






命名规范
类名:类名的首字母应该大写。
方法名:首字母应该小写。
标识符:
- 所有的标识符都应该以字母、美元符($)、下划线(_)开头。
- 首字符之后可以是字母,美元符,下划线和数字。
修饰符:
-
访问控制修饰符:default、public、protected、private
-
非访问控制修饰符:final、abstract、static、synchronized
数据类型
内置数据类型
有8种基本数据类型。其中六种数字类型(四个整数型,两个浮点型),一种字符型,还有一种布尔型。
byte # 8位 以二进制补码表示的整数
short # 16 位以二进制补码表示的整数
int # 32 位以二进制补码表示的整数
long # 64 位以二进制补码表示的整数
float # 32 位浮点数
double # 64 位浮点数
boolean # 布尔型
char # 字符型
引用数据类型
所有的引用类型默认值都是 null
对象和数组都是引用类型
类型转换
从低到高:
byte,short,char -> int -> long -> float -> double
数据类型转换规则:
- 不能对 Boolean 类型进行类型转换
- 不能把对象类型转换为不相关的对象
- 把容量大的类型转换为容量小的类型需要强转
- 转换过程中可能导致溢出或损失精度
- 浮点数到整数的转换是通过舍弃小数而不是四舍五入
修饰符
在 Java 中,可以使用访问控制符来保护对类、变量、方法和构造方法的访问。
- default 默认使用的就是 default。在同一包可见。使用对象:类、接口、变量、方法。
- private 在同一类内可见。 使用对象: 变量、方法
- public 对所有类可见。 使用对象:类、接口、变量、方法
- protected 对同一包内的所有类和子类可见。 使用对象:变量、方法
访问控制和继承
- 父类声明为 public 的方法在子类中也必须声明为 public
- 父类中声明为 protected 的方法在子类中要么声明为 protected,要么声明为 public,不能声明为private
- 父类中声明为 private 的方法,不能够被子类继承
非访问修饰符
static 修饰符,用来修饰类方法和类变量
静态变量
static 关键字用来声明独立于对象的静态变量,无论一个类实例化多少对象,它的静态变量只有一份拷贝。静态变量也被称为类变量。局部变量不能被声明为 static 变量
静态方法
static 关键字用来声明独立于对象的静态方法。静态方法不能使用类的非静态变量。静态方法从参数列表获得数据,然后计算这些数据
final 修饰符,用来修饰类、方法和变量,final 修饰的类不能被继承,修饰的方法不能被继承类重新定义,修饰的变量为常量,是不可修改的。
final 变量
final 变量一旦赋值后,不能被被重新赋值。被 final 修饰的实例变量必须显示指定初始值
final 修饰符通常和 static 修饰符一起使用来创建类常量
final 方法
父类中的 final 方法可以被子类继承,但是不能被子类重写
声明 final 方法的主要目的是防止该方法的内容被修改
final 类
final 类不能被继承,没有类能够继承 final 类的任何特性
abstract 修饰符,用来创建抽象类和抽象方法。
抽象类:
抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充。
一个类不能同时被 abstract 和 final 修饰。如果一个类包含抽象方法,那么该类一定要声明为抽象类,否则将出现编译错误。
抽象类可以包含抽象方法和非抽象方法
抽象方法:
抽象方法是一种没有任何实现的方法,该方法的具体实现由子类提供
抽象方法不能被声明成 final 和 static
任何继承抽象类的子类必须实现父类所有的抽象方法,除非该子类也是抽象类
如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法。
抽象方法的声明以分号结尾
synchronize 和 volatile 修饰符,主要用于线程的编程
synchronized 关键字声明的方法同一时间只能被一个线程访问。synchronized 修饰符可以应用于四个访问修饰符。
transient 修饰符
序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
该修饰符包含在定义变量的语句中,用来预处理类和变量的数据类型。
volatile 修饰符
volatile 修饰的成员变量在每次被线程访问时,都强制从共享内存中重新读取该成员变量的值。而且,当成员变量发生变化时,会强制线程将变化值回写到共享内存。这样在任何时刻,两个不同的线程总是看到某个成员变量的同一个值。
字符串操作
str 为以一个具体要对其进行操作的字符串
str.subString( int beginIndex) 从 beginIndex 开始 截取直到该字符串结束的字串。
str.trim() 去掉字符串首尾的空格
str.replace(char oldChar, char newChar) 字符串替换 返回一个新的字符串,如果oldChar在str中没有则返回原字符串
判断字符串的开始和结尾: return:Boolean
str.startsWith(String prefix) // prefix 前缀
str.endsWith(String suffix) // suffix 后缀
判断两个字符串是否相等 return:Boolean
str.equals(String otherstr)
字母大小写转换:
str.toLowerCase() 将String转换为小写
str.toUpperCase() 将String转换为大写
字符串分割:
str.split(String sign) sign为分割字符串的分割符
数组
Arrays 类
给数组赋值:通过 fill 方法
填充替换数组元素
Arrays.fill(int[] a, int value)
a:要进行元素替换的数组
value: 要存储数组中的所有元素的值
注:将 a 数组中的每个元素的值替换为 value
Arrays.fill(int[] a, int fromIndex, int toIndex, int value)
将指定的值 value 分配给 a 数组中的指定范围
注:填充的范围从下标 fromIndex (包括)一直到下标 toIndex(不包括)
复制数组
Arrays.copyOf(arr, int newLength)
arr: 要进行复制的数组
newLength: 复制后新数组的长度。如果新数组的长度大于数组 arr 的长度,则用0填充(根据复制数组的类型判断,整型用0, char 型用 null)
copyOfRange(arr, int formIndex, int toIndex)
arr: 要进行复制的数组
填充的范围从下标 fromIndex (包括)一直到下标 toIndex(不包括)
二分查找 return 搜索值的索引
Array.binarySearch(arr,key) arr为要搜索的数组 key为要搜索的值
Array.binarySearch(arr, int fromIndex, int toIndex, key) 指定范围搜索
日期时间
使用 SimpleDateFormat 格式化时间
Date date = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(simpleDateFormat.format(date));
注:HH 是24小时制,hh 是12小时制。
日期和时间的格式化编码
| 字母 | 描述 | 示例 |
|---|---|---|
| G | 纪元标记 | AD |
| y | 四位年份 | 2001 |
| M | 月份 | July or 07 |
| d | 一个月的日期 | 10 |
| h | A.M./P.M. (1~12)格式小时 | 12 |
| H | 一天中的小时 (0~23) | 22 |
| m | 分钟数 | 30 |
| s | 秒数 | 55 |
| S | 毫秒数 | 234 |
| E | 星期几 | Tuesday |
| D | 一年中的日子 | 360 |
