





主要学习如何了解数据,例如读入数据的模块如何,各个变量都属于什么数据类型,一些重要的统计指标对应的值是多少,离散变量唯一值的频次如何统计等等。
# 数据类型转换及描述统计
# 数据读取
sec_cars = pd.read_table(r'C:\Users\LENOVO\Desktop\sec_cars.csv', sep = ',')
# 预览数据的前五行
sec_cars.head()
# 查看数据的行列数
print('数据集的行列数:\n',sec_cars.shape)
# 查看数据集每个变量的数据类型
print('各变量的数据类型:\n',sec_cars.dtypes)

上表就是要读入并解析的数据,如果想预览数据可以使用head函数和tail函数。head可以返回数据的前五行,tail可以预览数据的末尾五行。shape函数查看数据的形状。dtypes查看数据的类型。

结果显示,该数据集一共包含了10948条记录和7个变量,除价格和行使里数为浮点型数据外,其他变量均为字符型变量。但从预览中可以看出二手车上牌时间应该为日期型,新车价格应该为浮点型,为了数据分析,需要对这两个变量进行数据类型的转换。
# 修改二手车上牌时间的数据类型
sec_cars.Boarding_time = pd.to_datetime(sec_cars.Boarding_time, format = '%Y年%m月')
# 修改二手车新车价格的数据类型
sec_cars.New_price = sec_cars.New_price.str[:-1].astype('float')
# 重新查看各变量数据类型
sec_cars.dtypes
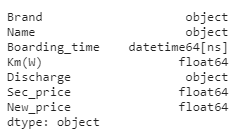
在这里需要说明,pandas模块中的to_datetime函数可以通过format参数灵活地将各种格式的字符型型日期转换成真正的日期数据;由于价格中含有万字,因此不可以直接转换数据类型,需要三步走,首先通过str方法将该字段转换成字符串,然后通过切片手段把万剔除,最后运用astype方法实现数据类型的转换。
接下来,通过基本的统计量(最小值,均值,中位数,最大值等)描述出数据的特征。关于数据的描述性分析可以使用describe方法:
# 数据的描述性统计
sec_cars.describe()

通过describe方法,直接运算了数据框中所有数值型变量的统计值,包括非缺失值个数,平均数、标准差、最小值、下四分位数、中位数,上四分位数和最大值。
统计描述,但不可以清晰地知道数据的形状分布,如数据是否有偏以及是否属于“尖峰厚尾”的特征,为了一次性统计数值型变量的偏度和峰度,
# 数据的形状特征
# 挑出所有数值型变量
num_variables = sec_cars.columns[sec_cars.dtypes !='object'][1:]
# 自定义函数,计算偏度和峰度
def skew_kurt(x):
skewness = x.skew()
kurtsis = x.kurt()
# 返回偏度值和峰度值
return pd.Series([skewness,kurtsis], index = ['Skew','Kurt'])
# 运用apply方法
sec_cars[num_variables].apply(func = skew_kurt, axis = 0)
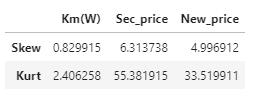
代码说明:columns方法用于返回数据集的所有变量名,通过布尔索引和切片方法获得所有的数值型变量;在自定义函数中,运用计算偏度的skew方法和计算峰度的kurt方法,然后将计算结果组合到序列中;最后使用apply方法,该方法目的就是对指定轴(axis=0,即垂直方向的各列)进行统计计算(运算函数即自定义函数)。
结果显示这三个变量都属于右偏(偏度均大于零)
以上统计分析全都是针对数值型变量的,对于数据框中的字符型变量该如何统计呢,仍然可以使用describe方法,所不同的是需要设置该方法中的include参数:
# 离散型变量的统计描述
sec_cars.describe(include = ['object'])
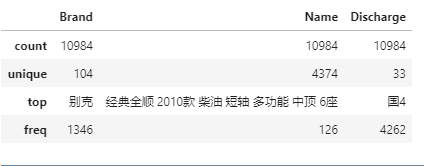
结果中包含离散变量的4个统计值,分别是非缺失观测数、唯一水平数、频次最高的离散值和具体的频次。以二手车品牌为例,一共有10984辆二手车,包含104个品牌,其中别克品牌最多,高达1346辆。需要注意的是,如果对离散型变量作统计分析,需要将object以列表的形式传递给include函数。
对于离散型变量,运用describe方法只能得知哪个离散水平属于最多的,如果需要统计的是各个变量值的频次,甚至是对应的频率,如下代码(以二手车品牌的标准排量discharge为例)
# 离散变量频次统计
Freq = sec_cars.Discharge.value_counts()
Freq_ratio = Freq/sec_cars.shape[0]
Freq_df = pd.DataFrame({'Freq':Freq,'Freq_ratio':Freq_ratio})
Freq_df.head()
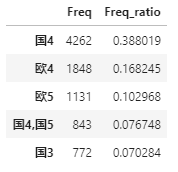
如上结果所示,构成的数据框包含两列,分别是二手车各种标准排量对应的频次和频率,数据框的行索引就是二手车不同的标准排量。如果需要把行标签设置为数据框中的列,可以使用reset_index方法:
# 将行索引重设为变量
Freq_df.reset_index(inplace = True)
Freq_df.head()
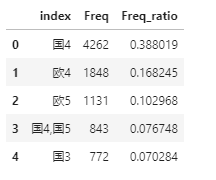
reset_index函数是很常用的,可以非常方便的将行标签转换成数据框的变量。代码中inplace参数设置为True,表示直接对原始数据集进行操作,影响到原始数据集的变化,否则返回的只是变化预览,并不会改变原来的数据集。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









