







项目背景就是项目描述,主要描述以下几个方面:
1、你分析的数据源是什么,有几个,为什么
2、通过这些数据要分析什么结果(有几个模块,每个模块有哪些需求)
3、通过这些结果能够给公司的产品或决策带来什么
项目描述
该项目的数据源是通过不同的用户点击多个app或网站生成的用户点击流日志,ADX通过多个app或网站收集的这些日志并整合到一起用于标签的分析。
通过多个载体提供的用户点击流日志,可以分析各种报表和用户画像基础数据的分析(标签信息)。
生成的结果中,报表可以给决策者进一步分析用户的点击习惯或操作行为,标签信息可以给公司的推荐系统和RTB(实时竞价)系统提供基础数据。
技术架构
描述技术架构的顺序:
1、数据源涉及的技术
2、数据对接过程用到的技术,涉及的问题
3、数据进行需求的分析用到的技术
4、结果的存储

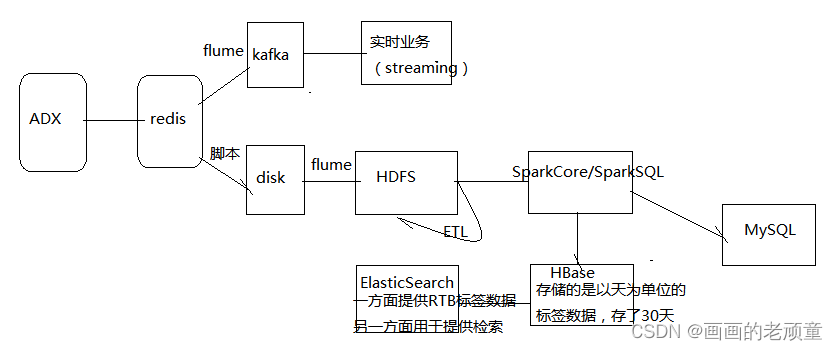
业务流程
业务流程需要结合技术架构进行描述,主要是偏业务方面的描述,描述业务的整个实现过程
首先需要描述用户请求时需要广告的展示的内容,接下来描述展示的广告的分析过程,最后在描述你负责的项目所做的具体内容。

