一个char*类型的文件或文件夹的字符串,遇到结束符('\0')结束,假设读取了n字节
(9+n-1)字节之后的就是额外数据了,暂且不需要了解,额外数据大小计算公式为 ExtraDataBlockSize = szItemID - 14 - n
代码实现
我们可以创建一个类LnkReader,输入lnk文件路径,通过另一个成员方法获取路径
先将基础代码写好,为了方便我打算直接将实现代码写在头文件里
//LnkReader.h
#include <Windows.h>
#include <assert.h>
#include <iostream>
#include <fstream>
#include <unordered_map>
using namespace std;
class LnkReader {
public:
LnkReader() = default;
private:
};
//main.cpp
#include "LnkReader.h"
int main()
{
return 0;
}
准备工作
(若觉得繁琐可直接跳到完整代码处)
lnk文件结构准备
我们只要用到三种数据结构
...
class LinkFileReader {
public:
typedef struct _tagLinkFileHeader {
DWORD HeaderSize; //文件头的大小
GUID LinkCLSID; //CLSID
DWORD Flags; //lnk文件标志
DWORD FileAttributes; //文件属性(目标文件的)
FILETIME CreationTime; //创建时间(目标文件的)
FILETIME AccessTime; //访问时间
FILETIME WriteTime; //修改时间
DWORD FileSize; //文件大小
DWORD IconIndex;
DWORD ShowCommand; //显示方式
WORD Hotkey; //热键
BYTE retain[10]; //保留的10byte数据
}LINKFILE_HEADER, *LPLINKFILE_HEADER;
typedef struct _tagLinkItemID {
WORD wSize;
BYTE bType;
BYTE* bData;
inline int getTypeData() { return (bType & 0xFL); }; //获取bType低四位
inline int getListType() { return ((bType & 0xF0L) >> 4); }; //获取bType高四位
}ITEMID, *LPITEMID;
public:
...ITEMID被我加了两个方法便于获取bType的低四位和高四位
接下来我们可以再增加一个结构用来区分各级目录类型
...
}ITEMID, *LPITEMID;
typedef struct _tagItemType {
static const BYTE ROOT = 1;
static const BYTE VOLUME = 2;
static const BYTE FILE = 3;
}ITEM_TYPE;
public:
...这样能使代码更加美观易懂。
接下来直到开始读取的一切封装操作只是为了使代码美观易懂
为了方便错误提示,我们可以自己写一个简单的断言(assert)。
...
private:
fstream lnkFile; //文件流
//自己写的断言
void Assert(bool condition, string description)
{
if (condition)
{
MessageBoxA(0, description.c_str(), "Error", MB_ICONERROR);
throw "assert.";
}
}
...该方法一旦接收的condition参数为true,就弹窗提示并抛出错误,比较简略。
我们需要封装seekg方法,为了美观awa
若不知道seekg等方法还请学习一下C++的fstream,相信有win32编程基础的人都能看懂
...
#include <fstream>
#include <unordered_map>
#define LNK_SEEK_BEG 1
#define LNK_SEEK_END 2
#define LNK_SEEK_CUR 3
using namespace std;
...
private:
fstream lnkFile;
//自己写的断言
void Assert(bool condition, string description)
{
if (condition)
{
MessageBoxA(0, description.c_str(), "Error", MB_ICONERROR);
throw "assert.";
}
}
//跳过数据
void seek(DWORD point, int offset)
{
switch (point)
{
case LNK_SEEK_BEG: //跳到开头进行偏移
lnkFile.seekg(offset, ios::beg);
break;
case LNK_SEEK_CUR: //当前位置进行偏移
lnkFile.seekg(offset, ios::cur);
break;
case LNK_SEEK_END: //结束位置进行偏移
lnkFile.seekg(offset, ios::end);
default:
break;
}
}
...tellg方法同样简单封装一下
...
//跳过数据
void seek(DWORD point, int offset)
...
//获取指针当前的位置
LONGLONG tell()
{
return lnkFile.tellg();
}
...以十六进制打开文件后需要用read方法读取十六进制数据,为了让代码更美观通用,我们可以将read方法简单封装一下
...
//获取指针当前的位置
LONGLONG tell()
{
return lnkFile.tellg();
}
...
