



基础概念
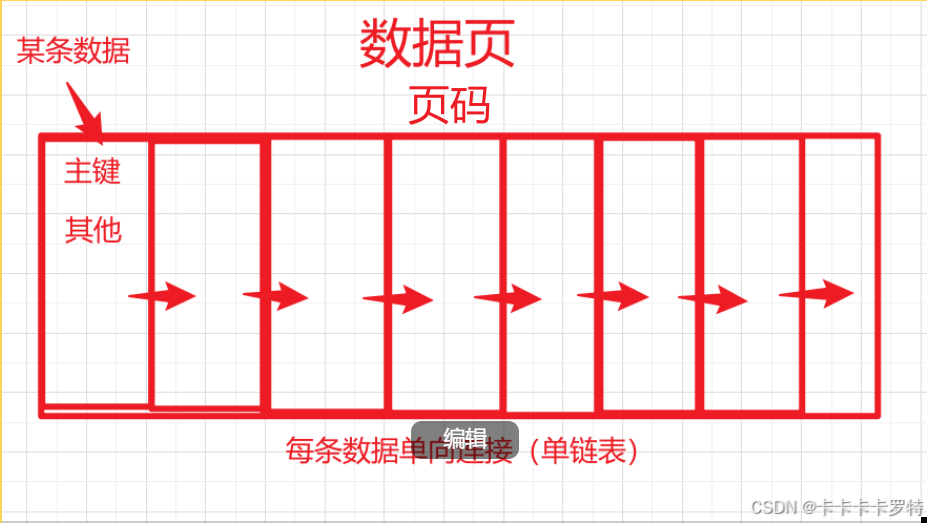
数据页
由页码和多条数据单向链接组成的单向链表构成(简单介绍)
页目录(也是数据页)
由数据页中最小的主键和对应的页码组成(不包含数据),还有自身的页码数
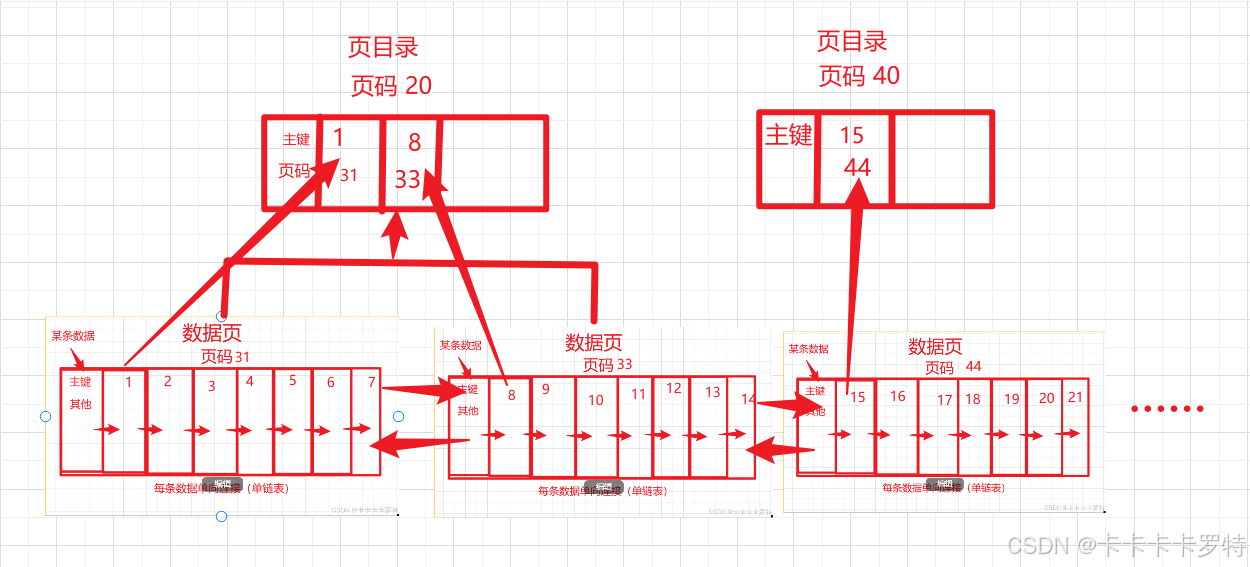
根节点(也是数据页)
由页目录中的最小主键值和对应的页码和自身的页码所组成
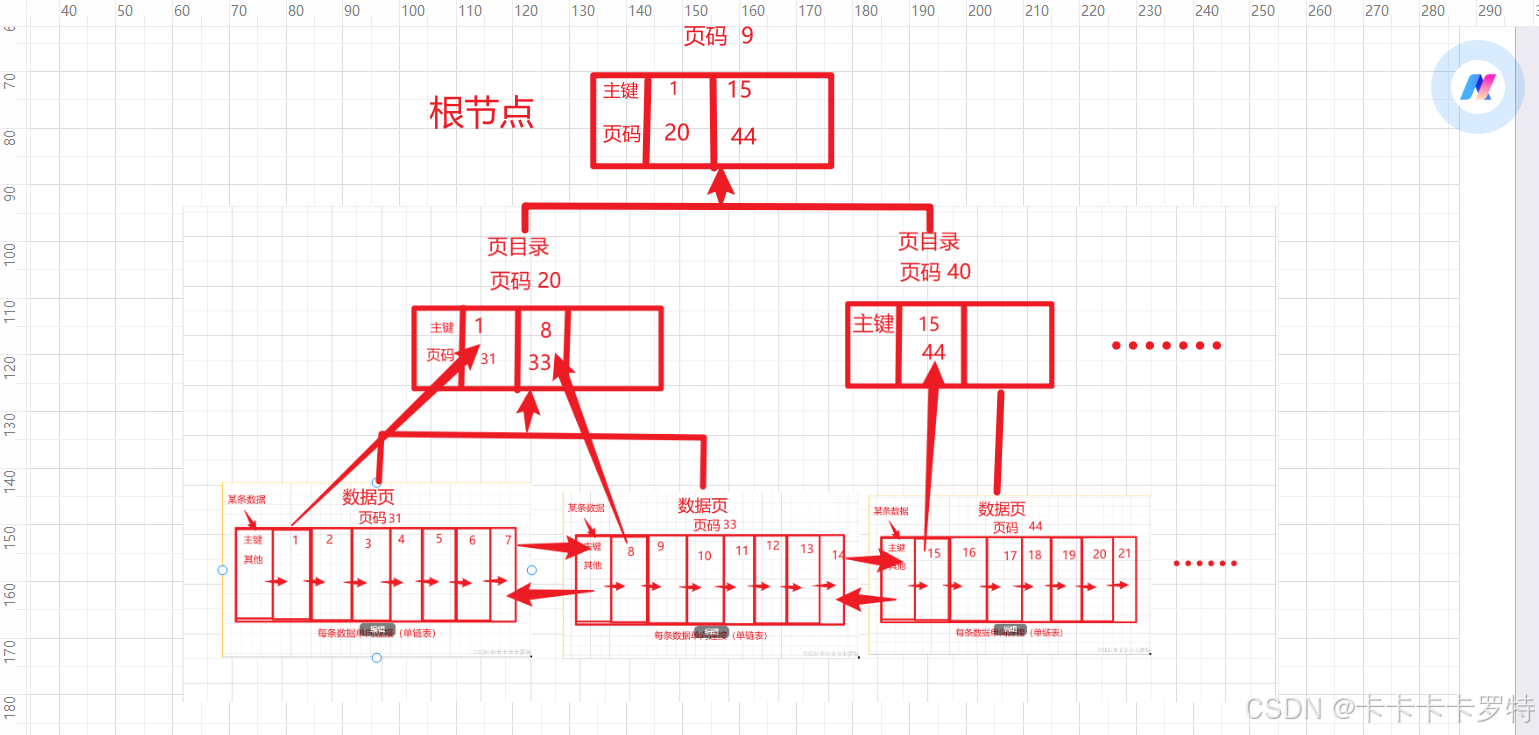
这里只由叶子节点存储数据。
查找举例
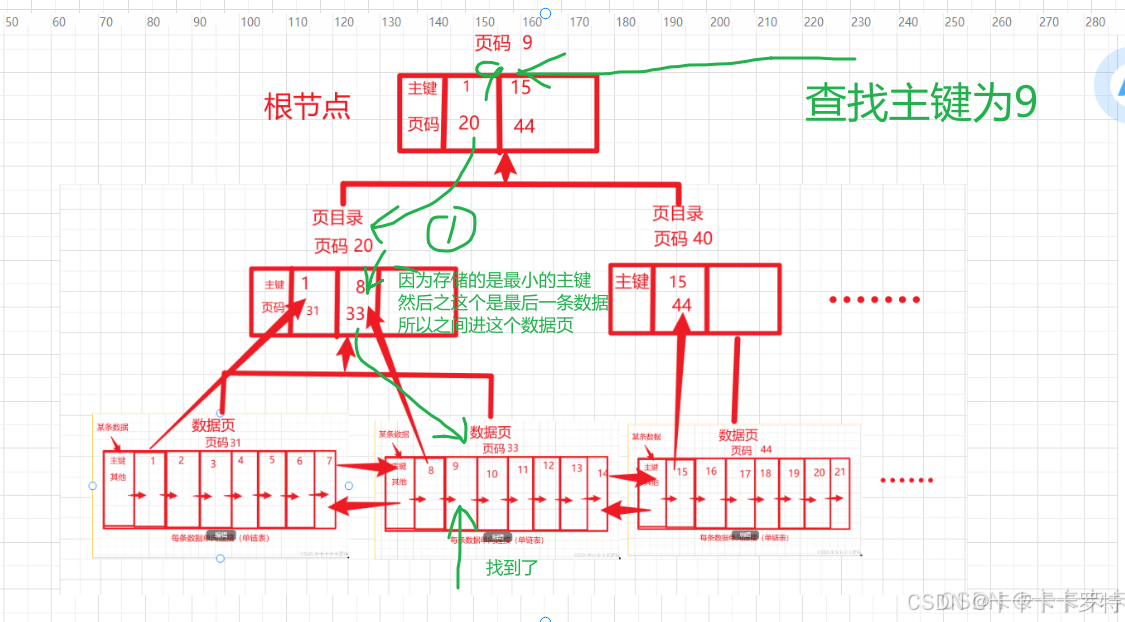
查找主要是利用二分查找法
当查找主键为9的数据的时候
首先进入根节点页码9,因为9比1大,比15小,所以进入找到第一条数据,对应的页码是20.
因此寻找到页码为20的目录,9比1大,也比8大,但是页码已经确定了,然后存储的是最小的主键,因此确定是最后一条数据,取出页码33.
然后找到数据页的页码为33,然后简单的二分即可找到主键为9的数据
查找图解:
主键索引
主键索引(聚簇索引)——以主键作为排序的标准建立b+树。(参考上图建立的b+树)
