







前言
想与你们共同学习,想与你们一起努力,想得到你们的支持与喜欢~
一、Hive 引言
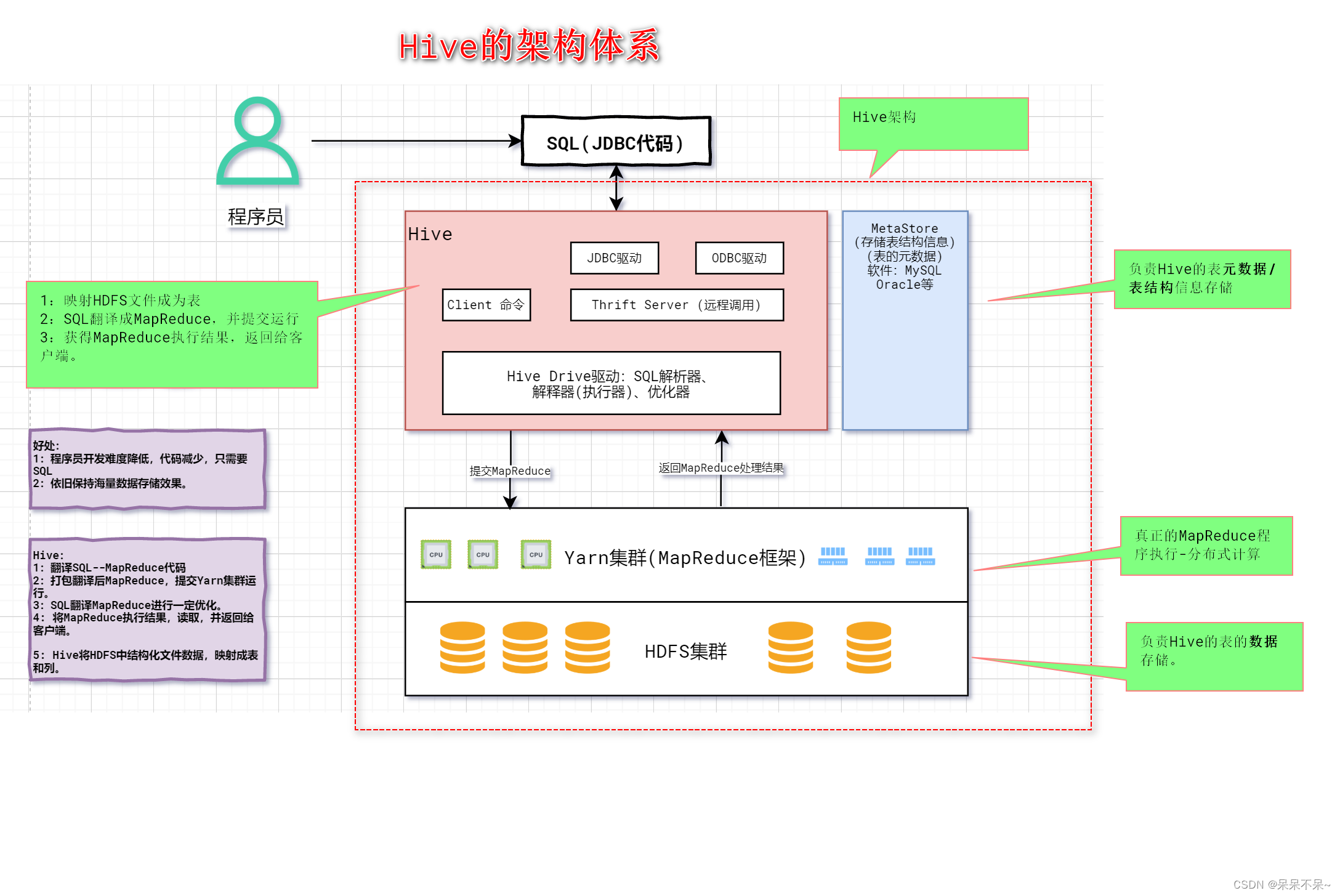
hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户(程序员)书写的SQL语句翻译成MapReduce代码,然后发布任务给Yarn执行,完成SQL 到 MapReduce的转换。可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
【总结】
-
Hive是一个数据仓库
-
Hive构建在HDFS上,可以存储海量数据。
-
Hive允许程序员使用SQL命令来完成数据的分布式计算,计算构建在yarn之上。(Hive会将SQL转化为MR操作)
-
Hive不适合场景: 小数据量 实时计算
-
数据库 DataBase
-
数据量级小,数据价值高
-
-
数据仓库 DataWareHouse
-
数据体量大,数据价值密度低
-
二、Hive 的架构
1. 简介
HDFS:用来存储hive仓库的数据文件
yarn:用来完成hive的HQL转化的MR程序的执行
MetaStore:保存管理hive维护的元数据
Hive:用来通过HQL的执行,转化为MapReduce程序的执行,从而对HDFS集群中的数据文件进行统计。2. 图
三、Hive的安装
# 步骤
1. HDFS
2. Yarn
3. MySQL
4. Hive1. 安装mysql数据库
mysql已经安装好,但没有启动,可以执行下面的语句:
systemctl enable mysqld
systemctl start mysqld
systemctl status mysqld
最后测试是否可用:
mysql -uroot -p1234562. 安装Hadoop
# 配置hdfs和yarn的配置信息
修改hadoop下的core-site.xml文件
<!-- 配置权限,hive访问hdfs的权限开启 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>3. 安装hive
1 上传hive安装包到linux中
2 解压缩hive
[root@hadoop ~]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/installs
[root@hadoop ~]# mv apache-hive-3.1.2-bin hive3.1.23 配置环境变量
export HIVE_HOME=/opt/installs/hive3.1.2
export PATH=$PATH:$HIVE_HOME/bin4 加载系统配置生效
[root@hadoop ~]# source /etc/profile5 配置hive
hive-env.sh
# 拷贝一个hive-env.sh
[root@hadoop10 conf]# mv hive-env.sh.template hive-env.sh
# 配置hadoop目录
HADOOP_HOME=/opt/installs/hadoop3.1.4/
# 指定hive的配置文件目录
export HIVE_CONF_DIR=/opt/installs/hive3.1.2/conf/hive-site.xml
拷贝得到hive-site.xml
[root@hadoop10 conf]# cp hive-default.xml.template hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--hive的元数据保存在mysql中,需要连接mysql,这里配置访问mysql的信息-->
<!--url:这里必须用ip-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop10:3306/hive?useSSL=false</value>
</property>