//读取数据
void read(PVOID pData, int szCount)
{
lnkFile.read((char*)pData, szCount);
}
...我们还想让它实现一个功能:当pData输入为nullptr时,就跳过要求读取的字节数,因此我们可以这么改
...
//读取数据
void read(PVOID pData, int szCount)
{
if (pData == nullptr)
seek(LNK_SEEK_CUR, szCount); //跳过字节
else
lnkFile.read((char*)pData, szCount);
}
...我们还需要一个初始化内存(填充0)的方法memzero,其实就是封装了一下ZeroMemory宏
...
//读取数据
void read(PVOID pData, int szCount)
...
//初始化内存
void memzero(PVOID pDst, int iSize)
{
ZeroMemory(pDst, iSize);
}
...还记得我们在介绍LINKTARGET_IDLIST结构时说的一句话吗
“......9字节后就是一个char*类型的文件或文件夹的字符串,遇到结束符(‘\0’)结束......”
我们现在就需要实现这么一个方法,使其在文件流中取出一个以'\0'结尾的字符串
...
//初始化内存
void memzero(PVOID pDst, int iSize)
{
ZeroMemory(pDst, iSize);
}
//从数据流中获取一个完整的字符串, 返回字符长度(包括结束符)
int getstring(string& src)
{
src = "";
int n = 0;
for (char ch[2] = "";; n++)
{
read(ch, 1);
if (ch[0] == '\0')
break;
src += string(ch);
}
return n + 1;
}
...都很简单,就不过多赘述了
完整代码
现在完整代码应该长这样
#include <Windows.h>
#include <assert.h>
#include <iostream>
#include <fstream>
#include <unordered_map>
#define LNK_SEEK_BEG 1
#define LNK_SEEK_END 2
#define LNK_SEEK_CUR 3
using namespace std;
class LnkReader {
public:
typedef struct _tagLinkFileHeader {
DWORD HeaderSize; //文件头的大小
GUID LinkCLSID; //CLSID
DWORD Flags; //lnk文件标志
DWORD FileAttributes; //文件属性(目标文件的)
FILETIME CreationTime; //创建时间(目标文件的)
FILETIME AccessTime; //访问时间
FILETIME WriteTime; //修改时间
DWORD FileSize; //文件大小
DWORD IconIndex;
DWORD ShowCommand; //显示方式
WORD Hotkey; //热键
BYTE retain[10]; //保留的10byte数据
}LINKFILE_HEADER, * LPLINKFILE_HEADER;
typedef struct _tagLinkItemID {
WORD wSize;
BYTE bType;
BYTE* bData;
inline int getTypeData() { return (bType & 0xFL); };
inline int getListType() { return ((bType & 0xF0L) >> 4); };
}ITEMID, * LPITEMID;
typedef struct _tagItemType {
static const BYTE ROOT = 1;
static const BYTE VOLUME = 2;
static const BYTE FILE = 3;
}ITEM_TYPE;
public:
LnkReader() = default;
private:
fstream lnkFile;
//自己写的断言
void Assert(bool condition, string description)
{
if (condition)
{
MessageBoxA(0, description.c_str(), "Error", MB_ICONERROR);
throw "assert.";
}
}
//跳过数据
void seek(DWORD point, int offset)
{
switch (point)
{
case LNK_SEEK_BEG: //跳到开头进行偏移
lnkFile.seekg(offset, ios::beg);
break;
case LNK_SEEK_CUR: //当前位置进行偏移
lnkFile.seekg(offset, ios::cur);
break;
case LNK_SEEK_END: //结束位置进行偏移
lnkFile.seekg(offset, ios::end);
default:
break;
}
}
//获取指针当前的位置
LONGLONG tell()
{
return lnkFile.tellg();
}
//读取数据
void read(PVOID pData, int szCount)
{
if (pData == nullptr)
seek(LNK_SEEK_CUR, szCount); //跳过字节
else
lnkFile.read((char*)pData, szCount);
}
//初始化内存
void memzero(PVOID pDst, int iSize)
{
ZeroMemory(pDst, iSize);
}
//从数据流中获取一个完整的字符串, 返回字符长度(包括结束符)
int getstring(string& src)
{
src = "";
int n = 0;
for (char ch[2] = "";; n++)
{
read(ch, 1);
if (ch[0] == '\0')
break;
src += string(ch);
}
return n + 1;
}
};
开始读取
我们需要先打开一个lnk文件,可以定义一个方法run传入lnk路径并开始解析lnk文件
...
