







 本文详细介绍了MySQL的工作机制,包括客户端与服务器的交互、文件结构、查询优化和存储引擎。深入探讨了InnoDB存储引擎的行格式、数据页结构以及字符集和比较规则。重点分析了InnoDB的行溢出数据、页目录和页头部等关键概念,帮助读者理解MySQL内部的存储和访问机制。
本文详细介绍了MySQL的工作机制,包括客户端与服务器的交互、文件结构、查询优化和存储引擎。深入探讨了InnoDB存储引擎的行格式、数据页结构以及字符集和比较规则。重点分析了InnoDB的行溢出数据、页目录和页头部等关键概念,帮助读者理解MySQL内部的存储和访问机制。
说明
文章的图片来源《MySQL是怎么运行的:从根儿上理解MySQL》,欢迎大家买一本看看,对于mysql是由浅入深的讲解非常细致
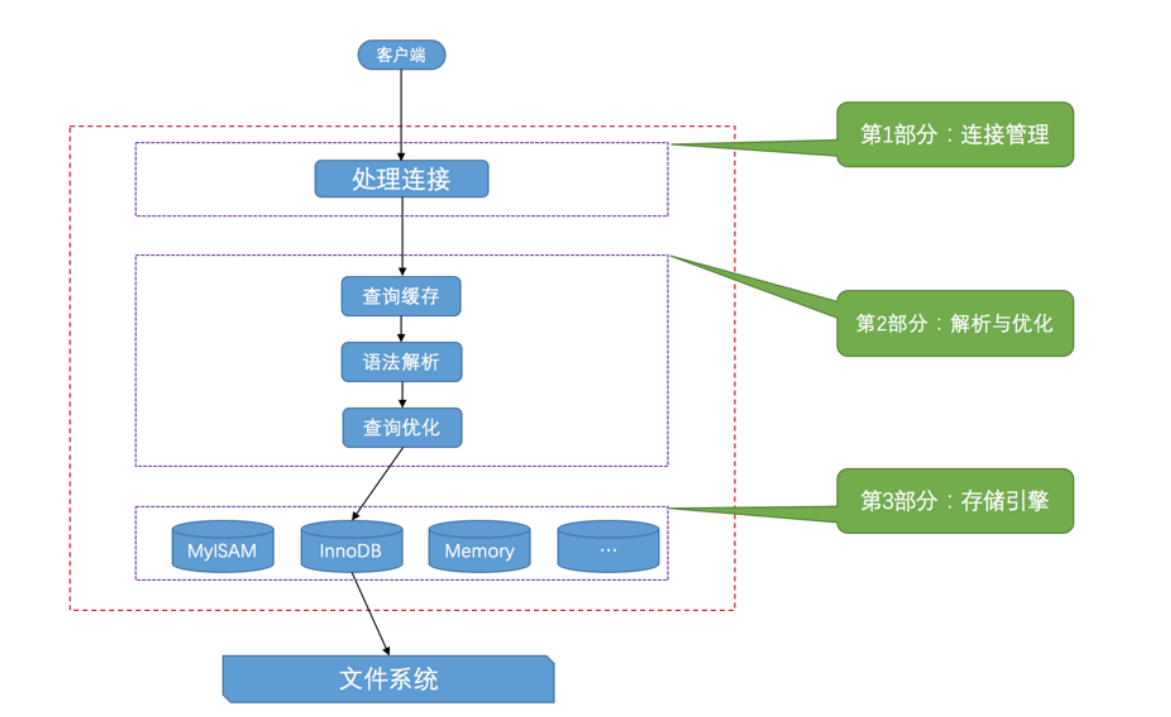
1.mysql的工作机制
- 客户端发送命令
- 服务器端接收并且处理
1.文件
- bin目录,执行文件
- mysqld:服务器程序
- mysqld-safe:启动脚本,监控程序
- mysql-server:启动脚本,简介调用mysqld-safe
- mysqladmin、mysqldump:客户端
2.mysql使用的协议
- 使用的是TCP协议进行请求和应答
3.连接管理
- 服务器端会通过开启线程来与客户端进行连接,如果断开连接之后线程会被缓存并且等待下一次的连接
4.解析和优化
查询缓存
- 就是查询的请求和结果缓存起来
- 但是缓存失效太快,mysql没有人聪明,就算是缓存了一次结果,但是由于请求一点点不同都不会命中缓存,而且表只要发生修改就需要重新加载缓存,缓存失效
语法解析
- 相当于就是一个编译的过程
查询优化
- 对语句进行优化,比如连接使用的索引,使用什么索引,需不需要调换表的位置。相当于就是一个执行计划
存储引擎
- 数据的存储和提取操作都在存储引擎
- 怎么把数据写到数据库上,读取都是引擎的工作
2.启动和配置文件
启动选项
- 比如客户端允许连接数,使用的存储引擎等。
配置文件的使用选项
- my.ini或者是my.cnf
配置文件内容
- server,作用与所有服务器端的启动配置
- mysqld
- client,作用与所有客户端的启动配置
- mysql
- mysqladmin
格式就是option1=xxx
启动命令可以读取的分组
mysqld 启动服务器 [mysqld]、[server]
mysqld_safe 启动服务器 [mysqld]、[server]、[mysqld_safe]
mysql.server 启动服务器 [mysqld]、[server]、[mysql.server]
mysql 启动客户端 [mysql]、[client]
mysqladmin 启动客户端 [mysqladmin]、[client]
mysqldump 启动客户端 [mysqldump]、[client]
系统变量
- 影响程序行为的变量,比如max_connections、default_storage_engine
- 修改变量可以通过修改my.ini的[server]里面的变量
系统变量的作用范围
不同客户端可能需要不同引擎之类的,就需要系统变量的范围,能够让客户端互不干扰。
- global:全局变量,影响服务器
- session:会话变量,影响一个客户端
- 某个客户端修改global不会影响当前客户端的系统变量,但是会影响后面进来会话的变量
-- set session default_storage_engine=MyISAM
-- show session variables like "default_storage_engine"\
show global variables like 'default_storage_engine';
状态变量
- Thread_connected多少个线程正在连接
- 他们的值只能是程序自己来进行配置
show status like 'thread%'
3.字符集和比较规则简介
怎么存储字符集?