| F | 一个月中第几周的周几 | 2 (second Wed. in July) |
| w | 一年中第几周 | 40 |
| W | 一个月中第几周 | 1 |
| a | A.M./P.M. 标记 | PM |
| k | 一天中的小时(1~24) | 24 |
| K | A.M./P.M. (0~11)格式小时 | 10 |
| z | 时区 | Eastern Standard Time |
| ’ | 文字定界符 | Delimiter |
| " | 单引号 | ` |
# 获取当前时间戳
System.currentTimeMillis( )
Calendar类
Calendar类是一个抽象类,在实际使用时实现特定的子类的对象,创建对象的过程对程序员来说是透明的,只需要使用getInstance方法创建即可。
创建一个代表系统当前日期的Calendar对象
Calendar c = Calendar.getInstance();//默认是当前日期
创建一个指定日期的Calendar对象
//创建一个代表2009年6月12日的Calendar对象
Calendar c1 = Calendar.getInstance();
c1.set(2009, 6 - 1, 12);
Add设置
Calendar c1 = Calendar.getInstance();
把c1对象的日期加上10,也就是c1也就表示为10天后的日期,其它所有的数值会被重新计算
c1.add(Calendar.DATE, 10);
把c1对象的日期减去10,也就是c1也就表示为10天前的日期,其它所有的数值会被重新计算
c1.add(Calendar.DATE, -10);
Calendar类对象字段类型
| 常量 | 描述 |
|---|---|
| Calendar.YEAR | 年份 |
| Calendar.MONTH | 月份 |
| Calendar.DATE | 日期 |
| Calendar.DAY_OF_MONTH | 日期,和上面的字段意义完全相同 |
| Calendar.HOUR | 12小时制的小时 |
| Calendar.HOUR_OF_DAY | 24小时制的小时 |
| Calendar.MINUTE | 分钟 |
| Calendar.SECOND | 秒 |
| Calendar.DAY_OF_WEEK | 星期几 |
Calendar类对象信息的获得
Calendar c1 = Calendar.getInstance();
// 获得年份
int year = c1.get(Calendar.YEAR);
// 获得月份
int month = c1.get(Calendar.MONTH) + 1;
// 获得日期
int date = c1.get(Calendar.DATE);
// 获得小时
int hour = c1.get(Calendar.HOUR_OF_DAY);
// 获得分钟
int minute = c1.get(Calendar.MINUTE);
// 获得秒
int second = c1.get(Calendar.SECOND);
// 获得星期几(注意(这个与Date类是不同的):1代表星期日、2代表星期1、3代表星期二,以此类推)
int day = c1.get(Calendar.DAY_OF_WEEK);
Java 正则表达式
正则表达式语法
| 字符 | 说明 |
|---|---|
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如, n匹配字符 n。\n 匹配换行符。序列 \\ 匹配 \ ,\( 匹配 (。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,"do(es)?“匹配"do"或"does"中的"do”。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}“不匹配"Bob"中的"o”,而匹配"foooood"中的所有 o。"o{1,}“等效于"o+”。"o{0,}“等效于"o*”。 |
| {n,m} | m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。‘o{0,1}’ 等效于 ‘o?’。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(*、+、?、{n}、{n,}、{n,m})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?“只匹配单个"o”,而"o+“匹配所有"o”。 |
| . | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| (pattern) | 匹配 pattern 并捕获该匹配的子表达式。可以使用 $0…$9 属性从结果"匹配"集合中检索捕获的匹配。若要匹配括号字符 ( ),请使用"(“或者”)"。 |
| (?:pattern) | 匹配 pattern 但不捕获该匹配的子表达式,即它是一个非捕获匹配,不存储供以后使用的匹配。这对于用"or"字符 (|) 组合模式部件的情况很有用。例如,'industr(?:y|ies) 是比 ‘industry|industries’ 更经济的表达式。 |
| (?=pattern) | 执行正向预测先行搜索的子表达式,该表达式匹配处于匹配 pattern 的字符串的起始点的字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,‘Windows (?=95|98|NT|2000)’ 匹配"Windows 2000"中的"Windows",但不匹配"Windows 3.1"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| (?!pattern) | 执行反向预测先行搜索的子表达式,该表达式匹配不处于匹配 pattern 的字符串的起始点的搜索字符串。它是一个非捕获匹配,即不能捕获供以后使用的匹配。例如,‘Windows (?!95|98|NT|2000)’ 匹配"Windows 3.1"中的 “Windows”,但不匹配"Windows 2000"中的"Windows"。预测先行不占用字符,即发生匹配后,下一匹配的搜索紧随上一匹配之后,而不是在组成预测先行的字符后。 |
| x|y | 匹配 x 或 y。例如,‘z|food’ 匹配"z"或"food"。‘(z|f)ood’ 匹配"zood"或"food"。 |
| [xyz] | 字符集。匹配包含的任一字符。例如,"[abc]“匹配"plain"中的"a”。 |
| [^xyz] | 反向字符集。匹配未包含的任何字符。例如,"[^abc]“匹配"plain"中"p”,“l”,“i”,“n”。 |
| [a-z] | 字符范围。匹配指定范围内的任何字符。例如,"[a-z]"匹配"a"到"z"范围内的任何小写字母。 |
| [^a-z] | 反向范围字符。匹配不在指定的范围内的任何字符。例如,"[^a-z]"匹配任何不在"a"到"z"范围内的任何字符。 |
| \b | 匹配一个字边界,即字与空格间的位置。例如,“er\b"匹配"never"中的"er”,但不匹配"verb"中的"er"。 |
| \B | 非字边界匹配。“er\B"匹配"verb"中的"er”,但不匹配"never"中的"er"。 |
| \cx | 匹配 x 指示的控制字符。例如,\cM 匹配 Control-M 或回车符。x 的值必须在 A-Z 或 a-z 之间。如果不是这样,则假定 c 就是"c"字符本身。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。等效于 [^0-9]。 |
| \f | 换页符匹配。等效于 \x0c 和 \cL。 |
| \n | 换行符匹配。等效于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等效于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等。与 [ \f\n\r\t\v] 等效。 |
| \S | 匹配任何非空白字符。与 [^ \f\n\r\t\v] 等效。 |