public:
LnkReader() = default;
int run(string stLnkPath)
{
return 0;
}
private:
fstream lnkFile; //文件流
...然后我们使用fstream以二进制只读的方式打开文件流
...
int run(string stLnkPath)
{
lnkFile.open(stLnkPath, ios::in | ios::binary); //以二进制只读的方式打开文件流
if (!lnkFile.is_open())
return -1; //打开失败,返回-1
return 0;
}
...读取成功后我们先获取文件大小,若文件大小还没有一个lnk文件头大(文件大小不足76 bytes),说明文件一定出错了
...
if (!lnkFile.is_open())
return -1; //打开失败,返回-1
//获取文件大小
seek(LNK_SEEK_END, 0); //先跳到结束的位置
tagFileSize = tell(); //通过tell获取文件大小
seek(LNK_SEEK_BEG, 0); //再跳到开头
if (tagFileSize < (LONGLONG)sizeof(LINKFILE_HEADER))
{
return -2;//文件大小甚至没有一个lnk文件头大, 很明显文件错误
}
return 0;
...接着我们就需要检验该文件是否为lnk文件,一个文件的开头前四个字节若为0x4c则该文件为lnk文件
...
if (tagFileSize < (LONGLONG)sizeof(LINKFILE_HEADER))
{
return -2;//文件大小甚至没有一个lnk文件头大, 很明显文件错误
}
//读取4个字节判断是否是lnk类型文件
read(&lnkHeader.HeaderSize, 4);
if (lnkHeader.HeaderSize != 0x4c)//若不是lnk文件则返回 -2
{
return -2;
}
//移动数据到文件开头的位置, 因为读取文件头4个字节时改变了文件读取的位置
seek(LNK_SEEK_BEG, 0);
return 0;
}
...
private:
fstream lnkFile; //文件流
LONGLONG tagFileSize; //文件大小
LINKFILE_HEADER lnkHeader; //lnk文件头
...接下来我们就可以无脑读取76个字节直接将文件头读出来了
...
//移动数据到文件开头的位置, 因为读取文件头4个字节时改变了文件读取的位置
seek(LNK_SEEK_BEG, 0);
//读取文件头
read(&lnkHeader, sizeof(LINKFILE_HEADER));
return 0;
...我们可以专门写一个方法用来读取 LinkTargetIDList 结构并获取目标文件路径
int getstring(string& src)
...
//读取 LinkTargetIDList 结构并获取目标文件路径
void getLinkTargetIDList()
{
Assert(!(lnkHeader.Flags & 0x1), "The .lnk file doesn't have the HasLinkTargetIDList flag, so we cannot continue.");
int szIDList = 0;
char* buf = NULL;
string path = "";
//读取IDList大小
read(&szIDList, 2);
Assert(szIDList == 0, "Failed to read the IDList size."); //读取IDList大小错误或文件错误
}
...先判断Flags标志的第一位是否为1,若不为1则弹窗提示并抛出异常,然后把要用到的变量先定义好,然后读取IDList的大小,也就是LinkTargetIDList结构的大小,若其大小为0,则引发异常
然后我们就要开始读取每个ItemID并解析出目标文件路径了
...
Assert(szIDList == 0, "Failed to read IDList size."); //读取IDList大小错误或文件错误
//开始读取ItemID并解析目标路径
for (int szCurrent = 0; szCurrent < szIDList - 2;)
{
}
...szCurrent 用来统计已经读取的字节数,规定循环条件为szCurrent不大于szIDList,防止出现一些离谱的错误导致进入死循环
for (int szCurrent = 0; szCurrent < szIDList - 2;)
{
ITEMID ItemID;
read(&ItemID.wSize, 2); //读取大小
if (ItemID.wSize == 0) //判断是否是 TerminallID
break;
read(&ItemID.bType, 1); //读取类型
//判断ItemID类型
switch (ItemID.getListType())
{
default:
Assert(1, "Failed to read ItemID."); //ItemID类型未知
}
szCurrent += ItemID.wSize;
}先创建一个ItemID类型的变量,用来存放读取的ItemID数据
然后读取当前ItemID大小,若大小为0,说明这是TerminalID,读取已完成,调出循环
若大小不为0,则继续读取1字节获取目录类型
ItemID.getListType()获取的是bType的低四位数据,也就是当前一级目录类型,再进行判断,若没有匹配项则引发异常,这个待会再仔细说
最后一句通过累加每次读取的ItemID大小统计已读取的字节数
现在我们开始编写switch里的具体代码
当前目录是根(ROOT)时可以忽略
...
