







论文地址:https://arxiv.org/abs/2008.01449
作者代码:https://github.com/dvlab-research/PFENet
一、数据加载dataset
(先处理查询集image、label,例:将目标mask由含有[0, 8,255]变为[0,1,255];然后处理支撑集和shot,最后返回return image, label, s_x, s_y, subcls_list【真实类别在训练的sub_list([6-20])中的下标2】)
1.1 class SemData(Dataset):中的__init__函数:最后进行了一个make_dataset操作
make_dataset函数最后返回image_label_list, sub_class_file_list
def make_dataset(split=0, data_root=None, data_list=None, sub_list=None):
assert split in [0, 1, 2, 3, 10, 11, 999]
if not os.path.isfile(data_list):
raise (RuntimeError("Image list file do not exist: " + data_list + "\n"))
# Shaban uses these lines to remove small objects:
# if util.change_coordinates(mask, 32.0, 0.0).sum() > 2:
# filtered_item.append(item)
# which means the mask will be downsampled to 1/32 of the original size and the valid area should be larger than 2,
# therefore the area in original size should be accordingly larger than 2 * 32 * 32
image_label_list = []
list_read = open(data_list).readlines()
print("Processing data...".format(sub_list))
sub_class_file_list = {}
for sub_c in sub_list:
sub_class_file_list[sub_c] = []
for l_idx in tqdm(range(len(list_read))):
line = list_read[l_idx]
line = line.strip()
line_split = line.split(' ')
image_name = os.path.join(data_root, line_split[0])
label_name = os.path.join(data_root, line_split[1])
item = (image_name, label_name)
label = cv2.imread(label_name, cv2.IMREAD_GRAYSCALE)
# label = Image.open(label_name)
# label = np.array(label)
label_class = np.unique(label).tolist()
if 0 in label_class:
label_class.remove(0)
if 255 in label_class:
label_class.remove(255)
new_label_class = []
for c in label_class:
if c in sub_list:
tmp_label = np.zeros_like(label)
target_pix = np.where(label == c)
tmp_label[target_pix[0], target_pix[1]] = 1
if tmp_label.sum() >= 2 * 32 * 32:
new_label_class.append(c)
label_class = new_label_class
if len(label_class) > 0:
image_label_list.append(item)
for c in label_class:
if c in sub_list:
sub_class_file_list[c].append(item)
print("Checking image&label pair {} list done! ".format(split)) # split = 0, 1, 2 or 3
return image_label_list, sub_class_file_list # image list and cls dict

image_label_list中包含一个2007_000039.jpg原图和2007_000039.png的mask:


sub_class_file_list中分组包含6-20类的路径。
1.2 __len__函数:`def len(self):
return len(self.data_list)`
1.3 def __getitem(self, index):
调试运行:取到一张图片
image和label的路径如下:
‘/media/D_4TB/zhouhongjie/1.few-shot segmentation/3.CaNet/CaNet-master/dataset/dir/VOCdevkit/VOC2012/JPEGImages/2010_004171.jpg’
‘/media/D_4TB/zhouhongjie/1.few-shot segmentation/3.CaNet/CaNet-master/dataset/dir/VOCdevkit/VOC2012/SegmentationClassAug/2010_004171.png’

1.31 将包含0,8,255的原始数组转换为0,1,255数组
里面包含像素矩阵值:[0, 8, 255],之后处理的代码如下:

之后class_chosen = label_class[random.randint(1,len(label_class))-1]将下标为random.randint(1, len(label_class))[1, 1],再-1=0的位置取出来。
此时class_chosen=被选中的类别8,之后:
先记录label==class_chosen的位置信息,ignore_pix记录轮廓的255信息,清空label,将0,1,255填进去
target_pix = np.where(label == class_chosen)
ignore_pix = np.where(label == 255)
label[:, :] = 0
if target_pix[0].shape[0] > 0:
label[target_pix[0], target_pix[1]] = 1
label[ignore_pix[0], ignore_pix[1]] = 255
调试查看到label数组里面包含0,1,255:其中0为背景,1为目标,255为白色轮廓。

1.32 得到支撑集和查询集
首先file_class_chosen = self.sub_class_file_list[class_chosen]从make_dataset函数的第二个返回值中选出8类的一个list,list中包含每张原图和对应的mask:(num_file = len(file_class_chosen)得到8类有131张)

其次,根据设置的shot=1,random.randint随即一张支撑集下标support_idx,下一步的support_image_path和support_label_path和上小节处理的图片路径、mask路径一样:
python的range(1)为0 - 1-1

接下来while循环选择一张和上一次的support_image_path、support_label_path不同,且不在上一次support_idx_list中的不同图作为支撑集,添加到
支
撑
集
图
片
的
l
i
s
t
中
\color{red}{支撑集图片的list中}
支撑集图片的list中:support_image_path_list.append(support_image_path) support_label_path_list.append(support_label_path)
我们可以看到在这里支撑集图片路径list变为了:

‘/media/D_4TB/zhouhongjie/1.few-shot segmentation/3.CaNet/CaNet-master/dataset/dir/VOCdevkit/VOC2012/JPEGImages/2010_000469.jpg’
接着self.sub_list.index(class_chosen)得到6-20中第8类的下标为2
读取图片,使用np.unique(label).tolist()可以看到cv读取到的矩阵里面的像素值:

输出support_label的值:
np.unique(support_label).tolist()
Out[9]: [0, 8, 255]
最后得到support_image_list.append(support_image)和support_label_list.append(support_label):
尺寸(379,500),且:
support_image中像素值变成了0,1,255。- 上一步的
label中是同类不同张图片的0,1,255,作为查询集的label。
1.34 进行transform操作
将查询集的label复制一份,进行transform操作,且支撑集的image和label也进行transform操作:

(transform之前都为numpy数组,之后变成了list中装有Tensor,尺寸统一成了473*473)

