







背景
我需要获取堪培拉SA2 level 下的区域列表并获取每个区域的人口数量。由于网站上没有直接的列出SA2 level下对应区域的人口,需要人工点击区域进行查询。 所以我希望可以通过Python爬虫辅助我完成这个工作。已知堪培拉SA2 level 下的区域有135个。
目标
- 获取SA2 level 的区域ID
- 需要获取SA2 level下的人口数据
- 保存到excel文件
开始获取
第一步-浏览网页
网址:https://www.abs.gov.au/census/find-census-data/quickstats/2021/801091107
通过浏览网页发现每一个区域有一个对于的区域ID,在URL的结尾也有对应的区域ID。
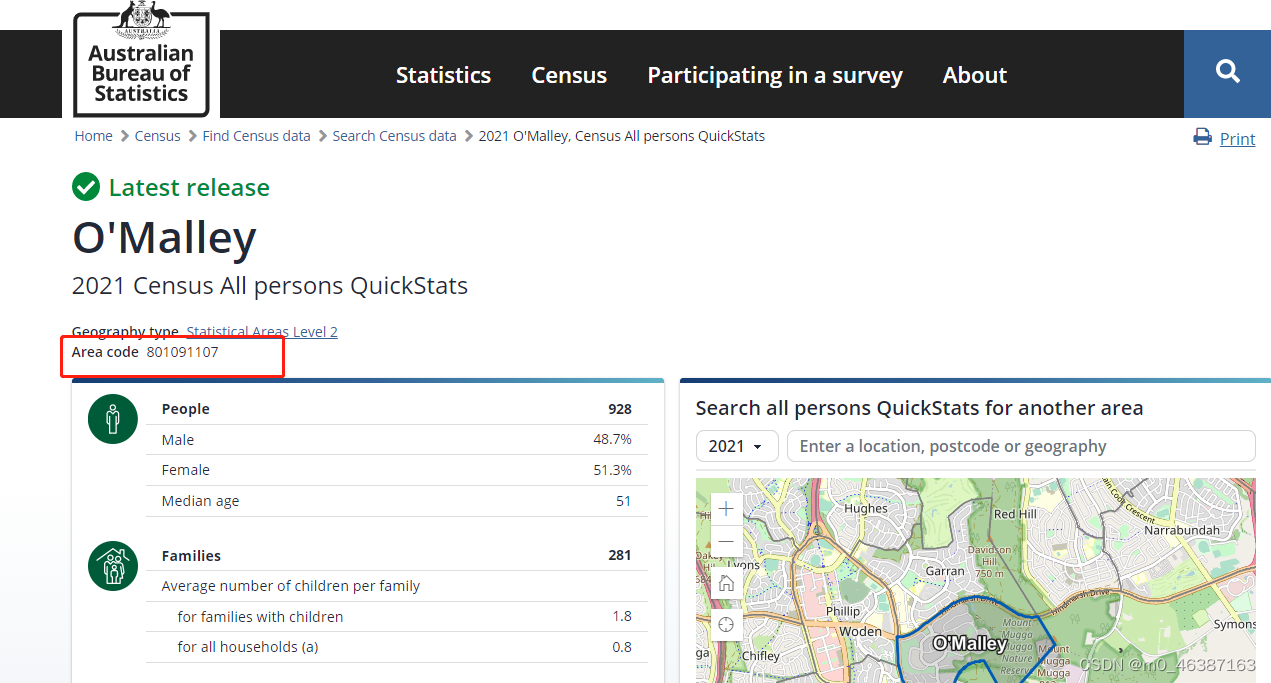
第二步-获取区域ID
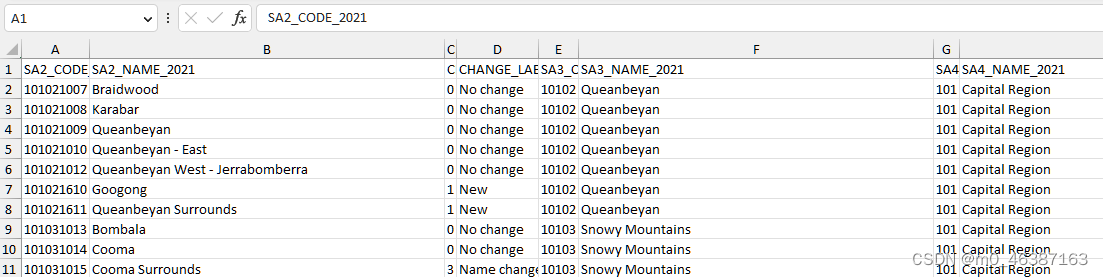
我需要获取SA2 level下的区域ID
这个可以在ABS上找到
网址:https://www.abs.gov.au/statistics/standards/australian-statistical-geography-standard-asgs-edition-3/jul2021-jun2026/main-structure-and-greater-capital-city-statistical-areas/statistical-area-level-2
第三部-编写代码
- 在页面中找到人口的数据对应的元素
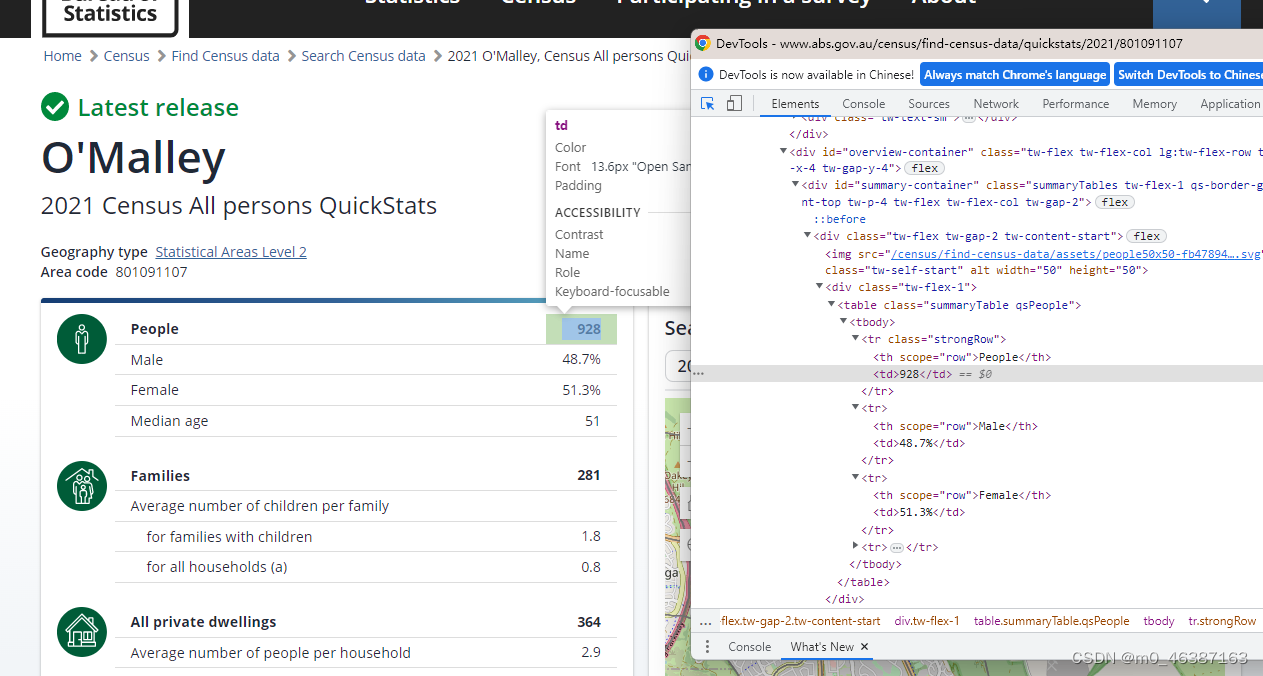
在图片中我们可以看到people对应的人口数据在class为“strongRow”的tr下,所以我们需要获取tr下td的值
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_element(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
# 假设你要抓取的元素是一个带有特定类名的<tr>标签
target_element = soup.find('tr', {'class': 'strongRow'})
if target_element:
target_td = target_element.find('td')
if target_td:
people = target_td.text.strip()
return people
else:
print("err")
return None
else:
print(f'在URL {url} 中未找到目标元素')
return None
else:
print(f'无法访问URL {url}')
return None
- 读取Excel的区域ID并新增一列
# 读取Excel文件
input_file = 'SA2_ACT.xlsx' # 你的Excel文件名
sheet_name = 'default_1' # 你的工作表名
id_column = 'SA2_CODE_2021' # 包含ID的列名
df = pd.read_excel(input_file, sheet_name=sheet_name)
df['people'] = None
- 根据Excel里的ID去进行请求
# 遍历数据框,访问URL并抓取元素
for index, row in df.iterrows():
