








 本文介绍了RPC(远程过程调用)的概念,强调其作为客户端与服务器间请求响应模型的角色,简化了底层通信的复杂性。接着探讨了分布式哈希(DHT),用于解决数据分布式存储的问题,确保每个节点只负责一部分路由和数据存储。进一步讨论了一致性哈希,它是一种哈希算法,当节点增删时,能最小化映射关系的改变,降低对系统稳定性的影响。一致性哈希在负载均衡、RPC服务和MemCache集群等场景中有广泛应用。
本文介绍了RPC(远程过程调用)的概念,强调其作为客户端与服务器间请求响应模型的角色,简化了底层通信的复杂性。接着探讨了分布式哈希(DHT),用于解决数据分布式存储的问题,确保每个节点只负责一部分路由和数据存储。进一步讨论了一致性哈希,它是一种哈希算法,当节点增删时,能最小化映射关系的改变,降低对系统稳定性的影响。一致性哈希在负载均衡、RPC服务和MemCache集群等场景中有广泛应用。
一、RPC
简单的说,
- RPC就是从一台机器(客户端)上通过参数传递的方式调用另一台机器(服务器)上的一个函数或方法(可以统称为服务)并得到返回的结果。
- RPC 会隐藏底层的通讯细节(不需要直接处理Socket通讯或Http通讯) RPC 是一个请求响应模型。
- 客户端发起请求,服务器返回响应(类似于Http的工作方式) RPC 在使用形式上像调用本地函数(或方法)一样去调用远程的函数(或方法)。
参考:RPC简介及框架参考
二、分布式哈希
参考:分布式哈希与一致性哈希
参考:“分布式哈希”和“一致性哈希”的概念与算法实现
两个key point:
- 每个节点只维护一部分路由;
- 每个节点只存储一部分数据。从而实现整个网络中的寻址和存储。
DHT只是一个概念,提出了这样一种网络模型。并且说明它是对分布式存储很有好处的。但具体怎么实现,并不是DHT的范畴。
我们将散列表放在一个机器的内存里,当散列表比较小时候,没有问题,但如果这张散列表超过了一台机器的内存时候,或者当存储在一台机器上时候,这台机器挂掉了,那所有的数据都会消失……
那现在我们又该怎么做呢?
这便需要引入DHT来处理这种情况了,说白了就是将一张哈希表分割在不同的机器上。
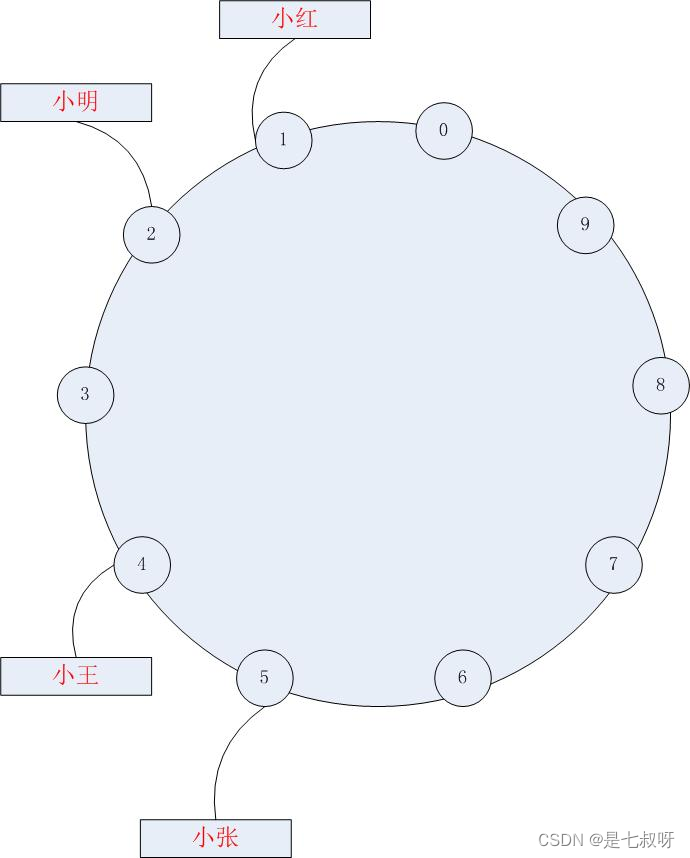
首先,将上面所说的散列空间0,1…9想像成一个首尾相衔的环,9之后又重新回到零,假设,这就是十台机器。
三、一致性哈希
好了,上面我们使用DHT实现了数据的分布式存储,但再考虑深一层,分布式架构中,节点的故障是不可避免的,当添加和删除某一节点了,会导致大量散列数据失效,需要重新散列。
影响非常大,那我们用什么哈希算法来实现DHT才能尽量的避免这种情况呢,这便说到了一致性哈希。
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在 key 映射关系。
刚刚我们把学生散列到了hash数值空间里,现在我们需要的是,同时将机器也散列在这个hash空间,让学生和机器的散列值同处在一个数值空间。
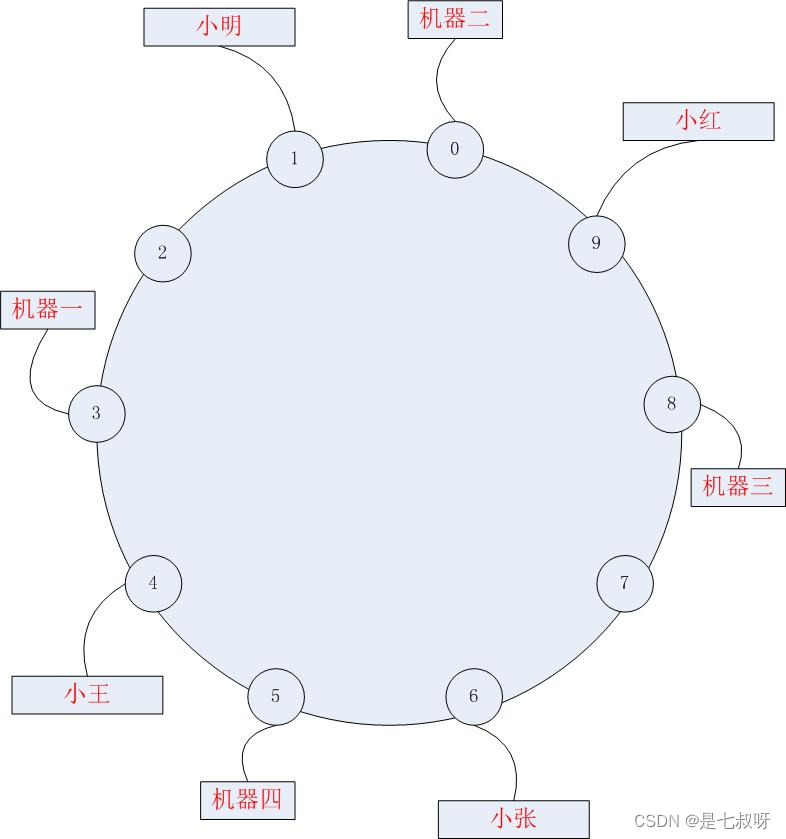