- 建立字符和二进制之间的关系
- 哪些字符映射为二进制数据
- 怎么映射
字符映射成二进制这个过程也可以叫做编码,二进制映射回字符就是解码
常见字符集
- acsii:128个字符
- utf-8:基本上收录世界上的所有字符
Mysql支持的字符集
-
utf-8
-
utf-8mb3:减少某些字符的存储字节,为了提升系统的性能
-
支持41种字符集show charset
字符集的比较规则
- SHOW COLLATION LIKE ‘utf8_%’;展示utf-8的所有比较规则

-
show variables like 'CHARACTER_set_server’查看服务器级别的字符集
-
show variables like 'collation_server’查看字符集的比较规则
-
只修改字符集,就会修改为当前字符集的默认比较规则
-
修改默认比较规则,那么字符集就会被修改为比较规则对应的字符集
字符集的作用
- 比如一个’我’在GBK里面占用的字节是4,但是到utf-8就是6个字节。合理使用字符集可以减少资源占用
字符集的转换
- 如果客户端和服务器端并不是使用同一个字符集,造成的问题就是乱码。根据上面的字符集的作用,也知道gbk解码和utf-8解码的同一个字符都是不同的方法。
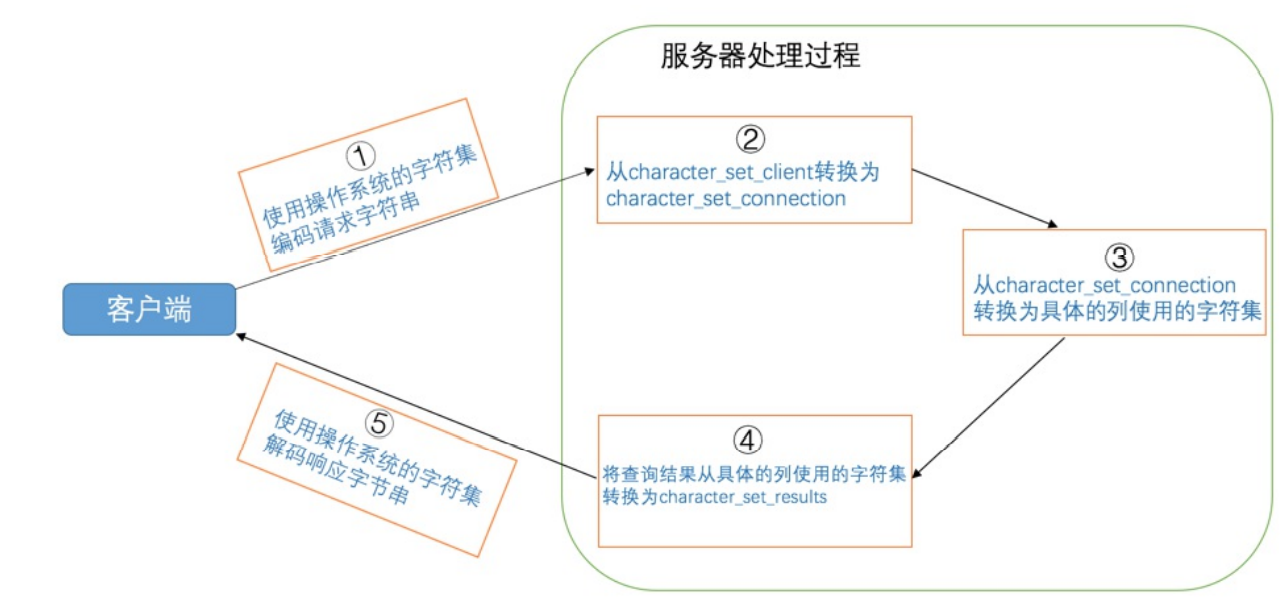
- 客户端和服务器实际上交流也是通过字符串,这里有三个重要系统变量
- character_set_client服务器解码使用的字符集
- character_set_connection服务器处理请求会把character_set_client转换为character_set_connetion
- character_set_results 服务器向客户端返回数据使用的字符集
- 客户端发送使用的是character_set_client,这个时候服务器转换到connection的时候也是这么认为的,如果客户端采用的是不同的编码就会导致转换失败
- character_set_result是服务器发送给客户端的,客户端的解码一定是要跟character_set_result设置的是一样才能够解码成功
- character_set_connetion相当于就是一个转换器,交给服务器去处理。但是如果character_set_connetion中有不认识的字符也会导致最后的错误.比如utf-8->ascii
- 如果希望修改client字符集只需要在ini中[client]配置default-character-set=utf8
总结
- 字符集是某个字符范围的编码规则
- 比较规则是字符串比较的一种方式
- 一个比较规则对应一个字符集
- 字符集的比较规则四个级别
- 服务器级别
- 数据库级别
- 表级别
- col级别
- 字符集从客户端转换到服务器端
4.Innodb存储结构
- 表的数据存到了哪里?
- 什么格式存储?