追溯到train.py中

然后进行torch.cat操作
其中它们的维度如下,其中s_x变为了tensor(维度[1, 3, 473, 473])。使用torch来对序列[s_xs[i].unsqueeze(0), s_x]在第一个维度(下标为0)上进行拼接。
range(1, self.shot)
因为range是从1开始到shot-1,所以只有shot数量>1的时候才会进行cat拼接操作(例如:shot=2,就会进行一次循环,拼接为[2, 3, 473, 473]),拼接为[2, 3, 473, 473]类似的这种作为return的输出。

return image, label, s_x, s_y, subcls_list【查询集图片、label;支撑集图片、label;图片类别在sub_list中的序号下标2】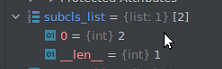
二、网络训练
github中:
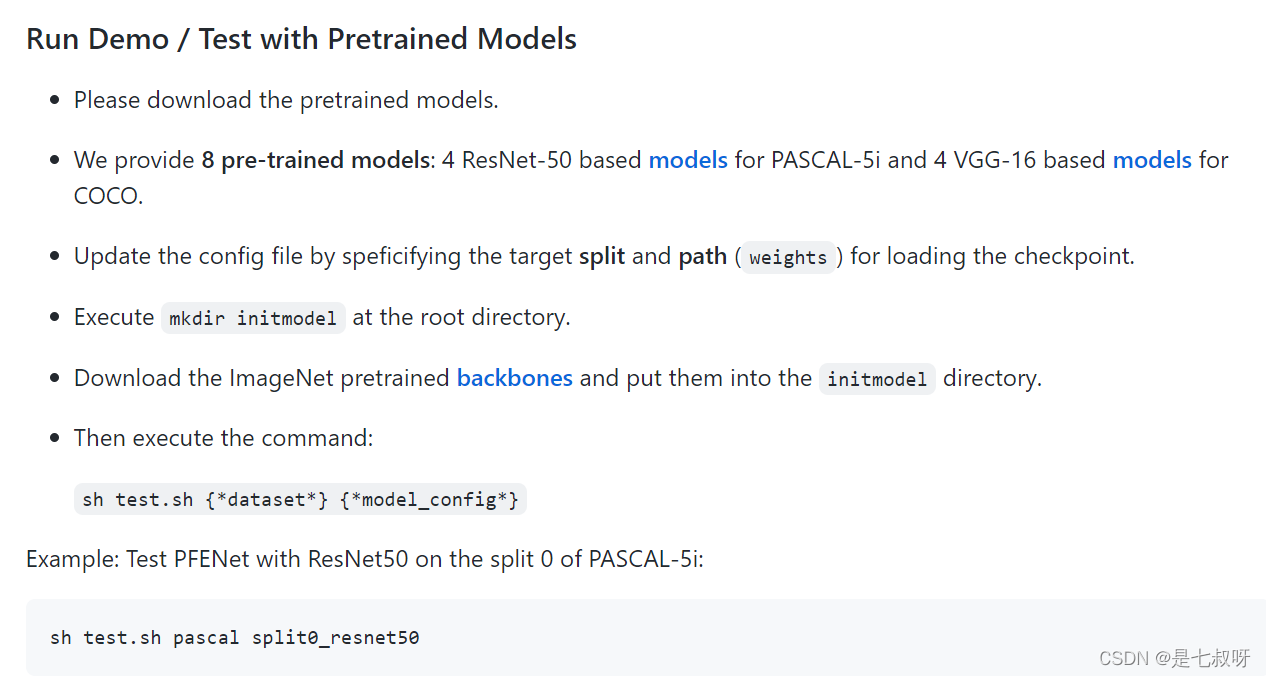
作者提供了4个使用ResNet-50在 PASCAL-5i上训练好的模型参数:
如果要使用预训练的resnet50和vgg1权重,需要下载backbones:

2.1 ResNet网络结构分析
参考链接:ResNet网络结构分析
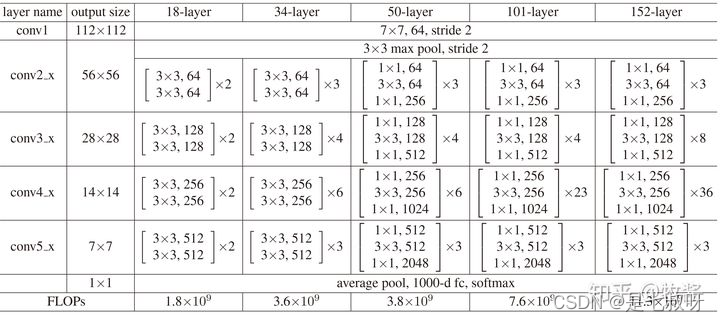
首先,ResNet在PyTorch的官方代码中共有5种不同深度的结构,深度分别为18、34、50、101、152(各种网络的深度指的是“需要通过训练更新参数”的层数,如卷积层,全连接层等),和论文完全一致。图1是论文里给出每种ResNet的具体结构:
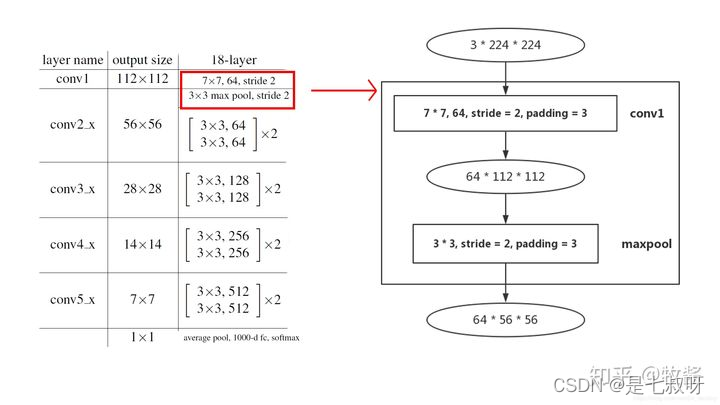
网络最浅层开始:
2.2 train.py
2.21 PFENet网络结构
resnet是由很多以下的结构组成:
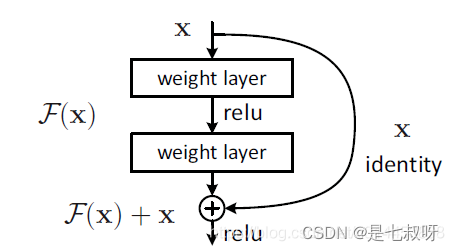
这种结构,当有1x1卷积核的时候,我们叫bottleneck,当没有1x1卷积核时,我们称其为BasicBlock。残差网络一般就是由这两个结构组成的。
残差网络的结构:(例resnet18)
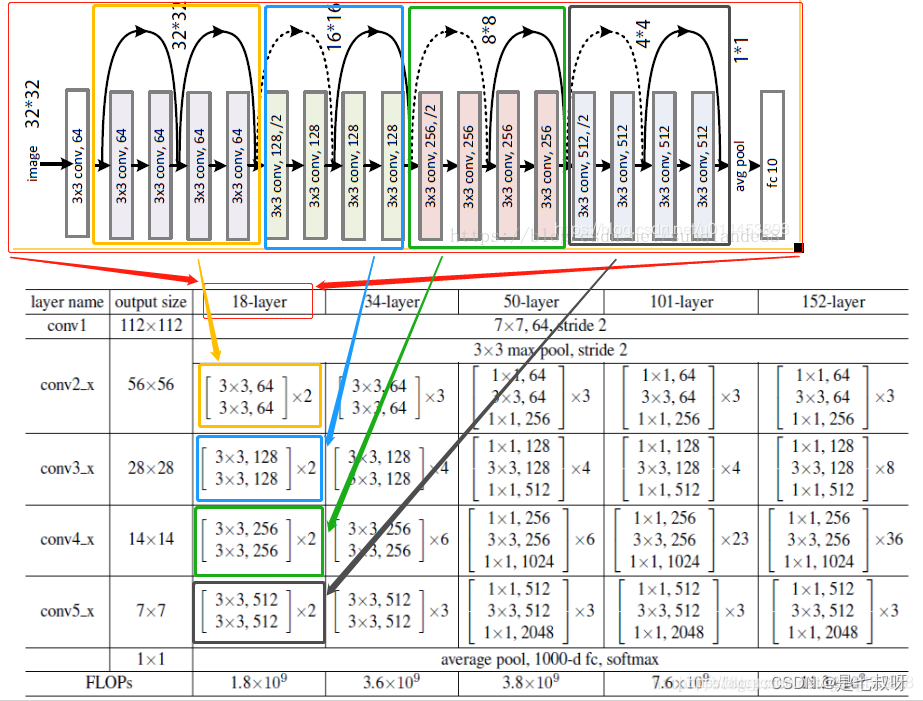
(彩图resnet18的结构图中,虚曲线表示不同维度的连接,实曲线表示相同维度的连接)
从上图可以看到几个重点的关于resnet的特点:
1.resnet18都是由BasicBlock组成的,并且从表中也可以得知,50层(包括50层)以上的resnet才由Bottleneck组成。
2.所有类型的resnet卷积操作的通道数(无论是输入通道还是输出通道)都是64的倍数
3.所有类型的resnet的卷积核只有3x3和1x1两种
4.无论哪一种resnet,除了公共部分(conv1)外,都是由4大块组成(con2_x,con3_x,con4_x,con5_x,),每一块的起始通道数都是64,128,256,512,这点非常重要。暂且称它为“基准 通道数”
了解这些有利于我们理解resnet的源码。
参考:pytorch中残差网络resnet的源码解读
ResNet _make_layer代码理解
在train.py中有如下代码调用forward函数:output, main_loss, aux_loss = model(s_x=s_input, s_y=s_mask, x=input, y=target)
网络输入参数:支撑集图片、mask;查询集图片、mask
forward函数如下:
def forward(self, x, s_x=torch.FloatTensor(1,1,3,473,473).cuda(), s_y=torch.FloatTensor(1,1,473,473).cuda(), y=None):
x_size = x.size()
assert (x_size[2]-1) % 8 == 0 and (x_size[3]-1) % 8 == 0
h = int((x_size[2] - 1) / 8 * self.zoom_factor + 1)
w = int((x_size[3] - 1) / 8 * self.zoom_factor + 1)
# Query Feature
with torch.no_grad():
query_feat_0 = self.layer0(x)
query_feat_1 = self.layer1(query_feat_0)
query_feat_2 = self.layer2(query_feat_1)
query_feat_3 = self.layer3(query_feat_2)
query_feat_4 = self.layer4(query_feat_3)
if self.vgg:
query_feat_2 = F.interpolate(query_feat_2, size=(query_feat_3.size(2),query_feat_3.size(3)), mode='bilinear', align_corners=True)
query_feat = torch.cat([query_feat_3, query_feat_2], 1)
query_feat = self.down_query(query_feat)
# Support Feature
supp_feat_list = []
final_supp_list = []
mask_list = []
for i in range(self.shot):
mask = (s_y[:,i,:,:] == 1).float().unsqueeze(1)
mask_list.append(mask)
with torch.no_grad():
supp_feat_0 = self.layer0(s_x[:,i,:,:,:])
supp_feat_1 = self.layer1(supp_feat_0)
supp_feat_2 = self.layer2(supp_feat_1)
supp_feat_3 = self.layer3(supp_feat_2)
mask = F.interpolate(mask, size=(supp_feat_3.size(2), supp_feat_3.size(3)), mode='bilinear', align_corners=True)
supp_feat_4 = self.layer4(supp_feat_3*mask)
final_supp_list.append(supp_feat_4)
if self.vgg:
supp_feat_2 = F.interpolate(supp_feat_2, size=(supp_feat_3.size(2),supp_feat_3.size(3)), mode='bilinear', align_corners=True)
supp_feat = torch.cat([supp_feat_3, supp_feat_2], 1)
supp_feat = self.down_supp(supp_feat)
supp_feat = Weighted_GAP(supp_feat, mask)
supp_feat_list.append(supp_feat)
corr_query_mask_list = []
cosine_eps = 1e-7
for i, tmp_supp_feat in enumerate(final_supp_list):
resize_size = tmp_supp_feat.size(2)
tmp_mask = F.interpolate(mask_list[i], size=(resize_size, resize_size), mode='bilinear', align_corners=True)
tmp_supp_feat_4 = tmp_supp_feat * tmp_mask
q = query_feat_4
s = tmp_supp_feat_4
bsize, ch_sz, sp_sz, _ = q.size()[:]
tmp_query = q
tmp_query = tmp_query.contiguous().view(bsize, ch_sz, -1)
tmp_query_norm = torch.norm(tmp_query, 2, 1, True)
tmp_supp = s
tmp_supp = tmp_supp.contiguous().view(bsize, ch_sz, -1)
tmp_supp = tmp_supp.contiguous().permute(0, 2, 1)
tmp_supp_norm = torch.norm(tmp_supp, 2, 2, True)
similarity = torch.bmm(tmp_supp, tmp_query)/(torch.bmm(tmp_supp_norm, tmp_query_norm) + cosine_eps)
similarity = similarity.max(1)[0].view(bsize, sp_sz*sp_sz)
similarity = (similarity - similarity.min(1)[0].unsqueeze(1))/(similarity.max(1)[0].unsqueeze(1) - similarity.min(1)[0].unsqueeze(1) + cosine_eps)
corr_query = similarity.view(bsize, 1, sp_sz, sp_sz)
corr_query = F.interpolate(corr_query, size=(query_feat_3.size()[2], query_feat_3.size()[3]), mode='bilinear', align_corners=True)
corr_query_mask_list.append(corr_query)
corr_query_mask = torch.cat(corr_query_mask_list, 1).mean(1).unsqueeze(1)
corr_query_mask = F.interpolate(corr_query_mask, size=(query_feat.size(2), query_feat.size(3)), mode='bilinear', align_corners=True)
if self.shot > 1:
supp_feat = supp_feat_list[0]
for i in range(1, len(supp_feat_list)):
supp_feat += supp_feat_list[i]
supp_feat /= len(supp_feat_list)
out_list = []
pyramid_feat_list = []
for idx, tmp_bin in enumerate(self.pyramid_bins):
if tmp_bin <= 1.0:
bin = int(query_feat.shape[2] * tmp_bin)
query_feat_bin = nn.AdaptiveAvgPool2d(bin)(query_feat)
else:
bin = tmp_bin
query_feat_bin = self.avgpool_list[idx](query_feat)
supp_feat_bin = supp_feat.expand(-1, -1, bin, bin)
corr_mask_bin = F.interpolate(corr_query_mask, size=(bin, bin), mode='bilinear', align_corners=True)
merge_feat_bin = torch.cat([query_feat_bin, supp_feat_bin, corr_mask_bin], 1)
merge_feat_bin = self.init_merge[idx](merge_feat_bin)
if idx >= 1:
pre_feat_bin = pyramid_feat_list[idx-1].clone()
pre_feat_bin = F.interpolate(pre_feat_bin, size=(bin, bin), mode='bilinear', align_corners=True)
rec_feat_bin = torch.cat([merge_feat_bin, pre_feat_bin], 1)
merge_feat_bin = self.alpha_conv[idx-1](rec_feat_bin) + merge_feat_bin
merge_feat_bin = self.beta_conv[idx](merge_feat_bin) + merge_feat_bin
inner_out_bin = self.inner_cls[idx](merge_feat_bin)
merge_feat_bin = F.interpolate(merge_feat_bin, size=(query_feat.size(2), query_feat.size(3)), mode='bilinear', align_corners=True)
pyramid_feat_list.append(merge_feat_bin)
out_list.append(inner_out_bin)
query_feat = torch.cat(pyramid_feat_list, 1)
query_feat = self.res1(query_feat)
query_feat = self.res2(query_feat) + query_feat
out = self.cls(query_feat)
# Output Part
if self.zoom_factor != 1:
out = F.interpolate(out, size=(h, w), mode='bilinear', align_corners=True)
if self.training:
main_loss = self.criterion(out, y.long())
aux_loss = torch.zeros_like(main_loss).cuda()
for idx_k in range(len(out_list)):
inner_out = out_list[idx_k]
inner_out = F.interpolate(inner_out, size=(h, w), mode='bilinear', align_corners=True)
aux_loss = aux_loss + self.criterion(inner_out, y.long())
aux_loss = aux_loss / len(out_list)
return out.max(1)[1], main_loss, aux_loss
else:
return out
PFENet.py中的self.layer0 ,self.layer1, self.layer2, self.layer3, self.layer4