//判断ItemID类型
switch (ItemID.getListType())
{
case ITEM_TYPE::ROOT:
{
//忽略
read(nullptr, ItemID.wSize - 3);
break;
}
default:
Assert(1, "Failed to read ItemID."); //ItemID类型未知
}
...当前目录是卷(VOLUME)时可直接读取剩下的字节作为字符串当做盘符
...
//判断ItemID类型
switch (ItemID.getListType())
{
case ITEM_TYPE::ROOT:
{
//忽略
read(nullptr, ItemID.wSize - 3);
break;
}
case ITEM_TYPE::VOLUME:
{
//读取盘符
char* buf = new char[ItemID.wSize - 3];
memzero(buf, ItemID.wSize - 3);
read(buf, ItemID.wSize - 3);
Assert(!strcmp(buf, ""), "Failed to read dirver letter."); //读取盘符失败
path += string(buf);
break;
}
default:
Assert(1, "Failed to read ItemID."); //ItemID类型未知
}
...当前目录是文件或文件夹(FILE)时
//判断ItemID类型
switch (ItemID.getListType())
{
case ITEM_TYPE::ROOT:
{
//忽略
read(nullptr, ItemID.wSize - 3);
break;
}
case ITEM_TYPE::VOLUME:
{
...
}
case ITEM_TYPE::FILE:
{
int iFileSize = 0;
WORD DosData = 0, DosTime = 0, FileAttributes = 0;
string str = "";
read(nullptr, 1); //跳过未知字节
/* 注:read函数第一个参数填NULL表示向后跳过 szCount 个字节, 相当于 seek(LNK_SEEK_CUR, szCount) ,可以看看read函数具体细节*/
read(&iFileSize, 4); //读取文件大小(暂时不需要)
//读取文件(文件夹)创建日期和时间
read(&DosData, 2);
read(&DosTime, 2);
read(&FileAttributes, 2); //读取文件(文件夹)类型
int reads = getstring(str); //读取文件名称
Assert(str == "", "Failed to read file name."); //读取文件名称失败
path += str + R"(\)";
//read(nullptr, ItemID.wSize - 1 - 4 - 2 - 2 - 2 - reads - 3)
read(nullptr, ItemID.wSize - reads - 14); //暂时不需要额外信息
break;
}
default:
Assert(1, "Failed to read ItemID."); //ItemID类型未知
}
先跳过1个未知字节,再读取4字节获取文件大小,再分别读取2字节获取目标文件创建日期和时间,再再读取2字节获取目标文件的属性,接着调用getstring()从文件流中获取一段字符串作为文件或文件夹名称,再再再拼接到path里
到这里,我们获取lnk目标文件路径的任务也就要完成了,然后我们需要在类中定义一个存放路径的变量
...
private:
fstream lnkFile; //文件流
LONGLONG tagFileSize; //文件大小
LINKFILE_HEADER lnkHeader; //lnk文件头
string tagFilePath; 目标文件全路径
...然后我们再将临时存放路径的变量path里的字符串赋值给tagFilePath就大功告成了!
void getLinkTargetIDList()
{
Assert(!(lnkHeader.Flags & 0x1), "The .lnk file doesn't have the HasLinkTargetIDList flag, so we cannot continue.");
...
for (int szCurrent = 0; szCurrent < szIDList - 2;)
{
...
}
path = path.substr(0, path.size() - 1); //删去最后一个多余的"\"
tagFilePath = path;
}最后我们添加一个返回路径的方法
...