<!--drivername-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!--username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--password-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 显示表的列名 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 显示数据库名称 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 解决启动等一分钟重试问题 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>
</configuration>登录mysql创建hive数据库
create database hive复制mysql驱动Jar到hive的lib目录下
6 修改jar,防止jar包冲突
#将/opt/installs/hive3.1.2/lib下的guava-19.0.jar修改为guava-19.0.jar.bak
#jar包带上bak,jvm将不进行加载,相当于删除
cd /opt/installs/hive3.1.2/lib
mv guava-19.0.jar guava-19.0.jar.bak
#将hadoop下的guava-27.0-jre.jar 复制到hive的lib下
cp /opt/installs/hadoop3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /opt/installs/hive3.1.2/lib
#将/opt/installs/hive3.1.2/lib下的log4j-slf4j-impl-2.10.0.jar修改带上.bak
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak四、 启动
1. 启动 hadoop
# 启动HDFS
start-dfs.sh
# 启动yarn
start-yarn.sh2. 初始化元数据
初始化元数据:schematool -dbType mysql -initSchema3. hive本地启动
# 本地模式启动 【管理员模式】
# 启动hive服务器,同时进入hive的客户端。只能通过本地方式访问。
[root@hadoop10 ~]# hive
hive># 1. 查看数据库
hive> show databases;
# 2. 创建一个数据库
hive> create database test_hive;
# 3. 查看database
hive> show databases;
# 4. 切换进入数据库
hive> use test_hive;
# 5.查看所有表
hive> show tables;
# 6.创建一个表
hive> create table t_user(id string,name string,age int);
# 7. 添加一条数据(转化为MR执行--不让用,仅供测试)
hive> insert into t_user values('1001','zhangsan',20);
# 8.查看表结构
hive> desc t_user;
# 9.查看表的schema描述信息。(表元数据,描述信息)
hive> show create table t_user;
# 明确看到,该表的数据存放在hdfs中。
# 10 .查看数据库结构
hive> desc database test_hive;
# 11.查看当前库
hive> select current_database();
# 12 其他sql
select * from t_user;
select count(*) from t_user; (Hive会启动MapReduce)4.hive的客户端和服务端
# 启动hive的服务器,可以允许远程连接方式访问。
// 前台启动
[root@hadoop10 ~]# hiveserver2
// 后台启动
[root@hadoop10 ~]# hiveserver2 &beeline客户端
# 启动客户端
[root@hadoop10 ~]# beeline
beeline>!connect jdbc:hive2://hadoop10:10000














 1251
1251











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











