







本文代码及数据集来自《Python大数据分析与机器学习商业案例实战》
# 1.读取数据
import pandas as pd
movies = pd.read_excel('电影.xlsx')
movies.head()
score = pd.read_excel('评分.xlsx')
score.head()
df = pd.merge(movies, score, on='电影编号') # 通过“电影编号”列关联起来
df.head()
df.to_excel('电影推荐系统.xlsx') # 将该汇总表导出为excel
print(df['评分'].value_counts()) # 查看各个评分的出现的次数
import matplotlib.pyplot as plt
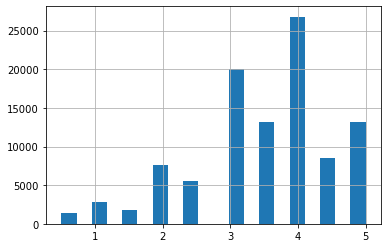
df['评分'].hist(bins=20) # hist()函数绘制直方图,竖轴为各评分出现的次数
plt.show()
可以看到,评分大多在3~4分之间。运行结果:

# 2.数据分析
ratings = pd.DataFrame(df.groupby('名称')['评分'].mean()) # 计算每部电影的评分均值
print(ratings.sort_values('评分', ascending=False).head()) # 从高到低排序
ratings['评分次数'] = df.groupby('名称')['评分'].count()
print(ratings.sort_values('评分次数', ascending=False).head())
运行结果:

可以看到,这5部电影的评分均值为5分,这可能是因为评分次数较少且普遍评分较高的缘故。

# 3.数据处理
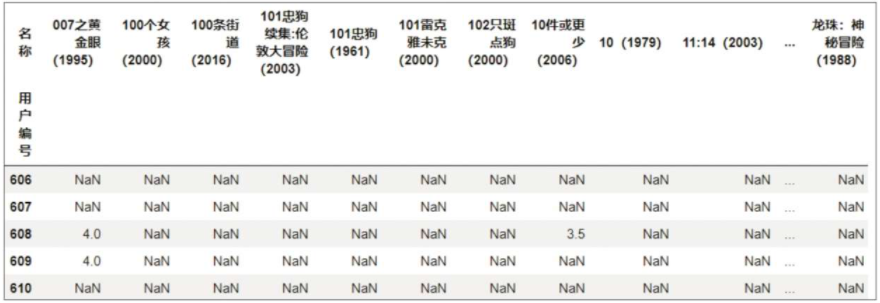
user_movie = df.pivot_table(index='用户编号', columns='名称', values='评分') # 转换为数据透视表
print(user_movie.tail())
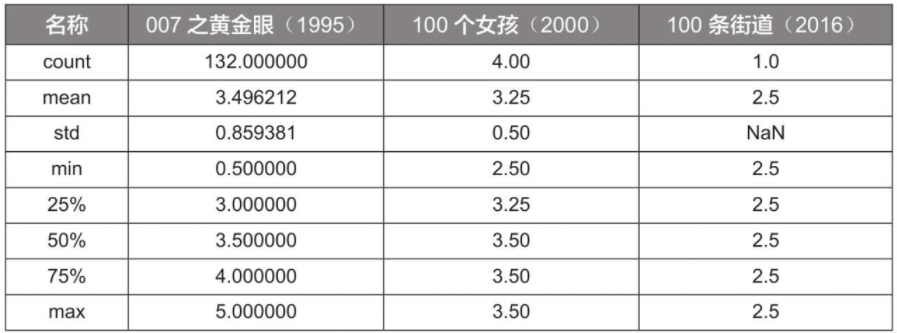
print(user_movie.describe()) # 因为数据量较大,这个耗时可能会有1分钟左右
运行结果:
# 4.智能推荐
FG = user_movie['阿甘正传(1994)'] # FG是Forrest Gump(),阿甘英文名称的缩写
pd.DataFrame(FG).head()
corr_FG = user_movie.corrwith(FG)
similarity = pd.DataFrame(corr_FG, columns=['相关系数'])
similarity.head()
# 剔除NaN值
similarity.dropna(inplace=True) # 或写成similarity=similarity.dropna()
similarity.head()
# 表格合并方法一
similarity_new = pd.merge(similarity, ratings['评分次数'], left_index=True, right_index=True)
similarity_new.head()
# 表格合并方法二
similarity_new = similarity.join(ratings['评分次数'])
similarity_new.head()
similarity_new[similarity_new['评分次数'] > 20].sort_values(by='相关系数', ascending=False).head() # 选取阈值
运行结果:

















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