| \t | 制表符匹配。与 \x09 和 \cI 等效。 |
| \v | 垂直制表符匹配。与 \x0b 和 \cK 等效。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。与"[^A-Za-z0-9_]"等效。 |
| \xn | 匹配 n,此处的 n 是一个十六进制转义码。十六进制转义码必须正好是两位数长。例如,“\x41"匹配"A”。“\x041"与”\x04"&"1"等效。允许在正则表达式中使用 ASCII 代码。 |
| *num* | 匹配 num,此处的 num 是一个正整数。到捕获匹配的反向引用。例如,"(.)\1"匹配两个连续的相同字符。 |
| *n* | 标识一个八进制转义码或反向引用。如果 *n* 前面至少有 n 个捕获子表达式,那么 n 是反向引用。否则,如果 n 是八进制数 (0-7),那么 n 是八进制转义码。 |
| *nm* | 标识一个八进制转义码或反向引用。如果 *nm* 前面至少有 nm 个捕获子表达式,那么 nm 是反向引用。如果 *nm* 前面至少有 n 个捕获,则 n 是反向引用,后面跟有字符 m。如果两种前面的情况都不存在,则 *nm* 匹配八进制值 nm,其中 n 和 m 是八进制数字 (0-7)。 |
| \nml | 当 n 是八进制数 (0-3),m 和 l 是八进制数 (0-7) 时,匹配八进制转义码 nml。 |
| \un | 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符。例如,\u00A9 匹配版权符号 (©)。 |
方法
方法的定义
修饰符 返回值类型 方法名(参数类型 参数名){
...
方法体
...
return 返回值;
}
-
**修饰符:**修饰符,这是可选的,告诉编译器如何调用该方法。定义了该方法的访问类型。
-
返回值类型 :方法可能会返回值。returnValueType 是方法返回值的数据类型。有些方法执行所需的操作,但没有返回值。在这种情况下,returnValueType 是关键字void。
-
**方法名:**是方法的实际名称。方法名和参数表共同构成方法签名。
-
**参数类型:**参数像是一个占位符。当方法被调用时,传递值给参数。这个值被称为实参或变量。参数列表是指方法的参数类型、顺序和参数的个数。参数是可选的,方法可以不包含任何参数。
-
**方法体:**方法体包含具体的语句,定义该方法的功能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CytmId9L-1642564950126)(D:/study/studyByMine/endBase/image-20220113174656236.png)]
-
可变参数:
方法的可变参数的声明:
typeName... parameterName在方法声明中,在指定参数类型后加一个省略号(…)
一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。任何普通的参数必须在它之前声明
I/O流
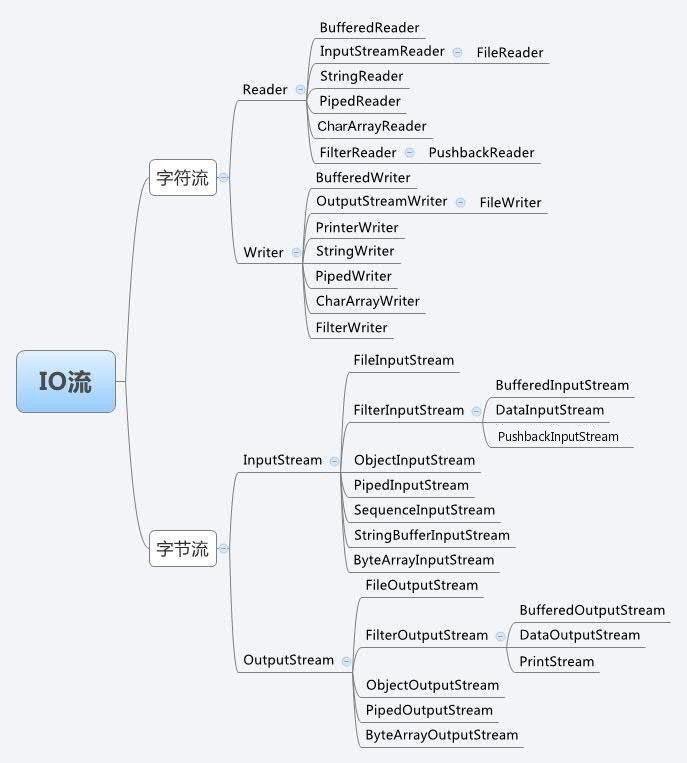
FileInputStream
该流 用于从文件读取数据,它的对象可以用关键字 new 来创建
有多种构造方法可用来创建对象
可以使用字符串类型的文件名来创建一个输入流对象读取文件
InputStream f = new FileInputStream("C:/java/hello");
也可以使用一个文件对象来创建一个输出流来写文件。我们首先得使用File()方法来创建一个文件对象:
File f = new File("C:/java/hello");
InputStream in = new FileInputStream(f);
FileOutputStream
该类用来创建一个文件并向文件中写数据。
如果该流在打开文件进行输出前,目标文件不存在,那么该流会创建该文件。
有两个构造方法可以用来创建 FileOutputStream 对象。
使用字符串类型的文件名来创建一个输出流对象:
OutputStream f = new FileOutputStream("C:/java/hello")
也可以使用一个文件对象来创建一个输出流来写文件。我们首先得使用File()方法来创建一个文件对象
File f = new File("C:/java/hello");
OutputStream fOut = new FileOutputStream(f);
向文件写入读取的实例
File file = new File("D:/study/studyByMine/endBase/test.txt");
// 构建 FIleOutputStream 输出流对象
FileOutputStream fileOutputStream = new FileOutputStream(file);
// 构建 OutputStreamWriter 对象,参数可以指定编码,默认为操作系统默认编码,Windows 上是 gbk
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream, "utf-8");
// 写入缓冲区
outputStreamWriter.append("测试向文件中写入的数据");
// 写入换行
outputStreamWriter.append("\n");
// 关闭写入流,同时会把缓冲区的数据写入到文件
outputStreamWriter.close();
// 关闭输出流
fileOutputStream.close();
// 构建 FileInputStream 输入流对象
FileInputStream fileInputStream = new FileInputStream(file);
// 构建 InputStreamReader 对象
InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream, "utf-8");
StringBuffer stringBuffer = new StringBuffer();
while (inputStreamReader.ready()) {
// 转换成 char 加到 StringBuffer 中
stringBuffer.append((char) inputStreamReader.read());
}
System.out.println(stringBuffer.toString());
// 关闭读取流
inputStreamReader.close();
//关闭输入流
fileInputStream.close();
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KzkX6U49-1642564950127)(D:/study/studyByMine/endBase/image-20220114120209810.png)]
面向对象
继承
继承就是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
继承的特性:
- 子类拥有父类非 private 的属性、方法
- 子类可以拥有自己的属性和方法
- 子类可以用自己的方法实现父类的方法(重写)
- Java 的继承是单继承,但是可以多重继承
- 提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)
继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字时,默认继承自object
super 与 this 关键字:
super:可以通过 super 关键字来实现对父类成员的访问,用来引用当前对象的父类
this:指向自己的引用
final 关键字:
final 关键字声明类可以把类定义为不能 继承的,即最终类;或者用于修饰方法,该方法不能被子类重写
实例变量也可以被定义为 final,被定义为 final 的变量不能被修改。被声明为 final 类的方法自动声明为final,但是实例变量并不是 final
构造器:
子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式)。如果父类的构造器有参数,则必须在子类的构造器中显式地通过 super 关键字调动父类的构造器并配以适当的参数列表
如果父类中构造器没有参数,则在子类中不需要 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
重写与重载
重写是子类对父类允许访问的方法的实现过程进行重新编写,返回值和形参都不能改变。
重写的好处是子类可以根据需要,定义特定与自己的行为。也就是说子类能够根据需要实现父类的方法
重写方法不能抛出新的检查异常或者比重写方法申明更加宽泛的异常。
方法重写规则:
- 参数列表与被重写的方法的参数列表必须完全一致
- 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类。
- 访问权限不能比父类中被重写的方法访问权限低
- 父类的成员方法只能被它的子类重写
- 声明为 final 的方法不能被重写
- 声明为 static 的方法不能被重写,但是能够被再次声明
- 子类和父类在同一个包中,那么子类可以重写父类的所有方法,除了声明为 private 和 final 的方法
- 子类和父类不在同一个包中,那么子类只能够重写父类声明 为 public 和 protected 的非 final 方法
- 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
- 构造方法不能被重写
- 如果不能继承一个类,则不能重写该类的方法。
Super 关键字的使用:
当需要子类中调用父类的被重写的方法时,要使用 super 关键字。
重载(Overload):
是在一个类里面,名字相同而参数不同。返回类型也可以相同。每个重载的方法(或者构造函数)都必须有独一无二的参数型列表
最常用的地方就是构造器的重载
重载规则:
- 被重载的方法必须该表列表参数
- 被重载的方法可以改变返回类型
- 被重载的方法可以改变访问修饰符
- 被重载的方法可以声明新的或更广的检查异常
- 方法能够在同一类中或者在一个子类中被重载。
- 无法以返回值类型作为重载函数的区分标准
重写和重载的区别:
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可以修改 | 一定不能修改 |
| 异常 | 可以修改 | 可以减少或删除,一定不能抛出新的或者更广的异常 |
| 访问 | 可以修改 | 一定不能做更严格的限制(可以降低限制) |
总结:
方法的重写和重载是 java 多态性的不同表现,重写是父类与子类之间多态性的表现,重载可以理解为多态的具体表现形式
- 方法重载是一个类中定义了多个方法名相同,参数不同的方法
- 方法重写是在子类存在方法与父类方法的名字相同,而且参数的个数与类型一样,返回值也一样的方法
- 方法重载是一个类的多态性表现,而方法重写是子类与父类的一种多态性表现
Java多态
多态是同一个行为具有多个不同表现形式或形态的能力
多态就是同一个接口,使用不同的实例而执行不同操作
多态性是对象多种表现形式的体现
多态的优点:
- 消除类型之间的耦合关系
- 可替换性
- 可扩充性
- 接口性
- 灵活性
- 简化性
多态存在的三个必要条件:
- 继承
- 重写
- 父类引用指向子类对象
多态的实现方式:
方式一:重写
方式二:接口
方式三:抽象类和抽象方法
Java抽象类
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用。也是因为这个原因,通常在设计阶段决定要不要设计抽象类。父类包含了子类集合的常见的方法,但是由于父类本身是抽象的,所以不能使用这些方法。在 Java 中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口。
抽象类:
在 Java 中使用 abstract class 来定义抽象类。
抽象方法:
如果你想设计这样一个类,该类包含一个特别的成员方法,该方法的具体实现由它的子类确定,那么你可以在父类中声明该方法为抽象方法。Abstract 关键字同样可以用来声明抽象方法,抽象方法只包含一个方法名,而没有方法体。抽象方法没有定义,方法名后面直接跟一个分号,而不是花括号。
注:如果一个类包含抽象方法,那么该类必须是抽象类。任何子类都必须重写父类的抽象方法,或者声明自身为抽象类
任何子类必须重写父类的抽象方法。否则,该子类也必须声明为抽象类,最终,必须有子类实现该抽象方法,否则从最初的父类到最终的子类都不能用来实例化对象
抽象类总结规定:
- 抽象类不能被实例化。只有抽象类的非抽象子类可以创建对象
- 抽象类中不一定包含抽象方法,但是包含抽象方法的类必须是抽象类
- 抽象类的抽象方法只是声明,不包含方法体。
- 构造方法、类方法(用 static 修饰的方法)不能声明为抽象方法
- 抽象类的子类必须给出抽象类中的抽象方法的具体实现,除非该子类也是抽象方法。
接口
接口特性:
- 接口中每一个方法也是隐式抽象的,接口中的方法会被隐式的指定为 public abstract(只能是 public abstract,其他修饰符都会报错)。
- 接口中可以含有变量,但是接口中的变量会被隐式的指定为 public static final 变量(并且只能是 public,用 private 修饰会报编译错误)。
- 接口中的方法是不能在接口中实现的,只能由实现接口的类来实现接口中的方法。
抽象类和接口的区别:
-
抽象类中的方法可以有方法体,就是能实现方法的具体功能,但是接口中的方法不行。
-
抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是 public static final 类型的。
-
接口中不能含有静态代码块以及静态方法(用 static 修饰的方法),而抽象类是可以有静态代码块和静态方法。
-
一个类只能继承一个抽象类,而一个类却可以实现多个接口。
接口的声明:
[可见度] interface 接口名称 [extends 其他的接口名] {
// 声明变量
// 抽象方法
}
Java 数据结构
-
枚举(Enumeration)
枚举(Enumeration)接口虽然它本身不属于数据结构,但它在其他数据结构的范畴里应用很广。 枚举(The Enumeration)接口定义了一种从数据结构中取回连续元素的方式。例如,枚举定义了一个叫nextElement 的方法,该方法用来得到一个包含多元素的数据结构的下一个元素。
-
位集合(BitSet)
位集合类实现了一组可以单独设置和清除的位或标志。
该类在处理一组布尔值的时候非常有用,你只需要给每个值赋值一"位",然后对位进行适当的设置或清除,就可以对布尔值进行操作了
-
向量(Vector)
向量(Vector)类和传统数组非常相似,但是Vector的大小能根据需要动态的变化。
和数组一样,Vector对象的元素也能通过索引访问。
使用Vector类最主要的好处就是在创建对象的时候不必给对象指定大小,它的大小会根据需要动态的变化。
-
栈(Stack)
栈的创建:
push:入栈
pop:出栈
peek:查看栈顶元素
Stack<String> strings = new Stack<>(); tack<String> strings = new Stack<>(); strings.push("第一个数据"); # 入栈 strings.push("第二个数据"); System.out.println(strings.peek()); # 查看栈顶元素 strings.pop(); # 出栈 System.out.println(strings.peek()); -
字典(Dictionary)
字典(Dictionary) 类是一个抽象类,它定义了键映射到值的数据结构。
当你想要通过特定的键而不是整数索引来访问数据的时候,这时候应该使用Dictionary。
由于Dictionary类是抽象类,所以它只提供了键映射到值的数据结构,而没有提供特定的实现。
-
哈希表(Hashtable)
-
属性(Properties)
Java 集合框架
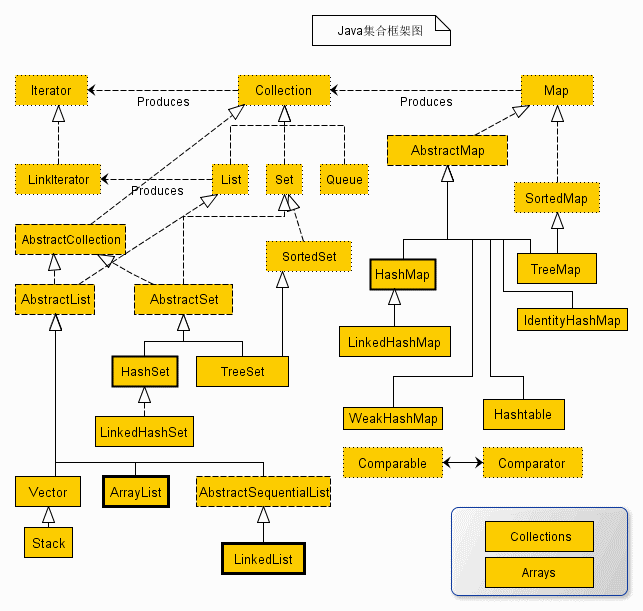
List 和 Set 的区别:
- List 接口实例存储的是有序的,可以重复的数据
- Set 接口实例存储的是无需的,不可以重复的数据
