







三 后台环境搭建
3. 创建数据库和数据库表
- 物理删除 delete
- 逻辑删除 update (建议使用)
- 原子性: 不可再分
3.1 物理建模 - 理论
3.1.1 第一范式
- 第一范式: 数据库表中的每一列都不可再分, 也就是
**原子性(不可再分)**
| 员工编号 | 员工姓名 | 部门岗位 | 员工工资 |
|---|---|---|---|
| AU0001 | 萧峰 | 行政部助理 | 1000 |
| AU002 | 段誉 | 财政部出纳 | 2000 |
| AU003 | 虚竹 | 技术部工程师 | 3000 |
-
- 这个表中 “部门” 和 “岗位” 应该拆分成两个字段: “部门名称” 和 “岗位”
| 员工编号 | 员工姓名 | 部门名称 | 岗位 | 员工工资 |
|---|---|---|---|---|
| AU0001 | 萧峰 | 行政部 | 助理 | 1000 |
| AU002 | 段誉 | 财政部 | 出纳 | 2000 |
| AU003 | 虚竹 | 技术部 | 工程师 | 3000 |
-
- 这样才能针对 “部门” 或 “岗位” 进行查询
3.1.2 第二范式
- 第二范式: 在满足第一范式基础上要求每个字段都和主键
**完整**相关, 而不是仅和主键部分相关 (只要针对联合主键而言)
| 订单详情表 | |||||
|---|---|---|---|---|---|
| 联合主键 | |||||
| 订单编号 | 产品编号 | 产品价格 | 产品数量 | 订单金额 | 下单时间 |
| ORD0011 | PDT577 | 100 | 2 | 680 | 2019/10/22 |
| ORD0011 | PDT578 | 120 | 4 | 680 | 2019/10/22 |
| ORD0012 | PDT578 | 110 | 11 | 3725 | 2020/1/1 |
| ORD0012 | PDT579 | 105 | 23 | 3625 | 2020/1/1 |
| ORD0013 | PDT579 | 130 | 17 | 8765 | 2018/7/18 |
| ORD0013 | PDT580 | 80 | 29 | 8765 | 2018/7/18 |
| ORD0013 | PDT581 | 77 | 55 | 8765 | 2018/7/18 |
-
- “订单详情表” 使用 “订单编号” 和 “产品编号” 作为联合主键。此时 “产品价格”、“产品数量” 都和联合主键整体相关,
- 但 “订单金额” 和 “下单时间” 只和联合主键中的 “订单编号” 相关, 和 “产品编号” 无关。
- 所以只关联了主键中的部分字段, 不满足第二范式
-
把 “订单金额” 和 “下单时间” 移到订单表就符合第二范式了
| 订单详情表 | |||
|---|---|---|---|
| 联合主键 | |||
| 订单编号 | 产品编号 | 产品价格 | 订单金额 |
| ORD0011 | PDT577 | 100 | 680 |
| ORD0011 | PDT578 | 120 | 680 |
| ORD0012 | PDT578 | 110 | 3725 |
| ORD0012 | PDT579 | 105 | 3625 |
| ORD0013 | PDT579 | 130 | 8765 |
| ORD0013 | PDT580 | 80 | 8765 |
| ORD0013 | PDT581 | 77 | 8765 |
| 订单详情表 | ||
|---|---|---|
| 订单编号 | 订单金额 | 下单时间 |
| ORD0011 | 680 | 2019/10/22 |
| ORD0011 | 680 | 2019/10/22 |
| ORD0012 | 3725 | 2020/1/1 |
| ORD0012 | 3625 | 2020/1/1 |
| ORD0013 | 8765 | 2018/7/18 |
| ORD0013 | 8765 | 2018/7/18 |
| ORD0013 | 8765 | 2018/7/18 |
3.1.3 第三范式
- 第三范式: 表中的非主键字段和主键字段
**直接**相关, 不允许间接相关
| 员工编号 | 员工姓名 | 部门名称 | 岗位 | 员工工资 |
|---|---|---|---|---|
| AU0001 | 萧峰 | 行政部 | 助理 | 1000 |
| AU002 | 段誉 | 财政部 | 出纳 | 2000 |
| AU003 | 虚竹 | 技术部 | 工程师 | 3000 |