如果有主键,默认会使用主键作为聚簇索引的索引键;
如果没有主键,就选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键;
在上面两个都没有的情况下,InnoDB 将自动生成一个隐式自增 id 列作为聚簇索引的索引键
普通索引(二级索引)和联合索引
普通索引
普通索引的叶子节点存放的是主键值,而不是实际数据
设想一下,如果涵盖数据,那不就是又多了一张完整的表,这对空间的消耗非常大。
这里以name作为举例,我们设置了name为索引,
首先会对name进行排序,叶子节点包含了name和对应的id作为一条数据,然后多个这样的数据组成数据页作为叶子节点。然后和主键索引一样,选出排序值最小的那条数据和这条数据对应的页码作为页目录的一条数据,然后取出页目录排序值最小的数据和该数据所在的目录页的页码作为数据放在根节点中。
可以理解成把上图(主键索引)的主键那一行全部换成你所设置的索引的字段,这里是name
联合索引
举个例子,这里同时为name和phone创建了索引,注意顺序,先是name再是phone。
同样也是创建一颗b+树,不过排序的字段变成了俩个
排序规则是:首先对name排序,name相同的时候对phone排序。
为什么索引可以增加查询速率
首先对数据页的概念进行进一步说明:
数据页是数据库管理的基本单位,用于存储和管理数据。在InnoDB存储引擎中,数据页的大小通常为16KB,每个数据页包含多个数据记录
而项目中存储的数据非常多,一个数据页是搞不定的。需要有多个数据页共同存储。
而查找的过程中假如顺序遍历的,找不到对应的数据页,导致进行多次io读取不同的磁盘块。查询时间大大增加。
而数据库引擎可以根据索引的位置信息快速定位到符合查询条件的数据所在的磁盘块,从而减少磁盘I/O操作的次数,提高查询速度。
我们可以对照b+树的查找过程,通过二分查找快速找到对应的数据页的页码。快速定位数据。大大加快了查询速度。
注意事项
虽然索引可以显著提高查询速度,但它也有一些缺点。创建和维护索引需要时间,并且占用额外的物理空间。此外,对数据的增删改操作也会因为需要更新索引而变慢。因此,在选择建立索引时需要权衡其优缺点,确保索引的使用能够带来实际的性能提升。



















 9616
9616


 到【灌水乐园】发言
到【灌水乐园】发言