- List 和数组类似,可以动态增长,根据实际存储的数据的长度自动增长 List 的长度。查找效率高,插入删除效率低,因为会引起其他位置改变。(实现类有 ArrayList,LinkedList,Vector)
LinkedList:查找效率低,但是插入删除效率高
该类实现了List接口,允许有null(空)元素。主要用于创建链表数据结构,该类没有同步方法,如果多个线程同时访问一个List,则必须自己实现访问同步,解决方法就是在创建List时候构造一个同步的List。例如:
List list=Collections.synchronizedList(newLinkedList(...));
ArrayList :查找效率高,但是插入删除效率低
该类也是实现了List的接口,实现了可变大小的数组,随机访问和遍历元素时,提供更好的性能。该类也是非同步的,在多线程的情况下不要使用。ArrayList 增长当前长度的50%,插入删除效率低。
HashSet:
该类实现了Set接口,不允许出现重复元素,不保证集合中元素的顺序,允许包含值为null的元素,但最多只能一个。
如何使用迭代器
通常情况下,你会希望遍历一个集合中的元素。例如,显示集合中的每个元素。
一般遍历数组都是采用for循环或者增强for,这两个方法也可以用在集合框架,但是还有一种方法是采用迭代器遍历集合框架,它是一个对象,实现了Iterator 接口或 ListIterator接口。
迭代器,使你能够通过循环来得到或删除集合的元素。ListIterator 继承了 Iterator,以允许双向遍历列表和修改元素。
遍历 ArrayList
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("ArrayList");
list.add("hello,ArrayList");
System.out.println("foreach=====> 第一种遍历方式");
for (String str : list) {
System.out.println(str);
}
System.out.println("===========> 第二种方式,先将 list 转换为 array,再用for循环遍历");
String[] strArray = new String[list.size()];
list.toArray(strArray);
for (int i = 0; i < strArray.length; i++) {
System.out.println(strArray[i]);
}
System.out.println("Iterator=======> 第三种方式,Iterator迭代器遍历");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
注:三种方法都是用来遍历ArrayList集合,第三种方法是采用迭代器的方法,该方法可以不用担心在遍历的过程中会超出集合的长度。
遍历 Map
map.keySet() # map.keySet 可以获取到所有的 key
map.get(key) # 获取 map 中对应的 key 的值
map.entrySet() # 获取 map 的 set 视图
#set 视图意思是 HashMap 中所有的键值对都被看做一个 set 集合 例:[1=value1, 2=value2, 3=value3] )
map.values() # 获得所有的 value 值
HashMap<String, Object> map = new HashMap<>();
map.put("1", "value1");
map.put("2", "value2");
map.put("3", "value3");
System.out.println("========> 遍历方法一:先通过map.keySet()获取到所有的 key 值,再用 foreach 二次取值");
for (String key : map.keySet()) {
System.out.println("key = " + key + "; value = " + map.get(key));
}
System.out.println("=======> 遍历方法二:通过 Map.entrySet使用 iterator 遍历 key 和 value");
Iterator<Map.Entry<String, Object>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<String, Object> entry = iterator.next();
System.out.println("key = " + entry.getKey() + "; value = " + entry.getValue());
}
System.out.println("=======> 遍历方法三:通过 Map.entrySet 遍历 key 和 value");
for (Map.Entry<String, Object> entry : map.entrySet()) {
System.out.println("key = " + entry.getKey() + "; value = " + entry.getValue());
}
System.out.println("======> 遍历方法四:通过Map.values()遍历所有的value,但不能遍历key");
for (Object value : map.values()) {
System.out.println("value = " + value);
}
ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。ArrayList 继承了 AbstractList ,并实现了 List 接口。
ArrayList 初始化:
ArrayList<E> objectName =new ArrayList<>(); // 初始化
# E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
# objectName: 对象名。
ArrayList 是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
添加元素:
ArrayList 类提供了很多有用的方法,添加元素到 ArrayList 可以使用 add() 方法
访问元素:
访问 ArrayList 中的元素可以使用 get() 方法
修改元素:
如果要修改 ArrayList 中的元素可以使用 set() 方法:
删除元素:
如果要删除 ArrayList 中的元素可以使用 remove() 方法
计算大小:
如果要计算 ArrayList 中的元素数量可以使用 size() 方法
迭代数据列表:
可以使用 for ,foreach 来迭代数组中列表中的元素
ArrayList 排序:
sort() 方法进行排序
Java ArrayList 常用方法列表:
| 方法 | 描述 |
|---|---|
| add() | 将元素插入到指定位置的 arraylist 中 |
| addAll() | 添加集合中的所有元素到 arraylist 中 |
| clear() | 删除 arraylist 中的所有元素 |
| clone() | 复制一份 arraylist |
| contains() | 判断元素是否在 arraylist |
| get() | 通过索引值获取 arraylist 中的元素 |
| indexOf() | 返回 arraylist 中元素的索引值 |
| removeAll() | 删除存在于指定集合中的 arraylist 里的所有元素 |
| remove() | 删除 arraylist 里的单个元素 |
| size() | 返回 arraylist 里元素数量 |
| isEmpty() | 判断 arraylist 是否为空 |
| subList() | 截取部分 arraylist 的元素 |
| set() | 替换 arraylist 中指定索引的元素 |
| sort() | 对 arraylist 元素进行排序 |
| toArray() | 将 arraylist 转换为数组 |