-
上面表中的 “部门名称” 和 “员工编号” 的关系是 “员工编号” -> “部门编号” -> “部门名称”, 不是直接相关。此时会带来下列问题
-
- 数据冗余: “部门名称” 多次重复出现
- 插入异常: 组建员工新部门时没有员工信息, 也就无法单独插入部门信息。就算强行插入部门信息, 员工表中没有员工信息的记录同样是非法记录
- 删除异常: 删除员工信息会连带删除部门信息导致部门信息意外丢失
- 更新异常: 哪怕只修改一个部门的名称也要更新多条员工记录
-
正确的做法是: 把上标拆分成两张表, 以外键形式关联
| 员工编号 | 员工姓名 | 部门编号 | 岗位 | 员工工资 |
|---|---|---|---|---|
| AU0001 | 萧峰 | CZ093 | 助理 | 1000 |
| AU002 | 段誉 | CZ094 | 出纳 | 2000 |
| AU003 | 虚竹 | CZ095 | 工程师 | 3000 |
| 部门编号 | 部门名称 |
|---|---|
| CZ093 | 行政部 |
| CZ094 | 财务部 |
| CZ095 | 技术部 |
- “部门编号” 和 “员工编号” 是直接相关的
- 第二范式的另一种表述方式是: 两张表要通过外键关联, 不保持冗余字段。
- 例外不能在 “员工表” 中存储 “部门名称”
3.2 物理建模 - 实践
-
规则的变通
-
- 三大范式是设计数据库表架构的规则约束, 但是在实际开发中允许局部变通
- 比如为了快速查询到关联数据可能会允许冗余字段的存在。
-
-
- 例如在员工表中存储部门名称虽然违背第三范式, 但是免去了对部门表的关联查询
-
-
根据业务功能设计数据库表
-
- 看得见的字段
- 能够从需求文档或原型页面上直接看到的数据都需要设计对应的数据库表、字段来存储
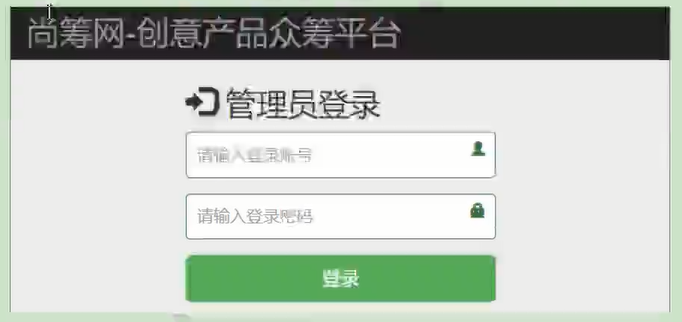
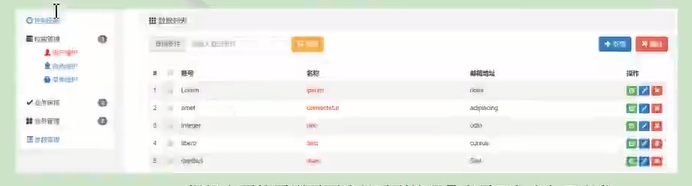
-
根据上面的原型页面我们看到管理员表需要包含如下字段:
-
- 账号
- 密码
- 名称
- 邮箱地址
-
看不见的字段
-
- 除了能够直接从需求文档中看到的字段, 实际开发中往往还会包含一些其他字段来保持其他相关数据。
- 例如: 管理员表需要再增加如下字段以有利于数据维护
-
-
- 主键
- 创建时间
-
-
冗余字段 - backup1…
-
- 为了避免建表时考虑不周有所遗漏, 到后期再修改表结构非常麻烦, 所以也有的团队会设置一些额外的冗余字段备用
-
实际开发对接
-
- 实际开发中除了一些各个模块都需要使用的公共表在项目启动时创建好, 其他专属于各个模块的表由该模块的负责人创建。
- 但通常开发人员不能直接操作数据库服务器, 所以需要把建表的 SQL 语句发送给运维工程师执行创建操作
3.3 创建数据库
CREATE DATABASE project_crowd CHARACTER SET utf8;
3.4 创建管理员数据库表
use project_crowd;
drop table if exists t_admin;
create table t_admin(
id int not null auto_increment, # 主键
login_acct varchar(255) not null , # 登录账号
user_pswd char(32) not null , # 登录密码
user_name varchar(255) not null , # 昵称
email varchar(255) not null , # 邮件地址
create_time char(19) , # 创建时间
primary key(id)
)
insert into t_admin(login_acct, user_pswd, user_name, email, create_time) values('eav', '123123', '伊娃', 'eva@qq.com', now());
| id | login_acct | user_pswd | user_name | create_time | |
|---|---|---|---|---|---|
| 1 | eav | 123123 | 伊娃 | eva@qq.com | 2021/10/12 14:54:33 |















 1331
1331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