- mysql以什么方式来访问这些数据
innodb简介
- 发生数据处理是在内存
- innodb获取数据并不是一行一行地读而是把数据分成很多个页,一个页一个页地读,通常是16KB
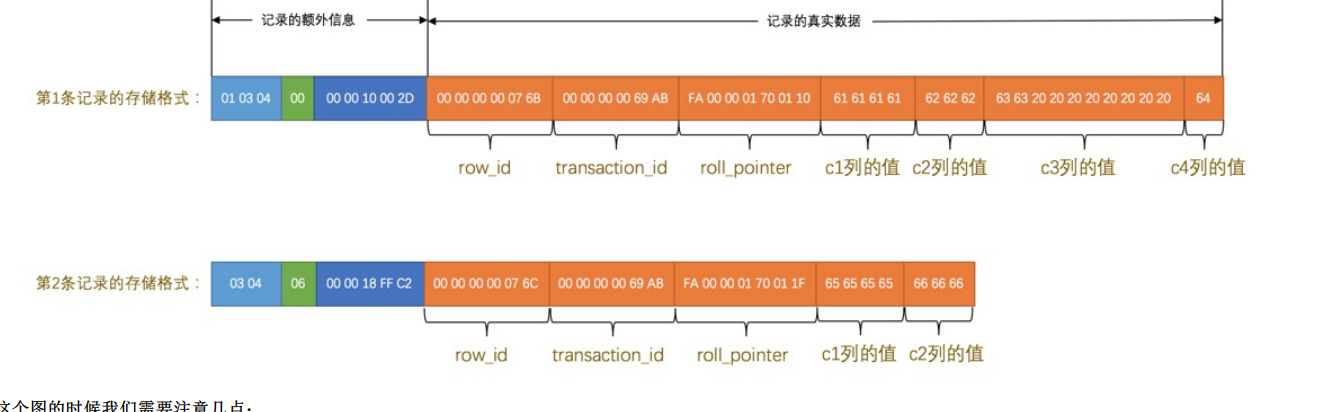
Innodb的行格式
Compact格式
一条完整的记录
- 额外信息
- 真实数据
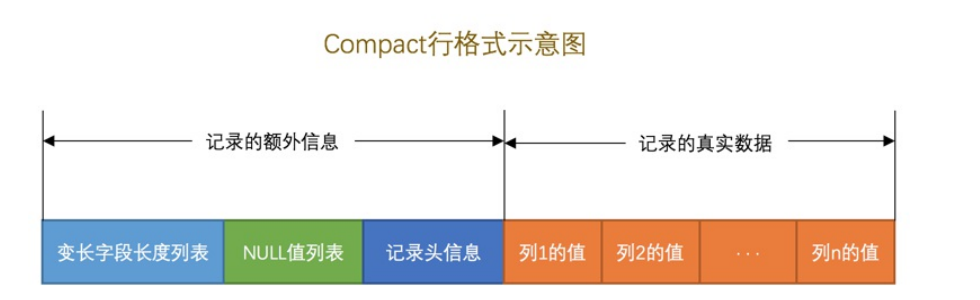
变长字段长度列表
- 各种varchar 、blob、varbinary、text
- 分为了两个部分
- 真正数据内容
- 占用字节数
- 实际上就是保存了每个列的一个字节长度到底是多少,而且按照列的逆序来排序。
- 这里区分是两个字节还是一个字节主要是看第一个二进制是不是0,如果是0那么就是单独一个字节,如果不是那么就是两个字节

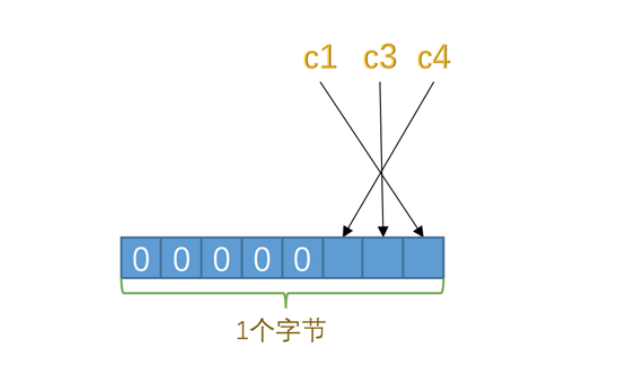
null列表值
- 也是对应列的逆序,1即使null,0就是非null。意思就是列的值是否是null
- 而且规定一定就是一个字节,如果null不够,那么就在高位补0。
比如这里只有3个值是null,那么很自然就是倒序的二进制位是1.c1列最后,c3倒数第二,c4倒数第三
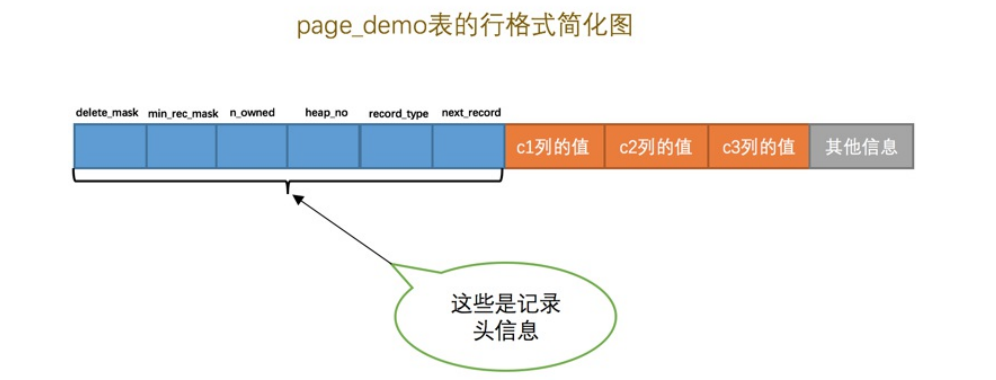
记录头信息
- 五个字节组成
- 预留位1:没有使用
- 预留位2:没有使用
- delete_mask:标记记录是否被删除
- min_rec_mask:B+树每层非叶子节点最小记录都会添加这个标记
- n_owned:拥有的记录数
- heap_no:表示堆的位置