| toString() | 将 arraylist 转换为字符串 |
| ensureCapacity() | 设置指定容量大小的 arraylist |
| lastIndexOf() | 返回指定元素在 arraylist 中最后一次出现的位置 |
| retainAll() | 保留 arraylist 中在指定集合中也存在的那些元素 |
| containsAll() | 查看 arraylist 是否包含指定集合中的所有元素 |
| trimToSize() | 将 arraylist 中的容量调整为数组中的元素个数 |
| removeRange() | 删除 arraylist 中指定索引之间存在的元素 |
| replaceAll() | 将给定的操作内容替换掉数组中每一个元素 |
| removeIf() | 删除所有满足特定条件的 arraylist 元素 |
| forEach() | 遍历 arraylist 中每一个元素并执行特定操作 |
// 初始化数组
ArrayList<String> list1 = new ArrayList<>();
ArrayList<String> list2 = new ArrayList<>();
ArrayList<String> list3 = new ArrayList<>();
// 使用 add 添加元素
list1.add("value1");
list1.add("value2");
list2.add("value3");
list2.add("value4");
list3.add("value5");
list3.add("value6");
// 使用 addAll 向数组中添加一个数组
list1.addAll(list2);
// 使用 addAll 向数组中指定索引位置后添加数组
list1.addAll(1, list3);
// 使用 clone 复制一份数组
List<String> list4 = (List<String>) list3.clone();
// 使用 clear 删除 list3 中的所有元素
list3.clear();
// 使用 indexOf 查找索引值
System.out.println(list1.indexOf("value1"));
System.out.println(list1.indexOf("value3"));
// 使用 foreach 遍历数组
System.out.println("=====> list1 中的元素");
for (String value : list1) {
System.out.println(value);
}
System.out.println("=====> list3 中的元素");
for (String value : list3) {
System.out.println(value);
}
System.out.println("=====> list4 中的元素");
for (String value : list4) {
System.out.println(value);
}
LinkedList
LinkedList 的创建:
LinkedList<E> list = new LinkedList<E>(); // 普通创建方法
LinkedList<E> list = new LinkedList(Collection<? extends E> c); // 使用集合创建链表
常用方法:
| 方法 | 描述 |
|---|---|
| public boolean add(E e) | 链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public void add(int index, E element) | 向指定位置插入元素。 |
| public boolean addAll(Collection c) | 将一个集合的所有元素添加到链表后面,返回是否成功,成功为 true,失败为 false。 |
| public boolean addAll(int index, Collection c) | 将一个集合的所有元素添加到链表的指定位置后面,返回是否成功,成功为 true,失败为 false。 |
| public void addFirst(E e) | 元素添加到头部。 |
| public void addLast(E e) | 元素添加到尾部。 |
| public boolean offer(E e) | 向链表末尾添加元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerFirst(E e) | 头部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public boolean offerLast(E e) | 尾部插入元素,返回是否成功,成功为 true,失败为 false。 |
| public void clear() | 清空链表。 |
| public E removeFirst() | 删除并返回第一个元素。 |
| public E removeLast() | 删除并返回最后一个元素。 |
| public boolean remove(Object o) | 删除某一元素,返回是否成功,成功为 true,失败为 false。 |
| public E remove(int index) | 删除指定位置的元素。 |
| public E poll() | 删除并返回第一个元素。 |
| public E remove() | 删除并返回第一个元素。 |
| public boolean contains(Object o) | 判断是否含有某一元素。 |
| public E get(int index) | 返回指定位置的元素。 |
| public E getFirst() | 返回第一个元素。 |
| public E getLast() | 返回最后一个元素。 |
| public int indexOf(Object o) | 查找指定元素从前往后第一次出现的索引。 |
| public int lastIndexOf(Object o) | 查找指定元素最后一次出现的索引。 |
| public E peek() | 返回第一个元素。 |
| public E element() | 返回第一个元素。 |
| public E peekFirst() | 返回头部元素。 |
| public E peekLast() | 返回尾部元素。 |
| public E set(int index, E element) | 设置指定位置的元素。 |
| public Object clone() | 克隆该列表。 |
| public Iterator descendingIterator() | 返回倒序迭代器。 |
| public int size() | 返回链表元素个数。 |
| public ListIterator listIterator(int index) | 返回从指定位置开始到末尾的迭代器。 |
| public Object[] toArray() | 返回一个由链表元素组成的数组。 |
| public T[] toArray(T[] a) | 返回一个由链表元素转换类型而成的数组。 |
HashSet
HashSet 不允许重复,无序。不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
创建 HashSet
HashSet<String> sites = new HashSet<String>();
HashMap
HashMap 的创建
HashMap<String, Object> hashMap = new HashMap<>();
HashMap 常用方法列表如下:
| 方法 | 描述 |
|---|---|
| clear() | 删除 hashMap 中的所有键/值对 |
| clone() | 复制一份 hashMap |
| isEmpty() | 判断 hashMap 是否为空 |
| size() | 计算 hashMap 中键/值对的数量 |
| put() | 将键/值对添加到 hashMap 中 |