如上图所示,如果我们将学生和机器同时散列在一个环中,那么假设小张散列后的值为6,我们顺时针寻找,寻找到的第一台机器,则将小张放入其中。
依次类推,则得到:
小王——>机器一
小明——>机器二
小红——>机器三
小张——>机器四
假设我们机器三失效了,那这时候影响到的仅仅是小红,重新散列到机器四中。
而如果重新加入一台新的机器,影响到的也仅仅是旁边的一台机器,这样便解决了添加删除机器时候的震荡问题,这便是一致性hash的大致思想。
参考:一致性哈希
什么是一致性哈希
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系 。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题。
一致性哈希算法一般用来干什么
一般我们在项目的负载均衡上要求资源被均匀的分配到所有的服务器节点上,同时,还需要对资源的请求能迅速的路由到具体的节点,例如:
- 我们在做RPC服务的时候,会经常部署多台服务器,然而有时有这样的需求就是,我们希望将同一类型的请求路由到同一台机器上,这个时候就可以用一致性hash算法来实现。
- MemCache集群,要求存储数据均匀的放到集群中的各个节点上,访问这些数据时能快速的路由到集群中对应存放该数据的节点上;并且要求增删节点对整个集群的影响很小,不至于有大的动荡造成整体负载的不稳定,这个时候也是可以用一致性hash算法。
一致性哈希算法原理解析
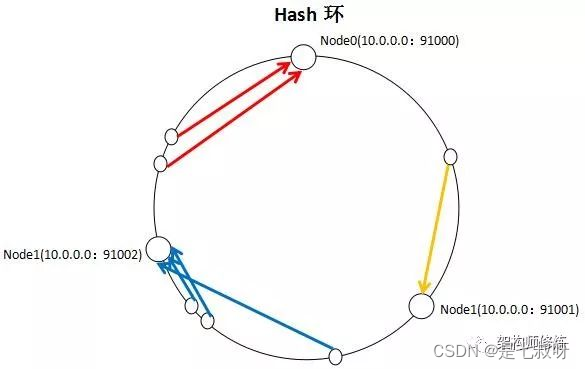
一致性哈希算法核心思想就是,先维护出一个2的32次方整数环【0,2^32-1】,然后将每个节点的计算hash值放到环上。下面通过一个例子来看看 ;
现在有三个节点分别是Node0、Node1、Node3,我们要将多个资源尽可能均匀的分配到这三个节点中,该怎么做呢?
依据一致性hash算法思想,我们需要将资源key进行hash运算,得到的hash值在环上顺时针查找,找到离它最近的节点也就是第一个大于或等于它的节点,这样资源就和节点建立了映射关系。
取余算法和一致性哈希算法
我们要向分配节点第一想到的办法就是
取
余
算
法
\color{red}{取余算法}
取余算法。即现在有3个节点,资源key=7,7%3=1,则选择Node1,key=5,5%3= 2,则选择Node2,key=3,3%3=0,则选择Node0。虽然简单,但有个缺点,如果节点数增加或减少,就会有大量的key不命中,造成请求压力转移,可能对系统整体有很大的影响,甚至发生宕机危险。
而
一
致
性
哈
希
算
法
\color{red}{一致性哈希算法}
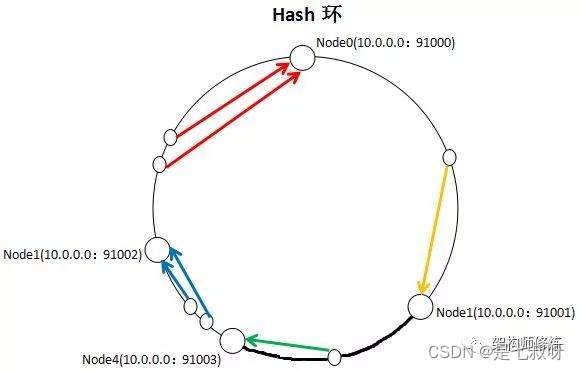
一致性哈希算法增加或减少节点,只会引起很少部分的key不会命中,如下图,增加一个Node4节点,则只会将部分的key值从Node1移到Node4,对集群影响很小。

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