- recode_type:表示记录的类型,0普通记录、1是B+树的非叶子节点记录、2是最小记录、3表示最大的记录
- next_record:表示下一条记录的相对位置

记录真实数据
除了主要的数据还有几个隐藏的列
- row_id:行id
- transaction_id:事务id
- roll_pointer:回滚指针
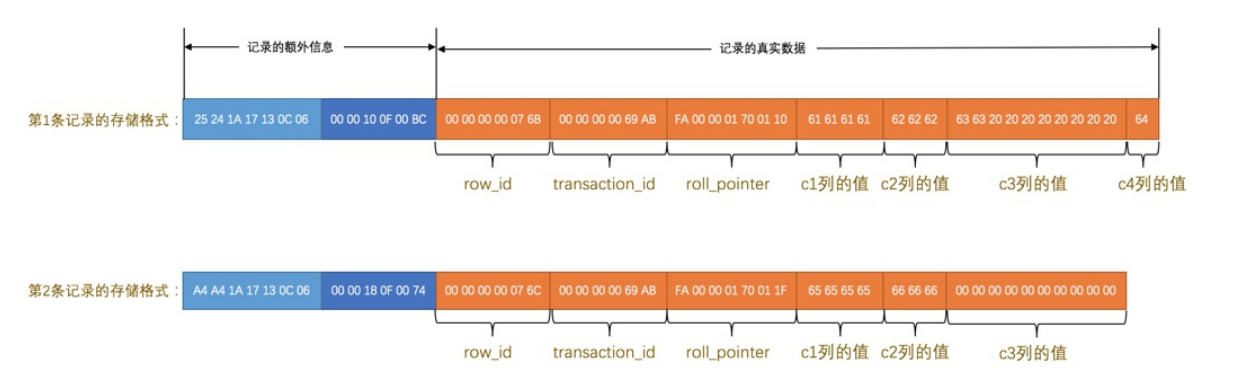
- 这里的第一条记录的c3的占用字节(char(10))是10个,但是实际上只是使用了’cc’就是0x6363后面全部使用0x2020来进行填充那些不需要使用的字节
- 第二个记录里面的c3和c4已经是null,索引存储到了null记录后面就不占用任何字符了。
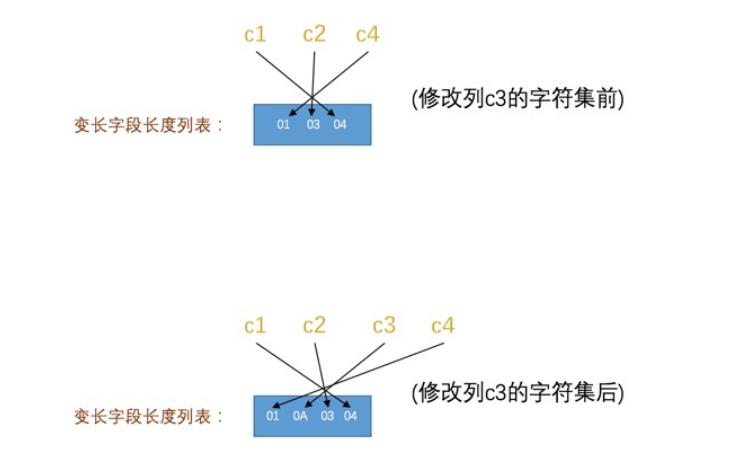
char(M)存储格式
-
ascii是一个定长字符集(一个字符一个字节),但是utf-8(一个字符1-3个字节)并不是
-
对于char(m)来说如果是使用定长字符集,占用的字节数不会放到边长字段长度列表,但是如果是使用变长字符集那么就会放入
Redundant格式
- 开头是字段长度偏移列表,没有了变长两个字
- 所有列的长度都会被倒序记录到长度列表
- 多了偏移,使用相邻两个的数值计算长度
记录头信息
- 多了n_field和1byte_offs_flag
- 但是没有record_type
1byte_offs_flag
-
字符长度偏移记录字符串结束位置
-
那么什么时候使用一个字节或者是两个字节来判断每个列的存储?
①如果列的存储不大于127使用一个字节
②如果大于127但是不大于32767那么就使用两个字节来表示偏移量