需求实现
关于媒体类别需求的实现:
在获取媒体类别(appname)字段进行分组操作时,发现有的值为空,这时需要在分组之前做一步操作,按照appid到app_dict.txt里根据appid去找对应的appname,如果找不到,则以appid作为媒体类别。
报表-媒体分析
需要用媒体类别(appname)进行分组,但该字段可能有空值,如果有空值,需要从扩展字典(app_dict)文件里按照appid取对应的媒体类别字段,如果取不到,则以appid作为媒体类别的值。
在统计的过程中,扩展字段内容有可能根据需要不断地更新(修改或删除或新增),如果放到HDFS,此时是不好维护。再有,扩展字典的数据量不是很大,而且会频繁的交互,所以可以将给文件放到一个内存数据库中,我们选择用redis存储app_dict。
用SparkSQL的方式实现媒体分析,需要用UDF实现获取redis中的扩展字典
数据标签化
按照指定的规则生成标签数据,比如广告位类型,获取的字段如果是3,需要拼接“LC”,该值不大于10的情况下,需要补0,则生成的标签为:(LC03, 1),该值不大于10的情况下,需要补0。最后需要将生成的所有标签按照key进行聚合。
为什么生成标签?
给rtb作为分析用户行为习惯的基础数据
给推荐系统作为基础数据
标签的数据格式:key-value
key:用户的操作行为,比如点击的广告,操作的某个媒体、输入的关键字等
value:用户操作该行为的聚合值(次数)
最终生成的标签数据是:(userid,List(标签,聚合值,标签,聚合值,标签,聚合值,标签,聚合值,。。。。))
关于userid,不是用户在某个媒体或网站注册的userid,因为不同的媒体或网站会生成不同的userid,这样会让rtb无法找到对应的唯一的标签。实际上rtb拿到的userid是一般是以用户操作设备的id或系统id做为userid。
最终生成的标签的聚合过程是以用户粒度进行聚合的
标签实现的过程:
App 名称标签:需要考虑到扩展字典,需要获取扩展字典的数据和appid进行匹配。
关键字标签:如果有包含“|”,则切分生成多个关键字,字段长度要求大于等于3小于等于8,需要匹配停用字典,匹配到则过滤掉。
**商圈信息标签:**主要是为了给用户做商品或店铺的推荐用途,是通过用户提供的经纬度里找到附近的商圈信息。
GeoHash的应用场景:数据里提供的是具体的经纬度信息,但经纬度信息不能作为地理范围的商圈推荐,需要想办法将经纬度信息转换为一个大致地理范围,这样才能在这个范围当中获取对应的商圈信息,并推荐给用户,此时就可以用GeoHash实现。
GeoHash值的范围是通过生成一定长度的字符串决定的,length越大范围越小。一般生成用户画像中的商圈标签,GeoHash值的长度给6~8位。字符串相似的表示距离相近。
对接百度地图接口过程
1、注册登录
2、获取密钥: 创建应用-》记录刚刚生成的AK、SK,以后请求百度地图时起校验用途
3、查看帮助文档,对接第三方接口
对接百度地图的地理信息需要存到数据库,为什么?
1、为了成本考虑,先到数据库进行查找,如果没有,再请求百度地图
2、减少网络请求数,提高效率
该项目中用到的图计算的应用场景
昨天操作的标签聚合的过程,我们只是拿到第一个不为空的userid作为结果标签数据的key进行聚合,这样有可能出现一个问题,就是一个用户在不同的系统或不同的设备中的操作,此时一定会生成不同的userid,因此生成的标签一定不会聚合在一起,我们可以用图计算的方式实现将同一个用户不同的userid的标签数据尽量给关联起来。
认识图计算
用图计算的方式实现过程中,首先需要构建点的集合,再构建边的集合,最后用图计算生成关系图并进行join整合
关于每天的标签数据存储到HBase和最终标签数据存储到ES的问题描述
HBase里存储的是最近30天的标签数据,而且每天的标签数据之间是没有关系的。
最终的标签数据是在ES中存储的。
为什么用HBase存储每天的标签数据?
是因为在运营部门的展示端(数据平台)需要展示一定时间范围内的标签数据,当然在展示的时候,还有其他的条件,比如,按照某个区域展示,按照某个年龄段。
为什么 最终的标签数据用ES来存?
1、数据量多,ES可以存储海量数据。
2、需要保证数据的安全性,ES实现了多副本机制。
3、一方面是rtb需要不断地获取数据,另一方面是运营部门的数据平台需要通过多种查询方式进行检索,所以当时的技术选型选择的是ES。
最终的标签聚合过程和标签的衰减
首先拿到HBase前一天的聚合数据,再拿到ES中所有的最终标签数据,按照相同的key(userid)进行聚合,聚合的过程就是,同一个userid下,相同的标签进行value累加,不同的标签进行合并。
在聚合的过程中,需要注意一点,标签数据需要根据时间的迭代需要有一个衰减的过程,目的就是为了提高标签的有效性。标签的聚合值需要和衰减系数相乘,相乘后得到的值和最初的聚合值相比,如果大于0.5,则留下,如果小于0.5,则过滤掉该标签。该项目中的衰减系数为0.83,不同的业务衰减系数是不同,衰减系数是怎么出来的?是由你的算法部门计算出来的。
所以,最终的聚合过程是需要另一个应用程序进行计算。
标签的分类
标签一定要先分类,在安装每一个分类确定多个标签,一般用户画像系统的标签数都是在几百甚至是上千。
互联网常见指标
pv:用户请求页面的访问量,页面被刷新一次就会被记录一次,注意pv不是页面的访问量者的数量,是统计网站被访问的页面的数量。
ip访问数:指独立ip访问数,是以一个独立ip在一个计算时间段内访问网站计算为1次ip访问数。在同一个时间段内多次访问均记录为1次。时间段可以是一天,也可以是一个小时。
uv:独立访客。一台终端为一个访客。在同一个局域网中对互联网访问时对外通常是同一个ip,比如该局域网中终端数为10台,这10台同时访问一个网站,此时对该网站的独立ip访问数为1,uv访问数10.
同比、环比、定基比通常用于描述产品的发展速度,比如用于分析销售部额、销售数量、在线人数、充值金额等等。
**同比:**指本期发展水平与上一年同期发展水平对比。
同比有同比增长速度和同比发展速度两种
同比增长速度=(本期数-去年同期数)/去年同期数*100%
同比发展速度=本期数/去年同期数*100%
**环比:**指本期与前期数之比,代表逐期的发展速度。环比分日环比、周环比、月环比、年环比。
环比分环比增长速度和环比发展速度两种
分环比增长速度=(本期数-上期数)/上期数*100%
环比发展速度=本期数/上期数*100%
**环比指数:**指各期依次以前一时期进行统计的指数。统计整个期数发展的趋势。
**定基比:**也指总速度,值本期与某一固定时期进行比较,代表在较长时间期段内的发展速度。
比如“九五”期间各年水平,都是以1995年为基数期进行对比。














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