| putAll() | 将所有键/值对添加到 hashMap 中 |
| putIfAbsent() | 如果 hashMap 中不存在指定的键,则将指定的键/值对插入到 hashMap 中。 |
| remove() | 删除 hashMap 中指定键 key 的映射关系 |
| containsKey() | 检查 hashMap 中是否存在指定的 key 对应的映射关系。 |
| containsValue() | 检查 hashMap 中是否存在指定的 value 对应的映射关系。 |
| replace() | 替换 hashMap 中是指定的 key 对应的 value。 |
| replaceAll() | 将 hashMap 中的所有映射关系替换成给定的函数所执行的结果。 |
| get() | 获取指定 key 对应对 value |
| getOrDefault() | 获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值 |
| forEach() | 对 hashMap 中的每个映射执行指定的操作。 |
| entrySet() | 返回 hashMap 中所有映射项的集合集合视图。 |
| keySet | 返回 hashMap 中所有 key 组成的集合视图。 |
| values() | 返回 hashMap 中存在的所有 value 值。 |
| merge() | 添加键值对到 hashMap 中 |
| compute() | 对 hashMap 中指定 key 的值进行重新计算 |
| computeIfAbsent() | 对 hashMap 中指定 key 的值进行重新计算,如果不存在这个 key,则添加到 hasMap 中 |
| computeIfPresent() | 对 hashMap 中指定 key 的值进行重新计算,前提是该 key 存在于 hashMap 中。 |
Iterator(迭代器)
Iterator 迭代器的创建
// 先创建一个 ArrayList 或者 HashMap 或者 HashSet 对象
ArrayList<String> list = new ArrayList<>();
// 根据创建的对象创建迭代器
Iterator<String> iterator = list.iterator();
调用 iterator.next() 会返回迭代器的下一个元素,并且更新迭代器的状态。
调用 iterator.hasNext() 用于检测集合中是否还有元素。
调用 iterator.remove() 将迭代器返回的元素删除。
Java 泛型
泛型方法:
在调用时可以接受不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
泛型方法的规则:
- 所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在返回类型之前
- 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符
- 泛型方法体的声明和其他方法一样,注意类型参数只能代表引用类型,不能是原始类型
Java 中泛型标记符:
-
E Element:在集合中使用,因为集合中存放的是元素
-
T Type: Java 类
-
K key:键
-
V Value:值
-
N Number:数值类型
-
? 表示不确定的 java 类型
泛型类:
泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。
和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数也被称为一个类型参数,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
Java 序列化
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。整个过程都是 Java 虚拟机(JVM)独立的,也就是说,在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化该对象。
注:一个类的对象要想序列化成功,必须满足两个条件:该类必须实现 java.io.Serializable 接口。该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
序列化对象
注: 当序列化一个对象到文件时, 按照 Java 的标准约定是给文件一个 .ser 扩展名。
JavaDoc 标签
| 标签 | 描述 | 示例 |
|---|---|---|
| @author | 标识一个类的作者 | @author description |
| @deprecated | 指名一个过期的类或成员 | @deprecated description |
| {@docRoot} | 指明当前文档根目录的路径 | Directory Path |
| @exception | 标志一个类抛出的异常 | @exception exception-name explanation |
| {@inheritDoc} | 从直接父类继承的注释 | Inherits a comment from the immediate surperclass. |
| {@link} | 插入一个到另一个主题的链接 | {@link name text} |
| {@linkplain} | 插入一个到另一个主题的链接,但是该链接显示纯文本字体 | Inserts an in-line link to another topic. |
| @param | 说明一个方法的参数 | @param parameter-name explanation |
| @return | 说明返回值类型 | @return explanation |
| @see | 指定一个到另一个主题的链接 | @see anchor |
| @serial | 说明一个序列化属性 | @serial description |
| @serialData | 说明通过writeObject( ) 和 writeExternal( )方法写的数据 | @serialData description |
| @serialField | 说明一个ObjectStreamField组件 | @serialField name type description |
| @since | 标记当引入一个特定的变化时 | @since release |
| @throws | 和 @exception标签一样. | The @throws tag has the same meaning as the @exception tag. |
| {@value} | 显示常量的值,该常量必须是static属性。 | Displays the value of a constant, which must be a static field. |
| @version | 指定类的版本 | @version info |
Java 8 新特性
Stream 流
Stream 流的创建
ArrayList<String> list = new ArrayList<>();
// 获取一个顺序流
Stream<String> stream1 = list.stream();
// 获取一个并行流
Stream<String> stringStream = list.parallelStream();
// 使用 Arrays 中的 stream() 方法将数组转换成流
Integer[] nums = new Integer[10];
Stream<Integer> stream2 = Arrays.stream(nums);
// 通过使用 Stream 中的静态方法:of()、iterate()、generate()
// 通过 of() 创建流并向在创建时在其中添加元素
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6);
// 通过 iterate() 和 limit() 添加元素
Stream<Integer> limit = Stream.iterate(0, (x) -> x + 2).limit(6);
