






编程题第二题
A、B、C三人之间进行了若干场一对一的乒乓球比赛。比赛规则如下,
题目描述:
1)每场比赛为一对一形式,只有两人参与;
2)每场比赛的胜者加 10 分,败者扣 10 分;
3)初始时,三人的分数均为0分。
已知比赛结束后 A和 B的最终分数,请根据规则判断C的分数是否大于0,并输出 C的最终分数。
一行输入两个整数(-1000≤整数≤1000),分别表示比赛结束后A和B的分数,整数之间以一个空格隔开。
输入述
输出一个整数,表示C的分数
第一问,比赛第一轮到最后一轮,三人分数相加的结果?
编程题第三题讲解:
有n座山峰排成一行,从左到右依次编号为1至n、已知每座山峰的高度,请找出满足以下所有山峰中编号最大的那个。
条件:该山峰的左侧(即所有编号比它小的山峰)至少存在一座山峰的高度小于它
如果存在这样的山峰,输出其编号;否则,输出-1.
例1:n=5,从左到右每座山峰的高度依次为140,200,120,150,110;其中2号和4号山峰都满足条件,编号最大的是4号山峰。
例2:n=3,从左到右每座山峰的高度依次为 190,105,82,没有满足条件的山峰。
第一行输入一个整数n(1<=n<=500)表示山峰的数量
第二行输入 n 个整数 (1<=整数<=5000),表示从左到右每座山峰的高度,整数之间用空格隔开
输出一个整数,表示满足题目条件的最大山峰编号,如果没有满足条件的山峰泽输出-1
#include <iostream>
using namespace std;
int main() {
int n;
cin >> n;
int h[500];
for (int i = 0; i < n; i++) {
cin >> h[i];
}
int m = -1;
for (int i = 0; i < n; i++) {
for (int j = 0; j < i; j++) {
if (h[j] < h[i]) {
m = i + 1;
}
}
}
cout << m;
return 0;
}
想做山峰那道题先会解下面的题:
步骤一:
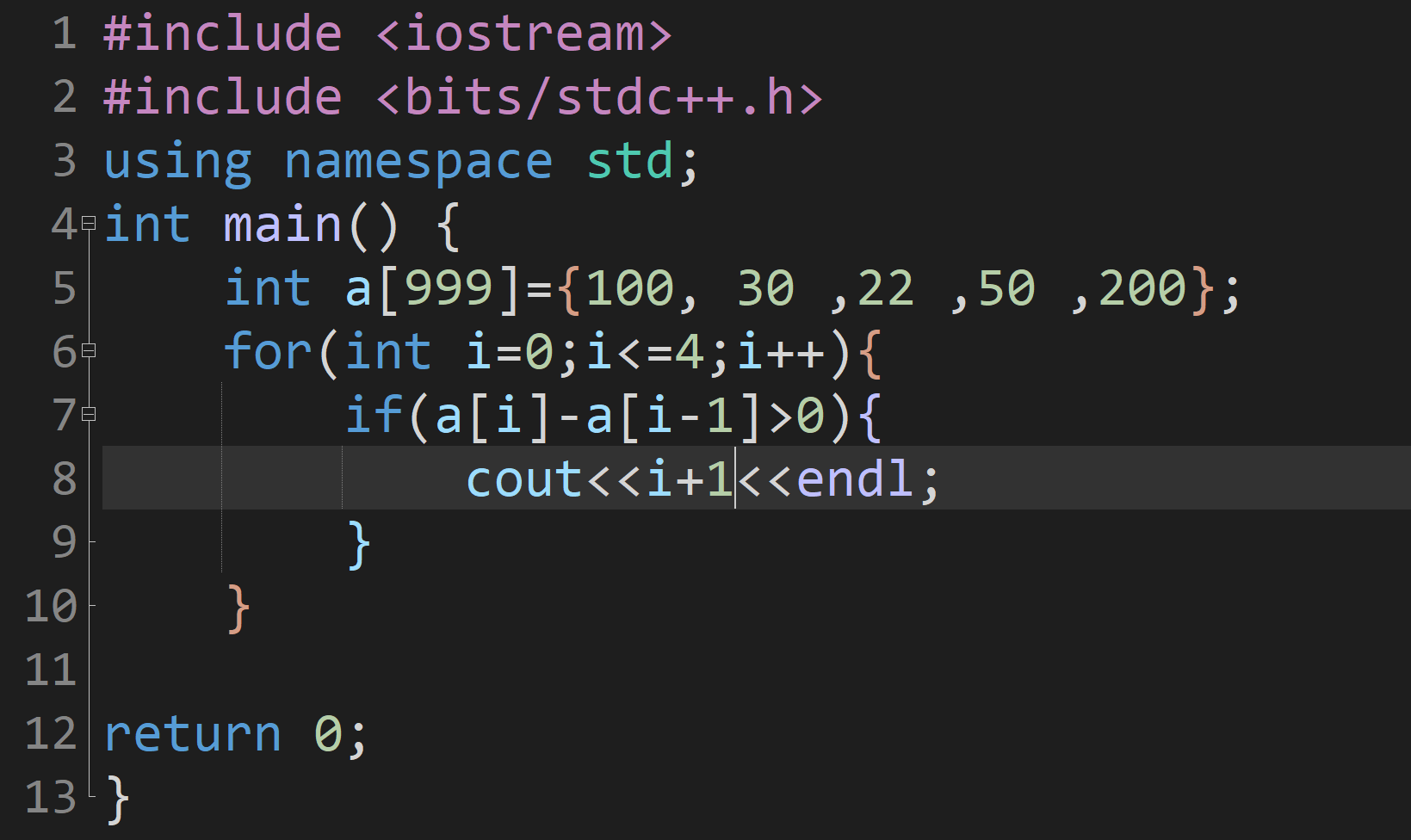
100 30 22 50 200
上面五个数字,如果存在 左边大于右边的数字,把它输出
步骤二:
输出满足条件的数字编号
步骤三:
把声明五个数字变成输入
如果有困难,那就创建一个数组,输入两个数字,输出这两个数字
步骤四:
把输入几个数字设置成变了n
把输出值变成下标,变成i+1
练习:
创建一个长度为99的整数数组,
输出,数组的每个位置数字是几
代码解释:
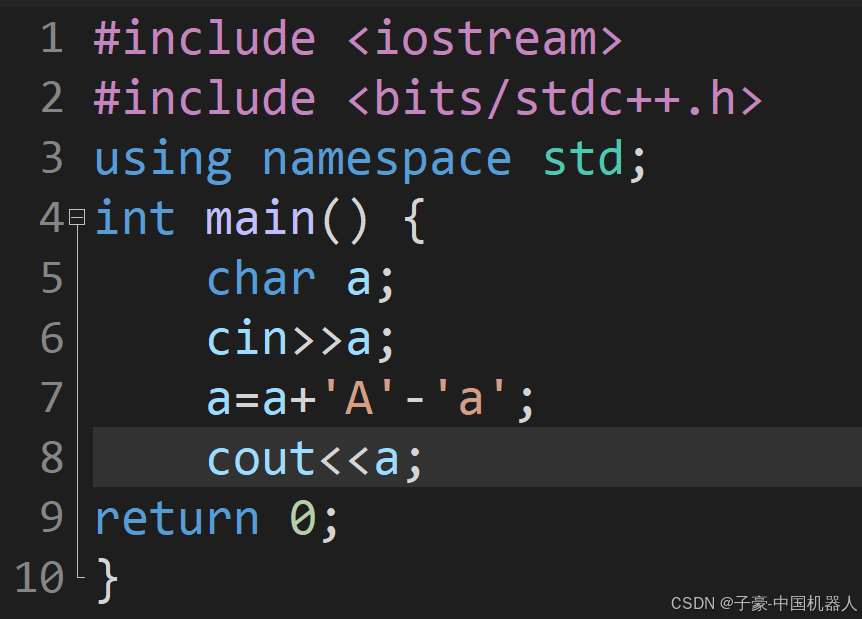
6. `a=a+'A'-'a';`:这里试图将小写字母转换为大写。假设输入的是小写字母,比如a,那么ASCII码中'a'是97,'A'是65,'A'-'a'的结果是-32。所以,如果输入的是小写字母,加上这个差值就会得到对应的大写字母。例如,'a' + (-32) = 65,即'A'。
该程序存在缺陷
第一,只能解决一个小写字母,比如a,请大家完善该程序,让他能解决abnvx一起变成大写