最后一层的分类:
self.cls = nn.Sequential(
nn.Conv2d(reduce_dim, reduce_dim, kernel_size=3, padding=1, bias=False),
nn.ReLU(inplace=True),
nn.Dropout2d(p=0.1),
nn.Conv2d(reduce_dim, classes, kernel_size=1)
)
out = self.cls(query_feat)
在train.py中损失采用二分类交叉熵损失:criterion=nn.CrossEntropyLoss(ignore_index=255),得到main_loss:
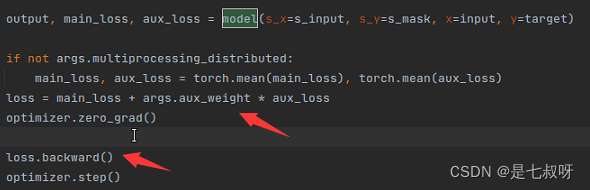
训练的时候返回三个损失output, main_loss, aux_loss = model(s_x=s_input, s_y=s_mask, x=input, y=target)
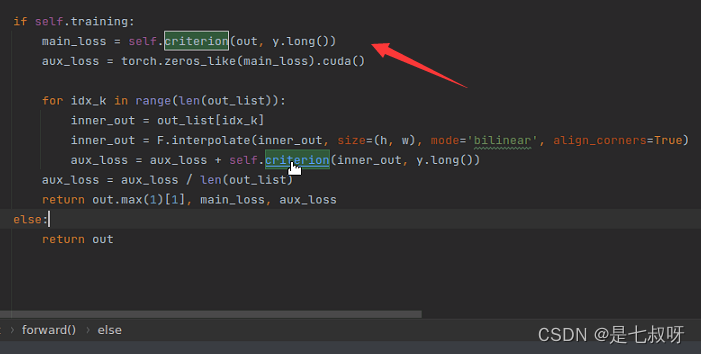
PS: torch.zeros_like:生成和括号内变量维度维度一致的全是零的内容。
输入:
import torch
a = torch.rand(5,1)
print(a)
n=torch.zeros_like(a)
print('n=',n)
输出:
tensor([[0.9653],
[0.5581],
[0.1648],
[0.3715],
[0.2194]])
n= tensor([[0.],
[0.],
[0.],
[0.],
[0.]])
使用总的loss进行反向传播:
2.22 train.py中对loss和IOU的处理
网络输出损失后:
先判断,为False
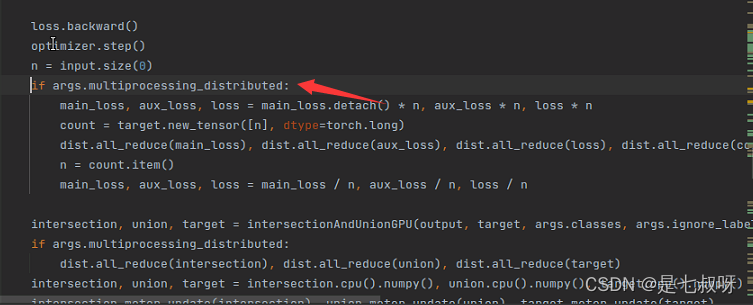
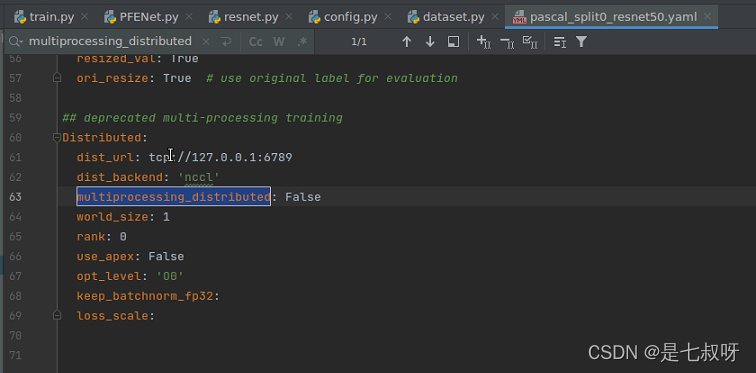
之后进入intersection, union, target = intersectionAndUnionGPU(output, target, args.classes, args.ignore_labe计算交集和并集、target,函数如下:
def intersectionAndUnionGPU(output, target, K, ignore_index=255):
# 'K' classes, output and target sizes are N or N * L or N * H * W, each value in range 0 to K - 1.
assert (output.dim() in [1, 2, 3])
assert output.shape == target.shape
output = output.view(-1)
target = target.view(-1)
output[target == ignore_index] = ignore_index
intersection = output[output == target]
area_intersection = torch.histc(intersection, bins=K, min=0, max=K-1)
area_output = torch.histc(output, bins=K, min=0, max=K-1)
area_target = torch.histc(target, bins=K, min=0, max=K-1)
area_union = area_output + area_target - area_intersection
return area_intersection, area_union, area_target
输入4个参数:
output网络输出target查询集真实maskargs.classes=21(ymal中可以配置)args.ignore_label=255(ymal中可以配置)
先判断尺寸是否一样,output和target尺寸都为(batchsize=64),view(-1)之后展成1维:


使用np.unique(output.cpu().numpy()).tolist()将Tensor转为numpy且查看里面元素:

从intersectionAndUnionGPU函数中可以看出:交集:intersection = output[output == target]- 之后交集:area_intersection = torch.histc(intersection, bins=K, min=0, max=K-1)
并集:area_union = area_output + area_target - area_intersection
PS:经过torch.histc函数
torch.histc(input, bins=100, min=0, max=0, *, out=None) → Tensor
计算张量的直方图。
Parameters
- input(Tensor)–输入张量。
- bins(int)–直方图箱数
- min(int)–范围的下限(包括)
- max(int)–范围的上限(包括)
例:bins是4,说明有4个块;其中min和max可以看出(0、1、2、3)
>>> torch.histc(torch.tensor([1., 2, 1]), bins=4, min=0, max=3)
tensor([ 0., 2., 1., 0.])
asgnet中util.py代码使用:
area_output = torch.histc(output, bins=K, min=0, max=K-1)
最后函数返回值:
return area_intersection, area_union, area_target
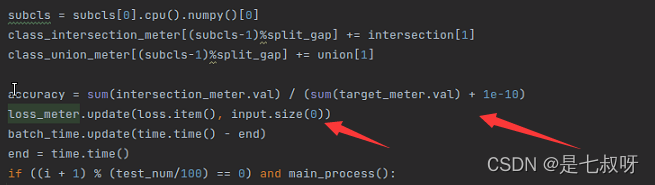
程序继续进行,计算train的mIOU、accuracy_class:
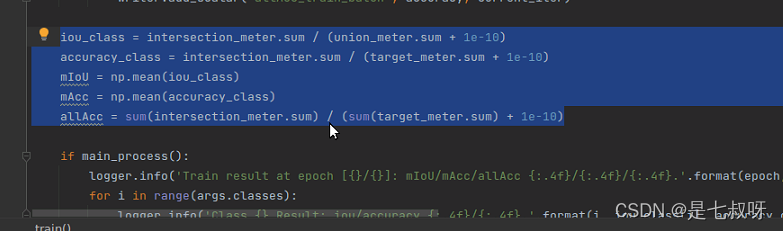
训练过程产生的输出,main_loss、aux_loss、loss = main_loss + args.aux_weight * aux_loss、accuracy = sum(intersection_meter.val) / (sum(target_meter.val) + 1e-10):

后面的输出显示:

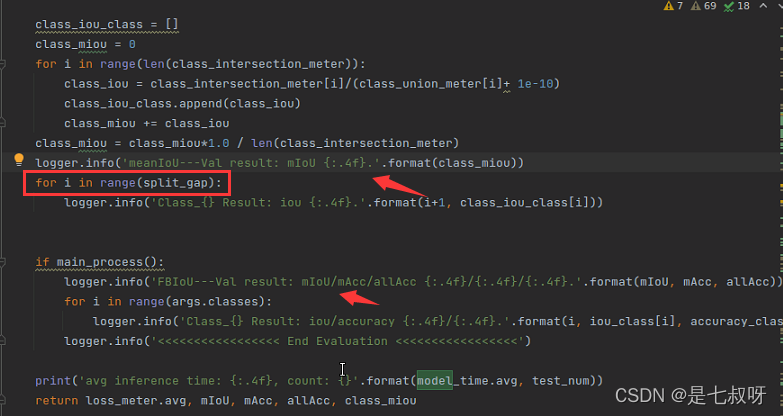
for i in range(args.classes):
logger.info('Class_{} Result: iou/accuracy {:.4f}/{:.4f}.'.format(i, iou_class[i], accuracy_class[i]))
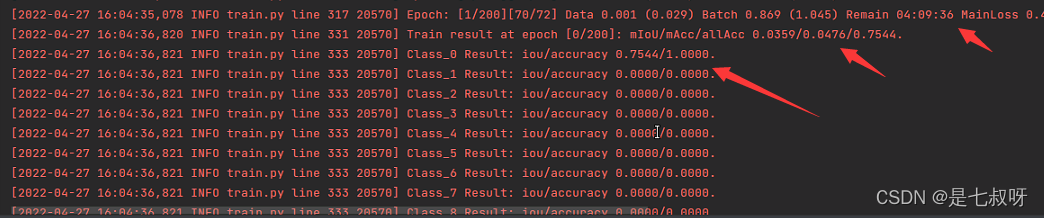
三、网络测试
使用5个未加入训练的类进行验证
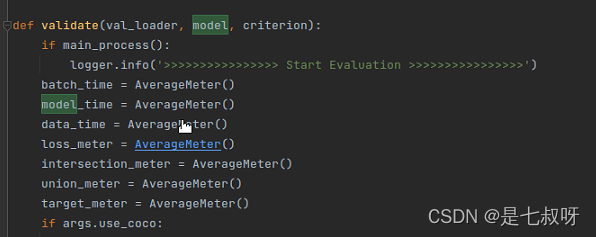
得到网络输出:output = model(s_x=s_input, s_y=s_mask, x=input, y=target)
经过intersectionAndUnionGPU函数得到intersection, union, new_target(和训练时候的函数是同一个):
intersection, union, new_target = intersectionAndUnionGPU(output, target, args.classes, args.ignore_label)
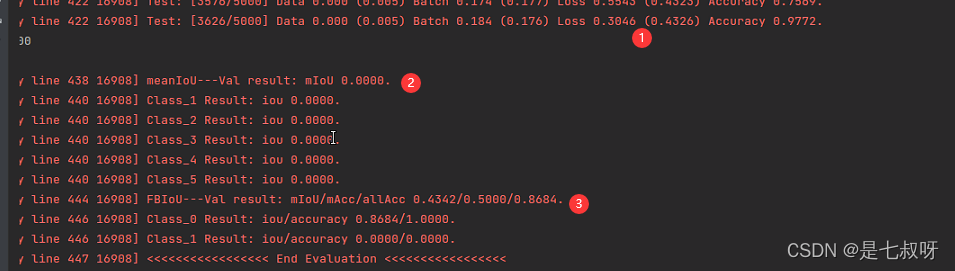
首先打印Loss 0.3046 (0.4326) Accuracy 0.9772.:

之后打印mIOU和F-IOU:
3.1 加载测试权重
这里test后结果为0的原因是没有加载权重进去。【而train.py中是训练几个epoch,使用当前参数val一次,不用load】
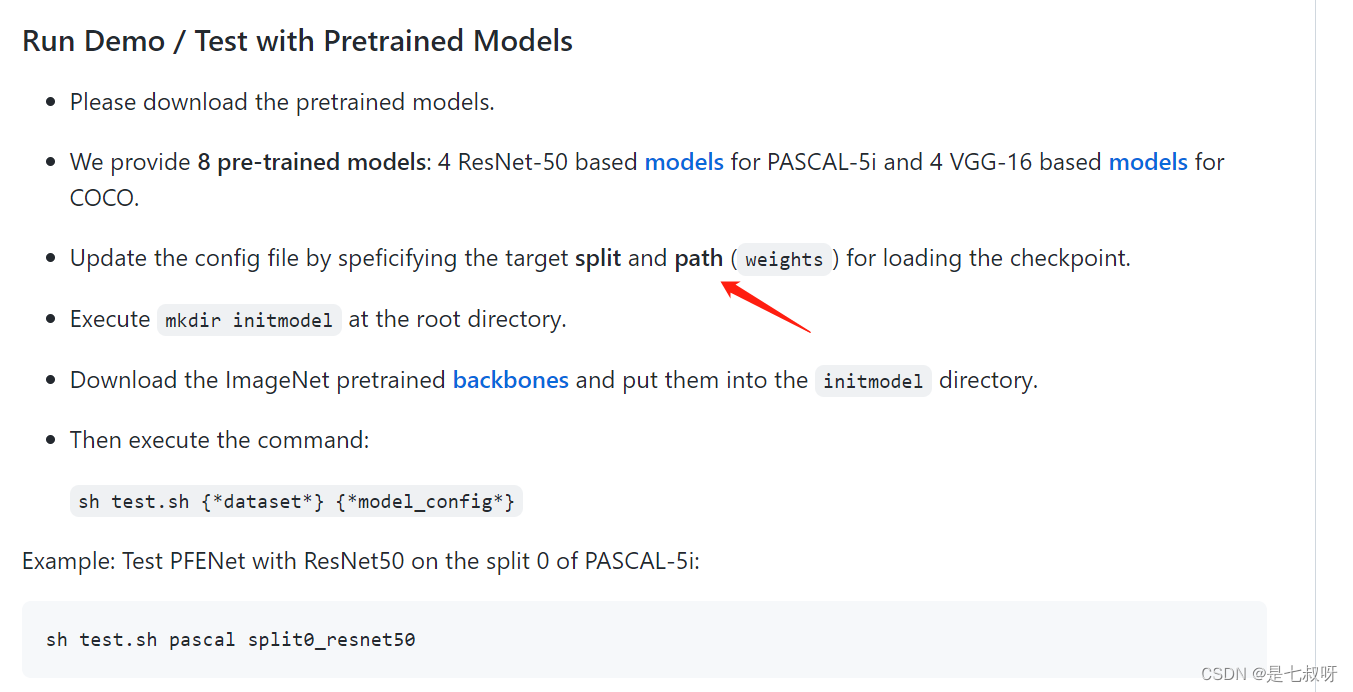
这里test.py中要修改一下:
config的位置