string getPath() { return tagFilePath; }
...现在我在桌面有一个快捷方式,目标文件路径为
"D:\Program Files (x86)\Sublime Text\sublime_text.exe"

用LnkReader试着读取它的目标文件路径
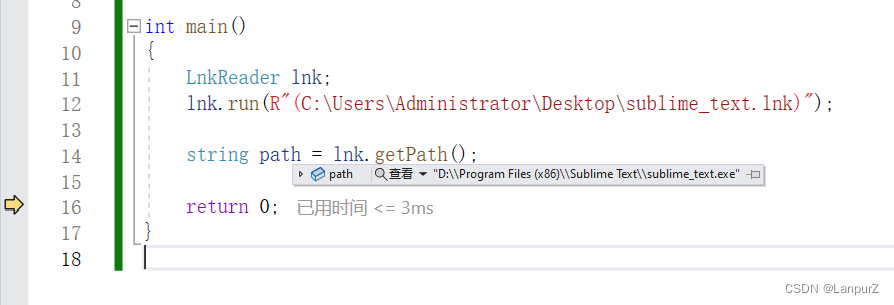
很明显,读取成功
完整代码
https://github.com/lanpurz/LnkReader
参考文档
补充
2025/4/25:
最近心血来潮看了一下以前写的代码,发现里面漏洞百出,毕竟当时初生牛犊不怕虎想到什么写什么,也没考虑过性能问题,今天补充一下把曾今的代码优化一下
在源代码49行左右
typedef struct _tagItemType {
static const BYTE ROOT = 1;
static const BYTE VOLUME = 2;
static const BYTE FILE = 3;
}ITEM_TYPE;
public:
LnkReader() = default;
int run(string stLnkPath)
{
lnkFile.open(stLnkPath, ios::in | ios::binary); //以二进制只读的方式打开文件流
if (!lnkFile.is_open())
return -1; //打开失败,返回-1
//获取文件大小
seek(LNK_SEEK_END, 0); //先跳到结束的位置从中可以看出来两个问题:
1.没有析构函数无法释放资源
2.std::string没有用引用导致占用资源
可以改成
public:
LnkReader() = default;
virtual ~LnkReader()
{
if (lnkFile.is_open())
{
// 析构函数主要用来关闭文件流
lnkFile.close();
}
}
int run(string&& stLnkPath)
{
lnkFile.open(stLnkPath, ios::in | ios::binary); //以二进制只读的方式打开文件流
if (!lnkFile.is_open())
return -1; //打开失败,返回-1
还有第95行,自己写的断言
//自己写的断言函数
void Assert(bool condition, string description)
{
if (condition)
{
MessageBoxA(0, description.c_str(), "Error", MB_ICONERROR);
throw "assert.";
}
}现在看来真的是愚蠢之极,直接throw
我的建议是直接删除所有断言,扔掉错误检查(因为我懒得写了awa)
还有seek函数,根本不需要用switch
直接改成这样
...
#define LNK_SEEK_BEG std::ios::beg
#define LNK_SEEK_END std::ios::end
#define LNK_SEEK_CUR std::ios::cur
...
//跳过数据
void seek(int pot, int offset)
{
lnkFile.seekg(offset, pot);
}
...还有就是代码结构,为什么要先运行run函数然后再用getPath而不直接获取路径呢?我也不知道当时自己是怎么想的
现在直接改成运行get函数直接获取路径
完整代码如下
#include <iostream>
#include <fstream>
#include <string>
#define LNK_SEEK_BEG std::ios::beg
#define LNK_SEEK_END std::ios::end
#define LNK_SEEK_CUR std::ios::cur
class LnkReader {
public:
typedef struct _tagLinkFileHeader {
DWORD HeaderSize; //文件头的大小
GUID LinkCLSID; //CLSID
DWORD Flags; //lnk文件标志
DWORD FileAttributes; //文件属性(目标文件的)
FILETIME CreationTime; //创建时间(目标文件的)
FILETIME AccessTime; //访问时间
FILETIME WriteTime; //修改时间
DWORD FileSize; //文件大小
DWORD IconIndex;
DWORD ShowCommand; //显示方式
WORD Hotkey; //热键
BYTE retain[10]; //保留的10byte数据
}LINKFILE_HEADER, * LPLINKFILE_HEADER;
typedef struct _tagLinkItemID {
WORD wSize;
BYTE bType;
BYTE* bData;
inline int getTypeData() { return (bType & 0xFL); };
inline int getListType() { return ((bType & 0xF0L) >> 4); };
}ITEMID, * LPITEMID;
typedef struct _tagItemType {
static const BYTE ROOT = 1;
static const BYTE VOLUME = 2;
static const BYTE FILE = 3;
}ITEM_TYPE;
public:
LnkReader() = default;
virtual ~LnkReader()
{
if (lnkFile.is_open())
{
// 析构函数主要用来关闭文件流
lnkFile.close();
}
}
std::string get(std::string&& lnkpath)
{
if (lnkFile.is_open())
lnkFile.close();