id = row[id_column]
url = f'https://www.abs.gov.au/census/find-census-data/quickstats/2021/{id}'
element = fetch_element(url)
if element:
df.at[index, 'people'] = element
print(f'ID {id} 对应的元素:{element}')
- 将数据写入Excel
# 将结果保存到新的Excel文件
output_file = 'output.xlsx'
df.to_excel(output_file, index=False)
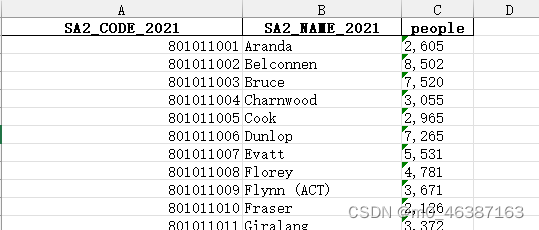
效果展示
完整代码
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_element(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.content, 'html.parser')
# 假设你要抓取的元素是一个带有特定类名的<div>标签
target_element = soup.find('tr', {'class': 'strongRow'})
if target_element:
target_td = target_element.find('td')
if target_td:
people = target_td.text.strip()
return people
else:
print("err")
return None
else:
print(f'在URL {url} 中未找到目标元素')
return None
else:
print(f'无法访问URL {url}')
return None
# 读取Excel文件
input_file = 'SA2_ACT.xlsx' # 你的Excel文件名
sheet_name = 'default_1' # 你的工作表名
id_column = 'SA2_CODE_2021' # 包含ID的列名
df = pd.read_excel(input_file, sheet_name=sheet_name)
# 在数据框中添加一个新列'people'
df['people'] = None
# 遍历数据框,访问URL并抓取元素
for index, row in df.iterrows():
id = row[id_column]
url = f'https://www.abs.gov.au/census/find-census-data/quickstats/2021/{id}'
element = fetch_element(url)
if element:
df.at[index, 'people'] = element
print(f'ID {id} 对应的元素:{element}')
# 将结果保存到新的Excel文件
output_file = 'output.xlsx'
df.to_excel(output_file, index=False)














 735
735











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