limit.forEach(System.out::println); // 执行后得到的结果是 0 2 4 6 8 10
// 调要Math汇总的random生成随机数存放在流中
Stream<Double> limit1 = Stream.generate(Math::random).limit(2);
limit1.forEach(System.out::println);
Stream 流的中间操作
-
筛选与切片:
filter:过滤流中的某些元素
limit(n):获取 n 个元素
skip(n):跳过 n 元素,配合 limit(n) 可实现分页
distinct:通过流中元素的 hashCode() 和 equals() 去除重复元素
Stream<Integer> integerStream = Stream.of(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14); Stream<Integer> limit = integerStream.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14 .distinct() //6 7 9 8 10 12 14 .skip(2) // 9 8 10 12 14 .limit(2); // 9 8 limit.forEach(System.out::println); -
映射:
map:接收一个函数作为参数,该函数就会被应用到每个元素上,并将其映射成一个新的元素
flatMap:接收一个函数作为参数,将流中的每个值都转换成另一个流,然后把所有流连接成一个流。
List<String> list = Arrays.asList("a,b,c", "1,2,3"); //将每个元素转成一个新的且不带逗号的元素 Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", "")); s1.forEach(System.out::println); // abc 123 Stream<String> s3 = list.stream().flatMap(s -> { //将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s2 = Arrays.stream(split); return s2; }); s3.forEach(System.out::println); // a b c 1 2 3 -
排序:
sorted():自然排序,流中元素需实现 Comparable 接口
sorted(Comparator com):定制排序,自定义Comparator 排序器
List<String> stringList = Arrays.asList("aa", "ff", "dd"); // String 类自身已实现 Compareable 接口 stringList.stream().sorted().forEach(System.out::println); -
消费
peek:如同于 map,能得到流中的每一个元素,但 map 接收的是一个 Function 表达式,有返回值;而 peek 接收的是 ConsUmer 表达式,没有返回值
Student s1 = new Student("aa", 10); Student s2 = new Student("bb", 20); List<Student> studentList = Arrays.asList(s1, s2); studentList.stream() .peek(o -> o.setAge(100)) .forEach(System.out::println); //结果: Student{name='aa', age=100} Student{name='bb', age=100}
流的终止操作
-
匹配、聚合操作:
allMatch:接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false
noneMatch:接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false
anyMatch:接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false
findFirst:返回流中第一个元素
findAny:返回流中的任意元素
count:返回流中元素的总个数
max:返回流中元素最大值
min:返回流中元素最小值
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5); boolean allMatch = list.stream().allMatch(s -> s > 10); // false boolean noneMatch = list.stream().noneMatch(s -> s > 10); // true boolean anyMatch = list.stream().anyMatch(s -> s > 4); // true Optional<Integer> findFirst = list.stream().findFirst(); // 1 Optional<Integer> findAny = list.stream().findAny(); // 1 long count = list.stream().count(); //5 Optional<Integer> max = list.stream().max(Integer::compareTo); // 5 Optional<Integer> min = list.stream().min(Integer::compareTo); // 1[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Of0A2eRG-1642564950128)(D:/study/studyByMine/endBase/image-20220115160620193.png)]
lambda 表达式
lambda 表达式推导:
/**
* lambda 表达式推导
*/
public class LambdaTest {
public static void main(String[] args) {
/**
* 局部内部类
*/
class Way3 implements Ways {
@Override
public void lambda() {
System.out.println("这是局部内部类");
}
}
// 1. 通过外部类实现
new Way1().lambda();
// 2.通过静态内部类
new Way2().lambda();
// 3.通过局部内部类实现
new Way3().lambda();
// 4.通过匿名内部类实现
/**
* 匿名内部类,没有类的名称,必须借助接口或父类
*/
new Ways() {
@Override
public void lambda() {
System.out.println("这是匿名内部类");
}
}.lambda();
// 5.lambda 表达式
Ways ways = () -> System.out.println("这是 lambda 表达式");
ways.lambda();
}
/**
* 静态内部类
*/
static class Way2 implements Ways {
@Override
public void lambda() {
System.out.println("这是静态内部类");
}
}
}
/**
* 定义一个函数式接口
*/
interface Ways {
void lambda();
}
/**
* 外部类
*/
class Way1 implements Ways {
@Override
public void lambda() {
System.out.println("这是外部类");
}
}















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