null值处理
- 其实就是偏移量的第一个bit来记录,所以这就是为什么列只能是>127的时候就使用2个字节的原因
- 如果是定长比如是char(10)那么null值也会用于记录真实数据
- 如果是变长类型则不记录真实数据,而且不占据存储空间,比如前一个的偏移是36,那么下一个如果是null那么偏移也是36,表示下一个就是null
char(M)存储格式
- 一个字符需要的字节数*M(需要字符的个数)
行溢出数据
- 最多存储不超过65532,但是如果列是非空那么就能节省一个null的bit出来(ascii)
- 但是如果是gbk每个字符是2个字节,那么只能存储65532/2个最长的字符。M*n(n是每个字符需要的字节数)

如果一个页存储不够
- 一个页16kB,也就是说是16484个字节,但是如果存储65532个字节,那么一个页是不足以存储这么的数据的。那么剩下来的真实数据的20个字节就是指向下一个页地址存储数据
- 第一行记录最多只能有768个字节
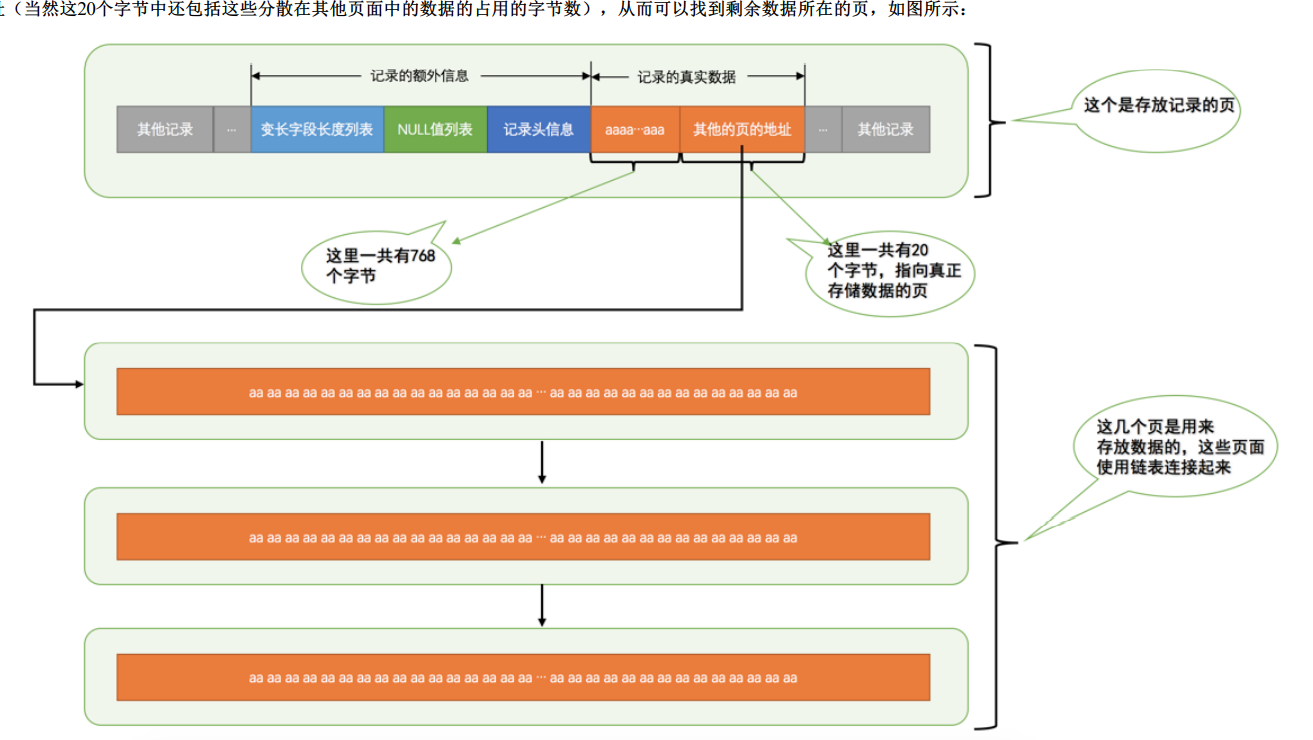
那么什么时候会出现行溢出
- 额外信息占了136个字节,其它空间都是存储数据的
- 每个记录的额外信息是27个字节
- 2个字节用于存储真实数据的长度
- 1个字节用于存储列是否是NULL值
- 5个字节大小的头信息
- 6个字节的row_id列
- 6个字节的transaction_id列
- 7个字节的roll_pointer列
如果是行溢出就是136 + 2×(27 + n) > 16384
总结
- 页是mysql内存和磁盘的交互基本单位
- create table 表名 row_format=行格式数据