第二,输入大写,它会报错,解决这个问题
-
潜在问题
-
非小写字母输入:若输入大写字母(如
B),计算结果为B - 32 = 66 - 32 = 34(对应字符"),导致错误。 -
特殊字符风险:输入数字或符号(如
5)会生成不可预测的非字母字符。
-
-
改进方案
cpp
复制
#include <iostream> using namespace std; int main() { char a; cin >> a; if (a >= 'a' && a <= 'z') { // 仅处理小写字母 a = a - ('a' - 'A'); // 等价于 a = a - 32 } cout << a; return 0; } -
关键修正点
-
增加条件判断,确保仅对小写字母进行转换。
-
使用更清晰的表达式
a - ('a' - 'A'),提升代码可读性。 -
移除非标准头文件
bits/stdc++.h,改用必要的<iostream>。
-
总结:原程序在小写字母转换功能上正确,但缺乏输入验证,需通过条件判断限制处理范围以避免逻辑错误。
作业:
20 13 66 请给这三个数字排序
字符串题:
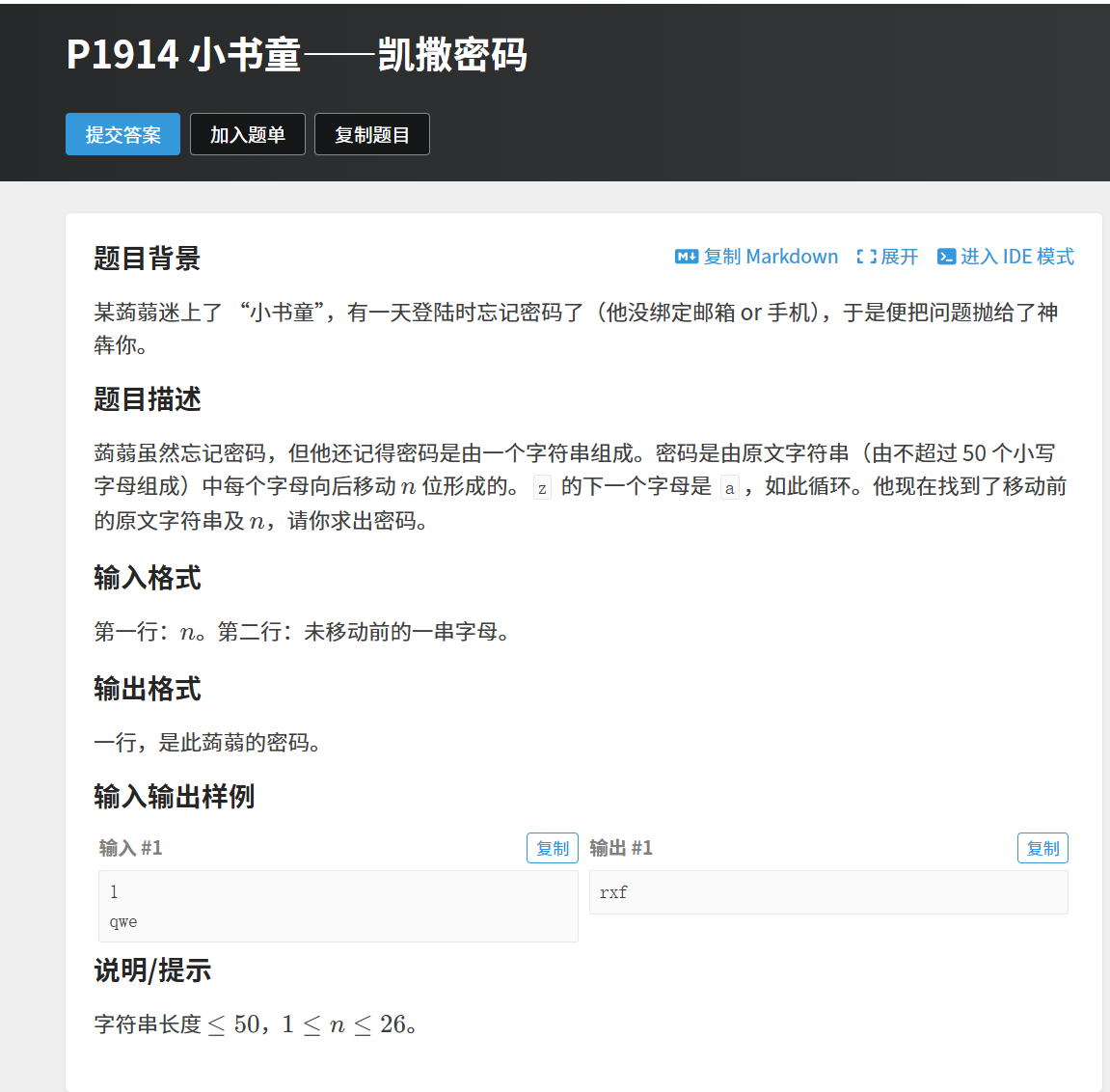
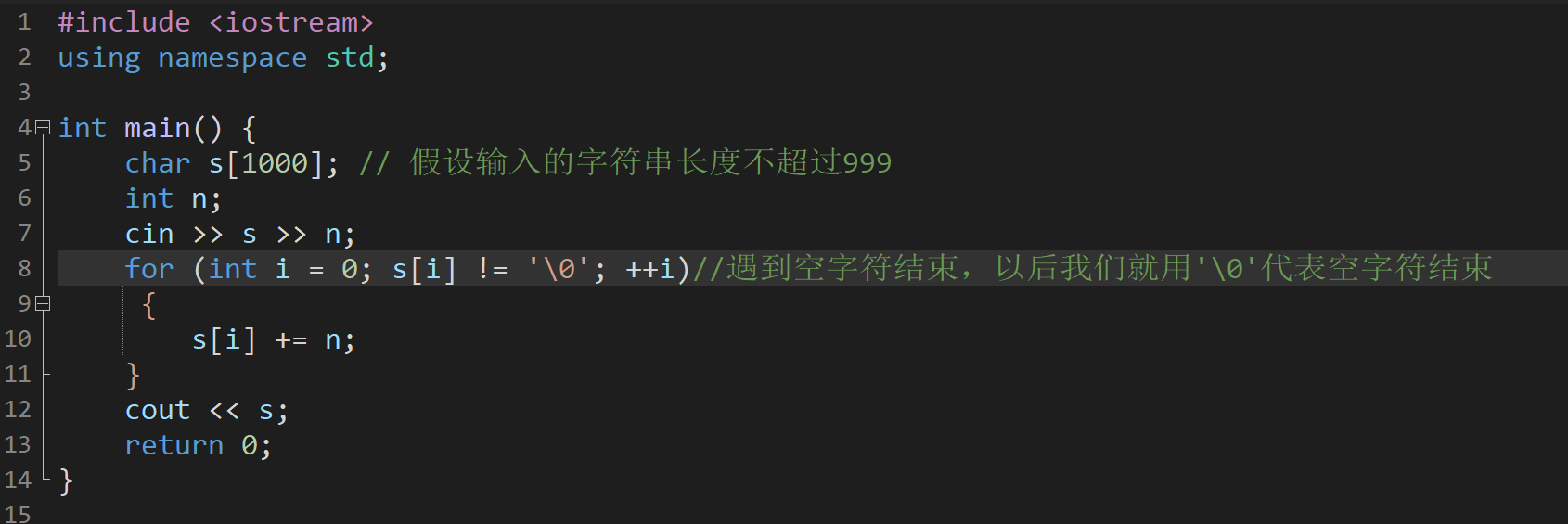
或者
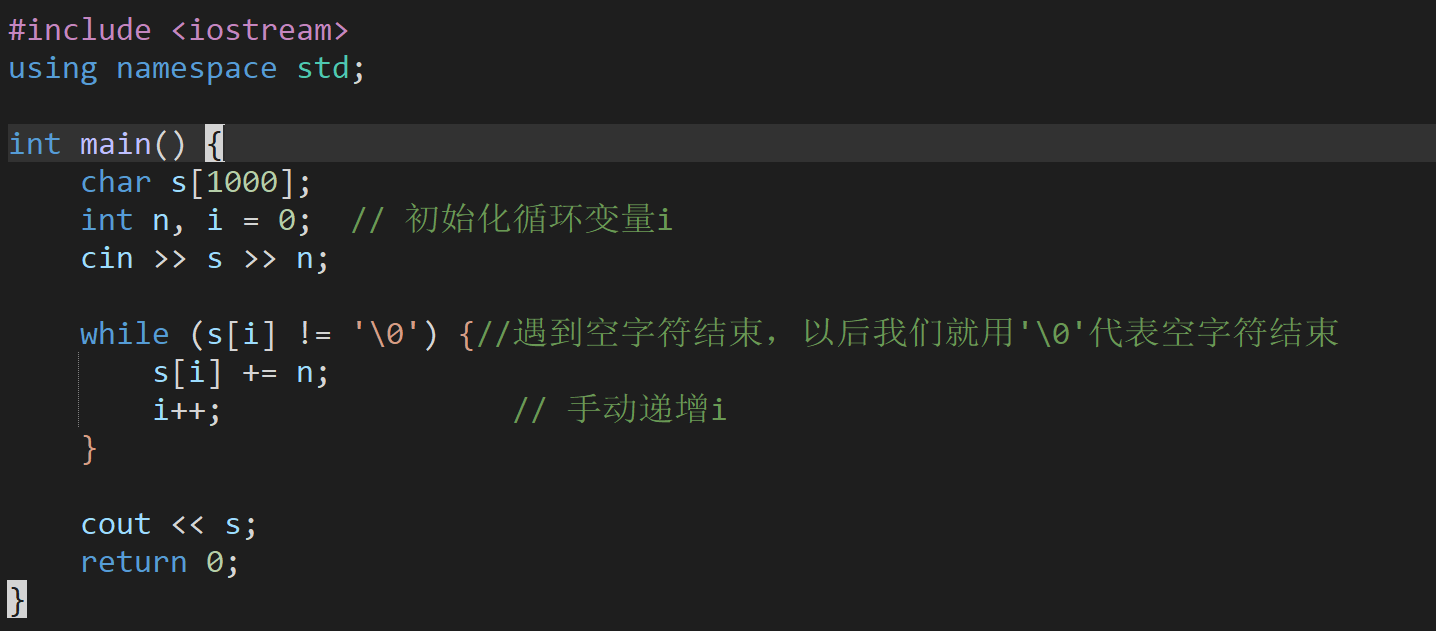
解题思路:
第一步,做阅读理解,把题翻译成 “人话”,它究竟问的是啥
第二步,分步解题
第三步,限定条件和注意事项最后写,比如上面的输入小写输出大写,最后再考虑,输入内容是否是大写,会不会报错,因为,及时限定条件没写对,也会给分
开始做题:
输入一个字母,
ASCII发现:a到z,是数字多少到多少
查表发现是:97到122


















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









