







1、防火墙


这道题的答案是A。
解题思路
- 选项A:病毒防治主要是由专门的防病毒软件来完成,它需要对文件、进程等进行深度扫描和实时监控,以检测和清除病毒、恶意软件等。防火墙主要工作在网络层和传输层等较低层次,侧重于网络访问控制,本身并不具备直接查杀病毒的功能 。
- 选项B:状态检测防火墙能够跟踪连接状态,根据连接的状态信息来决定是否允许数据包通过,是现代防火墙常见的一种功能特性。
- 选项C:代理功能是防火墙的一种常见功能,防火墙可以作为内部网络和外部网络之间的代理服务器,代表内部网络用户与外部进行通信,从而隐藏内部网络的真实IP等信息,同时也可以对通信进行过滤和控制 。
- 选项D:包过滤是防火墙最基本的功能之一,它根据预先设定的规则对数据包的源地址、目的地址、端口号等信息进行检查,决定是否允许数据包通过。
2、哈夫曼树

本题可根据哈夫曼树的性质来求解能得到的字符编码个数。
1. 明确哈夫曼树的性质
在哈夫曼树中,叶子节点的个数等于字符的个数,且哈夫曼树的节点总数 n 与叶子节点数 m 之间存在关系:n=2m−1。
2. 根据上述性质计算叶子节点个数
已知哈夫曼树共有127个结点,设叶子节点个数为m,根据n=2m−1(其中n=127),可得方程:
127=2m−1
求解上述方程:
m=128/2=64
由于叶子节点的个数等于字符的个数,所以对其进行哈夫曼编码,共能得到64个字符的编码。
综上,答案是A。
3、浮点加减法运算

本题可根据浮点加(减)法运算的具体步骤来确定正确的操作流程。
浮点加(减)法运算的具体步骤如下:
- 零操作数检查:首先需要检查两个操作数是否为零。如果其中一个操作数为零,那么运算结果就是另一个操作数(若另一个操作数也为零,则结果为零),无需进行后续复杂的运算,所以零操作数检查应放在第一步,即①排在首位。
- 对阶操作:由于浮点数的表示形式为阶码和尾数,为了使两个浮点数的尾数能够直接相加减,需要将它们的阶码调整到相同的值,这个过程就是对阶操作。只有先完成对阶,才能保证后续尾数相加减的有效性,因此对阶操作应在零操作数检查之后,即④排在①之后。
- 尾数加(减)法运算:在对阶完成后,就可以对两个浮点数的尾数进行相应的加或减运算了,所以③排在④之后。
- 规格化及舍入处理:尾数加(减)法运算得到的结果可能不符合浮点数的规格化要求,需要进行规格化处理,使其满足规定的形式;同时,在运算过程中可能会产生精度损失,还需要进行舍入处理,以保证结果的精度。因此,规格化及舍入处理应放在最后一步,即②排在③之后。
综上,正确的加(减)法运算操作流程是①④③②,答案选B。
4、(双端)队列

这是一道关于队列操作和出队序列可能性的题目。破题点在于理解队列两端入队、一端出队的规则,并通过对每个选项进行分析来判断其是否能由给定的入队顺序得到。
-
队列具有先进先出的特性,本题中队列可以在两端入队,但只在某一端出队。
各选项分析
选项A:dbac
-
入队过程:abcd
-
a从右入
-
b从左入
-
c从右入
-
d从左入
-
得到dbac
-

-
同理选c
5、构建的开发模型

这是一道关于基于构件的开发模型概念理解的选择题,破题点在于对每个选项所描述的基于构件开发模型特性进行准确判断。
选项A分析
-
基于构件的开发模型确实是本质上演进模型,它通过迭代的方式逐步构建软件。在开发过程中,不断对已有的构件组合和功能进行调整和完善,就像演进一样逐步形成最终的软件产品,所以该选项正确。
选项B分析
-
基于构件的开发模型并不强制必须采用面向对象开发技术。虽然面向对象技术在构件开发中应用广泛,因为它具有良好的封装性、继承性和多态性等特点,便于构件的设计、复用和管理,但也可以使用其他开发技术来构建构件,只要这些构件能满足软件的功能需求且便于组合使用即可。所以该选项错误。
选项C分析
-
基于构件的开发模型的核心就是采用预先打包好的软件构件来构造软件。这些构件就像是软件构建的“积木”,开发人员可以根据软件的需求,从构件库中选取合适的构件进行组合和集成,从而快速构建出软件系统,所以该选项正确。
选项D分析
-
构件的来源是多样的,既可以是组织内部开发团队根据自身特定需求开发的构件,这些构件往往更贴合组织内部业务的特殊要求;也可以是市场上已经存在的商品化成品软件构件,它们经过了一定的测试和验证,具有一定的通用性和可靠性,开发人员可以直接购买和使用,所以该选项正确。
综上,答案是B。
6、非静态局部变量的存储位置