5.InnnoDB数据页结构
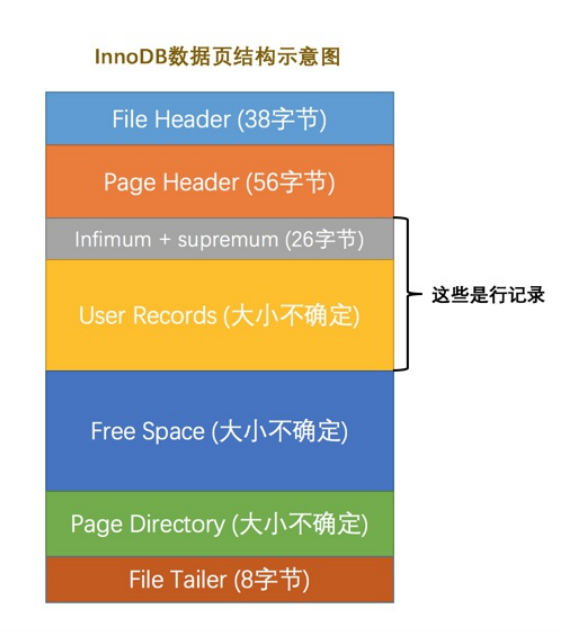

记录在页中的存储
- 也就是在Free space里面申请user Records,上一节的行格式记录就是存储到free space
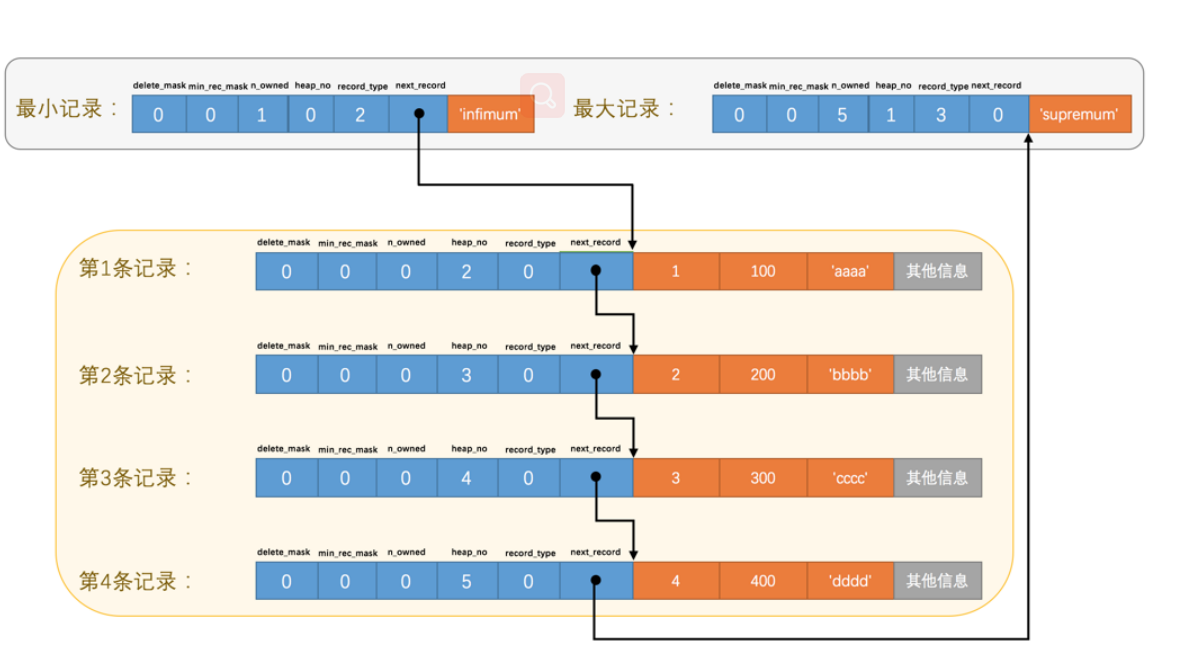
记录头信息的秘密
- 由于创建了主键c1所以在这个地方
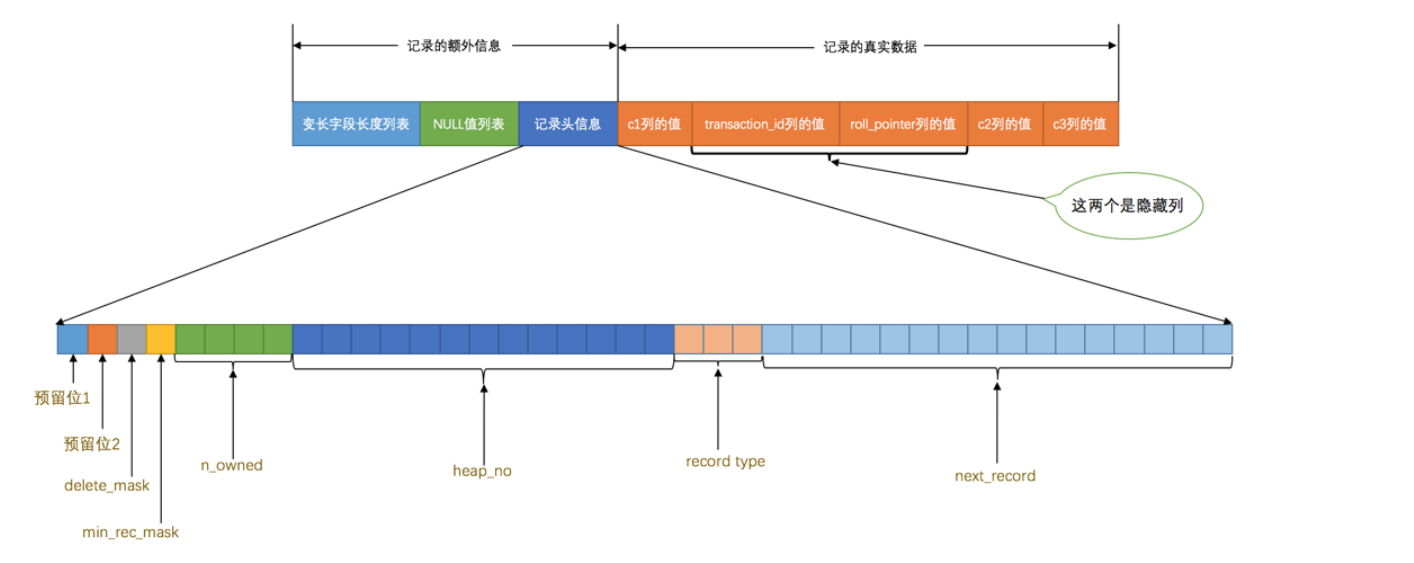
- 记录的简化部分
- delete_mask:是否被删除,也就是逻辑删除位
- min_rec_mask:B+树每层最小的节点会被标记
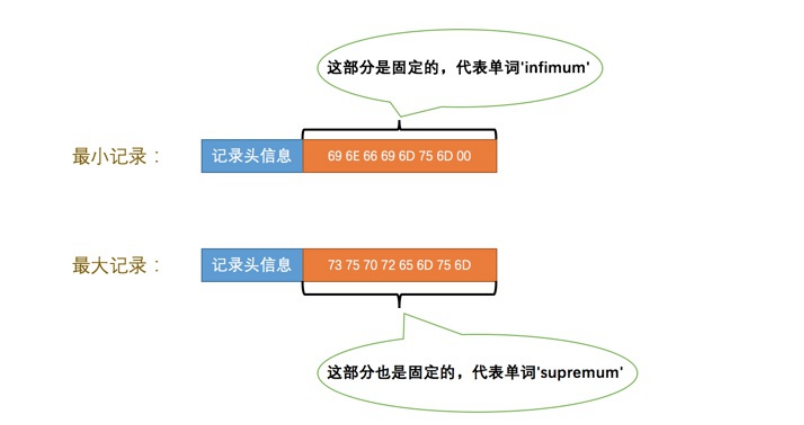
- heap_no:记录在这个页的位置,0和1是虚拟记录,虚拟记录一定是当前最小和最大的记录,因为不是我们自己加上所以两条记录存储在别的位置Infimum+Supremum

- recordtype:0表示普通记录,1表示B+树非叶节点记录,2表示最小记录,3表示最大记录。
- nextrecord:下一条记录的位置

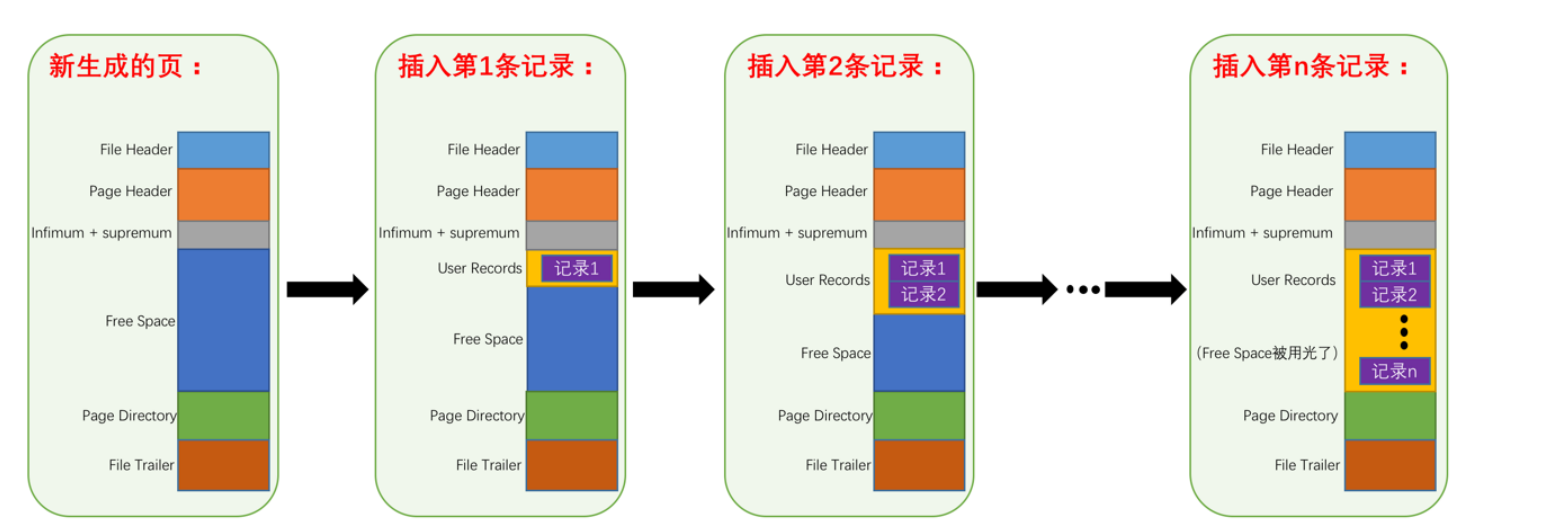
记录的删除和添加
- 我们的记录其实就是一条单链表
- 如果删除一个记录只是把delete_mask标记为1说明是逻辑删除,并没有从存储空间删除
- 删除的next_record变成了0,没有指向
- 并且按照单链表删除方式来进行删除
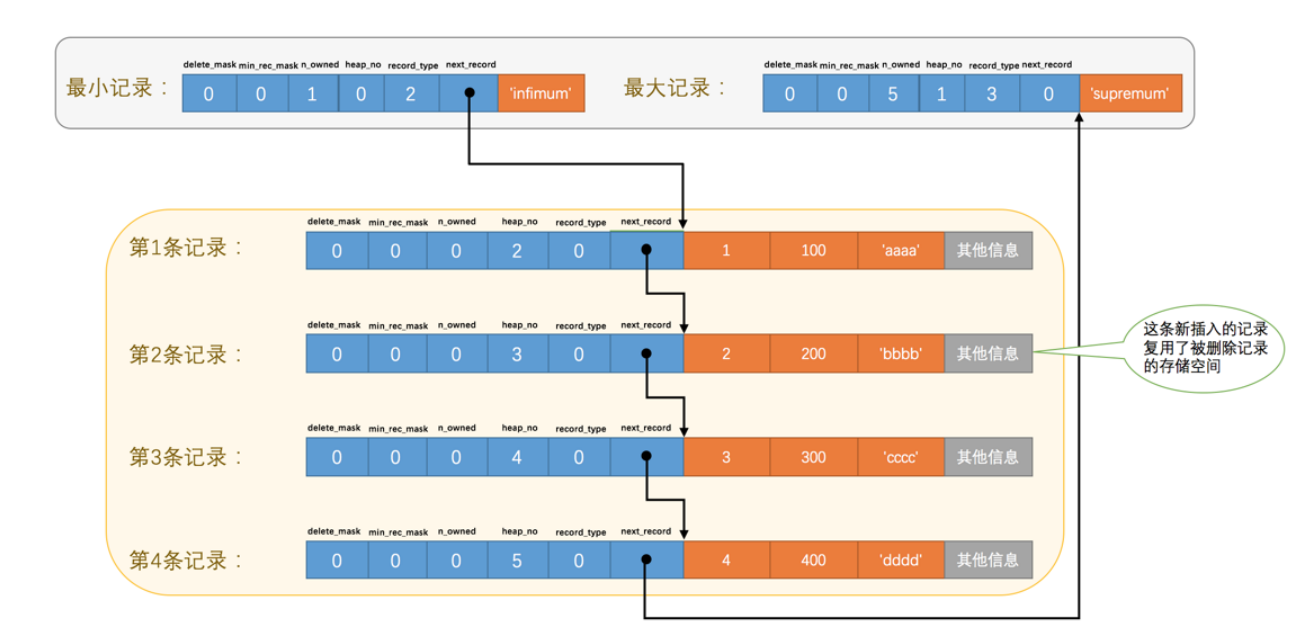
- 如果重新插入就会复用之前的位置
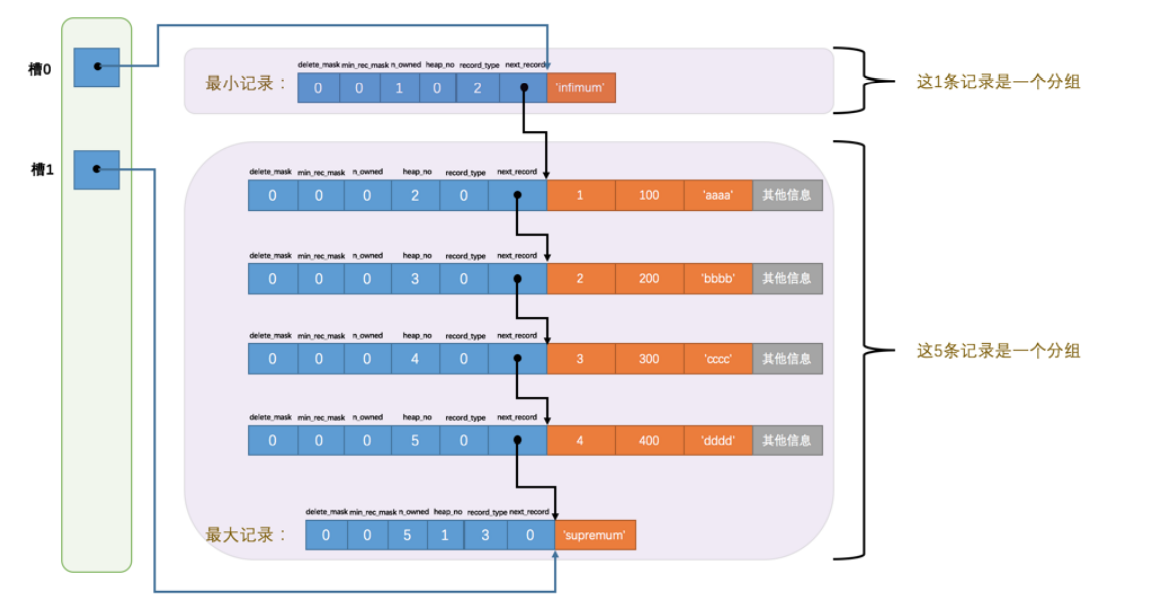
