







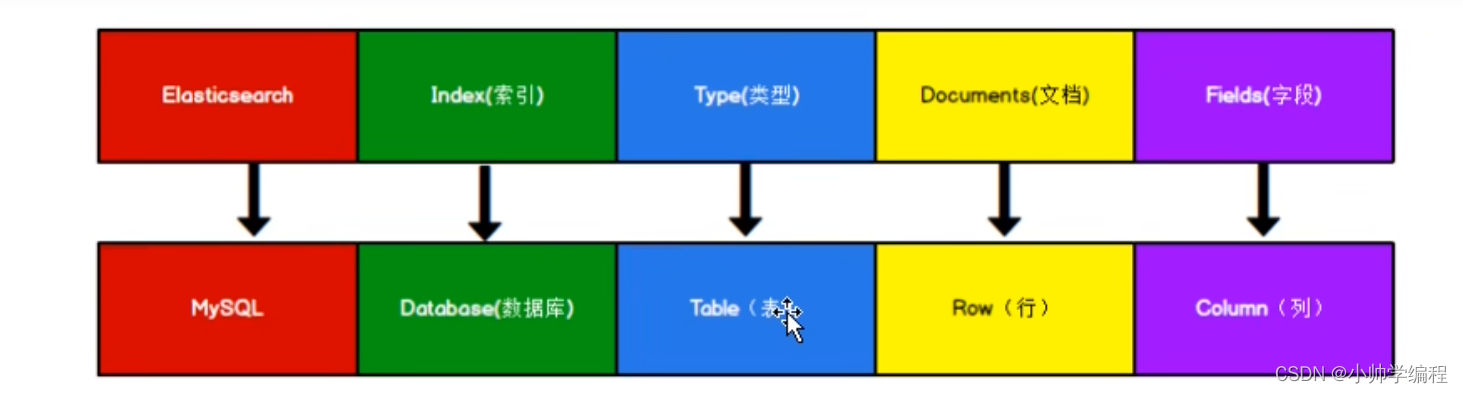
1.基本概念
Index(索引)
动词相当于mysql的insert,名词相当于databases
tyep(类型)
在Index(索引)中,可以定义一个或者多个类型,类似于Mysql中的Table,每一种类型的数据放在一起。
在ElasticSearch6.X中,一个index中只能存在一个type,而在ElasticSearch7.X中,type的概念已经被废除了。
Document(文档)
保存在某个索引下,某个类型的一个数据,文档是JSON格式,Document就像是Mysql中的某个Table里面的内容
模型
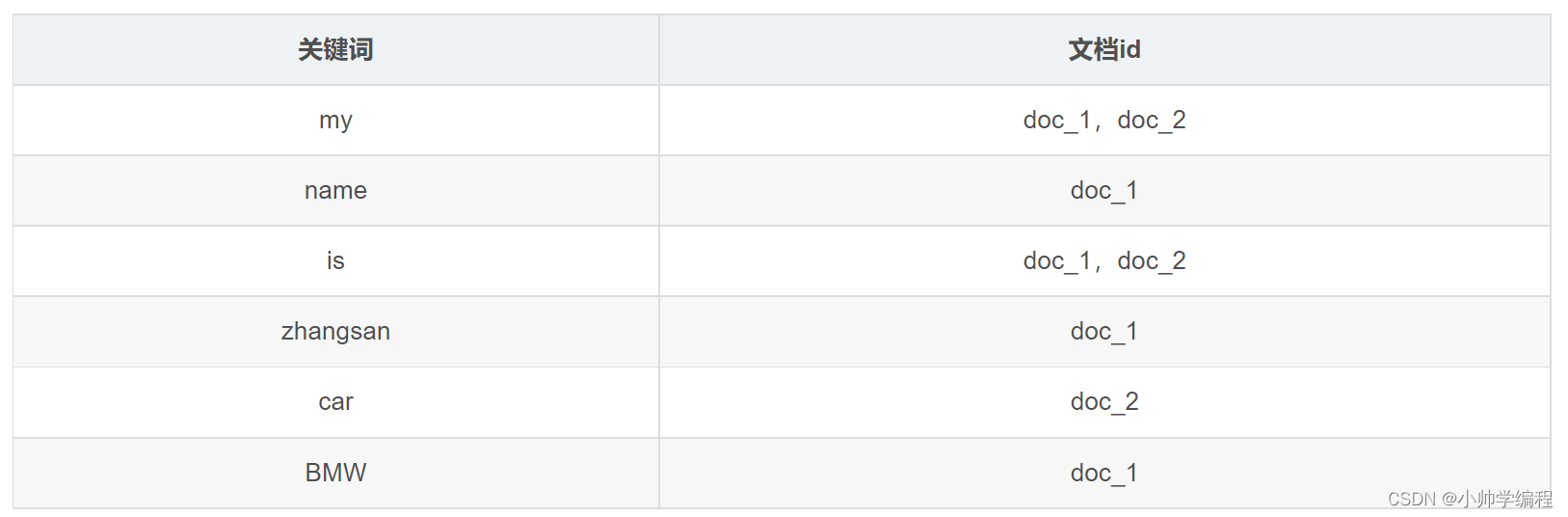
正向索引和倒排索引的概念
正排索引
正向索引 (forward index) 以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档

倒排索引
倒排索引以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档
2.初步检索
_cat
GET /_cat/nodes; ## 查看所有节点
GET /_cat/health;## 查看es的健康状况
GET /_cat/master; ##查看主节点
GET /_cat/indices; ## 查看所有索引
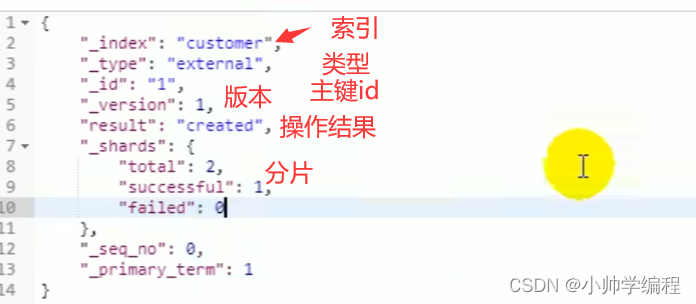
索引一个文档
PUT /索引名/类型名/主键id ## 使用put方式,必须传入主键id,如果存在当前id,为更新操作,否则为新增操作
POST /索引名/类型名/主键id ##使用post方式,传入主键id可选择,如果当前没有传入id,为新增操作,否则传入id,如果存在当前id,为更新操作,否则为新增操作
查询文档操作
## 查询指定id的索引
GET /索引名/_doc/主键id ##例如:GET /shopping/_doc/1
## 查询当前索引下的所有数据
GET /索引名/_search/ ## 例如:GET /shopping/_search

乐观锁修改:
更新携带?if_seq_no=0&if_primary_term=1(PUT请求)
更新文档操作
POST /索引名/_update/主键名
## 例如:
POST /shopping/_update/1
{
"doc": {
"更新字段名":"更新数据",
.....
}
}
删除文档操作
DELETE /索引名/_doc/主键id ## 删除一个文档
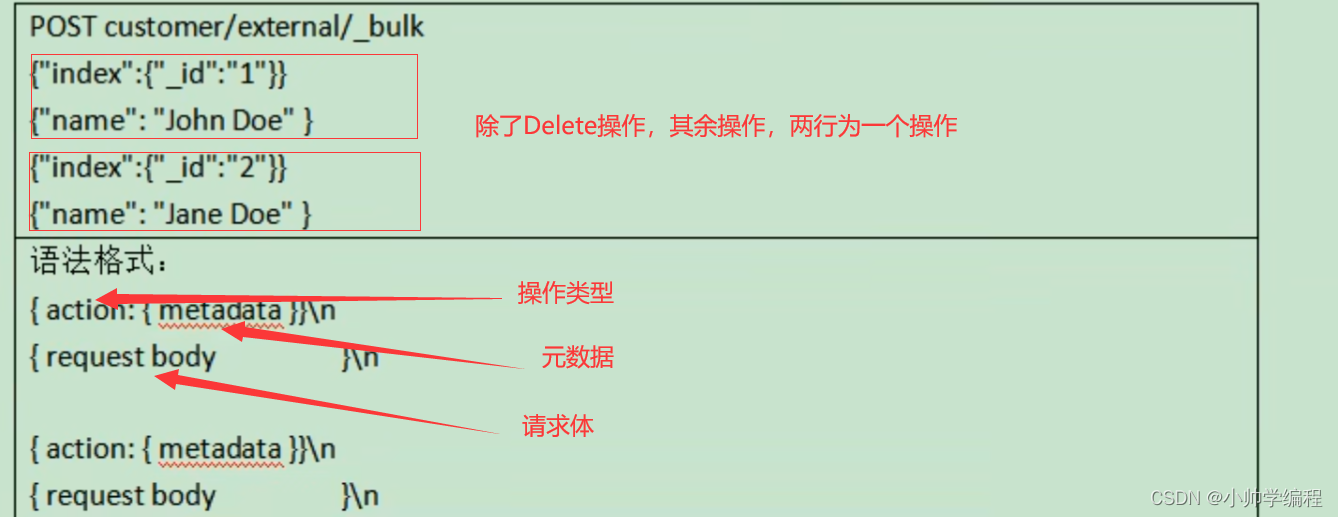
批量操作
3.高级检索
两种检索方式:
- 一个是通过使用REST request URI 发送搜索参数(uri+检索参数)(不推荐)
GET /shopping/_search/?q=*
- 一个是通过REST request body来发送他们(uri+请求体)(推荐)
GET /shopping/_search
{
"query": {
"match": {
"username": "admin"
}
}
}
DSL操作
语法格式
{
"操作类型“: "操作规则"
}
按照字段值关键字查询(match操作)
GET /索引名/_search
{
"query":{
"match":{
"字段名":"字段值"
}
}
}