本题可根据C/C++程序中不同存储区域的特点,来判断函数中定义的非静态局部变量的存储位置。
各存储区域特点
- 栈区(Stack):由编译器自动分配和释放,通常存放函数的参数值、局部变量的值等。其操作方式类似于数据结构中的栈,遵循先进后出(FILO)原则。函数调用时,局部变量在栈上分配空间;函数执行结束时,这些局部变量的存储空间会被自动释放。
- 静态数据区(Static Data Area):用于存储全局变量和静态局部变量,这些变量在程序运行期间一直存在,直到程序结束才被释放。静态数据区又可细分为已初始化静态数据区和未初始化静态数据区。
- 文本区(Text Segment):也叫代码段,用于存放程序的可执行代码和只读数据,如常量字符串等。这部分内存区域通常是只读的,以防止程序意外修改代码。
- 自由堆区(Heap):用于动态内存分配,程序员可以通过
malloc、calloc、realloc等函数在堆上申请内存空间,并且需要使用free函数手动释放不再使用的内存。如果程序员没有正确释放堆上的内存,可能会导致内存泄漏。
分析题目
题目问的是函数中定义的非静态局部变量的存储空间位置。根据上述各存储区域的特点可知,函数中定义的非静态局部变量是在函数调用时由编译器自动分配空间,在函数执行结束时自动释放空间,符合栈区的特性。
因此,函数中定义的非静态局部变量,其存储空间在栈区分配,答案选A。

7、管理键盘的IO控制方式

本题答案为D。
解析
-
选项A:DMA(直接内存访问)
-
DMA 方式主要用于高速数据传输,例如磁盘与内存之间的数据传输等。它允许外设直接与内存进行数据交换,而不需要 CPU 的过多干预。键盘输入的数据量相对较小且速度较慢,采用 DMA 方式过于复杂且不经济,所以 A 选项不合适。
-
-
选项B:无条件传送
-
无条件传送方式适用于简单的、随时可以进行数据交换的设备,例如简单的开关量输入输出设备。键盘的输入是随机的,不是随时都准备好数据供 CPU 读取,所以不适合采用无条件传送方式,B 选项错误。
-
-
选项C:程序查询
-
程序查询方式下,CPU 需要不断地查询外设状态,以确定外设是否准备好进行数据传输。对于键盘这种可能会随时有按键按下(即随时准备好数据)的设备,CPU 若采用程序查询方式会浪费大量的 CPU 时间在不断查询上,降低了 CPU 的利用率,C 选项不合适。
-
-
选项D:中断
-
中断方式下,键盘等外设在有数据输入(例如按键按下)时,会向 CPU 发送中断请求。CPU 在执行完当前任务后,响应中断去处理键盘输入。这种方式使得 CPU 不需要一直等待或不断查询键盘状态,只有在键盘有实际输入时才进行处理,大大提高了 CPU 的利用率,所以管理键盘最适合采用中断方式,D 选项正确。
-
8、遍历二叉树

二叉树中序遍历和后序遍历的定义
-
中序遍历:先访问左子树,然后访问根节点,最后访问右子树。
-
后序遍历:先访问左子树,然后访问右子树,最后访问根节点。
综上,答案是A。
9、甘特图