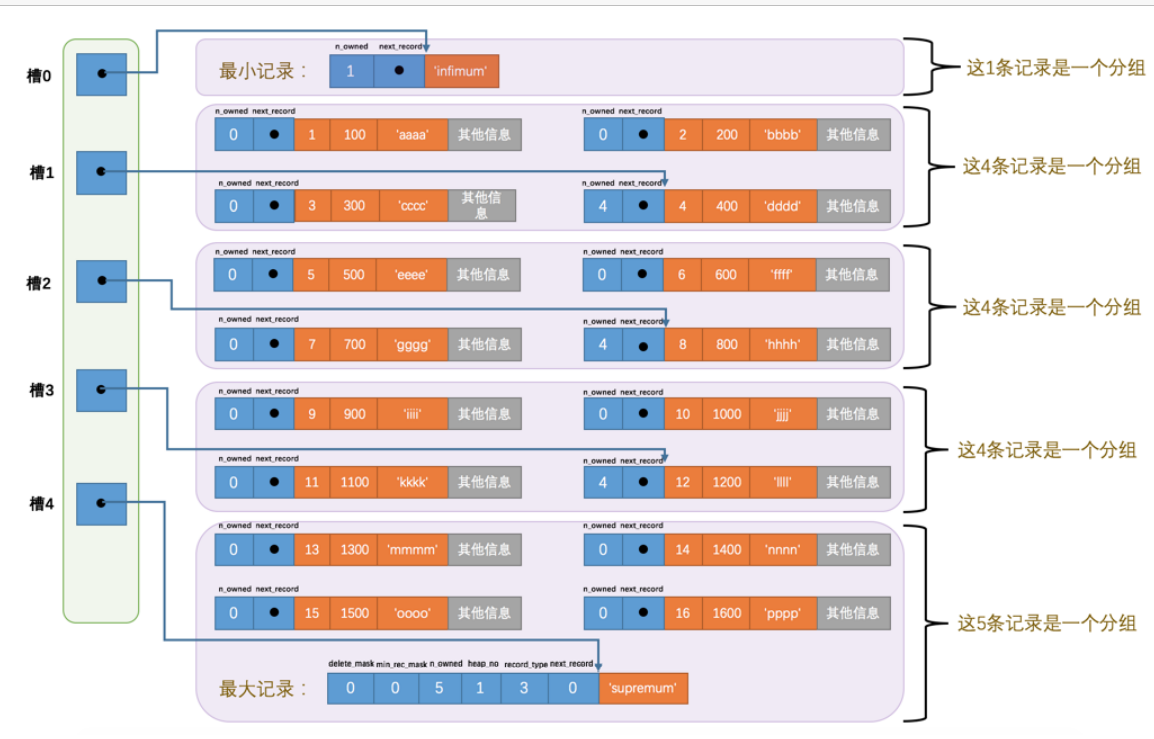
Page Directory(页目录)
- 查询的第一种方法就是直接遍历链表
- 第二种就是使用目录了
- 记录分成多个组
- 每组最后一条记录的n_owned记录当前组有多少记录
- 最后就是每组最后一个记录的偏移取出来放到槽中,这个所有的槽就是页目录,下面现在只是分成了两组,第一组是最小记录,最后一组就是我们插入的4条记录+最大记录
- 最小记录的n_owned是1,最大记录的是5
- 对于最小记录的分组只能是一条,最大记录的分组是1-8条,其它分组就是4-8条
- 每次插入记录都会找主键比当前记录大,而且差值小的位置,并且槽记录大小+1

- 现在又增加12个记录,如果现在要找主键是6的位置那么先是从槽的位置开始寻找,而且使用的是二分法,最后找到的位置是槽2的位置。那么问题来了如何找最小的那个节点?肯定就是从上一个槽1的最后一个节点的下一个节点就是槽2最小的节点,然后开始遍历找6.
总结来说就是
- 二分在页目录找槽
- 然后就是遍历槽
Page Header(页面头部)
- 主要是记录页目录有多少个槽、第一条记录的地址、记录的状态
- page_direction:如果插入记录比上一条记录的主键大,那么就是右边反之左边
- page_n_direction:连续几条插入的方向都是一样的,比如连续在链表后面插入

File Header(文件头部)
- 描述的是各种页的通用数据
- Page Header是数据页的头


重要部分
- fil_page_space_or_chesum:校验和,比较两个字符串的长度,减少时间的损耗