查询所有文档(match_all操作)
GET /shopping/_search
{
"query": {
"match_all": {
}
}
}
完全查询和高亮显示(match_phrase)
GET /shopping/_search
{
"query": {
"match_phrase": {
"字段名": "字段显示"
}
},
"highlight": {
"fields": {
"字段名": {
}
}
}
}
分页查询(操作等级与query相等)
GET /shopping/_search
{
"query": {
"match_all": {
}
},
"from":"1", ##代表offset,从第一个数据开始
"size":"2" ## 代表limit,查询多少数据
}
只显示部分字段
GET /shopping/_search
{
"query": {
"match_all": {
}
},
"_source": ["字段名1", "字段名2"...]
}
排序
不能对文本类型进行排序
GET /shopping/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"字段名": {
"order": "升序或者降序(ASC或者DESC)"
}
}
]
}
多添加查询
GET /shopping/_search
{
"query": {
"bool": {
"must": [ ## must中的条件必须同时符合,类似于and
{
"match": {
"price": "3"
}
}
],
"should": [ ## should中的条件符合其一集合,类似于or
{
"match": {
"username.keyword": "admin"
}
}
],
"filter": { ##过滤以上结果
"range": { ## 范围过滤
"price": {
"gte": 1,
"lte": 5
}
}
}
}
}
}
聚合操作(aggs)
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"age_group": { ##聚合操作名
"terms": { ## 聚合操作类型
"field": "age"
"size": 10
}
}
},
"size": 0
}
映射(mapping)
表示字段的类型,一般在创建索引的时候指定,但是在ElasticSearch8中,将移除,因此,此处降只记录一个概念。
创建一个映射
PUT /testIndex
{
"mappings": {
"properties": {
"age": {
"type":"integer", ## 字段类型
"index": false, ## 是否能够被索引到
"doc_values": true ##是否存储到磁盘中
},
"email": {
"type":"keyword" ## 字段类型
}
}
}
}
在已创建的映射中添加一个字段映射
PUT /testIndex/_mapping
{
"properties": {
"email": {
"type":"keyword" ## 字段类型
}
}
}
修改已存在字段的类型
elasticsearch中不能修改已存在字段的类型,因为这样会使历史数据丢失,因此在elasticsearch中如果要修改现有字段的类型,只能创建一个新的索引,规定mapping后,进行数据迁移、
数据迁移