加载权重的地方
!!!【 P F E N e t 中 \color{red}{PFENet中} PFENet中,如果特征提取直接融合Timm库中的swin transformer做特征提取,自测使用多卡并行训练会报错:模型不在同一个GPU显卡上,所以这时候就要用到单GPU训练了】
- 网络在进行单GPU训练的时候运行test.py使用:
model.load_state_dict(checkpoint),命令行可以使用:python test.py也可以使用指定GPU的:CUDA_VISIBLE_DEVICES=2 python test.py
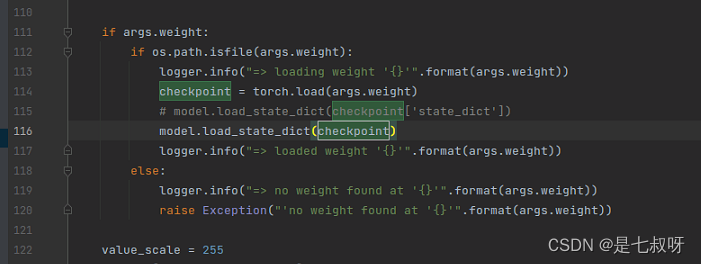
- 多GPU并行的时候【一般情况下】:
model.load_state_dict(checkpoint['state_dict'])
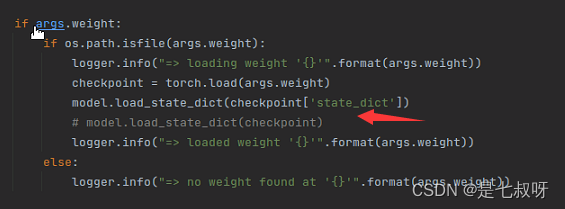
然后yaml配置文件也要修改一下文件位置为自己的权重文件位置。