- fil_page_offset:每个页的页号
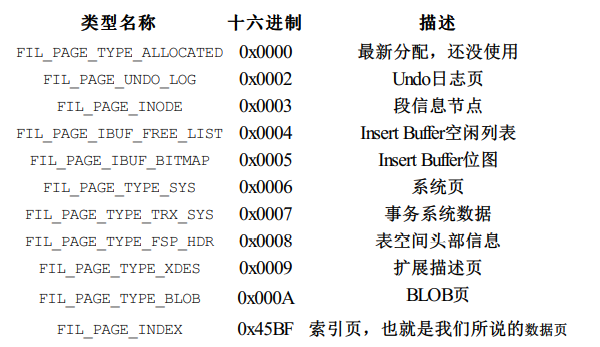
- fil_page_type:页的类型
- fil_page_prev和fil_page_next其实就是因为数据页是不连续的,但是可以通过双链表结构把他们串联起来
File Tailer
- 前四个字节是校验和
与File Header相对应的校验和,当把修改的数据页同步到内存全部写完的时候就会把校验和写到File Tailer上面,如果发现head和tail不同说明同步到一半的时候被终止同步失败了
- 后四个字节代表最后修改的日志序列位置(LCS)
总结
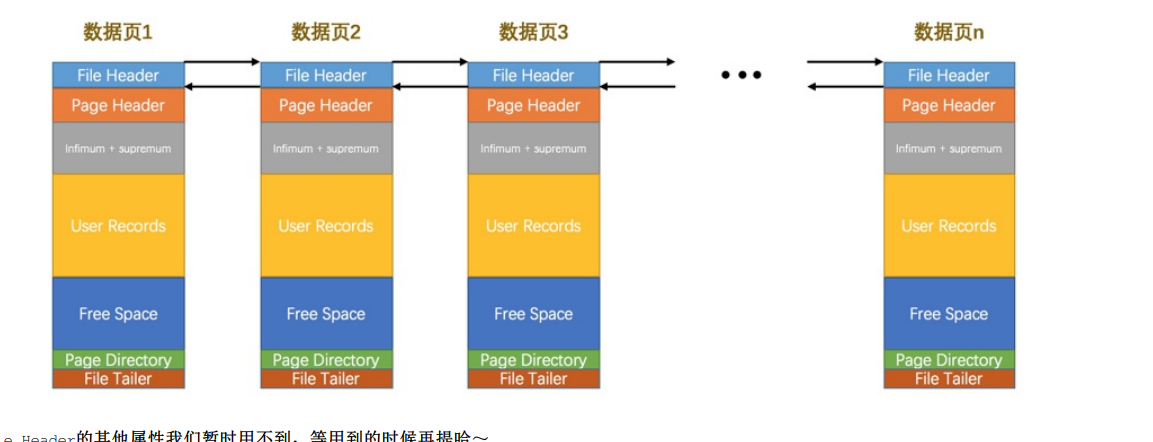
- 数据页是innodb的存储单位
- 数据页的7大部分
- File Header页通用信息
- Page Header数据页特有的信息
- Infimum+Supremum:两个伪记录
- User Records:插入记录
- Free Space:页面没有使用的部分
- Page Directory:页中记录的相对位置
- File Tailer:校验页是不是完整
- 每个记录都有next_record让记录之间形成了单链表
- Innodb会把数据拆分成多个组,每个组最后一个记录偏移就是页目录的一个槽
- 二分+遍历槽
- File Header部分都有上一页和下一页
- 为了保证同步成功需要通过头部校验和和tail校验和进行比较。

















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