elasticsearch6.0之后的写法

elasticsearch6.0以前的写法


分词
一个tokenizer(分词器)接受一个字符流,将之分隔为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
ElasticSearch提供了很多内置的分词器,可以用来构建custom analyzers(自定义分词器)
安装ik分词器
下载地址:https://hub.fastgit.xyz/medcl/elasticsearch-analysis-ik/releases?page=7
安装步骤
将插件安装包传入elasticsearch的plugin目录下,即可。
自定义分词器
配置文件地址:elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml,由于配置的分词器是对应的网络地址,因此,我们需要搭一个Nginx。
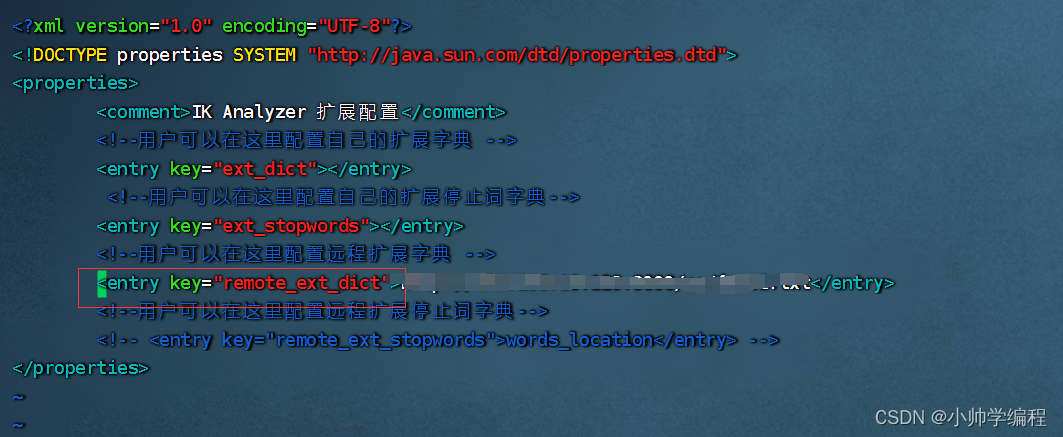
搭建nginx
docker-compose内容:
nginx:
image: nginx
container_name: nginx
ports:
- "8000:80"
volumes:
- './nginx/html:/usr/share/nginx/html'
- './nginx/logs/:/var/log/nginx/'
- './nginx/conf/:/etc/nginx/'
restart: always
privileged: true
networks:
- rmq1
将nginx的容器复制到外面
docker container cp nginx:/etc/nginx ./nginx_1
在nginx/html/目录下创建一个txt文件,添加你的词组
将对应的访问路径放入elasticsearch文件即可。
4.SpringBoot集成ElasticSearch
单体架构
使用步骤:
1.加入jar包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
2.application.yaml中加入配置
spring:
elasticsearch:
rest:
uris:
- IP地址:端口
3.工具类:ElasticsearchRestTemplate(是使用 High Level REST Client 的 ElasticsearchOperations 接口的实现)
4.创建实体类
package com.tom.gulimall.search.es;
import com.tom.common.es.AttrsEsModelDto;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.data.elasticsearch.annotations.IndexPrefixes;
import java.util.List;
/**
* @author: wys
* @date: 2022/9/8 17:42
* @description: 首页索引
*/
@Document(indexName = "product") //设置索引名,如果不存在,默认创建
@Data
public class HomeIndexEntity {
@Id
@Field(type = FieldType.Long)
private Long skuId;