我使用作者github的权重,进行测试的结果:split0的mIOU为
61.78
\color{red}{61.78}
61.78

感兴趣的话也可以使用作者权重test一下可能会比作者的还要高哦(⊙o⊙)【比如未来的某陈大佬同学】:
3.2 作者的GitHub中关于不能复现问题的答复
两个原因:
- 要使用单GPU训练
- 作者在训练的时候测试的轮数是2000,test的时候是5000
其中有人使用作者训练好的权重进行测试,对于1shot和5shot好多Split效果都变的更好了,总的mean也有提升:
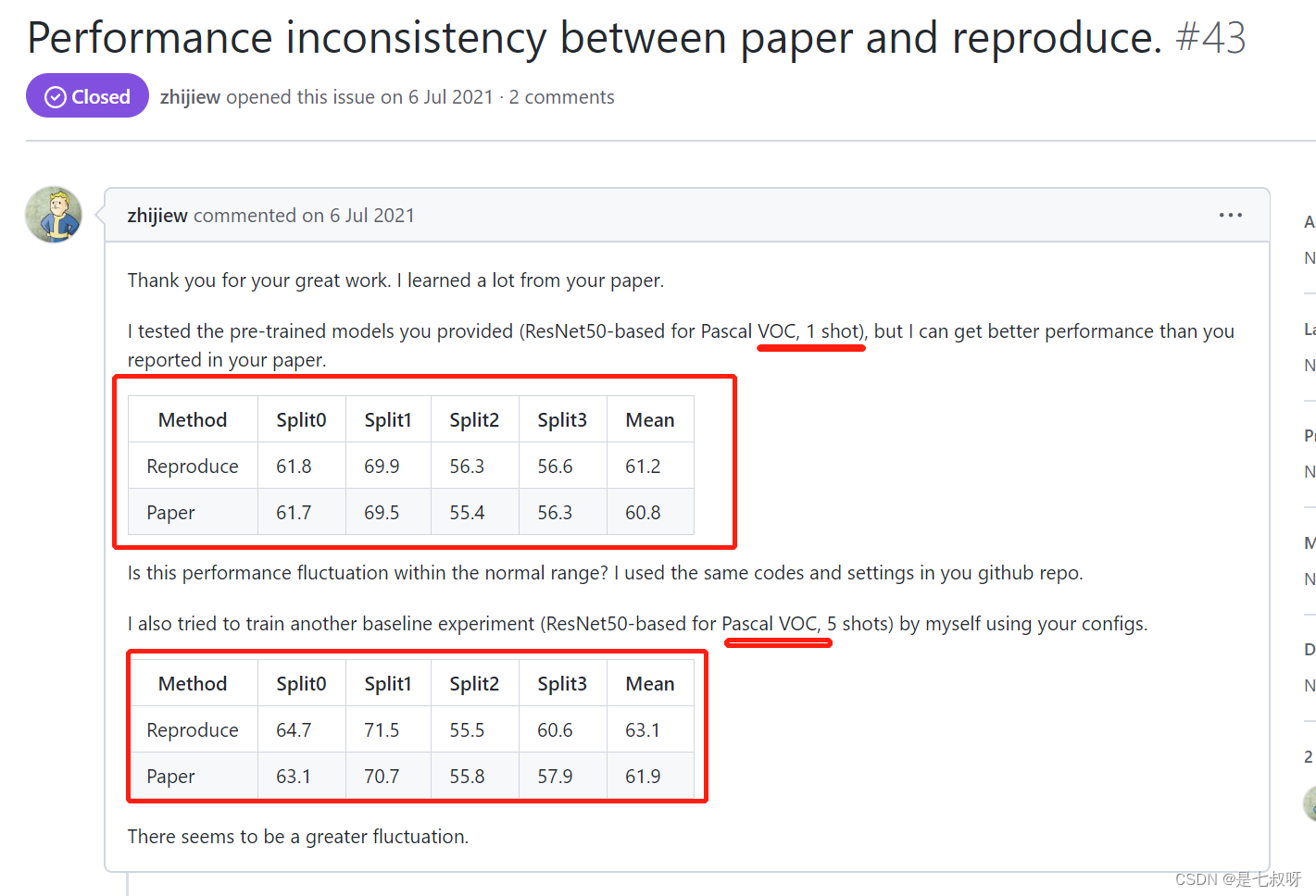
作者回复他也不清楚为什么会变好,可能是不同的运行环境可能会导致性能波动。
根据#6中的相关讨论,您的复制品的单次性能差异是可以接受的。
对于5shot的结果,在本文中,我们用5个支持样本直接测试了用1次激发训练的模型,但这可能不是最佳情况,这可以解释为什么您可以获得比我们报告的更好的5次激发结果。
四、添加训练曲线函数
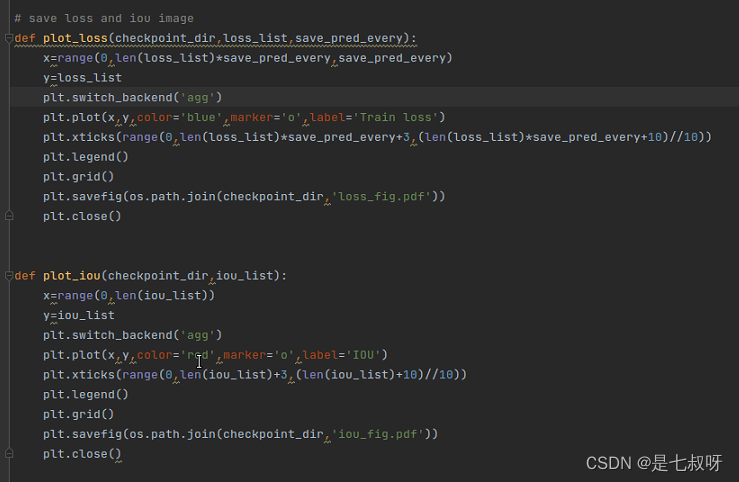
4.1 在util文件夹的util.py中添加函数plot_loss和plot_iou(之前ASGNet写好的):
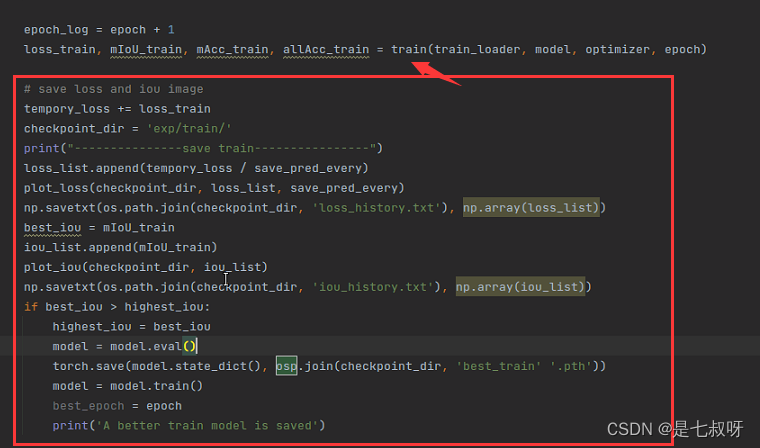
4.2 在train.py中模型train和val后行添加写好的模块:
在epoch中
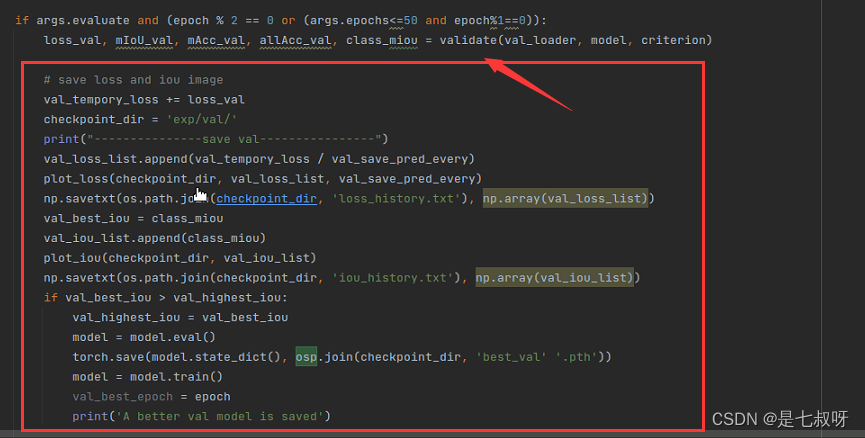
4.3 添加未定义的参数------在train.py的最前面添加追踪训练和验证的list,在每个epoch前定义train需要的参数
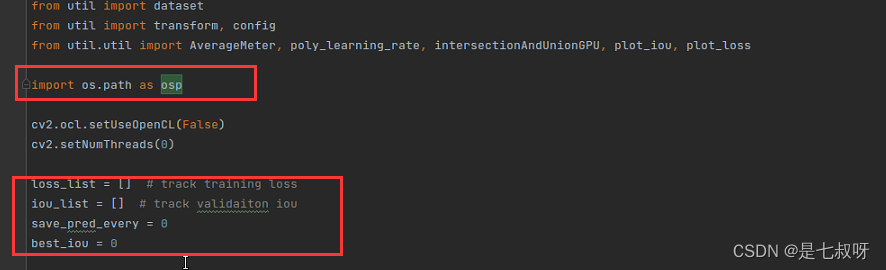
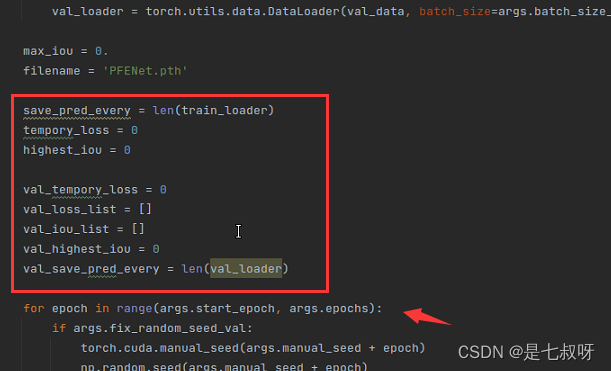















 4247
4247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