lnkFile.open(lnkpath, std::ios::in | std::ios::binary); //以二进制只读的方式打开文件流
if (!lnkFile.is_open())
return "Failed to open file."; //打开失败,返回-1
//获取文件大小
seek(LNK_SEEK_END, 0); //先跳到结束的位置
tagFileSize = tell(); //通过tell获取文件大小
seek(LNK_SEEK_BEG, 0); //再跳到开头
//因为lnk文件一般都比较小故可以用以上方法获取文件大小
//读取4个字节判断是否是lnk类型文件
read(&lnkHeader.HeaderSize, 4);
if (lnkHeader.HeaderSize != 0x4c)//若不是lnk文件
{
return "Not lnk file.";
lnkFile.close();
}
//移动数据到文件开头的位置, 因为读取文件头4个字节时改变了文件读取的位置
seek(LNK_SEEK_BEG, 0);
//读取文件头
read(&lnkHeader, sizeof(LINKFILE_HEADER));
//获取快捷方式指向的文件路径
return getLinkTargetIDList();
}
private:
std::fstream lnkFile; //文件流
LONGLONG tagFileSize; //文件大小
LINKFILE_HEADER lnkHeader; //lnk文件头
//跳过数据
void seek(int pot, int offset)
{
lnkFile.seekg(offset, pot);
}
//获取指针当前的位置
LONGLONG tell()
{
return lnkFile.tellg();
}
//读取数据
void read(PVOID pData, int szCount)
{
if (pData == nullptr)
seek(LNK_SEEK_CUR, szCount); //跳过字节
else
lnkFile.read((char*)pData, szCount);
}
//初始化内存
void memzero(PVOID pDst, int iSize)
{
ZeroMemory(pDst, iSize);
}
//从数据流中获取一个完整的字符串, 返回字符长度(包括结束符)
int getstring(std::string& src)
{
src = "";
int n = 0;
for (char ch[2] = "";; n++)
{
read(ch, 1);
if (ch[0] == '\0')
break;
src += std::string(ch);
}
return n + 1;
}
std::string getLinkTargetIDList()
{
int szIDList = 0;
char* buf = nullptr;
std::string path = "";
//读取IDList大小
read(&szIDList, 2);
for (int szCurrent = 0; szCurrent < szIDList - 2;)
{
ITEMID ItemID;
read(&ItemID.wSize, 2); //读取大小
if (ItemID.wSize == 0) //判断是否是 TerminallID
break;
read(&ItemID.bType, 1); //读取类型
//判断ItemID类型
switch (ItemID.getListType())
{
case ITEM_TYPE::ROOT:
{
//忽略
read(nullptr, ItemID.wSize - 3);
break;
}
case ITEM_TYPE::VOLUME:
{
//读取盘符
char* buf = new char[ItemID.wSize - 3];
memzero(buf, ItemID.wSize - 3);
read(buf, ItemID.wSize - 3);
path += std::string(buf);
break;
}
case ITEM_TYPE::FILE:
{
int iFileSize = 0;
WORD DosData = 0, DosTime = 0, FileAttributes = 0;
std::string str = "";
read(nullptr, 1); //跳过未知字节
/* 注:read函数第一个参数填NULL表示向后跳过 szCount 个字节, 相当于 seek(LNK_SEEK_CUR, szCount) ,可以看看read函数具体细节*/
read(&iFileSize, 4); //读取文件大小(暂时不需要)
//读取文件(文件夹)创建日期和时间
read(&DosData, 2);
read(&DosTime, 2);
read(&FileAttributes, 2); //读取文件(文件夹)类型
int reads = getstring(str); //读取文件名称
path += str + R"(\)";
//read(nullptr, ItemID.wSize - 1 - 4 - 2 - 2 - 2 - reads - 3)
read(nullptr, ItemID.wSize - reads - 14); //暂时不需要额外信息
break;
}}
szCurrent += ItemID.wSize;
}
if (buf != nullptr)
{
delete[] buf;
buf = nullptr;
}
path = path.substr(0, path.size() - 1); //删去最后一个多余的"\"
return path;
}
};现在已经把明显的错误找出来并修正了


















 1992
1992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









