






字符提取实例
在参考:https://blog.csdn.net/Koala_Tree/article/details/78725881
该文章时,发现里面对字符串的提取用到了extract函数
提取过程如下所示:
这是原本的字符串,要将称号Mr、Mrs、Miss等提取出来
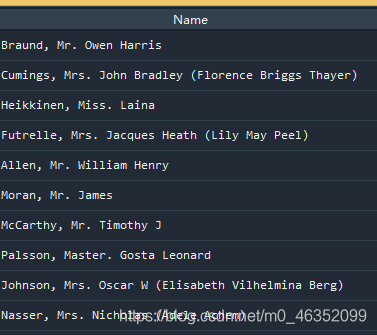
代码如下所示:
train_data['Title'] = train_data['Name'].str.extract(' ([A-Za-z]+)\.', expand=False)
提取结果:
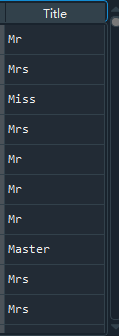
该提取使用了extract函数以及正则表达式,
所以我分别介绍一下该函数的使用以及正则表达式
extract解释
在python的帮助中查找其详细介绍:
Series.str.extract
- 这是该函数用法的英文解释:
- Extract capture groups in the regex pat as columns in a DataFrame.
- For each subject string in the Series, extract groups from the first match of regular expression pat.
- 将正则表达式中的提取为数据框中的列。 对于系列中的每个主题字符串,从正则表达式的第一个匹配中提取组。
| 参数 | 解释 |
|---|---|
| pat | 字符串 / 正则表达式 |
| flags | int型,默认为0(无标志)。 来自re模块的标志,例如re.IGNORECASE,修改正则表达式匹配,如大小写、空格等。有关更多详细信息,请参见 re |
| expand | 布尔值,默认为真。 如果为真,则返回每个捕获组有一列的数据框。如果为假,如果有一个捕获组,则返回序列/索引;如果有捕获组,则返回数据框。 |
- python的help中的例子
剩下的例子可以直接通过help来查看该函数的用法以及举例
>>>s = pd.Series(['a1', 'b2', 'c3'])
>>>s.str.extract(r'([ab])(\d)')
'''
该语句的含义也就是从字母a,b中找出对应字符的字母,并分割开来
所以得到一下结果,但没有c,所以结果c那里就是NaN
'''
#结果:
0 1
0 a 1
1 b 2
2 NaN NaN
>>>s.str.extract(r'([ab])?(\d)')
'''
?表示匹配前面的子表达式零次或一次。例如,"do(es)?"
可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do"
'''
0 1
0 a 1
1 b 2
2 NaN 3
正则表达式介绍
- 关于捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。当然,这种引用既可以是在正则表达式内部,也可以是在正则表达式外部。
捕获组有两种形式,一种是普通捕获组,另一种是命名捕获组,通常所说的捕获组指的是普通捕获组。语法如下:
普通捕获组:(Expression)
命名捕获组:(?Expression)
另外需要说明的一点是,除(Expression)和(?Expression)语法外,其它的(?..)语法都不是捕获组。、
- 正则表达式
示例:
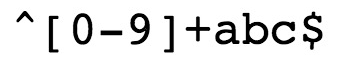
| 示例解释 |
|---|
| ^为匹配输入字符串的开始位置。 |
| [0-9]+ 匹配多个数字, [0-9] 匹配单个数字,+ 匹配一个或者多个。 |
| abc$ 匹配字母 abc 并以 abc 结尾,$ 为匹配输入字符串的结束位置。 |
- 关于上述姓名提取字符的正则表达式的解释:
再展示一下姓名数据的样子:

' ([A-Za-z]+)\.'
为了提取Mr,可以看到Mr前面有空格,且从大写字母开始再到小写字母 。
所以该正则表达式也是类似:先空了一格,从大写字母A-Z中匹配,再从小写字母a-z中匹配, 到 .(点)这里结束。
\表示转义,在正则表达式中点(.)表示:匹配除换行符 \n 之外的任何单字符。若要直接使用则需要加上转义符号
另编写两行简单的代码实现如下:
'''
提取Mi,Xr,可以看到该提取字符前面没有空格了,所以将正则表达式稍作
修改删除空格,即可得到需要的效果
'''
improt pandas as pd
x=['Aaa,Mi.mmmki','Aaa,Xr.mmmki']
x=pd.DataFrame(x)
x[1]=x[0].str.extract('([A-Za-z]+)\.')
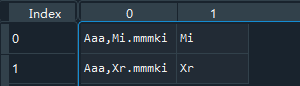
下图可以看到第一列为提取前,第二列为提取后的样子
参考的文章:
有关正则表达式的详细介绍,关于语法等,请参考该篇文献
https://www.runoob.com/regexp/regexp-syntax.html
有关正则捕获组的相应介绍,请参考该篇文献
https://www.cnblogs.com/luckcs/articles/2212976.html

















 2937
2937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