@Field(type = FieldType.Keyword)
private Long spuId;
@Field(type = FieldType.Text, analyzer = "ik_smart")
private String skuTitle;
@Field(type = FieldType.Keyword)
private String skuPrice;
@Field(type = FieldType.Keyword, index = false, docValues = false)//index代表不作为索引对象,docValue表示不序列化
private String skuImg;
@Field(type = FieldType.Long)
private Long saleCount;
@Field(type = FieldType.Boolean)
private Boolean hasStock;
@Field(type = FieldType.Long)
private Long hotScore;
@Field(type = FieldType.Long)
private Long brandId;
@Field(type = FieldType.Long)
private Long catelogId;
@Field(type = FieldType.Keyword, index = false, docValues = false)
private Long brandName;
@Field(type = FieldType.Keyword, index = false, docValues = false)
private String brandImg;
@Field(type = FieldType.Keyword, index = false, docValues = false)
private String catelogName;
@Field(type = FieldType.Object)
private List<AttrsEsModelDto> attr;
}
5.创建持久层对象,继承ElasticsearchRepository接口
//第一个泛型代表操作对象,第二个泛型代表主键id类型
@Component
public interface UpProductDao extends ElasticsearchRepository<HomeIndexEntity, Long> {
}
6.可以根据语法定义常用方法,也可以用@Query自定义方法
GET /product/_search
{
"query": {
"match_all": {}
}
}
上述查询方法,可以简述为(@Query中的内容为【“query”:】后的内容):
@Query("{\n" +
" \"match_all\": {}\n" +
" }")
List<HomeIndexEntity> findAllProduct();
5.常见的问题:
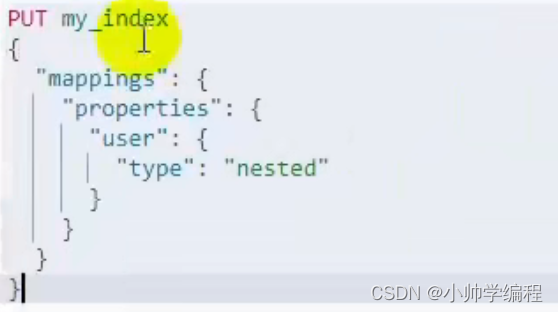
ES存储数组数据的时候会对数据执行扁平化操作,而扁平化操作会导致数据操作错误,如何解决这种影响?
设置属性为nested类型















 2649
2649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