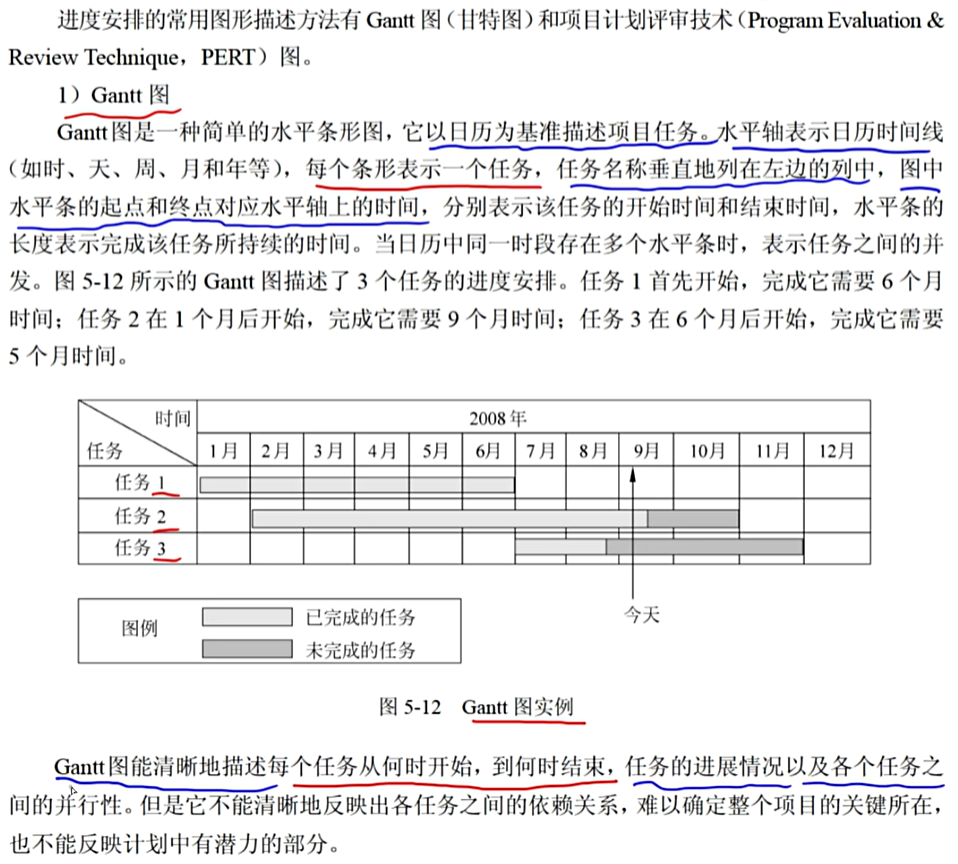
选D
10、PERT图

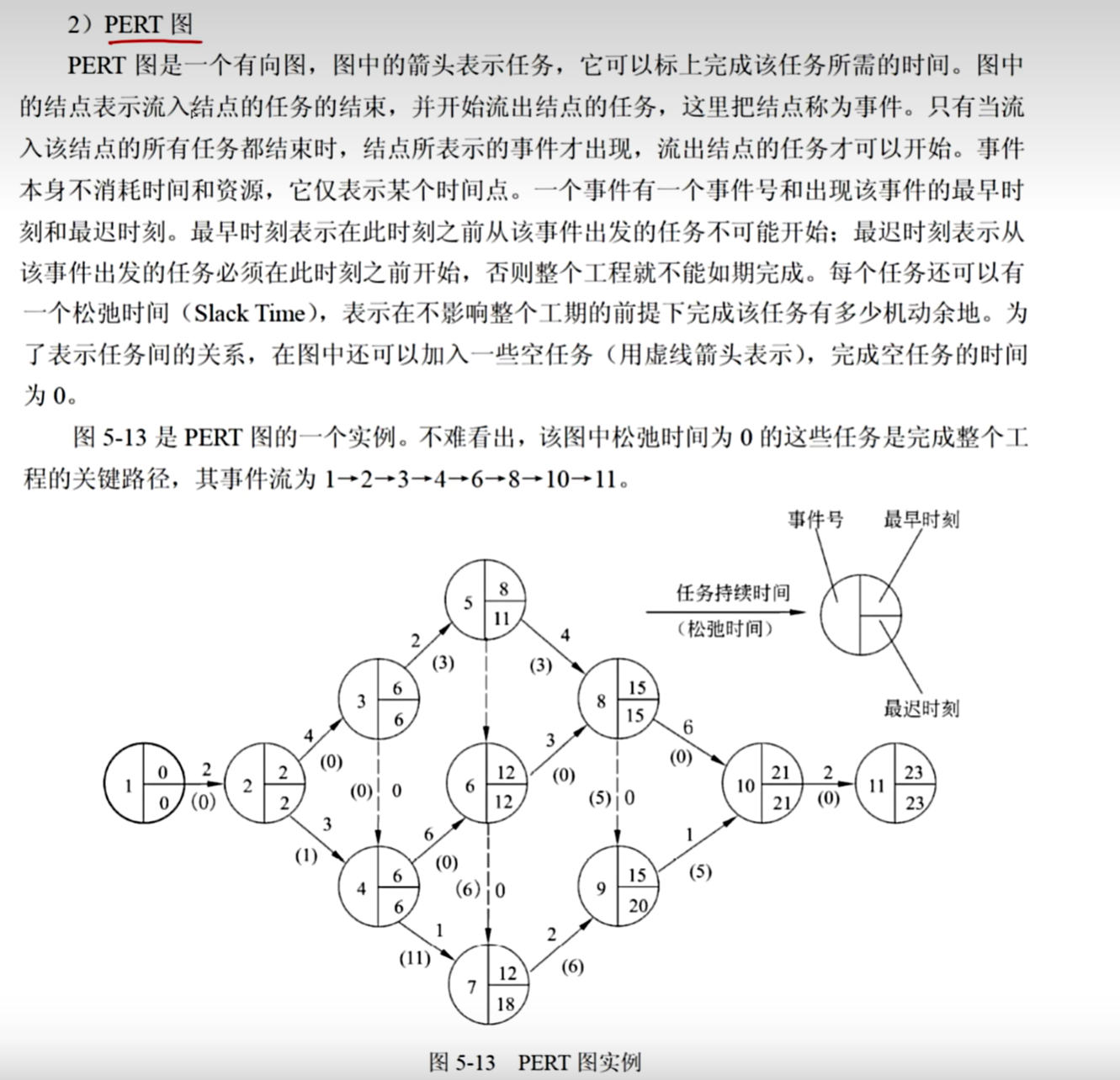
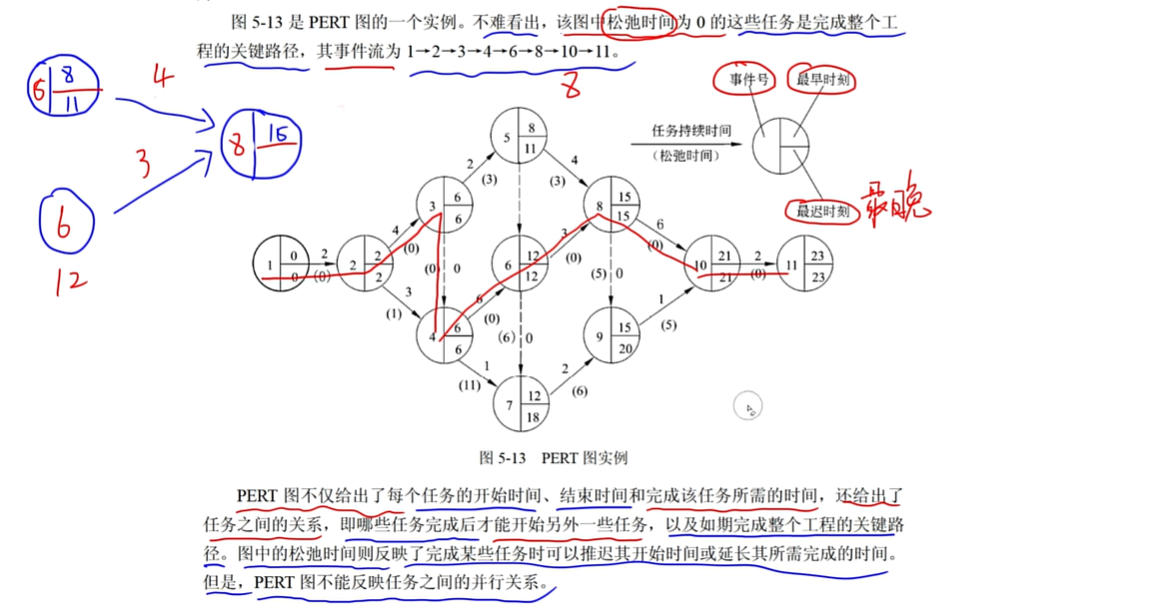
本题可根据PERT图(计划评审技术图)的特点,对每个选项逐一进行分析。
选项A:易于看出每个子任务的持续时间
PERT图以图形化的方式展示项目中的各个子任务,通过在图中明确标注每个子任务的开始时间和结束时间等信息,能够清晰直观地看出每个子任务的持续时间。所以该选项正确。
选项B:易于看出目前项目的实际进度情况
PERT图主要侧重于展示项目的计划安排,包括任务的先后顺序、持续时间以及任务之间的依赖关系等计划层面的信息。它本身并不直接体现项目的实际进度情况,要了解实际进度,通常需要结合实际的数据记录(如实际开始时间、实际完成时间等)并与计划进行对比分析,仅从PERT图本身难以直接看出目前项目的实际进度情况。所以该选项不正确。
选项C:易于看出子任务之间的衔接关系
PERT图通过箭头等方式明确地表示了各个子任务之间的先后顺序和依赖关系,即一个任务的开始可能依赖于另一个任务的完成,能够很清楚地展示子任务之间的衔接关系。所以该选项正确。
选项D:易于识别出关键的子任务
在PERT图中,可以通过分析任务之间的依赖关系、持续时间等因素,运用关键路径法(CPM)等相关方法来确定关键路径,而关键路径上的子任务就是关键的子任务,因此PERT图易于识别出关键的子任务。所以该选项正确。
综上,答案是B。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









